第一部分(基础)
一、什么是内部类,内部类的作用?
1.定义
在java语言中,可以把一个类定义到另外一个类的内部,在类里面的这个类就叫内部类,外面的类就叫外部类。
2.内部类的种类
主要以下4种:静态内部类,成员内部类,局部内部类,匿名内部类
静态内部类
静态内部类是指被声明为static的内部类,他可以不依赖内部类而实例,而通常的内部类需要实例化外部类,从而实例化。静态内部类不可以有与外部类有相同的类名。不能访问外部类的普通成员变量,但是可以访问静态成员变量和静态方法(包括私有类型)
成员内部类
一个 静态内部类去掉static 就是成员内部类,他可以自由的引用外部类的属性和方法,无论是静态还是非静态。但是不可以有静态属性和方法
局部内部类
定义在一个代码块的内类,他的作用范围是所在代码块,是内部类中最少使用的一类型。局部内部类跟局部变量一样,不能被public ,protected,private以及static修饰,只能访问方法中定义final类型的局部变量
匿名内部类
匿名内部类是一种没有类名的内部类,不使用class,extends,implements,没有构造函数,他必须继承其他类或实现其他接口。匿名内部类的好处是使代码更加简洁,紧凑,但是带来的问题是易读性下降
3.内部类的好处
①隐藏你不想让别人知道的操作,也即封装性。
②一个内部类对象可以访问创建它的外部类对象的内容,甚至包括私有变量!
4.内部类的使用时机
①实现事件监听器的时候(比方说actionListener 。。。采用内部类很容易实现);
②编写事件驱动时(内部类的对象可以访问外部类的成员方法和变量,注意包括私有成员)
二、抽象类和接口
....大家都知道
三、抽象类的意义
1.因为抽象类不能实例化对象,所以必须要有子类来实现它之后才能使用。这样就可以把一些具有相同属性和方法的组件进行抽象,这样更有利于代码和程序的维护。
2.当又有一个具有相似的组件产生时,只需要实现该抽象类就可以获得该抽象类的那些属性和方法。
四、抽象类和接口的使用场景
这篇总结的很好
抽象类的应用场景:
a. 在某些情况下,某个父类只是知道其子类应该包含怎样的方法,但无法准确知道这些子类如何实现这些方法。
b. 从多个具有相同特征的类中抽象出一个抽象类,以这个抽象类作为子类的模板,从而避免了子类设计的随意性。
接口的应用场景:
a. 一般情况下,实现类和它的抽象类之前具有 "is-a" 的关系,但是如果我们想达到同样的目的,但是又不存在这种关系时,使用接口。
b. 由于 java 中单继承的特性,导致一个类只能继承一个类,但是可以实现一个或多个接口,此时可以使用接口。
所以上面说完,可能你是有点蒙蔽,下面就是博文答主的总结,联想到工作中使用的,确实是这么回事:
在使用中抽象类和接口我们该如何选择?
如果你拥有一些方法并且想让它们中的一些有默认实现,那么使用抽象类吧。
如果你想实现多重继承,那么你必须使用接口。由于Java不支持多继承,子类不能够继承多个类,但可以实现多个接口。因此你就可以使用接口来解决它。
如果基本功能在不断改变,那么就需要使用抽象类。如果不断改变基本功能并且使用接口,那么就需要改变所有实现了该接口的类。
四、抽象类是否可以没有方法和属性
可以没有方法和属性。但是有抽象方法的类一定是抽象类。
五、接口的意义
接口 提高代码的重用率。
减低耦合性。
统一访问:
接口的最主要的作用是达到统一访问,就是在创建对象的时候用接口创建,【接口名】 【对象名】=new 【实现接口的类】,这样你像用哪个类的对象就可以new哪个对象了,不需要改原来的代码
多重继承:
另外java用接口还有一个好处,就是java不支持多重继承,但是可以实现多个接口,这个在某种程度上可以看做进行多重继承的一种办法。
六、泛型中extends和super的区别
详细说明
和是Java泛型中的“通配符(Wildcards)”和“边界(Bounds)”的概念。
:是指 “上界通配符(Upper Bounds Wildcards)”
:是指 “下界通配符(Lower Bounds Wildcards)”
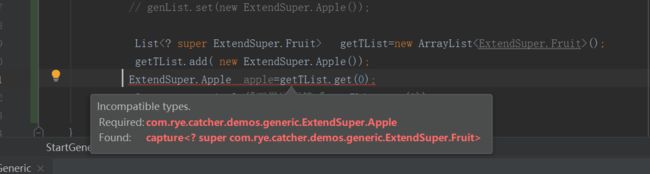
上界不能往里存,只能往外取
会使往盘子里放东西的set( )方法失效。但取东西get( )方法还有效。

如上图。
不能向上转型
而下界通配符,即super,可以向里存,取则会出问题:
只能存放进Object对象里:
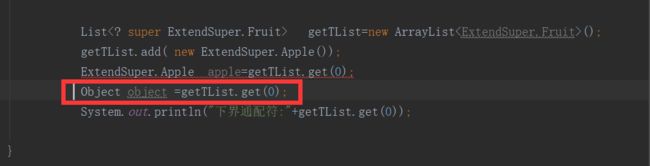
extends 里的不能存,比如extends Number,那可能存存入Double,也可能存入Integer,类型不确定;super的不能取,比如super Number,那么取出的可能是Number,也可能是Object的。
extends和super的使用时机:
PECS
请记住PECS原则:生产者(Producer)使用extends,消费者(Consumer)使用super。
生产者使用extends
如果你需要一个列表提供T类型的元素(即你想从列表中读取T类型的元素),你需要把这个列表声明成,比如List,因此你不能往该列表中添加任何元素。
消费者使用super
如果需要一个列表使用T类型的元素(即你想把T类型的元素加入到列表中),你需要把这个列表声明成,比如List,因此你不能保证从中读取到的元素的类型。
即是生产者,也是消费者
如果一个列表即要生产,又要消费,你不能使用泛型通配符声明列表,比如List
七、进程和线程的区别
...
八、final,finally,finalize的区别
final用于声明属性,方法和类,分别表示属性不可交变,方法不可覆盖,类不可继承。
finally是异常处理语句结构的一部分,表示总是执行。(并不一定,例如try里return)
finalize是Object类的一个方法,在垃圾收集器执行的时候会调用被回收对象的此方法,供垃圾收集时的其他资源回收,例如关闭文件等。
九、父类的静态方法能否被子类重写
不能。
父类的静态方法能够被子类继承。但是不能被重写,即使子类中的静态方法与父类中的静态方法完全一样,也是两个完全不同的方法。
静态属性和静态方法是否可以被继承?
可以被继承。但如果子类中有相同的静态方法和静态变量。那么父类的方法以及变量就会被覆盖。要想调用就必须使用父类来调用。
原因:static修饰函数/变量时,其实是全局函数/变量,它与任何类都没有关系。靠这个类的好处就是这个类的成员函数调用static方法不用带类名。
十、静态内部类的设计意图
这篇文章解释的很透彻
内部类的使用时机:
在一个类的内部,需要操作某种属性,而这个属性需要涉及的面又很广,我们可以考虑将这些属性设计成内部类。
如果内部类和外部类关系不紧密,耦合程度不高,不需要访问外部类的所有属性或方法,那么就设计成静态内部类。
比如有A、B两个类,B可以单独存在,但只被A使用,B对A没有任何依赖关系。那么我们就可以将B设计成静态内部类。
在android中,静态内部类一般用于创建单例模式、与弱引用配合使用防止内存泄漏。
单例模式暂且不提,先说一下如何防止内存泄漏。
非静态内部类(包括匿名内部类)默认就会持有外部类的引用,当非静态内部类对象的生命周期比外部类对象的生命周期长时,就会导致内存泄漏。
比如Handler,但activity销毁时,MessageQueue里或者还有正在处理的msg,因为handler持有activity的引用。从而导致activity销毁时,msg可能还持有activity的引用,这样就导致了内存泄漏。
mHandler 通过弱引用的方式持有 Activity,当 GC 执行垃圾回收时,遇到 Activity 就会回收并释 放所占据的内存单元。这样就不会发生内存泄露了。
上面的做法确实避免了 Activity 导致的内存泄露,发送的 msg 不再已经没有持有 Activity 的引用 了,但是 msg 还是有可能存在消息队列 MessageQueue 中,所以更好的是在 Activity 销毁时就将 mHandler 的回调和发送的消息给移除掉。
十一、闭包和内部类的区别
https://www.jianshu.com/p/f55b11a4cec2
Ruby之父松本行弘在《代码的未来》一书中解释的最好:闭包就是把函数以及变量包起来,使得变量的生存周期延长。闭包跟面向对象是一棵树上的两条枝,实现的功能是等价的
那么如何在java中实现闭包:
https://blog.csdn.net/u010412719/article/details/49453235
十二、string转成integer的原理
1.parseInt(String s)--内部调用parseInt(s,10)(默认为10进制)
2.正常判断null,进制范围,length等
3.判断第一个字符是否是符号位
4.循环遍历确定每个字符的十进制值
5.通过*= 和-= 进行计算拼接
6.判断是否为负值 返回结果。
第二部分(比较深入的知识)
一、哪些情况下的对象会被垃圾回收机制处理掉?
在说这个问题前,务必明白java的垃圾回收机制。
垃圾回收策略详解
二、常见的编码方式
https://blog.csdn.net/warmbeast/article/details/87911596
三、utf-8编码中的中文占几个字节;int型几个字节
utf-8的编码规则:
如果一个字节,最高位为0,表示这是一个ASCII字符(00~7F)
如果一个字节,以11开头,连续的1的个数暗示这个字符的字节数
一个utf8数字占1个字节
一个utf8英文字母占1个字节
少数是汉字每个占用3个字节,多数占用4个字节。
四、静态代理和动态代理的区别
链接一
链接二,这篇例子很好
五、Java异常体系
https://www.cnblogs.com/fwnboke/p/8529469.html
Java把异常作为一种类,当做对象来处理。所有异常类的基类是Throwable类,两大子类分别是Error和Exception。这些异常类可以分为三种类型:系统错误、异常和运行时异常。系统错误由Java虚拟机抛出,用Error类表示。Error类描述的是内部系统错误,例如Java虚拟机崩溃。这种情况仅凭程序自身是无法处理的,在程序中也不会对Error异常进行捕捉和抛出。
异常(Exception)又分为RuntimeException(运行时异常)和CheckedException(检查异常),两者区别如下:
RuntimeException:程序运行过程中出现错误,才会被检查的异常。例如:类型错误转换,数组下标访问越界,空指针异常、找不到指定类等等。
CheckedException:来自于Exception且非运行时异常都是检查异常,编译器会强制检查并通过try-catch块来对其捕获,或者在方法头声明该异常,交给调用者处理。
两种异常的处理方式:若是运行时异常,则表明程序出错,应该找到错误并修改,而不是对其捕获。若是检查异常,遵循该原则:谁知情谁处理,谁负责谁处理,谁导致谁处理。处理就是对其捕获并处理。
六、java解析与分派
https://sufushi.github.io/2018/03/09/Java%E6%96%B9%E6%B3%95%E8%B0%83%E7%94%A8%E2%80%94%E2%80%94%E8%A7%A3%E6%9E%90%E4%B8%8E%E5%88%86%E6%B4%BE/
七、剩下几个面试题
https://www.jianshu.com/p/4dcfe941317a
八、多态的机制
https://www.cnblogs.com/crane-practice/p/3671074.html
九、java中String为什么设计成不可变
String为什么不可变:
安全首要原因是安全,不仅仅体现在你的应用中,而且在JDK中,Java的类装载机制通过传递的参数(通常是类名)加载类,这些类名在类路径下,想象一下,假设String是可变的,一些人通过自定义类装载机制分分钟黑掉应用。如果没有了安全,Java不会走到今天
性能 string不可变的设计出于性能考虑,当然背后的原理是string pool,当然string pool不可能使string类不可变,不可变的string更好的提高性能。
线程安全 当多线程访问时,不可变对象是线程安全的,不需要什么高深的逻辑解释,如果对象不可变,线程也不能改变它
第三部分(数据结构)
一、常用数据结构简介
略。
二、并发集合了解哪些
这里只说两个用过的:
1.ConcurrentHashMap
在JDK1.8中:
ConcurrentHashMap取消了segment分段锁,而采用CAS和synchronized来保证并发安全。数据结构跟HashMap1.8的结构一样,数组+链表/红黑二叉树。
synchronized只锁定当前链表或红黑二叉树的首节点,这样只要hash不冲突,就不会产生并发,效率又提升N倍。
三、集合之间的继承关系
https://www.cnblogs.com/jing99/p/7057245.html
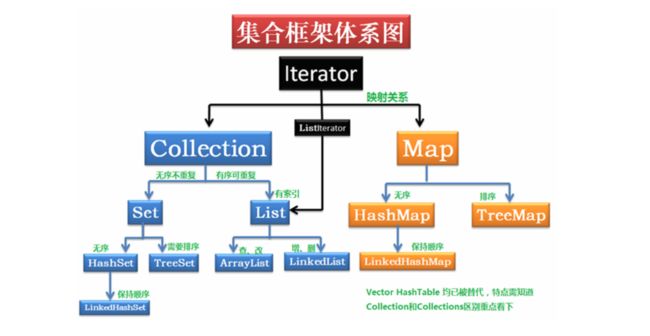
Iterator接口:
Iterator接口,这是一个用于遍历集合中元素的接口,主要包含hashNext(),next(),remove()三种方法。它的一个子接口LinkedIterator在它的基础上又添加了三种方法,分别是add(),previous(),hasPrevious()。也就是说如果是先Iterator接口,那么在遍历集合中元素的时候,只能往后遍历,被遍历后的元素不会在遍历到,通常无序集合实现的都是这个接口,比如HashSet,HashMap;而那些元素有序的集合,实现的一般都是LinkedIterator接口,实现这个接口的集合可以双向遍历,既可以通过next()访问下一个元素,又可以通过previous()访问前一个元素,比如ArrayList。
这些集合具体的情况,我们接下来会逐次分析。
四、java中常见的容器类及其区别
https://blog.csdn.net/qq_37465368/article/details/80854672
五、List,Set,Map的区别
https://www.jianshu.com/p/46a6b4c6693f
六、HashMap原理解析
看了好些篇关于原理解析的文章,都各有所长。
知乎文章
美团技术
hashMap多线程操作死循环
HashMap夺命二十一问
HashMap初始大小
文章较多,总结一些关键性信息:
- HashMap:它根据键的hashCode值存储数据,大多数情况下可以直接定位到它的值,因而具有很快的访问速度,但遍历顺序却是不确定的。 HashMap最多只允许一条记录的键为null,允许多条记录的值为null。HashMap非线程安全,即任一时刻可以有多个线程同时写HashMap,可能会导致数据的不一致。如果需要满足线程安全,可以用 Collections的synchronizedMap方法使HashMap具有线程安全的能力,或者使用ConcurrentHashMap。
2.从结构实现来讲,HashMap是数组+链表+红黑树(JDK1.8增加了红黑树部分)1.7的只有数组+链表。
3.HashMap类中有一个非常重要的字段,就是 Node[] table,即哈希桶数组。 - HashMap就是使用哈希表来存储的。哈希表为解决冲突,可以采用开放地址法和链地址法等来解决问题,Java中HashMap采用了链地址法。链地址法,简单来说,就是数组加链表的结合。在每个数组元素上都一个链表结构,当数据被Hash后,得到数组下标,把数据放在对应下标元素的链表上。
5.通过什么方式来控制map使得Hash碰撞的概率又小,哈希桶数组(Node[] table)占用空间又少呢?答案就是好的Hash算法和扩容机制。
6.Node[] table的初始化长度length(默认值是16),Load factor为负载因子(默认值是0.75),threshold是HashMap所能容纳的最大数据量的Node(键值对)个数。threshold = length * Load factor。也就是说,在数组定义好长度之后,负载因子越大,所能容纳的键值对个数越多。
7.结合负载因子的定义公式可知,threshold就是在此Load factor和length(数组长度)对应下允许的最大元素数目,超过这个数目就重新resize(扩容),扩容后的HashMap容量是之前容量的两倍。HashMap扩容都是两倍两倍来的!没有说一次加2.4.8这么说。
8.如果内存空间很多而又对时间效率要求很高,可以降低负载因子Load factor的值;(负载因子低了,hashMap容量小了,可以分配的个数就多了,反之...)相反,如果内存空间紧张而对时间效率要求不高,可以增加负载因子loadFactor的值,这个值可以大于1。
9.capacity和size
capacity表示Map可以装多少个元素,size表示Map装了多少个元素。
10.这里存在一个问题,即使负载因子和Hash算法设计的再合理,也免不了会出现拉链过长的情况,一旦出现拉链过长,则会严重影响HashMap的性能。于是,在JDK1.8版本中,对数据结构做了进一步的优化,引入了红黑树。而当链表长度太长(默认超过8)时,链表就转换为红黑树,利用红黑树快速增删改查的特点提高HashMap的性能,其中会用到红黑树的插入、删除、查找等算法。
11.HashMap的插入操作HashMap如何put数据(从HashMap源码角度讲解)()
https://blog.csdn.net/the_one_and_only/article/details/81665098
补充说明:HashMap有个重要的字段就是Node[]table,即哈希桶数组。put操作是根据key的hashCode进行存储的,根据hashCode找其对应的索引Node[i],如果为空,说明没有冲突,那么就存储到数组对应的链表中;如果找到了对应的索引,说明相同的hashcode的不同key,那么接着就会遍历这个链表,如果链表的个数超过8,就将其转换为红黑树。接着会将这个键值对存在对应的链表下,在遍历列表的时候我们还需要equals一下key值,如果两个key值相同,那么就覆盖value。这也就是链地址法解决冲突的体现。每个数组上都有一个链表。最后我们判断一下当前的键值对个数即size是否超过了thresHold(首先,Node[] table的初始化长度length(默认值是16),Load factor为负载因子(默认值是0.75),threshold是HashMap所能容纳的最大数据量的Node(键值对)个数。threshold = length * Load factor。也就是说,在数组定义好长度之后,负载因子越大,所能容纳的键值对个数越多。),如果超过了,就进行扩容。
七、HashMap如何手写实现
https://www.cnblogs.com/chenfei-java/p/10674341.html
八、ConcurrentHashMap的实现原理
ConcurrentHashMap的实现原理
jdk1.7中是有Segment数据结构+HashEntry数组结构构成,采用分短缩来保证安全性。
jdk1.8抛弃了Segment的概念,直接采用Node数组+链表+红黑树的数据结构,并发控制使用Synchronized和CAS来操作。
1.put()方法解析

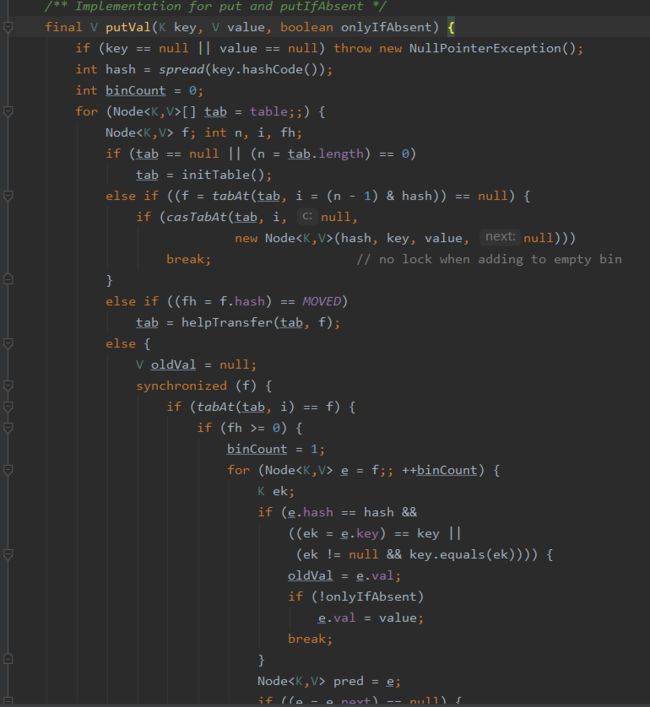

可以看到 Concurrent不允许key或者value为null。
put操作主要有两个步骤:
1.判断是否需要扩容
2.定位到添加元素的位置,将其放入HashEntry数组中
①首先判断Node数组是否初始化,如果还没有初始化,就调用initTable方法进行初始化。

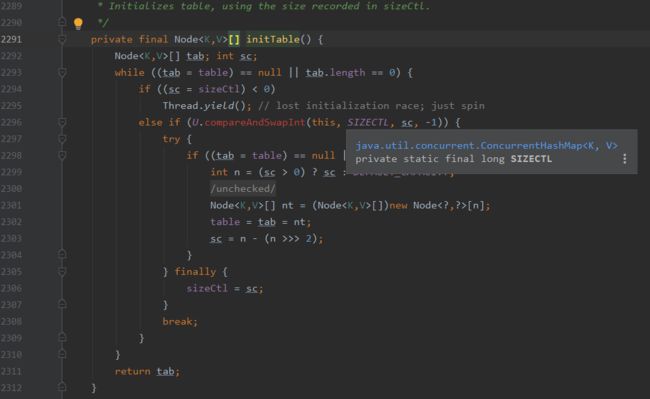
!]( https://upload-images.jianshu.io/upload_images/12111655-5b78ef6a9da07091.png?imageMogr2/auto-orient/strip%7CimageView2/2/w/1240)
如果正在初始化或正在扩容,调用Thread.yield()进行线程让步,把自己的时间片让让掉。否则调用native层Unsafe的compareAndSwapInt加上CAS锁初始化Node数组。
②接着判断是否有哈希冲突,没有就直接CAS插入(通过位与运算判断是否有冲突),调用UnSafe的compareAndSwapObject方法
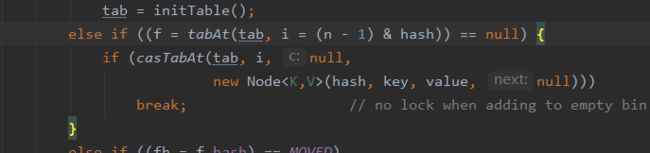
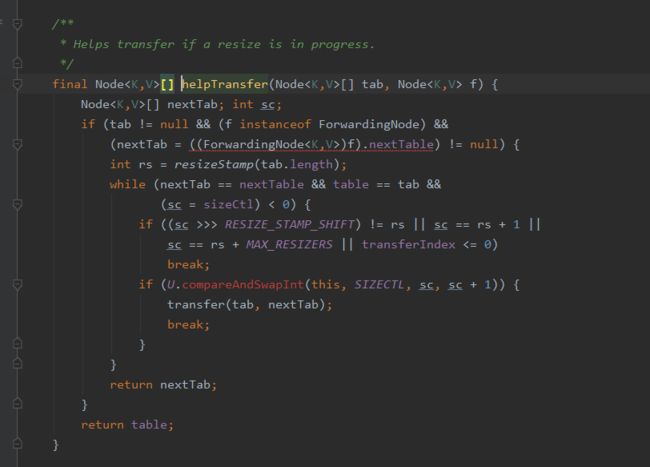
③如果还在扩容就先调用helpTransfer进行扩容操作;此方法目的就是调用多个工作线程一起帮助进行扩容,这样的效率就会更高,而不是只有检查到要扩容的那个线程进行扩容操作,其他线程就要等待扩容操作完成才能工作。

④如果存在hash冲突,加就上内部锁synchronized来保证线程安全,也就是else里的操作:
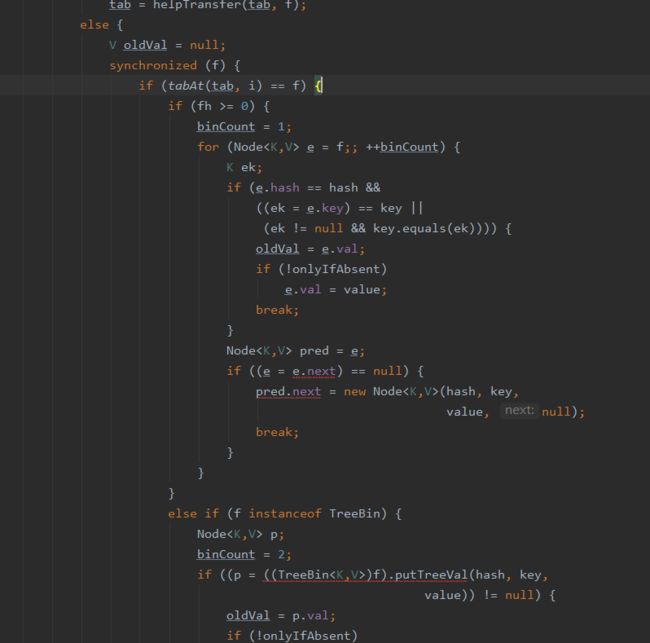
这里分为两种情况:
一种是链表形式直接遍历到尾端插入;(fh>=0,如果hash值大于0,就是链表,这里的hash值是由native层计算出来的)
另一种如果是红黑树就按照红黑树结构插入;
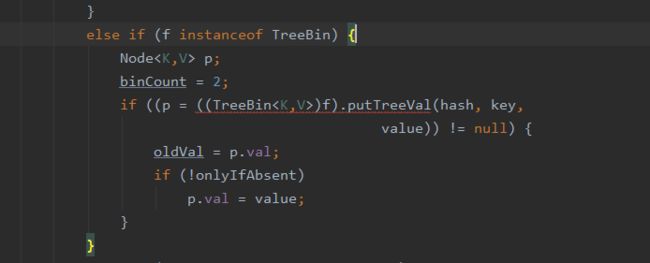
⑤如果Hash冲突时会形成Node链表,在链表长度超过8,Node数组超过64时会将链表结构转换为红黑树的结构;
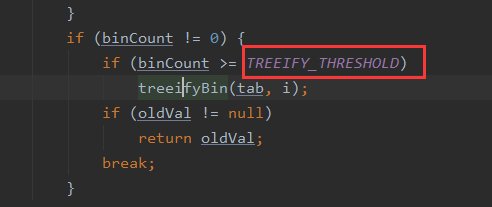

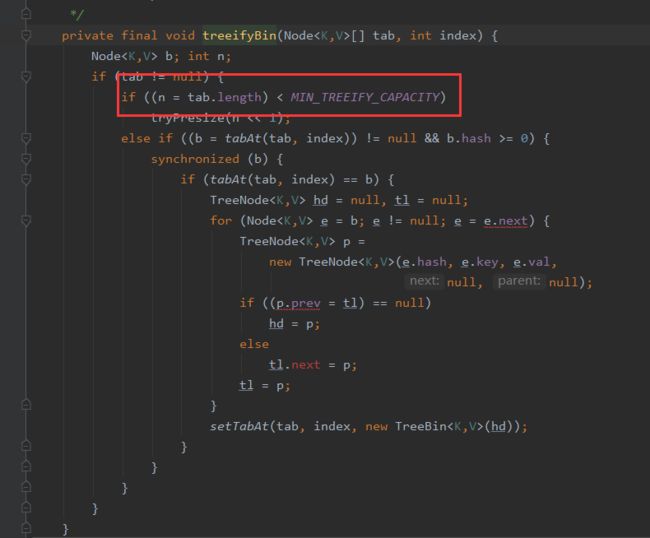

可以看到如果链表超过8,则把链表转化为红黑树,提高遍历查询效率。
⑥如果添加成功就调用addCount方法统计size,并且检查是否需要扩容。

如果需要扩容(size超过SIZECTL),就调动transfer()进行扩容操作。
tranfer()方法是ConcurrentHashMap扩容操作的核心方法,整个方法主要分为两步:
1.构建一个nextTable,其大小为原来大小的两倍,这个步骤是在单线程环境下完成的
2.将原来table里面的内容复制到nextTable中,这个步骤是允许多线程操作的,所以性能得到提升,减少了扩容的时间消耗
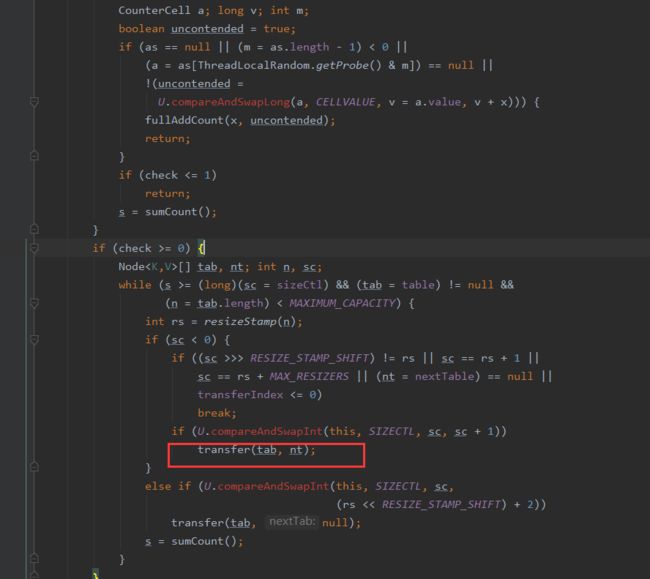
2.get方法
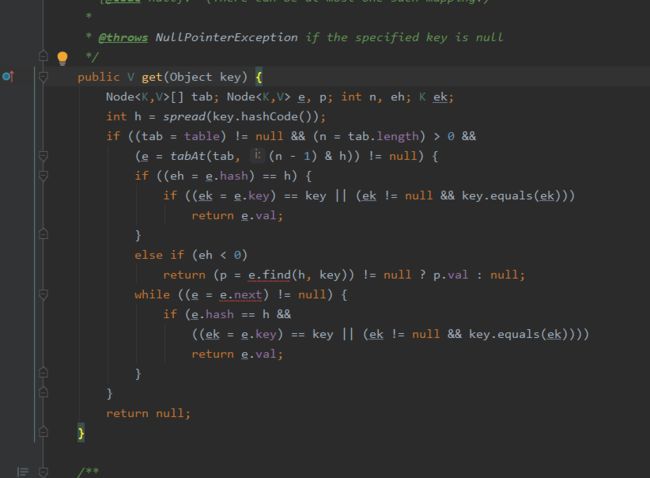
主要就是两步:
①判断table是否为空,如果为空返回null;
②计算key的hash值,并获取指定table中位置的Node节点,通过遍历链表或者红黑树来找到对应的节点,返回value值。
顺带一提,Node节点的数据结构;
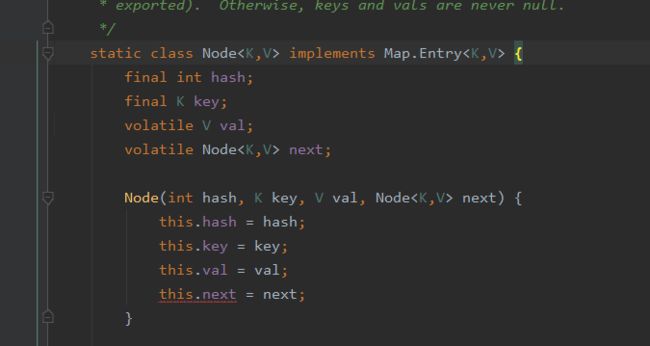
四个元素:
①hash值、②key值,③value值,④下一个节点。
3.size函数
在并发量很高时,如果存在两个线程同时执行CAS修改baseCount值,则失败的线程会继续执行方法体中的逻辑,使用CounterCell记录元素个数的变化;
通过累加baseCount和CounterCell数组中的数量,即可得到元素的总个数;
九、ArrayMap和HashMap的对比
https://www.cnblogs.com/yibutian/p/9626251.html
十、HashMap和HashTable的区别
https://blog.csdn.net/qq_35181209/article/details/74503362
十一、TreeMap
这里没怎么看原理,毕竟平常不怎么用,先看看如何使用的吧:
https://www.jianshu.com/p/e11fe1760a3d
十一、HashSet与HashMap怎么判断集合元素重复?
https://blog.csdn.net/github_37130188/article/details/96508223
十二、集合Set实现Hash怎么防止碰撞
https://blog.csdn.net/github_37130188/article/details/96508272
十三、ArrayList和LinkedList的区别,以及应用场景
https://blog.csdn.net/minolk/article/details/80978707
十四、数组和链表的区别
https://blog.csdn.net/qq_35044419/article/details/88580775
https://blog.csdn.net/qq_39291929/article/details/81351026
十五、二叉树的广度优先遍历和深度优先遍历
https://blog.csdn.net/weixin_39912556/article/details/82852749
十六、堆
https://www.jianshu.com/p/6b526aa481b1
十七、手写链表逆序算法(当然java中如何实现链表也是需要知道的)
手写链表逆风算法
十八、对B树,B+树、红黑树的理解
相关链接
在这篇博客的基础上做一下简单的总结:
B树:
①所有结点都带有指向记录的指针
②在内部索引出现过的索引项不会再出现在叶子结点中
③叶子结点并没有通过指针连接起来
④查找记录不能横向遍历,只能用中序遍历了
其优点:
对于在内部结点的数据,可以直接得到,不必根据叶子结点来定位。
B+树:
①非叶子结点不会带上指向记录的指针,这样一个块中就可以容纳更多的索引项。这样,一可以降低树的高度,二十一个内部结点可以定位更多的叶子结点
②叶子结点之间通过指针连接
③因为叶子结点连接起来了,所以查找的时候我们可以直接横向的遍历过去。
④已经在内部结点出现过的索引还会出现在叶子结点中。因为只用横向遍历,想遍历内部结点只能将其添加到叶子结点中了。
关于红黑树的博客一
关于红黑树的博客二
十九、判断单链表是否成环?
简单的算法实现
不过这里有个小问题,在while循环里,fast!=null应该改为fast.next!=null;
二十、合并单序链表
算法很精简,递归调用
线程、多线程和线程池
1.run和start方法的区别
run方法只是thread中的一个普通方法,并不会创建新的线程。start方法会创建新的线程。
2.如何控制某个方法允许并发访问线程的个数?
static Semaphore sSemaphore = new Semaphore(6) 表示该方法最多允许几个线程访问
sSemaphore.acquire():调用一次,允许进入方法的线程数量减一
sSemaphore.release():调用一次,允许进入方法的线程数量加1
3.在java中wait和sleep方法的不同?
①原理不同:
sleep方法时Thread类的静态方法,是线程用来控制自身流程的。wait是Object方法,用于线程通信。
②对锁的处理机制不同:
sleep是让线程暂停一段时间,不涉及线程间通信,所以不会释放锁。而wait,会释放掉他所占用的锁。
③使用区域不同:
wait方法必须放在同步控制方法和同步代码块内。sleep方法可以放在任何地方使用。sleep必须捕获异常,因为持有锁,所以可能造成死锁。
4.wait和notify的理解
这篇博客解释的很清楚
5.什么导致线程阻塞?
链接
这里的第二条解释了什么是线程阻塞...
6.线程停止的方法
有三种方法可以停止线程:
①设置退出标志,使线程正常退出,也就是run方法执行完毕后线程终止。
②使用interrupt()方法中断线程
③使用stop方法强行终止。强烈不推荐使用,已经被废弃。
在线程池中也有相应的方法:
①shutdown:
将线程池状态置为SHTUDOWN后,并不会立即停止:
停止接收外部submit的任务
内部正在跑的任务和队列里等待的任务,会执行完;
②shutdownNow
跟shutdown一样,先停止接收外部提交的任务;
忽略队列里等待的任务;
尝试将正在跑的任务interrupt中断;
返回未执行的任务列表。
7.Java中如何实现同步
①同步方法:即使用synchronized关键字修饰方法;可以修饰静态方法,此时如果调用该静态方法,将会锁住整个类;
②同步代码块:即有synchronized关键字修改的语句块;同步是一种高开销的操作,因此应该尽量减少同步的内容;通常没有必要同步整个方法,使用synchronized代码块同步关键代码即可。(DCL中的就是同步代码块,获取的是类的锁)
③使用特殊域变量volatile实现线程同步:
每次取值都从主存中获取,而不是使用寄存器的值;volatile不会提供任何原子操作,也不能修饰final类型的变量。
8.什么是线程安全?如何保证线程安全?
线程安全:
线程安全就是多线程访问时,采用了加锁机制,当一个线程访问该类的某个数据时,进行保护,其他线程不能进行访问直到该线程读取完,其他线程才可使用。不会出现数据不一致或者数据污染。 线程不安全就是不提供数据访问保护,有可能出现多个线程先后更改数据造成所得到的数据是脏数据。
如何保证线程安全?:
1.使用线程安全的类
2.使用synchronized关键字
3.使用volatile
9.如何实现线程同步:
①synchronized实现同步方法
②synchronized实现同步代码块
③使用volatile
④使用重入锁实现线程同步(ReenreantLock)
⑤ThreadLocal管理变量,没一个使用该变量的线程都获得该变量的副本,副本之间相互独立,不会对其他线程产生影响。
9.Java对象的生命周期
①创建阶段
②应用阶段
③不可见阶段
④不可达阶段
⑤收集阶段
⑥终结阶段
⑦对象空间重新分配阶段
各个阶段具体行为
10.有关Synchornized和volatile的相关内容
之前总结的博客
11.死锁产生的四个条件
①互斥:
某种资源一次只允许一个进程访问
②占有且等待:
一个进程本身占有资源(一种或多种),同时还有资源未满足,正在等待其他线程释放资源
③不可抢占
别人已经占用了某项资源,你不能因为自己需要改资源就给抢过来
④循环等待
存在一个进程链,使得每个进程都占有下一个进程所需的至少一种资源。
12、断点续传原理
主要是通过HttpUrlConnection设置
setRequestProperty("Range","bytes="+startPos+"-"+"endPos");
然后通过RandomAccessFile的seek方法,定位到startPos的位置,进行文件的写入。
第四部分、Android面试题
比较基础的就不记录了,只写几个不太注意的
一、横竖屏切换的时候,Activity各种情况下的生命周期
这里分两种情况:
1.不设置Activity的android:configChanges,切屏的时候生命周期都会再执行一次
2.设置android:configChanges="orientation|keyboardHidden|screenSize"
只会执行onConfiguarionChanged方法。
2.有dialog的activity按home键的生命周期
总结: 有 Dialog 和 无 Dialog 按 Home 键效果一样:
- 正常启动: onCreate() -> onStart() -> onResume()
- 按 home 键: onPause() -> onStop()
- 再次启动: onRestart() -> onStart() -> onResume()
3.Broadcast种类
8.0取消了大部分静态注册广播
静态注册和动态注册的区别
BroadcastReceiver 与 LocalBroadcastReceiver 有什么区别?
前者可以接受所有程序发出的广播
后者只能接收自己所在程序发出的广播
4.AlertDialog,popupWindow,Activity区别
这篇说的很清楚
5.ApplicationContext和Activity的Context的区别
还算详细
6.插值器和估值器
介绍的很详细
(Android源码相关分析)
1.android个版本api对比
到9.0
2.Requestlayout,onlayout,onDraw,DrawChild区别与联系
简述
requestLayout:(内部采用了责任链模式,一层层向上调用父布局的requestLayout)
会导致View的onMeasure、onLayout、onDraw方法被调用;
onLayout:ViewGroup中对子View进行布局;
onDraw:绘制视图;
drawChild:去重新回调每个子视图的draw()方法;
3.invalidate和postInvalidate的区别及使用
invalidate:在UI线程中调用
postInvalidate:可以在非UI线程中进行调用。
4.Activity-Window-View三者的关系
这篇文章介绍的比较明确
Activity是安卓四大组件之一,负责界面展示、用户交互与业务逻辑处理;
Window就是负责界面展示以及交互的职能部门,就相当于Activity的下属,Activity的生命周期方法负责业务的处理;
View就是放在Window容器的元素,Window是View的载体,View是Window的具体展示
5.低版本SDK如何实现高版本api
四种:
添加注解:①@TargetApi(Build.VERSION_CODES.N)
②添加注解 @RequiresApi(Build.VERSION_CODES.N)
③添加注解 @SuppressLint(“NewApi”)
④添加运行时SDK版本判断(推荐用这个,其他三个在7.0以下手机会报错)
6.Looper架构
这个实际上可以围绕Handler里的Looper进行说明
8.ActivityThread,AMS,WMS的工作原理
介绍的比较详细
9.请介绍下ContentProvider是如何实现数据共享的
简述:底层是用SQLite数据库实现的,所以其对数据做的各种操作都是以SQL实现的,只在上层提供Uri,这个Uri就是在清单文件中通过authorities来指定的。
例如: android:authorities="com.myit.providers.MyProvider"
其他程序可以使用ContentResolver来操作:
调用Activity的ContentResolver获取ContentResolver对象
调用ContentResolver的insert(),delete(),update(),query()进行增删改查;
要获取ContentResolver对象,可以使用Context提供的getContentResolver()方法。
10.封装View的时候怎么知道view的大小
可以通过onMeasure方法来获得;
如果测量的是一个View:
在onMeasure中获得传入的widthMeasureSpec和heightMeasureSpec(存储了测量的模式和大小),这两个参数是通过getDefaultSize获得的;
如果测量的是一个ViewGroup:
调用measureChildren()方法获得子控件的宽高,其内部判断View是否GONE,若没有,则调用measureChild方法测量每一个子View的宽高;
最后我们通过setMeasuredDimension来设置View的宽高。
11.onTouch和onTouchEvent的区别:
onTouchEvent方法是专门用来处理事件分发的,它一定存在Activity、View和ViewGroup这三者中。onTouch方法是View设置了触摸监听事件后,需要重写的方法,是OnTouchListener接口中的方法。
** onTouchEvent()和onTouch()方法优先级及控制关系**
①如果onTouch()方法返回值是true(事件被消费)时,则onTouchEvent()方法将不会被执行;
②只有当onTouch()方法返回值是false(事件未被消费,向下传递)时,onTouchEvent方法才被执行。
由此可见,给View设置监听OnTouchListener时,重写的onTouch()方法,其优先级比onTouchEvent()要高,假如onTouch方法返回false,会接着触发onTouchEvent,反之onTouchEvent方法不会被调用。内置诸如click事件的实现等等都基于onTouchEvent,假如onTouch返回true,这些事件将不会被触发。
12.View刷新机制
很详细
提取一些关键性信息:
当我们调用了invalidate(),requestLayou(),等之类刷新界面的操作时,并不是马上就会执行这些刷新的操作,而是通过ViewRootImpl的scheduleTraversals()先向底层注册监听下一个屏幕刷新信号事件,然后等下一个屏幕刷新信号来的时候,才会去通过performTraversals()遍历绘制View树来执行这些刷新操作。
具体参考点三。
13.View的绘制流程
这篇介绍的很详细
主要流程:
ViewRoot对应于ViewRootImpl类,它是连接WindowManager和DecorView的纽带,View的绘制流程开始于ViewRoot的performTraversals()方法,只有经过measure、layout、draw三个流程才能最终把View绘制出来。performTraversals()依次调用performMeasure()、performLayout()和performDraw()三个方法,分别完成顶级View的绘制。其中performMeasure()会调用measure(),measure()中又调用onMeasure(),实现对其所有子元素的measure过程,这样就完成了一次measure过程;接着子元素会重复父容器的measure过程,如此反复至完成整个View树的遍历(layout和draw同理)。
具体参考点三。
14.为什么不能在子线程中更新UI
实际上,我们在onCreate中新创建个子线程去更新UI,是可以的,但是如果线程睡眠100ms或者更久,就会崩溃。
因为在这100ms内ViewRootImpl已经完成了创建,并能执行checkThread方法来检测是不是主线程在更新UI。不是主线程就会报错。ViewRootImpl的创建是在onResume之后的。
原文链接
15.LruCache的默认大小
基本设置为手机内存的八分之一。
16.导致ANR的超时时间
Activity----->5秒
Broadcast----->10秒
Service----->20秒
会报ANR,都是在主线程中运行的
17.计算一个View的嵌套等级
while (view.getParents() != null) {
count++;
view = view.getParents();
}
18.Android线程有没有上限?
Android线程是有上限的。如果应用创建线程的数量过多,而没有及时释放会导致OOM
19.实体类为什么要序列化
当两个进程在进行远程通信时,彼此可以发送各种类型的数据。无论是何种类型的数据,都会以二进制序列的形式在网络上传送。发送方需要把这个对象转换为字节序列,才能在网络上传送;接收方则需要把字节序列再恢复为对象;
目的:就是为了跨进程传递格式化数据
20.简化Parceable的使用:
下载android parcelable code generator
21.线程池个数
CPU密集型任务 尽量使用较小的线程池,一般为CPU核心数+1。 因为CPU密集型任务使得CPU使用率很高,若开过多的线程数,只能增加上下文切换的次数,因此会带来额外的开销。IO密集型任务 可以使用稍大的线程池,一般为2*CPU核心数+1。
listView和RecycleView的缓存机制对比?
篇一
篇二
22.Android事件分发机制
当用户点击屏幕的时候,其事件分发如下:
①调用Activity的dispatchTouchEvent事件,如果是DOWN事件,还会调用onUserInterAction事件。
②接着调用Window也就是PhoneWindwo的superDispatchTouchEvent事件
将事件传递到DecorView中
③接着调用ViewGroup的dispathcTouchEvent事件,而ViewGroup里的dispatchTouchEvent中还会调用onInterceptTouchEvent方法决定是否拦截事件。第一个,如果返回false,表明不分发点击事件,那么点击事件就在本层级的onTouchEvent解决;而返回true,表明分发事件,那么点击事件就会传入到下一级ViewGroup中;ViewGroup里的dispatchTouchEvent跟上面一样,决定是否分发事件,如果返回fasle,表明不分发,在自己的onTouchEvent中进行处理;(onInterceptTouchEvent是ViewGroup特有的,也就是Activity和View都没有onIntterceptTouchEvent这个方法);如果返回true,那么就会进入onInterceptTouchEvent,返回true,则表示拦截事件,那么事件就被ViewGroup的onTouchEvent处理掉;返回false,表示不拦截事件,事件进入下一级,如果下一级还是ViewGroup,那么处理流程跟上面一样;如果是View,实际上在View中dispathTouchEvent是不执行分发逻辑的,因为在View中dispatchTouchEvent返回的是onTouchEvent(event)的值,所以我们只需要在View中执行onTouchEvent就可以了。而如果View的onTouchEvent没有处理这个事件,事件就会一层一层传递回去,最终交给Activity默认处理。
注意:onTouch()的执行 先于 onClick()
23.LeakCanary 原理解析
LeakCanary原理解析1.x
LeakCanary使用以及原理1.x
LeakCanary原理解析2.x
LeakCanary基本工作原理
①RefWatcher.watch()创建一个KeyedWeakReference用于观察对象
②在后台线程(HandlerThread)检查引用是否被清除,如果没有,调用GC.
③如果引用还没有被清除,把heap内存dump到对应文件系统中的一个.hprof文件中。
④在另外一个进程中的HeapAnalyzerService有一个HeapAnalyzer,会使用HAHA开源库解析这个hprof文件。
⑤根据唯一的reference key,HeapAnalyzer找到KeyedWeakReference,定位内存泄漏。
⑥HeapAnalyzer计算到GC roots的最短强引用路径,并确定是否内存泄漏。如果是的话,建立导致泄漏的引用链。
⑦引用链传递到APP进程中的DisplayLeakService,并以通知的方式显示出来。
总的来说就是:
在一个Activity执行完onDestroy的时候,会将其保存到WeakReference中,然后将这个WeakReference类型的Activity对象与ReferenceQueue关联。这时再从ReferenceQueue中查看是否还有该对象,如果有,执行GC;再次查看,如果还Activity的应用还存在KeyedWeakRefenece中的的话就是发生了内存泄漏。最后用HAHA开源库解析dump文件。
更加详细点的解析:
当一个Activity Destory之后,将它放在一个WeakReference弱引用中
WeakReference与ReferenceQueue联合使用,如果弱引用关联的对象被回收,则会把这个弱引用加入到ReferenceQueue中
查看ReferenceQueue中是否存在当前弱引用对象
如果存在,手动GC
再次移除不可达引用,如果引用不存在了,则不继续执行
如果两次判定都没有被回收,就Dump出heap信息,然后分析内存泄露的路径
执行两次判断,主要为了确保最大保险的判定是否被回收
原理解析
2.6版本已经不需要手动在Application调用LeakCanary.install进行初始化了。
而是在AppWatcherInstaller的onCreate方法里调用AppWatcher.manmulInstall进行初始化。其中AppWatcherInstaller继承自ContenrProvider,Provider的onCreate优于Application的onCreate执行,调用时机介于Application的attachBaseContext和onCreate之间,此时Application已经创建成功。ContentProvider里的Context正式Application对象。
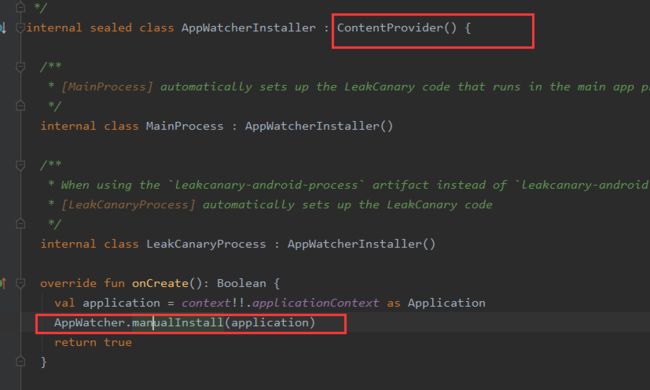
在AppWatcher里构造了四个默认的Watcher,并依次执行install方法:
分别是:
①ActivityWatcher
②FragmentAndViewModelWatcher
RootViewWatcher
ServiceWatcher
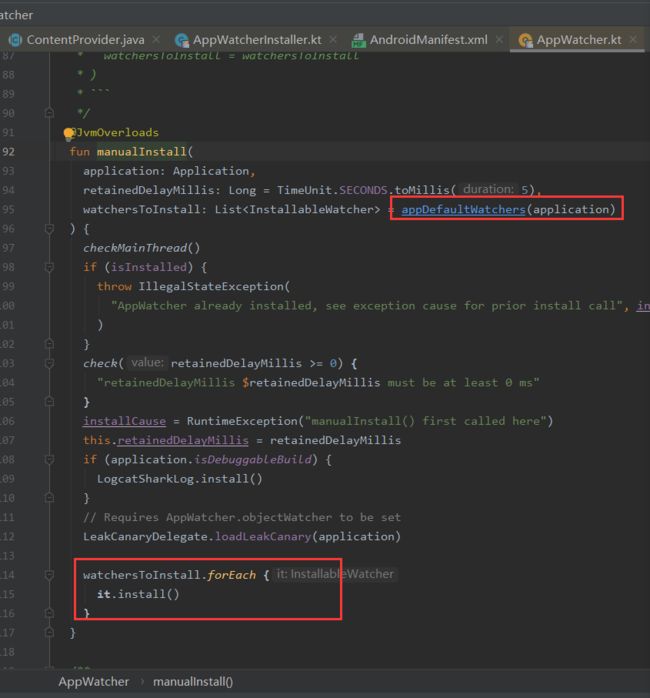
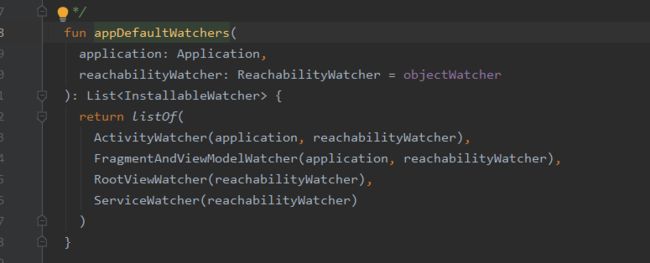
比如ActivityWatcher的install方法就是调用registerActivityLifecycleCallbacks添加生命周期监听。
而这四个默认的Watcher处理的基类都是ObjectWatcher。
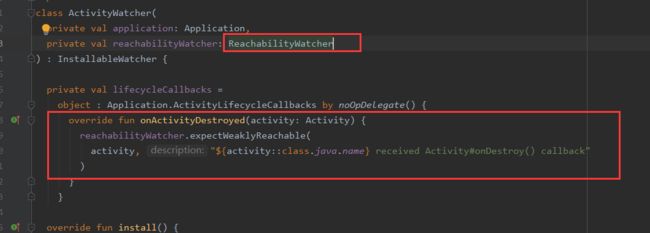

在ObjectWatcher中,有两个重要的对象:
一个KeyedWeakReference的Map。一个弱引用队列:ReferenceQueue。
在Activity销毁时,会将Activity以及ReferenceQueue存放到KeyedWeakReference中,同时生成UUID,将KeyedWeakReference存入到watchObjects中。
检测过程的主要步骤是:
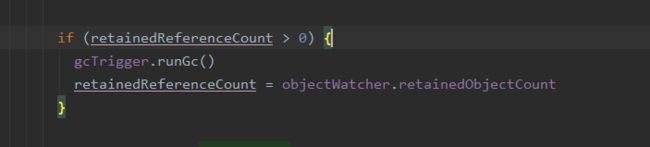
①在HeapDumpTrigger中第一次移除不可达对象:
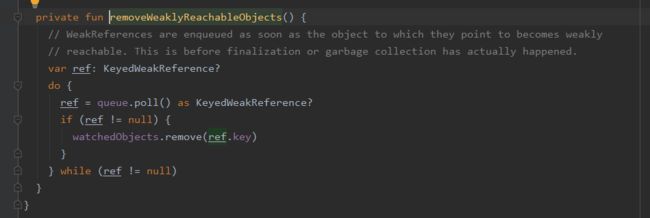
首先检测保留的弱引用对象个数是否大于0,如果大于0,移除ReferenceQueue中记录的KeyedWeakReference对象,主动触发GC,回收不可达对象。
②第二次移除不可达对象:经过一次GC后只有WeakReference持有的对象回收,调用ReferenceQueue的poll方法,remove掉watcheObjects这个Map中记录的KeyedWeakReference对象。
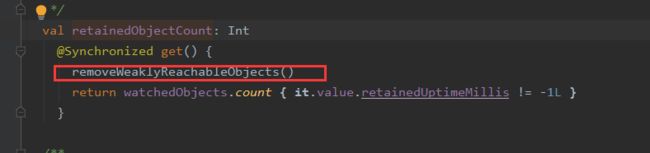
③判断是否还有剩余的监听对象存活,且存过的个数是否超过阈值,默认值是5.(值越大,dump的次数越少,可能会错过一些泄漏点)

④如果满足上述的条件,调用HeapDumpTrigger的dumpHeap方法,其内部调用系统的Debug.dumpHprofData方法,抓取Hprof文件。
⑤启动异步的HeapAnalyzerService分析hprof文件,找到泄漏的GCRoot链路,这个一个前台Service。
⑥调用shark库的HeapAnalyzer进行hprof文件的分析
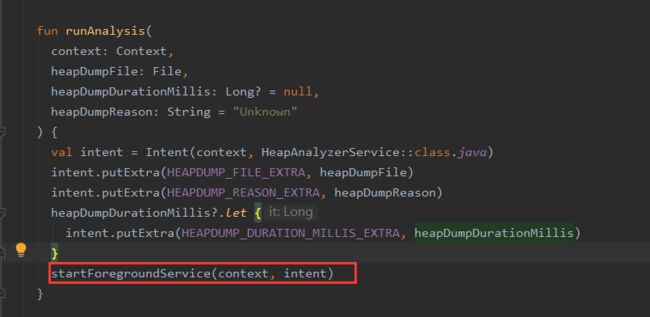
⑦当解析完毕后,调用onAnalysisProgress方法显示前台通知。

//TODO Fragment部分待解析
24 BlockCanary 原理解析
25.LifeCycle原理解析
基本使用
①实现LifecycleObserver接口
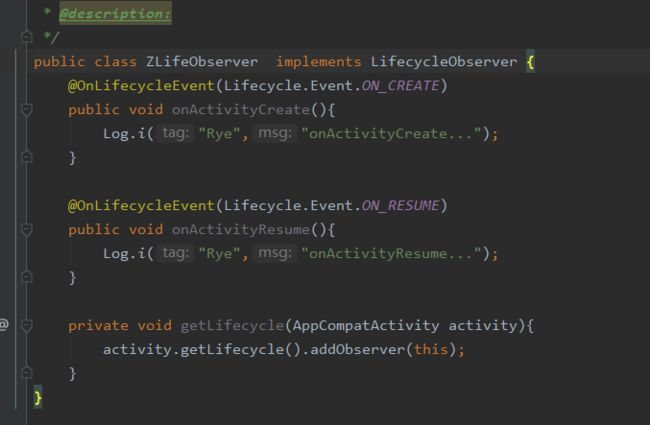
②在ComponentActivity中添加此接口:
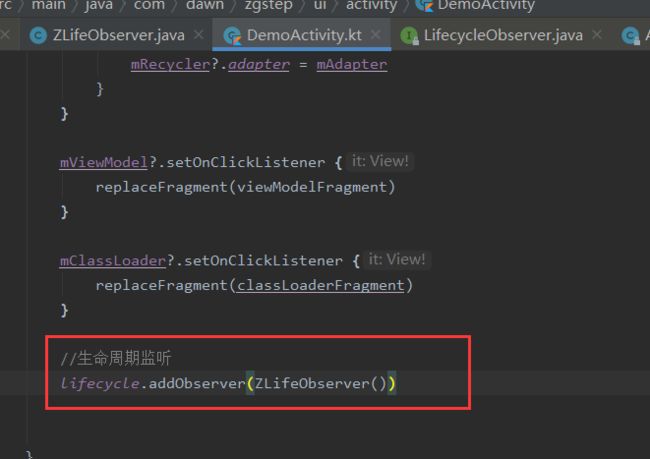
这样,我们只要在需要监听activity声明周期的地方拿到Activity对象,就可以添加LifecycleObserver来监听activity生命周期了。使用起来十分方面。
下面分析其原理
Lifecycle原理解析
总结基于lifecycle2.2.0,博客是2.0
Lifecycle原理解析
①Lifecycle是个抽象类,其中有两个枚举类:Event和State。
State指的是Lifecycle的生命周期所处的状态
Event代表Lifecycle生命周期对应的事件,会映射到Activity和Fragment的生命周期回调事件中。
②对于生命周期回调处理是在ComponentActivity中,AppCompatActivity继承FragmentActivity,FragmentActivity继承ComponentActivity,ComponentActivity继承自Activity。
ComponentActivity中持有LifecycleRegistry,这是Lifecycle的实现类:

ComponentActivity的各个生命周期方法中没有改变Lifecycle的State,而是在onCreate中调用ReportFragment的injectIfNeededIn(activity)方法,将任务委托给ReportFragment进行处理。
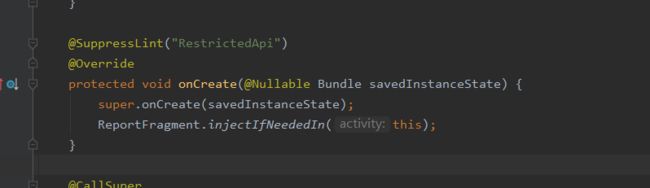
在Fragment的生命周期里会调用dispatch方法通知各个监听器生命周期的变化。
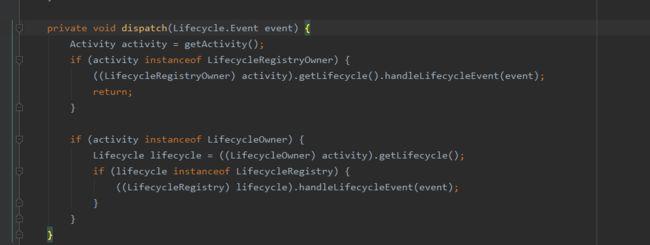
在dispatch方法中,会判断当前Activity是否实现了LifecycleRegistryOwner接口(此接口继承自LifecycleOwner接口,与此区别是前者getLifecycle返回的是Lifecycle的实现类LifecycleRegistry,后者返回的是Lifecycle),如果实现了,就会调用LifecycleRegistry的handleLifecycleEvent。
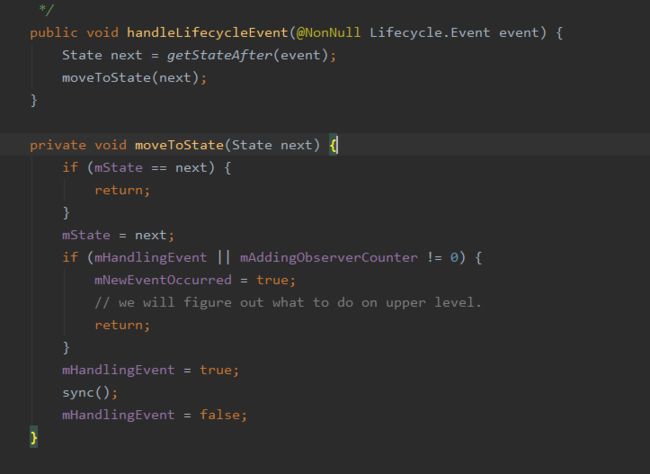

其内部调用的moveToState方法
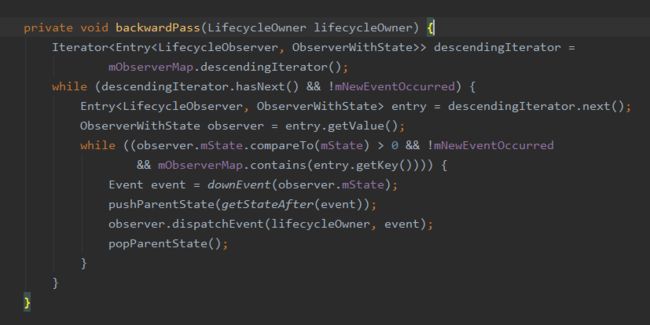
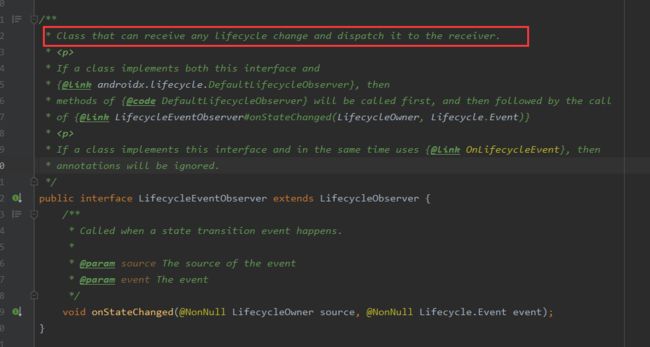
最终会调用到 ObserverWithState里的dispatchEvent,ObserverWithState里持有的LifecycleEventObserver的实现类实际上是ReflectiveGenericLifecycleObserver
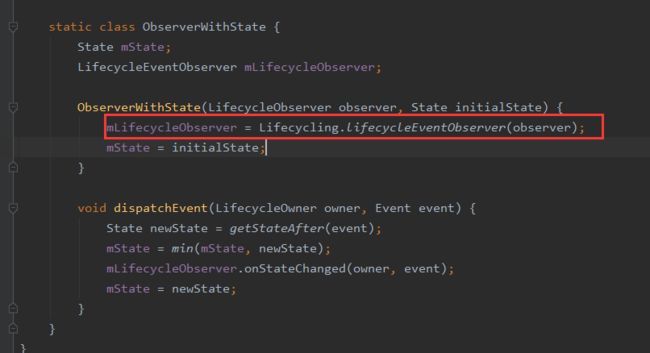

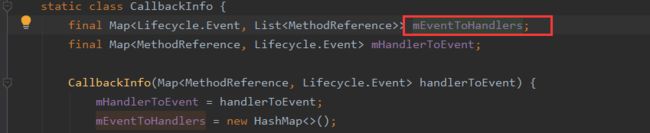
这个类中持有一个CallbackInfo对象:

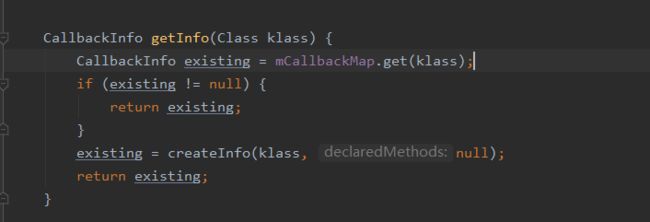
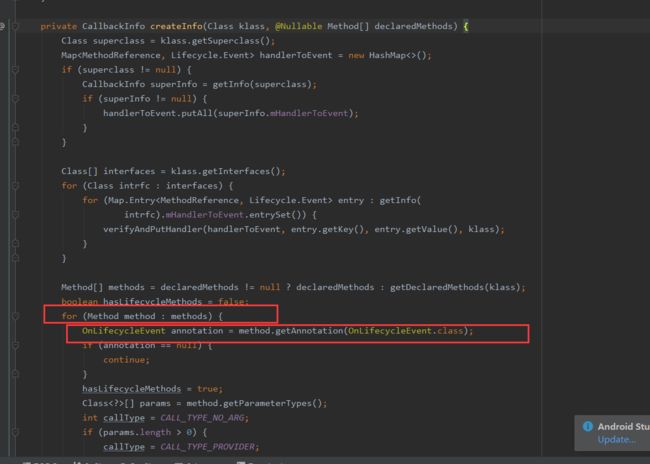
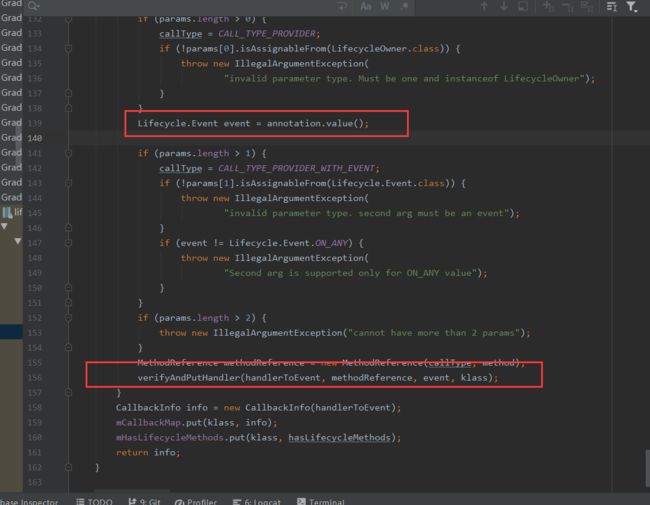
在其构造的时候,会通过反射遍历LifecycleObserver所有的方法,找到所有有OnLifecycleEvent注解的方法,拿到注解里的值;新建MethodReference,将对应方法塞进去,并将所有的MethodReference塞到CallbackInfo的mEventToHandlers中。

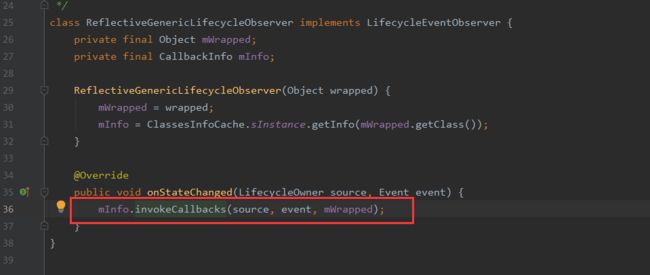
接着回到ReflectiveGenericeLifecycleObserver中,当生命周期发生改变时调用onStateChanged方法,其内部会调用CallbackInfo的invokeCallbacks方法:

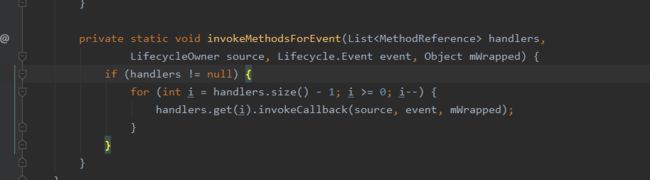
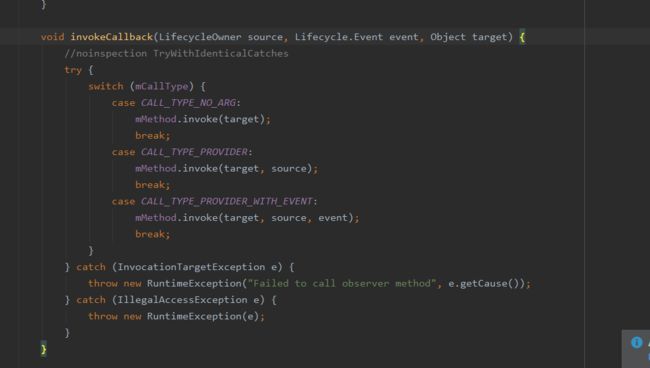
MethodReference类中有两个变量,一个是callType,它代表调用方法的类型,另一个是Method,它代表方法,不管是哪种callType都会通过 invoke对方法进行反射。所以LifecycleObserver中所有带有onLifecycleEvent方法都是通过反射调用的。
总而言之:
实现LifecycleObserver接口的类中,注解修饰的方法和事件会被保存起来,通过反射对事件的对应方法进行调用。
26.ViewModel 原理解析
ViewModel基本使用
①自定义一个ViewModel,继承自ViewModel
②ViewModelProvider,传入ViewModelStoreOwner参数(FragmentActivity已经实现此接口)接着调用其get方法,传入自定义的ViewModel的class名。
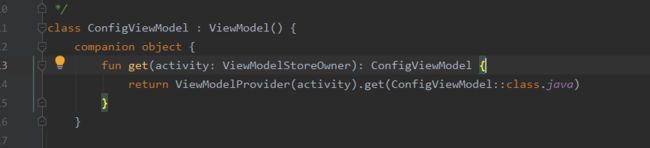
源码分析
①构造方法:ViewModelProvider的构造方法中,需要传入两个参数,一个是ViewModeStore,一个是Factory,后者用默认的即可。


ViewModelStore是通过owner.getViewModelStore方法获取到的。

在CompontActivity、Fragment、FragmentActivity中均实现了此方法。
ViewModelStore对象,是每个Activity或者Fragment都有一个,目的是用于保存该页面的ViewModel对象,方便ViewModel的管理;
ViewModelStore的创建方式有两个:
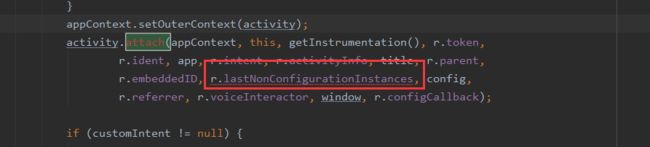
1>通过NonConfigurationInstances获取
2>new出来
NonConfigurationInstance是在ActivityThread中的performLaunchActvity中调用attach方法传进来的,所以一个Activity只有一个。
为什么Activity在配置改变的时候NonConfigurationInstances还能保证ViewModelStore是同一个,也就是ViewModel是同一个呢?
这就需要去页面销毁时排查了,页面销毁时会调用ActivityThread的performDestoryActivity方法:
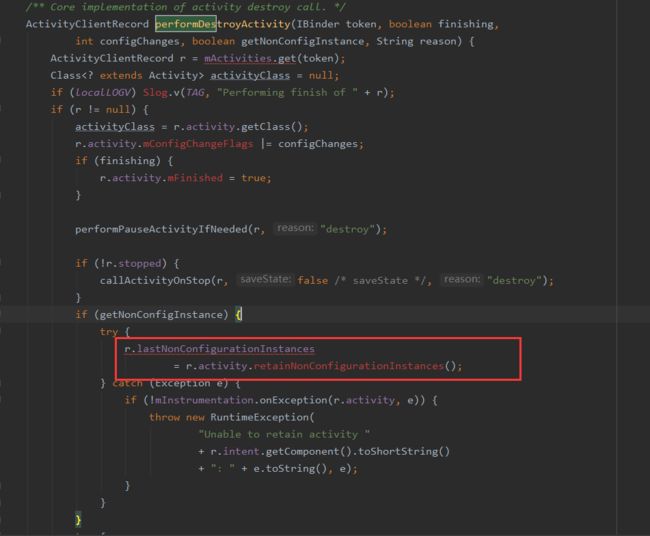
可以看到在执行onStop和onDestory的时候,会将NonConfigurationInstance存储在ActivityClientRecord中(这个里面记录了应用中所有的Activity),
在页面重新启动的时候,走performLaunchActivity,又会从ActivityClientRecord中获取lastNonConfigurationInstance绑定到Activity中;这样对于新的Activity实例来说,还是原来的NonConfigurationInstance,也就是同一个ViewModelStore,通过key也就能获取到同一个ViewModel。
那为什么正常销毁的ViewModel不是同一个对象呢?
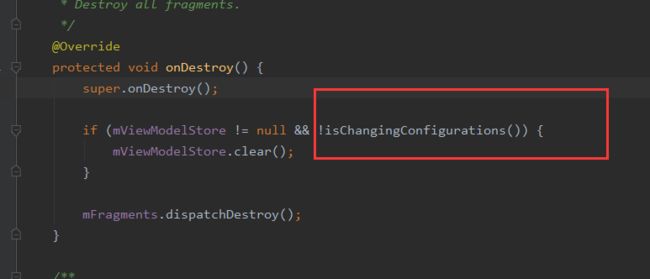
可以看到在FragmentActivity的onDestory中有做判断,如果不是配置导致的Activity销毁,就会清空ViewModelStore,自然也就不是同一个ViewModel了。
同理ComponetActivity和Fragment。
ViewModelStore是互不影响的,一个Activity的ViewModelStore并不会影响到另一个ViewModelStore里的内容。(不同的Activity对应的NonConfigurationInstance)
调用ViewModelProvider的构造方法时,会创建ViewModelStore并赋值给ViewModelProvider的mViewModelStore对象。
在ViewModelStore中,有一个键值对,ViewModel实际上是以HashMap
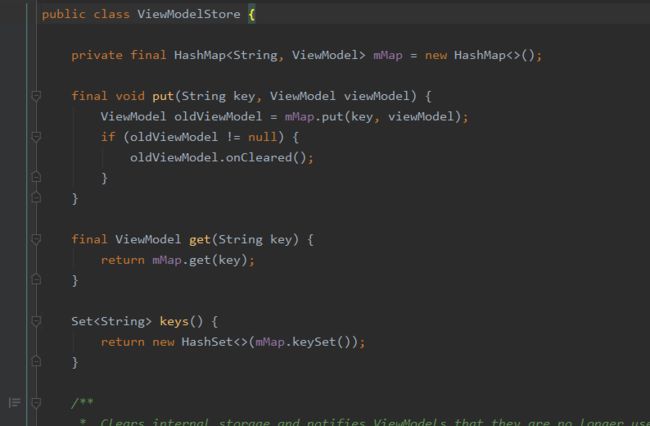
②get方法
就是传入了ViewModel的Class对象,以当前Class的java规范名为key去ViewModelStore中查找对应的ViewModel,如果缓存中有则返回对应的ViewModel;如果没有,则通过Factory创建ViewModel,并缓存到ViewModelStore中的HashMap中并返回。
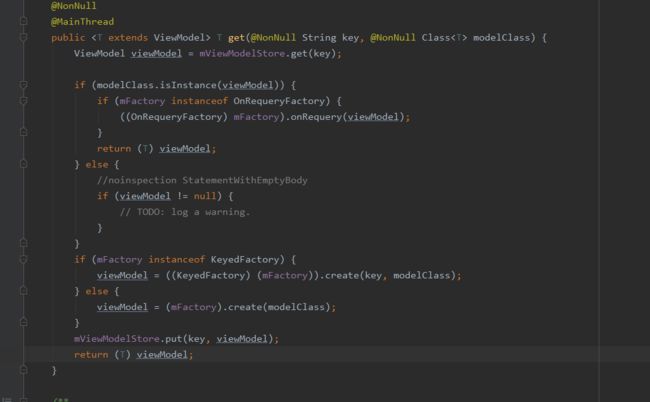
③可以看到ViewModel独立于Activity存在,所以Activity由于配置变化导致销毁重建并不会影响ViewModel。
注意点及相关问题
①ViewModel中不要持有View、Fragment或者Activity,我们知道ViewModel的生命周期要比它们要长(发生屏幕旋转的情况下),所以不能在ViewModel内部持有它们的引用,不然会发生内存泄漏。
②ViewModel和onSaveInstanceState()方法异同
onSaveInstanceState方法只能保存少量的能支持序列化的数据,而ViewModel没有这个限制。
ViewModel不支持数据的持久化,当界面被彻底销毁时,ViewModel及其持有的数据就不存在了。但onSaveInstanceState方法没有这个限制,它可以持久化页面的数据。
27. LiveData详解及原理解析
LiveData原理解析
LiveData特点:
1)采用观察者模式,数据发生改变,可以自动回调(比如更新UI)。
2)不需要手动处理生命周期,不会因为Activity的销毁重建而丢失数据。
3)不会出现内存泄漏。
4)不需要手动取消订阅,Activity在非活跃状态下(pause、stop、destroy之后)不会收到数据更新信息。
原理解析
LiveData是一个抽象类,其实现是MutableLiveData。
(1)postValue和setValue区别:
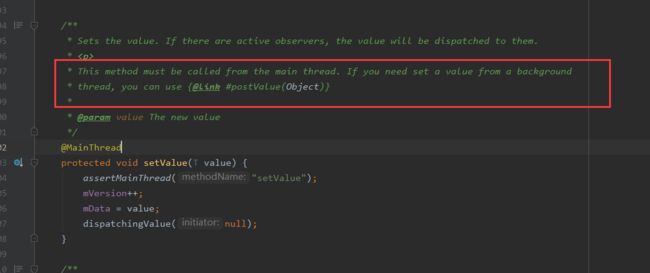
如图, setValue只能在主线程中调用,postValue在主线程和子线程中都可以调用
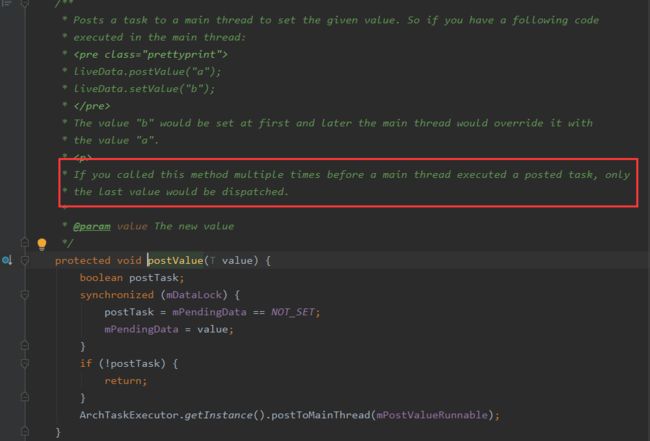
当多次调用postValue时,只有最后一次是生效的。
(2)LiveData如何观察组件生命周期(observe方法)
LiveData原理解析-刘望舒
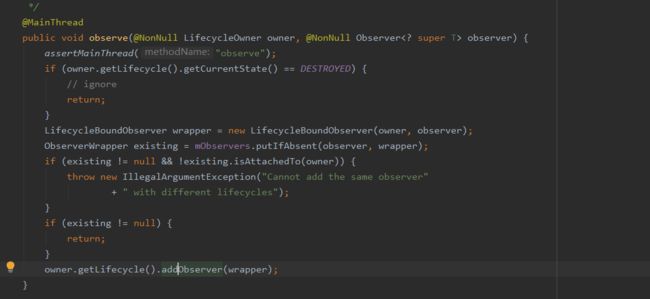
如何观察者的状态是DESTROYED,则直接忽略。否则新建一个Lifecycle的包装类LifecycleBoundObserver,将owner和observer传递进去。
接着将Observer和Lifecycle的包装类存到SafeIterableMap
如果等于null,就会将LifecycleBoundObserver添加到Lifecycle中进行注册,这样我们调用LiveData的observe方法时,实际上是LiveData内部完成了Lifecycle的观察者添加,也就能观察到组件的生命周期变化。
LifecycleBoundObserver是LiveData的一个内部类,其内部持有一个LifecycleOwner对象(LifecycleOwner能拿到当前Activity或者Fragment的生命周期状态)
LifecycleBoundObserver实现了LifecycleEventObserver接口,实现了onStateChanged方法,这样一来Fragment或者Activity生命周期发生改变时,就可以收到通知。当组件处于DESTROYED状态时,会移除observer。这样一来就解释了为什么一个观察者组件处于DESTORYED状态时,它将不会接收到通知。

ANR
ANR详解
ANR根本原因:
基于Handler消息机制来完成的。在一个事件执行开始时,通过Handler去post一个对应时间的延迟消息,如果事件在规定事件内执行完成,就remove掉这个message,否则,Handler就会收到这个ANR的Message,做进一步处理,dump日志,弹出ANR对话框。
场景
Service Timeout:前台服务在20s内未执行完成,后台服务200s;
BroadcastQueue Timeout:前台广播在10s内未执行完成,后台广播60s
ContentProvider Timeout:内容提供者执行超时
InputDispatching Timeout: 输入事件分发超时5s,包括按键分发事件的超时。
分析方法
在/data/anr/traces.txt文件中写入ANR相关信息.最新的ANR信息在最开始部分。
traces文件在/data/anr/目录下
如果手机已经root:可以直接通过adb pull /data/anr/traces.txt d:/导出
没有root:通过adb bugreport E:\bugs导出(可行)
trance.txt文件内容
ANR的进程id、时间和进程名称。
线程的基本信息
线程的优先级(默认5)、线程锁id和线程状态
线程的调用栈信息(这里可查看导致ANR的代码调用流程,分析ANR最重要的信息)
可能导致ANR的原因
IO操作,如数据库、文件、网络
CPU不足,一般是别的App占用了大量的CPU,导致App无法及时处理
硬件操作,如camera
线程问题,如主线程被join/sleep,或wait锁等导致超时
Service问题,如service忙导致超时无响应,或service binder的数量达到上限
system server问题,如WatchDog发现ANR