一、 实验目的
构造 LR(1)分析程序,利用它进行语法分析,判断给出的符号串是否为该文法识别的句子,了解 LR(K)分析方法是严格的从左向右扫描,和自底向上的语法分析方法。
二、 描述 LR(1)语法分析程序的设计思想
1. 拓广文法
假定文法是一个以为开始符号的文法,我们构造一个,它包含了整个,但它引进了一个不出现在中的非终结符,并加进一个新产生式,而是的开始符号。那么,我们称是的拓广文法。这样,便会有一个仅含项目的状态,这便是唯一的接受态。
2. 提取所有有效识别活前缀的式子:
形式上我们说一个LR(1)项目对于活前缀是有效的,如果存在规范推导
其中,① ;② a是的 第一个符号,或者a为#而 为 。
若 对活前缀 是有效的,则对于每个形如 的产生式, 对任何的 , 对 也是有效的。
3. 构造项目集I的闭包CLOSURE(I):
假定是一个项目集,它的闭包可按如下方式构造:
(1) 的任何项目都属于。
(2) 若项目属于,是一个产生式,那么,对于中的每个终结符,如果原来不在中,则把它加进去。
(3) 重复执行步骤2,直至不再增大为止。
4. 构造GO(I, X)
令是一个项目集,是一个文法符号,函数定义为
其中
5. 构造LR(1)项目集族C
关于文法的LR(1)项目集族的构造算法是:

6.分析表构造:
假设,令每个的下标为分析表的状态,令含有的的为分析器的初态。动作和状态转换可构造如下:
(1) 若项目属于且,为终结符,则置为“把状态和符号移入栈”,简记为""。
(2) 若项目属于,则置为“用产生式规约”,简记为"",其中假定为文法的第个产生式。
(3) 若项目属于,则置为“接受”,简记为""。
(4) 若,则置。
(5) 分析表中凡不能用规则1至4填入信息的空白栏均填上“出错标志”。
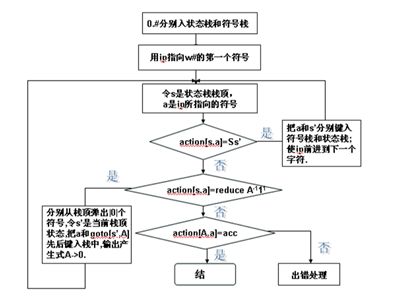
三、 LR分析器详细的算法描述
LR分析器的总控程序本身的工作是比较简单的。它的任何一步只需按照栈顶状态和现行输入符号执行所规定的动作。不管什么分析表,总控程序都是一样的工作。
一个LR分析器的工作过程可以看成是栈里的状态序列、已规约串和输入串所构成的三元式的变化过程。分析开始时的初始三元式是
其中,为分析器的初态; 为句子的左括号; 为输入串;其后的为结束符(句子右括号)。分析过程的每步结果可以表示为
分析器的下一步动作是由栈顶状态和现行输入符号所唯一确定的。即,执行所规定的动作。经执行每种动作后,三元式的变化情况是:
(1) 若为移进,且,则三元式变成
(2) 若为使用规约,则三元式变成
其中,,为的长度,
(3) 若为接受,则三元式不再变化,宣布分析成功
(4) 若为报错,则三元式的变化过程终止,报告错误。
用流程图表示如下:
四、 源代码
(1) LR1Project.java
package exp3;
import exp2.grammer.symbol.GrammerSymbol;
import exp2.grammer.symbol.GrammerSymbols;
import java.util.Objects;
/**
* LR(1)项目
*
* @version 2020-06-07
*/
public class LR1Project implements Comparable {
/** 产生式左部 */
public final GrammerSymbol left;
/** 产生式右部 */
public final GrammerSymbols right;
/** 圆点的位置 */
public final int pos;
/** 向前搜索的符号 */
public final GrammerSymbol forward;
/**
* 构造LR(1)项目
*
* @param left 产生式左部
* @param right 产生式右部
* @param pos 圆点的位置
* @param forward 向前搜索符
*/
public LR1Project(GrammerSymbol left, GrammerSymbols right, int pos, GrammerSymbol forward) {
this.left = left;
this.right = right;
this.pos = pos;
this.forward = forward;
}
@Override
public String toString() {
return "[" + left +
"->" +
right.subSequence(0, pos) +
"·" +
right.subSequence(pos) +
", " + forward +
']';
}
@Override
public int compareTo(LR1Project o) {
int cmp = this.left.compareTo(o.left);
if (cmp != 0) return cmp;
cmp = this.right.compareTo(o.right);
if (cmp != 0) return cmp;
cmp = Integer.compare(this.pos, o.pos);
if (cmp != 0) return cmp;
return this.forward.compareTo(o.forward);
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
LR1Project that = (LR1Project) o;
return this.toString().equals(that.toString());
}
@Override
public int hashCode() {
return Objects.hash(left, right, pos, forward);
}
}
(2) LR1Action.java
package exp3;
import java.util.Objects;
/**
* LR(1)文法的动作
*
* @version 2020-06-14
*/
public class LR1Action {
/** 动作类型编号,0为s,1为r,2为acc */
public final static int PUSHSTACK = 0;
public final static int REDUCE = 1;
public final static int ACCEPT = 2;
/** 动作类型 */
public int type;
/** 当为进栈操作时,表示把状态j放入栈中;当为规约操作时,表示使用第j个产生式进行规约 */
public int j;
/**
* 根据类型构造动作,应当为接受动作的构造方法,也就是type应为2
*
* @param type 类型,应为2,也就是ACCEPT
*/
public LR1Action(int type) {
this.type = type;
}
/**
* 根据类型构造动作,不应当为接受动作的构造方法
*
* @param type 类型,应为0和1,也就是PUSHSTACK和REDUCE
* @param j 当为进栈操作时,表示把状态j放入栈中;当为规约操作时,表示使用第j个产生式进行规约
*/
public LR1Action(int type, int j) {
this.type = type;
this.j = j;
}
@Override
public String toString() {
switch (this.type) {
case PUSHSTACK: return "s" + this.j;
case REDUCE: return "r" + this.j;
case ACCEPT: return "acc";
default: return "error";
}
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
LR1Action lr1Action = (LR1Action) o;
return type == lr1Action.type &&
j == lr1Action.j;
}
@Override
public int hashCode() {
return Objects.hash(type, j);
}
}
(3) LR1Grammer.java
package exp3;
import exp2.grammer.Grammer;
import exp2.grammer.exception.GrammerException;
import exp2.grammer.symbol.*;
import exp2.util.Pair;
import java.util.*;
import static exp2.grammer.symbol.GrammerSymbol.*;
import static java.util.AbstractMap.SimpleImmutableEntry;
/**
* LR(1)文法
*
* @version 2020-06-14
*/
public class LR1Grammer extends Grammer {
/* 文法的Fisrt集合 */
Map> FirstSets;
/* 文法的Follow集合 */
Map> FollowSets;
/** LR(1)文法中的所有项目 */
Set allProjects;
/** LR(1)文法的项目集族 */
List> C;
/** ACTION表 */
Map> ACTION;
/** GOTO表 */
Map> GOTO;
/** (有序的)产生式列表 */
List> ProdList;
/**
* 从文法产生式输入构造一个文法
*
* @param src 文法输入
*/
public LR1Grammer(String src) {
this(src.split("(\r\n)|(\n)|(\r)"));
}
/**
* 从文法产生式字符串数组构造一个文法
*
* @param srcs 文法字符串数组
*/
public LR1Grammer(String[] srcs) {
super(srcs);
this.FirstSets = this.generateFirstSets();
this.FollowSets = this.generateFollowSets();
this.allProjects = this.generateProjects();
this.C = this.generateC();
this.ProdList = this.generateProdList();
SimpleImmutableEntry>, Map>> Tables = this.generateActionTableAndGotoTable();
this.ACTION = Tables.getKey();
this.GOTO = Tables.getValue();
}
/**
* 根据一个已经存在的文法构造一个副本
*
* @param grammer 已经存在的文法
*/
public LR1Grammer(Grammer grammer) {
super(grammer);
this.FirstSets = this.generateFirstSets();
this.FollowSets = this.generateFollowSets();
this.allProjects = this.generateProjects();
this.C = this.generateC();
this.ProdList = this.generateProdList();
SimpleImmutableEntry>, Map>> Tables = this.generateActionTableAndGotoTable();
this.ACTION = Tables.getKey();
this.GOTO = Tables.getValue();
}
/**
* 从开始符号和产生式集合构造文法
*
* @param S 开始符号
* @param Productions 产生式集合
*/
public LR1Grammer(GrammerSymbol S, Map> Productions) {
super(S, Productions);
this.FirstSets = this.generateFirstSets();
this.FollowSets = this.generateFollowSets();
this.allProjects = this.generateProjects();
this.C = this.generateC();
this.ProdList = this.generateProdList();
SimpleImmutableEntry>, Map>> Tables = this.generateActionTableAndGotoTable();
this.ACTION = Tables.getKey();
this.GOTO = Tables.getValue();
}
/**
* 产生文法的所有终结符和非终结符的First集合
*
* @return 由文法符号作为键,文法符号对应的First集合作为值的键值对构成的映射
*/
private Map> generateFirstSets() {
Map> FirstSets = new TreeMap<>();
Set firstX;
/* 规则1 若X∈Vt, 则First(X) = {X}*/
for (GrammerSymbol X : this.getVt()) {
firstX = new TreeSet<>();
firstX.add(X);
FirstSets.put(X, firstX);
}
/* 规则2 若X∈Vn, 且有产生式X->a...,则把a加入到First(X)中 */
for (GrammerSymbol X : this.getVn()) {
firstX = new TreeSet<>();
FirstSets.put(X, firstX);
Set Productions = this.getProductions().get(X);
if (Productions == null) continue;
for (GrammerSymbols production : Productions) {
GrammerSymbol a = production.get(0);
if (GrammerSymbol.isTerminal(a))
firstX.add(a);
}
}
/* 连续使用规则3,直至每个文法符号的First集不再增大为止.
规则3-1 若X->Y...是一个产生式,且Y∈Vn,则把Fisrt(Y)中的所有非ε-元素都加到FIRST(X)中;
规则3-2 若X->Y_1Y_2...Y_k是一个产生式,Y_1,⋯,Y_(i-1)都是非终结符,而且,
对于任何j,1≤j≤i-1,First(Y_j)都含有ε(即Y_1Y_2...Y_(i-1)=*=>ε),则把First(Y_j )中的所有非ε-元素都加到First(X)中;
规则3-3 特别是,若所有的First(Y_j)均含有ε,j=1,2,⋯,k,则把ε加到First(X)中。
*/
boolean modified = true;
while (modified) {
modified = false;
for (GrammerSymbol X : this.getProductions().keySet()) {
firstX = FirstSets.get(X);
Set Productions = this.getProductions().get(X);
Label1:
for (GrammerSymbols production : Productions) {
/* 规则3-1 */
GrammerSymbol Y = production.get(0);
if (GrammerSymbol.isTerminal(Y)) continue;
Set firstY = new TreeSet<>(FirstSets.get(Y));
firstY.remove(GS_EPSILON);
int fslen = firstX.size();
firstX.addAll(firstY);
modified |= (fslen != firstX.size());
if (!FirstSets.get(Y).contains(GS_EPSILON)) continue;
/* 规则3-2 */
for (int i = 1; i < production.length(); ++i) {
Y = production.get(i);
if (GrammerSymbol.isTerminal(Y)) continue Label1;
firstY = new TreeSet<>(FirstSets.get(Y));
firstY.remove(GS_EPSILON);
fslen = firstX.size();
firstX.addAll(firstY);
modified |= (fslen != firstX.size());
if (!FirstSets.get(Y).contains(GS_EPSILON)) continue Label1;
}
/* 规则3-3 */
fslen = firstX.size();
firstX.add(GS_EPSILON);
modified |= (fslen != firstX.size());
}
}
}
return FirstSets;
}
/**
* 产生文法的所有非终结符的Follow集合
*
* @return 由文法符号作为键,文法中非终结符对应的Follow集合作为值的键值对构成的映射
*/
private Map> generateFollowSets() {
Map> FollowSets = new TreeMap<>();
Set FollowSet;
for (GrammerSymbol gs : this.getVn()) {
FollowSet = new TreeSet<>();
FollowSets.put(gs, FollowSet);
}
/* 规则1 对于文法的开始符号S,置#于FOLLOW(S)中; */
FollowSets.get(this.getS()).add(new GrammerSymbol("#"));
boolean modified = true;
/* 连续使用规则2和3,直至每个Follow集不再增大为止. */
while (modified) {
modified = false;
for (GrammerSymbol A : getProductions().keySet()) {
Set Productions = this.getProductions().get(A);
for (GrammerSymbols production : Productions) {
GrammerSymbol B;
Set followB;
int fslen;
for (int i = 0; i < production.length() - 1; ++i) {
/* 规则2 若A→αBβ是一个产生式,则把FIRST(β)\{ε}加至FOLLOW(B)中; */
B = production.get(i);
if (GrammerSymbol.isTerminal(B)) continue;
followB = FollowSets.get(B);
GrammerSymbols beta = production.subSequence(i + 1, production.length());
Set fisrtSetBeta = this.FirstSet(beta);
boolean firstSetBetaHasEpsilon = fisrtSetBeta.contains(GS_EPSILON);
fisrtSetBeta.remove(GS_EPSILON);
fslen = followB.size();
followB.addAll(fisrtSetBeta);
modified |= (fslen != followB.size());
/* 规则3-1 若A→αBβ是一个产生式而β→ε (即εFirst(β)),则把Follow(A)加至Follow(B)中。 */
if (firstSetBetaHasEpsilon) {
fslen = followB.size();
followB.addAll(FollowSets.get(A));
modified |= (fslen != followB.size());
}
}
/* 规则3-2 若A→αB是一个产生式,则把Follow(A)加至Follow(B)中。 */
B = production.get(production.length() - 1);
if (GrammerSymbol.isTerminal(B)) continue;
followB = FollowSets.get(B);
fslen = followB.size();
followB.addAll(FollowSets.get(A));
modified |= (fslen != followB.size());
}
}
}
return FollowSets;
}
/**
* 产生文法的所有LR(1)项目
*
* @return 所有的LR(1)项目
*/
private Set generateProjects() {
Set result = new TreeSet<>();
Set Vt = new TreeSet<>(this.getVt());
Vt.remove(GS_EPSILON);
Vt.add(new GrammerSymbol("#"));
Map> productions = this.getProductions();
for (GrammerSymbol left : productions.keySet()) {
Set rights = productions.get(left);
for (GrammerSymbols right : rights) {
for (int i = 0; i <= right.length(); ++i) {
for (GrammerSymbol forward : Vt) {
result.add(new LR1Project(left, right, i, forward));
}
}
}
}
return result;
}
/**
* 生成项目集族C
*
* @return 项目集族C
*/
private List> generateC() {
/* 找到文法中的所有符号 */
Set allSymbols = new TreeSet<>(this.getVn());
allSymbols.addAll(this.getVt());
allSymbols.remove(GS_EPSILON);
/* 采用LinkedHashSet来实现Set的首位元素即为分析器的初态 */
LinkedHashSet> result = new LinkedHashSet<>();
Set startSet = new TreeSet<>();
startSet.add(new LR1Project(new GrammerSymbol("S'"), new GrammerSymbols("S"), 0, new GrammerSymbol("#")));
result.add(this.Closure(startSet));
boolean modified = true;
while (modified) {
modified = false;
int fslen;
Set> C = new HashSet<>(result);
for (Set I : C) {
for (GrammerSymbol X : allSymbols) {
Set go_I_X = GO(I, X);
if (go_I_X.size() > 0) {
fslen = result.size();
result.add(go_I_X);
modified |= (fslen != result.size());
}
}
}
}
return new ArrayList<>(result);
}
/**
* 生成产生式列表
*
* @return 产生式列表
*/
private List> generateProdList() {
List> result = new ArrayList<>();
GrammerSymbol S_ = new GrammerSymbol("S'");
GrammerSymbol S = new GrammerSymbol("S");
Map> productions = this.getProductions();
Set lefts = new TreeSet<>(productions.keySet());
lefts.remove(S_);
lefts.remove(S);
List leftlist = new ArrayList<>();
leftlist.add(S_);
leftlist.add(S);
leftlist.addAll(lefts);
for (GrammerSymbol left : leftlist) {
Set rights = productions.get(left);
for (GrammerSymbols right : rights) {
result.add(new Pair<>(left, right));
}
}
return result;
}
/**
* 生成规范LR(1)分析表
*
* @return 规范LR(1)分析表
*/
private SimpleImmutableEntry>, Map>> generateActionTableAndGotoTable() {
Map> ActionTable = new TreeMap<>();
Map> GotoTable = new TreeMap<>();
for (int i = 0; i < this.C.size(); ++i) {
ActionTable.put(i, new TreeMap<>());
GotoTable.put(i, new TreeMap<>());
}
for (int i = 0; i < this.C.size(); ++i) {
Set I = C.get(i);
for (LR1Project project : I) {
GrammerSymbols right = project.right;
GrammerSymbol a = right.get(project.pos);
if (a != null && isTerminal(a)) {
int j = this.C.indexOf(GO(I, a));
LR1Action action = new LR1Action(LR1Action.PUSHSTACK, j);
if (!ActionTable.get(i).containsKey(a)) ActionTable.get(i).put(a, action);
else if (!ActionTable.get(i).get(a).equals(action))
throw new GrammerException("这个文法的LR(1)分析表含有多重定义入口,不是LR(1)的。");
}
else if (a == null) {
if (project.left.toString().equals("S'")) {
LR1Action action = new LR1Action(LR1Action.ACCEPT);
if (!ActionTable.get(i).containsKey(project.forward)) ActionTable.get(i).put(project.forward, action);
else if (!ActionTable.get(i).get(project.forward).equals(action))
throw new GrammerException("这个文法的LR(1)分析表含有多重定义入口,不是LR(1)的。");
}
else {
int j = ProdList.indexOf(new Pair<>(project.left, project.right));
LR1Action action = new LR1Action(LR1Action.REDUCE, j);
if (!ActionTable.get(i).containsKey(project.forward)) ActionTable.get(i).put(project.forward, action);
else if (!ActionTable.get(i).get(project.forward).equals(action))
throw new GrammerException("这个文法的LR(1)分析表含有多重定义入口,不是LR(1)的。");
}
}
}
for (GrammerSymbol A : this.getVn()) {
Set go_I_A = this.GO(I, A);
if (go_I_A.size() > 0) {
int j = this.C.indexOf(go_I_A);
if (!GotoTable.get(i).containsKey(A)) GotoTable.get(i).put(A, j);
else if (GotoTable.get(i).get(A).equals(j))
throw new GrammerException("这个文法的LR(1)分析表含有多重定义入口,不是LR(1)的。");
}
}
}
return new SimpleImmutableEntry<>(ActionTable, GotoTable);
}
/**
* 返回对应文法字符串的First集合
*
* @param production 文法字符串
* @return 文法字符串production对应的First集合
*/
public Set FirstSet(GrammerSymbols production) {
/* 构造文法的一个任何符号串α的First集合 */
/* 规则1 置First(α)=First(X_1)\{ε}; */
GrammerSymbol gsY = production.get(0);
if (gsY.toString().equals("#")) {
Set result = new TreeSet<>();
result.add(new GrammerSymbol("#"));
return result;
}
Set result = new TreeSet<>(this.FirstSets.get(gsY));
Set fsgsY;
result.remove(GS_EPSILON);
if (!FirstSets.get(gsY).contains(GS_EPSILON)) return result;
/* 规则2 若对于任何1≤j≤i-1,ε∈FIRST(X_j),则把FIRST(X_i)\{ε}加至FIRST(α)中; */
for (int i = 1; i < production.length(); ++i) {
gsY = production.get(i);
fsgsY = new TreeSet<>(FirstSets.get(gsY));
fsgsY.remove(GS_EPSILON);
result.addAll(fsgsY);
if (!FirstSets.get(gsY).contains(GS_EPSILON)) return result;
}
/* 规则3 特别是,若所有的First(Y_j)均含有ε,1≤j≤n,则把ε加到First(α)中。 */
result.add(GS_EPSILON);
return result;
}
/**
* CLOSURE(I)
*
* @param I 项目集
* @return CLOSURE(I)
*/
public Set Closure(Set I) {
/* (1) I的任何项目都属于CLOUSURE(I) */
Set result = new TreeSet<>(I);
/* (3) 重复执行步骤(2),直至CLOSURE(I)不再增大为止 */
boolean modified = true;
/* (2) 若项目[A→·αBβ,a]属于CLOSURE(I),B→ξ是一个产生式,那么,对于FIRST(βa)中的每个终结符b
如果[B→·ξ,b]原来不在CLOSURE(I)中,则把它加进去 */
while (modified) {
modified = false;
int fslen;
Set backup = new TreeSet<>(result);
for (LR1Project project : backup) {
if (project.right.get(project.pos) != null && isNonterminal(project.right.get(project.pos))) {
GrammerSymbol B = project.right.get(project.pos);
GrammerSymbols beta = project.right.subSequence(project.pos + 1);
GrammerSymbol a = project.forward;
Set first_beta_a = FirstSet(new GrammerSymbols(beta+a.toString()));
for (GrammerSymbol b : first_beta_a) {
for (GrammerSymbols rightProduction : this.getProductions().get(B)) {
fslen = result.size();
result.add(new LR1Project(B, rightProduction, 0, b));
modified |= (fslen != result.size());
}
}
}
}
}
return result;
}
/**
* GO(I, X)
*
* @param I 项目集
* @param X 文法符号
* @return GO(I, X)=CLOSURE(J),其中J={任何形如[A→αX·β,a]的项目|[A→α·Xβ,a]∈I}
*/
public Set GO(Set I, GrammerSymbol X) {
Set J = new TreeSet<>();
for (LR1Project project : I) {
GrammerSymbols right = project.right;
GrammerSymbols XA = new GrammerSymbols(X.toString());
int rightPos = right.indexOf(X);
while (rightPos >= 0) {
if (rightPos == project.pos) {
J.add(new LR1Project(project.left, project.right, rightPos+1, project.forward));
}
rightPos = right.indexOf(XA, rightPos + 1);
}
}
return this.Closure(J);
}
public Map> getFirstSets() {
return FirstSets;
}
public Map> getFollowSets() {
return FollowSets;
}
@Override
public Map> getProductions() {
return super.getProductions();
}
@Override
public GrammerSymbol getS() {
return super.getS();
}
@Override
public Set getVn() {
return super.getVn();
}
public List> getProdList() {
return ProdList;
}
public List> getC() {
return C;
}
public Map> getGOTO() {
return GOTO;
}
public Map> getACTION() {
return ACTION;
}
public Set getAllProjects() {
return allProjects;
}
@Override
public Set getVt() {
return super.getVt();
}
public static void main(String[] args) {
String[] srcs1 = {
"S'->S",
"S->BB",
"B->aB",
"B->b"
};
String[] srcs2 = {
"S'->S",
"S->S+T",
"E->T",
"T->T*F",
"T->F",
"F->(S)",
"F->i"
};
LR1Grammer lr1Grammer = new LR1Grammer(srcs1);
lr1Grammer = new LR1Grammer(srcs2);
}
@Override
public String toString() {
return "LR1Grammer{" +
"FirstSets=" + FirstSets +
", FollowSets=" + FollowSets +
", allProjects=" + allProjects +
", C=" + C +
", ACTION=" + ACTION +
", GOTO=" + GOTO +
", ProdList=" + ProdList +
'}';
}
}
(4) LR1Parser.java
package exp3;
import exp2.grammer.Grammer;
import exp2.grammer.LL1Grammer;
import exp2.grammer.exception.GrammerException;
import exp2.grammer.symbol.GrammerSymbol;
import exp2.grammer.symbol.GrammerSymbols;
import exp2.util.Pair;
import exp2.util.Quartet;
import java.util.*;
import static exp3.LR1Action.*;
/**
* LR(1)语法分析器
*
* @version 2020-06-15
*/
public class LR1Parser {
/* 某个LL(1)文法 */
final LR1Grammer grammer;
/**
* 从某个一个存在的LL(1)文法构造LL(1)预测分析程序
*
* @param grammer 已经存在的LL(1)文法
*/
public LR1Parser(LR1Grammer grammer) {
this.grammer = grammer;
}
/**
* 从某个一个存在的文法构造LL(1)预测分析程序
*
* @param grammer 已经存在的文法
* @throws GrammerException 如果这个文法不是LL(1)的
*/
public LR1Parser(Grammer grammer) { this.grammer = new LR1Grammer(grammer); }
/**
* 采用给定的LL(1)文法{@link #grammer}分析字符串
*
* @param string 要分析的字符串
* @return 分析结果
*/
public List> parseString(String string) {
return parseGrammerSymbols(new GrammerSymbols(string));
}
/**
* 采用给定的LL(1)文法{@link #grammer}分析输入的文法符号序列
*
* @param input 要分析的文法符号序列
* @return 分析结果
*/
public List> parseGrammerSymbols(GrammerSymbols input) {
/* 状态栈, 符号栈, 剩余输入串, 动作 */
List> snap = new LinkedList<>();
String inputString = input.toString();
Stack symbolStack = new Stack<>();
Stack stateStack = new Stack<>();
GrammerSymbol EOI = new GrammerSymbol("#");
GrammerSymbols Epsilon = new GrammerSymbols(Collections.singletonList(GrammerSymbol.GS_EPSILON));
/* 把#推入符号栈中 */
symbolStack.add(EOI);
/* 把初态推入状态栈中,初态按照实现,应当为项目集的第一个 */
stateStack.add(0);
snap.add(new Quartet<>(stateStack.toString(), symbolStack.toString(), inputString, "初始化"));
int index = 0;
GrammerSymbol a;
Set curState;
int curStateID;
LR1Action action;
String actionString;
boolean flag = true;
while (flag) {
/* 栈顶状态 */
curState = this.grammer.C.get(stateStack.peek());
/* 栈顶状态的标号 */
curStateID = this.grammer.C.indexOf(curState);
/* 现行输入符号a */
a = input.get(index);
/* 目前的动作 */
action = this.grammer.ACTION.get(curStateID).get(a);
switch (action.type) {
case PUSHSTACK: {
actionString = "状态" + action.j + "和符号" + a + "入栈";
stateStack.add(action.j);
symbolStack.add(a);
++index;
break;
}
case REDUCE: {
Pair prod = this.grammer.ProdList.get(action.j);
actionString = "用" + prod.value1 + "->" + prod.value2 +"规约";
int r = prod.value2.length();
for (int i = r-1; i >= 0; --i) {
GrammerSymbol curs = prod.value2.get(i);
GrammerSymbol symbolStackPeek = symbolStack.pop();
if (!curs.equals(symbolStackPeek)) {
flag = false;
actionString = "分析错误";
break;
}
stateStack.pop();
}
if (!flag) break;
symbolStack.add(prod.value1);
stateStack.add(this.grammer.GOTO.get(stateStack.peek()).get(prod.value1));
break;
}
case ACCEPT: {
flag = false;
actionString = "分析成功";
break;
}
default: {
flag = false;
actionString = "分析错误";
break;
}
}
/* 记录结果 */
snap.add(new Quartet<>(stateStack.toString(), symbolStack.toString(), inputString.substring(index), actionString));
}
return snap;
}
public LR1Grammer getGrammer() {
return grammer;
}
public static void main(String[] args) {
String[] srcs = {
"S'->S",
"S->BB",
"B->aB",
"B->b"
};
LR1Grammer lr1Grammer = new LR1Grammer(srcs);
LR1Parser parser = new LR1Parser(lr1Grammer);
List> snap = parser.parseString("aabab#");
System.out.println(snap);
System.out.println(snap.size());
}
}