预备知识
1. 核心
- 物理核:CPU中包含的物理内核(核心)个数,比如多核CPU,单核CPU。cpu cores记录了对应的物理CPU有多少个物理核;
- 逻辑核:所谓的4核8线程,4核指的是物理核心。用Intel的超线程技术(HT, Hyper-Threading)将物理核虚拟而成的逻辑处理单元。用一个物理核模拟两个虚拟核,即每个核两个线程,总数为8线程。
- 多核CPU:多核CPU是多个单核CPU的替代方案,多核CPU减小了体积,同时也减少了功耗。
2. 进程和线程
| 对比 | 进程 | 线程 |
|---|---|---|
| 定义 | 进程是程序运行的一个实体的运行过程,是系统进行资源分配和调配的一个独立单位 | 线程是进程运行和执行的最小调度单位 |
| 系统开销 | 创建撤销切换开销大,资源要重新分配和收回 | 仅保存少量寄存器的内容,开销小,在进程的地址空间执行代码 |
| 拥有资产 | 资源拥有的基本单位 | 基本上不占资源,仅有不可少的资源(程序计数器,一组寄存器和栈) |
| 调度 | 资源分配的基本单位 | 独立调度分配的单位 |
| 安全性 | 进程间相互独立,互不影响 | 线程共享一个进程下面的资源,可以互相通信和影响 |
| 地址空间 | 系统赋予的独立的内存地址空间 | 由相关堆栈寄存器和和线程控制表TCB组成,寄存器可被用来存储线程内的局部变量 |
线程切换:CPU给线程分配时间片(也就是分配给线程的时间),执行完时间片后会切换都另一个线程。从保存线程A的状态再到切换到线程B时,重新加载线程B的状态的这个过程就叫上下文切换。
线程开销:上下文切换消耗、线程创建和消亡的开销、线程需要保存维持线程本地栈,会消耗内存。
线程数量选择:计算密集型,CPU的利用率高,不用开太多的线程;IO密集型,因为IO操作会阻塞线程,CPU利用率不高,可以开多点线程。
java程序是跑在JVM实例上的。JVM本身是一个多线程的程序,当JVM启动执行时就是在操作系统中启动了一个JVM进程。我们编写的java单线程或多线程应用进程都是在JVM这个程序中作为一个或多个线程运行。
JVM启动时,必然会创建以下5个线程:
- main:主线程,执行我们指定的启动类的main方法
- Reference Handler:处理引用的线程
- Finalizer:调用对象的finalize方法的线程,就是垃圾回收的线程
- Signal Dispatcher:分发处理发送给JVM信号的线程
- Attach Listener:负责接收外部的命令的线程
虚拟化
虚拟化(技术)(Virtualization)是一种资源管理技术,是将计算机的各种实体资源(CPU、内存、磁盘空间、网络适配器等),予以抽象、转换后呈现出来并可供分割、组合为一个或多个电脑配置环境。
- 按虚拟的对象分类:虚拟机、虚拟内存、存储虚拟化、网络虚拟化等等;
- 按照抽象程度分类:指令集架构等级的虚拟化、硬件抽象层等级的虚拟化、操作系统等级的虚拟化等等。
 虚拟技术按抽象程度来分为五个层次
虚拟技术按抽象程度来分为五个层次
虚拟机(Virtual machine或VM)可以像真实机器一样运行程序的计算机的软件实现。广义来说,虚拟机是一种模拟系统,即在软件层面上通过模拟硬件的输入和输出,让虚拟机的操作系统得以运行在没有物理硬件的环境中(也就是宿主机的操作系统上),其中能够模拟出硬件输入输出,让虚拟机的操作系统可以启动起来的程序,被叫做hypervisor。

单纯模拟硬件的输入输出,效率是很差的。如果我们不模拟硬件输入输出,只是做下真实硬件输入输出的搬运工,那么虚拟机的指令执行速度,就可以和宿主机一致了。当然这前提是宿主机的硬件架构必须和虚拟硬件架构一致。
在linux上模拟windows,这个windows的运行速度基本上和原生装一个windows速度差不多,因为windows也能被直接安装在电脑上。但对于在windows系统中运行android系统不管用,因为android系统的运行硬件一般是手机(arm系统,不同的硬件架构体系和cpu指令集),所以android模拟机还是一样的慢。
容器
其实我们创建虚拟机也不一定需要模拟硬件的输入和输出,假如宿主机和虚拟机他们的kernel是一致的,就不用做硬件输入输出的搬运工了,只需要做kernel输入输出的搬运工即可,为了有别于硬件层面的虚拟机,这种虚拟机被命名为「操作系统层虚拟化」,也被叫做容器。
Docker
Docker的出现一定是因为目前的后端在开发和运维阶段确实需要一种虚拟化技术解决开发环境和生产环境环境一致的问题,排除因为环境造成不同运行结果的可能。
 Docker
Docker
1. Namespaces
命名空间(namespaces)是 Linux 为我们提供的用于分离进程树、网络接口、挂载点以及进程间通信等资源的方法。我们没有运行多个完全分离的服务器的需要,但是希望运行在同一台机器上的不同服务能做到完全隔离。Docker 其实就通过 Linux 的 Namespaces 对不同的容器实现了隔离。
# 进程
- Linux的上帝进程 idle 创建出来两个进程,pid=1 的 /sbin/init 进程,负责执行内核的一部分初始化工作和系统配置;pid=2的 kthreadd 进程,负责管理和调度其他的内核进程。
 Linux系统进程
Linux系统进程
 Docker系统进程
Docker系统进程- 创建新进程时传入 CLONE_NEWPID ,使用命名空间实现进程的隔离,Docker 容器内部的任意进程都对宿主机器的进程一无所知。当我们每次运行 docker run 或者 docker start 时,都会在下面的方法中创建一个用于设置进程间隔离的 Spec。
func (daemon *Daemon) createSpec(c *container.Container) (*specs.Spec, error) {
s := oci.DefaultSpec()
// ...
if err := setNamespaces(daemon, &s, c); err != nil {
return nil, fmt.Errorf("linux spec namespaces: %v", err)
}
return &s, nil
}
# 网络
- Docker 可以通过宿主机的网络与整个互联网相连,提供了四种不同的网络模式,Host、Container、None 和 Bridge 模式。
默认的网络模式是网桥模式, Docker在主机上启动之后会创建新的虚拟网桥 docker0,随后在该主机上启动的全部服务在默认情况下都与该网桥相连。docker0 会为每一个容器分配一个新的 IP 地址并将 docker0 的 IP 地址设置为默认的网关。网桥 docker0 通过 iptables 中的配置与宿主机器上的网卡相连,所有符合条件的请求都会通过 iptables 转发到 docker0 并由网桥分发给对应的机器。
 网桥模式
网桥模式
 容器内部端口的数据包转发
容器内部端口的数据包转发容器的网络模型由 Sandbox、Endpoint 和 Network组件组成。每一个容器内部都包含一个 Sandbox,其中存储着当前容器的网络栈配置,包括容器的接口、路由表和 DNS 设置,Linux 使用网络命名空间实现这个 Sandbox,每一个 Sandbox 中都可能会有一个或多个 Endpoint,在 Linux 上就是一个虚拟的网卡 veth。
 容器的网络模型
容器的网络模型为了避免Docker容器中的进程能够访问或者修改宿主机器上的其他目录,我们需要在新的进程中创建隔离的挂载点命名空间需要在 clone 函数中传入 CLONE_NEWNS,这样子进程就能得到父进程挂载点的拷贝(如果不传入这个参数子进程对文件系统的读写都会同步回父进程以及整个主机的文件系统)。
如果一个容器需要启动,那么它一定需要提供一个根文件系统(rootfs),容器需要使用这个文件系统来创建一个新的进程,同时挂载几个特定的目录,并建立一些符号链接保证系统 IO 不会出现问题。
 rootfs中挂载的特定目录
rootfs中挂载的特定目录
 符号链接
符号链接- 在 Linux 系统中,系统默认的目录就都是以 / 也就是根目录开头的,chroot 的使用能够改变当前的系统根目录结构,通过改变当前系统的根目录,我们能够限制用户的权利,在新的根目录下并不能够访问旧系统根目录的结构个文件,也就建立了一个与原系统完全隔离的目录结构;
2. Control Groups
 命名空间不能为我们提供物理资源上的隔离
命名空间不能为我们提供物理资源上的隔离
CGroup 是 Control Groups 的缩写,是 Linux 内核提供的一种可以限制、记录、隔离进程组 (process groups) 所使用的物力资源 (如CPU、内存、磁盘 I/O 和网络带宽等等) 的机制。每一个 CGroup 都是一组被相同的标准和参数限制的进程,不同的 CGroup 之间是有层级关系的,也就是说它们之间可以从父类继承一些用于限制资源使用的标准和参数。
 从父类继承用于限制资源使用的标准和参数
从父类继承用于限制资源使用的标准和参数
所有的资源控制都是以 CGroup 作为单位实现的,每一个进程都可以随时加入一个 CGroup 也可以随时退出一个 CGroup。9c3057f 其实就是我们运行的一个 Docker 容器,启动这个容器时,Docker 会为这个容器创建一个与容器标识符相同的 CGroup,在当前的主机上 CGroup 就会有以下的层级关系:
 CGroup的层级关系
CGroup的层级关系
每一个 CGroup 下面都有一个 tasks 文件,其中存储着属于当前控制组的所有进程的 pid,作为负责 cpu 的子系统,cpu.cfs_quota_us 文件中的内容能够对 CPU 的使用作出限制,如果当前文件的内容为 50000,那么当前控制组中的全部进程的 CPU 占用率不能超过 50%。当我们使用 Docker 关闭掉正在运行的容器时,Docker 的子控制组对应的文件夹也会被 Docker 进程移除。
$ docker run -it -d --cpu-quota=50000 busybox
53861305258ecdd7f5d2a3240af694aec9adb91cd4c7e210b757f71153cdd274
$ cd 53861305258ecdd7f5d2a3240af694aec9adb91cd4c7e210b757f71153cdd274/
$ ls
cgroup.clone_children cgroup.event_control cgroup.procs cpu.cfs_period_us cpu.cfs_quota_us cpu.shares cpu.stat notify_on_release tasks
$ cat cpu.cfs_quota_us
50000
3. Union FileSystem
Docker 镜像本质就是一个压缩包。Docker 使用了一系列不同的存储驱动管理镜像内的文件系统并运行容器,Docker 中的每一个镜像都是由一系列只读的层组成的,Dockerfile 中的每一个命令都会在已有的只读层上创建一个新的层,当镜像被 docker run 命令创建时就会在镜像的最上层添加一个可写的层,也就是容器层,所有对于运行时容器的修改其实都是对这个容器读写层的修改。
 一个拥有四层 layer 的镜像
一个拥有四层 layer 的镜像
每一个镜像层都是建立在另一个镜像层之上的,同时所有的镜像层都是只读的,只有每个容器最顶层的容器层才可以被用户直接读写,所有的容器都建立在一些底层服务(Kernel)上,包括命名空间、控制组、rootfs 等等,这种容器的组装方式提供了非常大的灵活性,只读的镜像层通过共享也能够减少磁盘的占用。
 组装过程
组装过程
容器和镜像的区别就在于,所有的镜像都是只读的,而每一个容器其实等于镜像加上一个可读写的层,也就是同一个镜像可以对应多个容器。
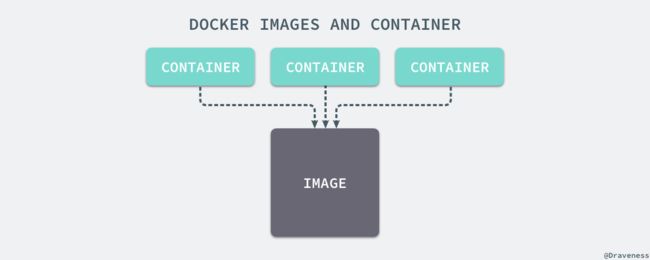 容器和镜像的区别
容器和镜像的区别
容器的管理

容器部署时代: 容器具有轻量级的隔离属性,可以在应用程序之间共享操作系统(OS),具有自己的文件系统、CPU、内存、进程空间等。由于它们与基础架构分离,因此可以跨云和 OS 分发进行移植。主要优势:
- 敏捷应用程序的创建和部署:与使用 VM 镜像相比,提高了容器镜像创建的简便性和效率。
- 持续开发、集成和部署:通过快速简单的回滚( ),提供可靠且频繁的容器镜像构建和部署。
- 关注开发与运维的分离:在构建/发布时而不是在部署时创建应用程序容器镜像,从而将应用程序与基础架构分离。
- 可观察性不仅可以显示操作系统级别的信息和指标,还可以显示应用程序的运行状况和其他指标信号。
- 跨开发、测试和生产的环境一致性:在便携式计算机上与在云中相同地运行。
- 云和操作系统分发的可移植性:可在 Ubuntu、RHEL、CoreOS、本地、Google Kubernetes Engine 和其他任何地方运行。
- 以应用程序为中心的管理:提高抽象级别,从在虚拟硬件上运行 OS 到使用逻辑资源在 OS 上运行应用程序。
- 松散耦合、分布式、弹性、解放的微服务:应用程序被分解成较小的独立部分,并且可以动态部署和管理 - 而不是在一台大型单机上整体运行。
- 资源隔离:可预测的应用程序性能。
- 资源利用:高效率和高密度
Kubernetes
提供:
- 服务发现和负载均衡
Kubernetes 可以使用 DNS 名称或自己的 IP 地址公开容器,如果到容器的流量很大,Kubernetes 可以负载均衡并分配网络流量,从而使部署稳定。 - 存储编排
Kubernetes 允许您自动挂载您选择的存储系统,例如本地存储、公共云提供商等。 - 自动部署和回滚
您可以使用 Kubernetes 描述已部署容器的所需状态,它可以以受控的速率将实际状态更改为所需状态。例如,您可以自动化 Kubernetes 来为您的部署创建新容器,删除现有容器并将它们的所有资源用于新容器。 - 自动二进制打包
Kubernetes 允许您指定每个容器所需 CPU 和内存(RAM)。当容器指定了资源请求时,Kubernetes 可以做出更好的决策来管理容器的资源。 - 自我修复
Kubernetes 重新启动失败的容器、替换容器、杀死不响应用户定义的运行状况检查的容器,并且在准备好服务之前不将其通告给客户端。 - 密钥与配置管理
Kubernetes 允许您存储和管理敏感信息,例如密码、OAuth 令牌和 ssh 密钥。您可以在不重建容器镜像的情况下部署和更新密钥和应用程序配置,也无需在堆栈配置中暴露密钥
集群
集群是一组节点(物理服务器或者虚拟机),之上安装了Kubernetes。
 Kubernetes架构图
Kubernetes架构图
- Kubernetes的三种IP
- Node IP:是Kubernetes集群中节点的物理网卡IP地址(一般为内网),属于这个网络的服务器之间都可以直接通信,所以Kubernetes集群外要想访问Kubernetes集群内部的某个节点或者服务,肯定得通过Node IP进行通信。
- Pod IP是每个Pod的IP地址,它是Docker Engine根据docker0网桥的IP地址段进行分配的。
- Cluster IP是一个虚拟的IP,仅仅作用于Kubernetes Service这个对象,由Kubernetes自己来进行管理和分配地址,当然我们也无法ping这个地址,他没有一个真正的实体对象来响应,他只能结合Service Port来组成一个可以通信的服务,相当于VIP地址,来代理后端服务。
- Pod
安排在节点上,包含一组容器和卷。同一个Pod里的容器共享同一个网络命名空间,可以使用localhost互相通信。
- Pod是短暂的非持续性实体,可以使用持久化的卷类型,来实现持久化。
- 可以手动创建单个Pod,但是也可以使用Replication Controller使用Pod模板创建出多份拷贝;
- Pod重启时IP地址可能会改变,那么怎么才能从前端容器正确可靠地指向后台容器呢?这时可以使用Service;
- Label
一个Label是attach到Pod的一对键/值对,用来传递用户定义的属性。比如,通过Label(tier=frontend, app=myapp)来标记前端Pod容器,使用Label(tier=backend, app=myapp)标记后台Pod。- Replication Controller
Replication Controller确保任意时间都有指定数量的Pod副本在运行。如果为某个Pod创建了Replication Controller并且指定3个副本,它会创建3个Pod,并且持续监控它们。如果某个Pod不响应,那么Replication Controller会替换它,保持总数为3。如果之前不响应的Pod恢复了,现在就有4个Pod了,那么Replication Controller会将其中一个终止保持总数为3。如果在运行中将副本总数改为5,Replication Controller会立刻启动2个新Pod,保证总数为5。还可以按照这样的方式缩小Pod,这个特性在执行滚动升级时很有用。
[图片上传失败...(image-f20209-1616571163835)]- Service
Service是定义一系列Pod以及访问这些Pod的策略的一层抽象。一个Serivce下面包含的Pod集合一般是由Label Selector来决定的。所以,不用去管Pod如何变化(只要服务中的 Pod 集合发生更改,Endpoints 就会被更新),只需要指定Service的地址就可以了,因为我们在中间添加了一层服务发现的中间件,Pod销毁或者重启后,把这个Pod的地址注册到这个服务发现中心去。Service的这种抽象就可以帮我们达到这种解耦的目的。
- Kubernetes会为Service创建一个本地集群的DNS入口,因此前端Pod只需要DNS查找主机名就能够解析出前端应用程序可用的IP地址。
- Service在多个后台Pod之间提供透明的负载均衡,会将请求分发给其中的任意一个。通过每个Node上运行的代理(kube-proxy)完成。
[图片上传失败...(image-996db-1616571163835)]- Node
节点是物理或者虚拟机器,作为Kubernetes worker,通常称为Minion。每个节点都运行如下Kubernetes关键组件:
 Kubelet架构
Kubelet架构
- Kubelet:是主节点代理,负责与容器运行时交互的。CRI shim是实现CRI接口(Container Runtime Interface,容器运行时接口规范)的gRPC server服务,负责连接Kubelet和Container runtime。Container runtime是容器运行时工具,它为用户进程隔离出一个独立的运行环境。每一个容器引擎只需要自己实现一个CRI shim,对CRI请求进行处理,就可以接入Kubelet当中去;
- Kube-proxy:在Kubernetes集群中,每个Node会运行一个kube-proxy进程,负责为Service实现一种 VIP(虚拟 IP,就是clusterIP)的代理形式。默认使用iptables这种模式来代理。
- Docker或Rocket:Kubernetes使用的容器技术来创建容器。
OCI规范(Open Container Initiative 开放容器标准),该规范包含两部分内容:容器运行时标准(runtime spec)、容器镜像标准(image spec);
 OCI规范
OCI规范- Kubernetes Master
集群拥有一个Kubernetes Master。Kubernetes Master提供集群的独特视角,并且拥有一系列组件,比如Kubernetes API Server。API Server提供可以用来和集群交互的REST端点。master节点包括用来创建和复制Pod的Replication Controller。
Kubernetes的日志采集方式
 K8S的日志采集方式
K8S的日志采集方式
- 原生方式
使用 kubectl logs 直接在查看本地保留的日志,或者通过docker engine的 log driver 把日志重定向到文件、syslog、fluentd等系统中。原生方式相对功能太弱,一般不建议在生产系统中使用,否则问题调查、数据统计等工作很难完成。- DaemonSet方式
在K8S的每个node上部署日志agent,由agent采集所有容器的日志到服务端。资源占用要小很多,但扩展性、租户隔离性受限,比较适用于功能单一或业务不是很多的集群。- Sidecar方式
一个POD中运行一个sidecar的日志agent容器,用于采集该POD主容器产生的日志。资源占用较多,但灵活性以及多租户隔离性较强,建议大型的K8S集群或作为PAAS平台为多个业务方服务的集群使用该方式。DaemonSet、Sidecar这两种模式均基于Logtail实现,日志服务客户端Logtail目前已有百万级部署,每天采集上万应用、数PB的数据,历经考验。可以参考:采集标准Docker容器日志
趋势展望
1. Service Mesh
第一代微服务
分布式系统特有的通信语义出现了,如熔断策略、负载均衡、服务发现、认证和授权、quota限制、trace和监控等等,于是服务根据业务需求来实现一部分所需的通信语义。
 第一代微服务
第一代微服务第二代微服务
一些面向微服务架构的开发框架如Twitter的Finagle、Facebook的Proxygen以及Spring Cloud等,这些框架实现了如负载均衡和服务发现等一套分布式系统通信的语义功能,一定程度上屏蔽了通信细节,使得开发人员使用较少的框架代码就能开发出健壮的分布式系统。
 第二代微服务
第二代微服务第一代Service Mesh
- 虽然第二代框架本身屏蔽了分布式系统通信的一些通用功能实现细节,但开发者却要花更多精力去掌握和管理复杂的框架本身;
- 开发框架通常只支持一种或几种特定的语言,很难做到语言无关;
- 框架以lib库的形式和服务联编,项目依赖复杂,库版本兼容问题棘手,框架库的升级也无法对服务透明,服务会因为和业务无关的lib库升级而被迫升级;
以Linkerd,Envoy,Ngixmesh为代表的Sidecar(边车模式)应运而生,将分布式服务的通信抽象为单独一层,在这一层中实现负载均衡、服务发现、认证授权、监控追踪、流量控制等分布式系统所需要的功能,作为一个和服务对等的代理服务,和服务部署在一起,接管服务的流量;
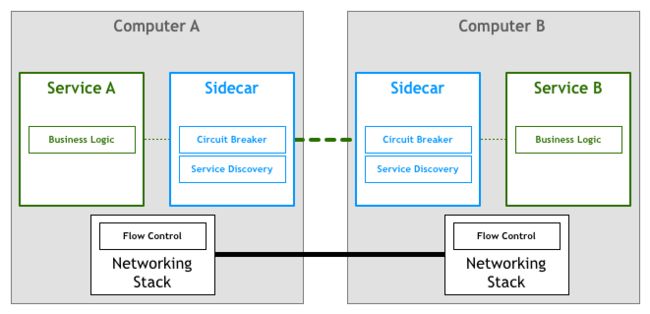 第一代Service Mesh
第一代Service Mesh
 服务网格(由若干服务代理所组成的错综复杂的网格)
服务网格(由若干服务代理所组成的错综复杂的网格)第二代Service Mesh
为了提供统一的上层运维入口,演化出了集中式的控制面板,所有的单机代理组件通过和控制面板交互进行网络拓扑策略的更新和单机数据的汇报。这就是以Istio为代表的第二代Service Mesh。
 第二代Service Mesh
第二代Service Mesh
 控制面板的全局部署视图
控制面板的全局部署视图Service Mesh定义
服务网格是一个基础设施层,用于处理服务间通信。云原生应用有着复杂的服务拓扑,服务网格保证。在实际应用当中,服务网格通常是由一系列轻量级的网络代理组成的,它们与应用程序部署在一起,但。优势:
- 基础设施层+请求在这些拓扑中可靠穿梭,这两个词描述了Service Mesh的定位,Service Mesh屏蔽了分布式系统通信的复杂性(负载均衡、服务发现、认证授权、监控追踪、流量控制等等),服务只用关注业务逻辑。是不是似曾相识?没错,你一定想到了TCP;
- 真正的语言无关,服务可以用任何语言编写,只需和Service Mesh通信即可;
- 对应用透明,描述了Service Mesh的关键特点,Service Mesh组件可以单独升级,正是由于这个特点,Service Mesh能够解决以Spring Cloud为代表的第二代微服务框架所面临的三个本质问题;
挑战:
- Service Mesh组件以代理模式计算并转发请求,一定程度上会降低通信系统性能,并增加系统资源开销;
- Service Mesh组件接管了网络流量,因此服务的整体稳定性依赖于Service Mesh,同时额外引入的大量Service Mesh服务实例的运维和管理也是一个挑战;
2. Serverless
云的时代,硬件软件化和软件服务化成为最显著的两个趋势。
硬件软件化
硬件功能中越来越多的部分由软件来呈现,从而在迭代效率、成本等方面获得显著优势。以软件定义存储(Software Defined Storage,SDS)为例,SDS 是位于物理存储和数据请求之间的一个软件层,允许用户操控数据的存储方式和存储位置。通过硬件与软件解耦,SDS 可运行于行业标准系统或者 X86 系统上,意味着用户可以无差别的使用任何标准的商用服务器来满足不断增长的存储需求。硬件与软件解耦也让 SDS 能够横向扩展,消除容量规划,成本管理等方面的复杂性。软件服务化
应用软件的功能通过网络以远程调用的模式被海量用户使用。服务成为应用构建的基础,API 被实现为服务提供给开发者,微服务架构获得广泛的成功。服务也成为云产品的基本形态。过去 10 年,云已经证明了它的成功。用户只需要通过调用 API 就能获取服务器,而无需自己建设数据中心。算力以前所未有简洁的方式提供给用户。
如果我们把云看作是 DT 时代的计算机,那么一个很自然的问题是:随着云的 API(全托管服务)越来越丰富,什么才是适合于云的编程模型?我们应当以何种 “抽象、解耦、集成” 的方式构建基于云的应用?
 云时代的两个趋势
云时代的两个趋势
基础设施即服务(IaaS)和容器技术是云的基础设施,以 K8S 为代表的容器编排服务是云原生应用的操作系统,面向特定领域的后端服务(BaaS)则是云的 API。为了实现更高的生产力,在存储、数据库、中间件、大数据、AI 等领域,大量的 BaaS 服务是全托管、Serverless 的形态,这一趋势已持续多年。例如现在客户已经非常习惯使用 Serverless 化的对象存储,而不是自己基于服务器搭建数据存储系统。当云提供了丰富的 Serverless BaaS 服务后,需要一种新的通用计算服务,能够屏蔽基础设施的复杂度,基于云服务快速构建应用。因此 Serverless 计算应运而生,它包含了以下要素:
- Serverless 计算是全托管的计算服务,客户编写代码构建应用,无需管理和运维服务器等底层基础设施;
- Serverless 计算是通用、普适的,结合云 API(BaaS 服务)的能力,能够支撑云上所有重要类型的应用;
- Serverless 计算不但实现了最纯粹的按需付费(为代码实际运行消耗的资源付费),也应当支持预付费等计量模式,使得客户成本在各种场景下,与传统方式相比都极具竞争力;
- 不同于虚拟机或容器等面向资源的计算平台,Serverless 计算是面向应用的。要能整合和联动云的产品体系及其生态,帮助用户在价值交付方式上实现颠覆式创新。
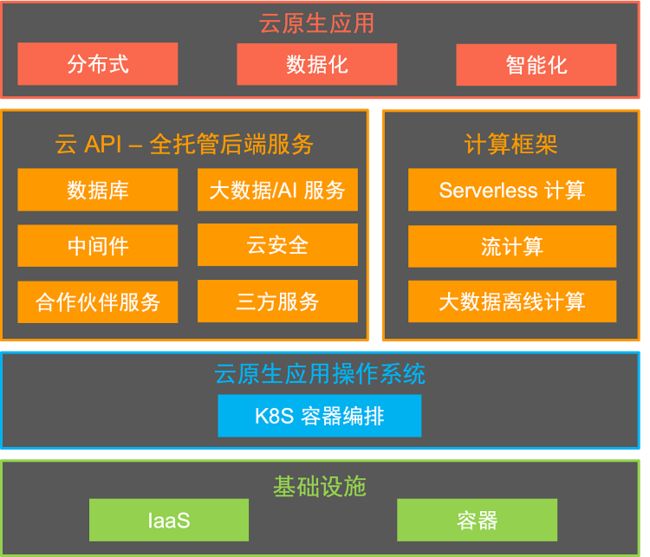 Serverless计算
Serverless计算
Reference
https://draveness.me/docker/
https://kubernetes.io/zh/docs/concepts/overview/what-is-kubernetes/
http://omerio.com/2015/12/18/learn-the-kubernetes-key-concepts-in-10-minutes/
https://kubernetes.io/zh/docs/concepts/overview/components/
https://philcalcado.com/2017/08/03/pattern_service_mesh.html