alloc的流程图
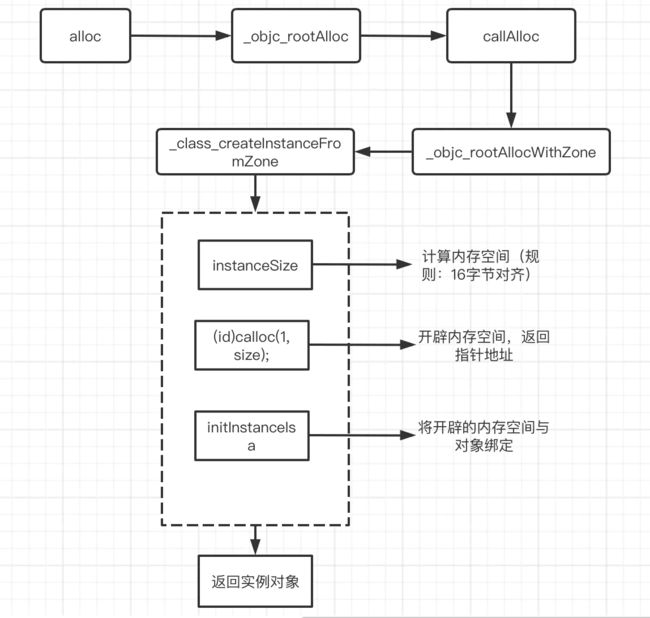
image.png
分析alloc流程图
在main函数中,增加一个自定义对象的定义;
int main(int argc, const char * argv[]) {
@autoreleasepool {
// insert code here...
LGPerson *objc = [[LGPerson alloc] init];
}
return 0;
}
在定义objc对象时,断点停住,通过单步调试的方法进入alloc的源码中。
+ (id)alloc {
return _objc_rootAlloc(self);
}
继续进入_objc_rootAlloc的源码中
id
_objc_rootAlloc(Class cls)
{
return callAlloc(cls, false/*checkNil*/, true/*allocWithZone*/);
}
跳转至callAlloc的源码实现中
static ALWAYS_INLINE id
callAlloc(Class cls, bool checkNil, bool allocWithZone=false)
{
#if __OBJC2__
if (slowpath(checkNil && !cls)) return nil;
if (fastpath(!cls->ISA()->hasCustomAWZ())) {
return _objc_rootAllocWithZone(cls, nil);
}
#endif
// No shortcuts available.
//判断一个类是否有自定义的 +allocWithZone 实现,没有则走到if里面的实现
if (allocWithZone) {
return ((id(*)(id, SEL, struct _NSZone *))objc_msgSend)(cls, @selector(allocWithZone:), nil);
}
return ((id(*)(id, SEL))objc_msgSend)(cls, @selector(alloc));
}
在callAlloc方法里面可以看到if的判断条件,那么fastpath(!cls->ISA()->hasCustomAWZ())都做了什么呢?fastpath又是什么呢?
- fastpath()
#define fastpath(x) (__builtin_expect(bool(x), 1))
#define slowpath(x) (__builtin_expect(bool(x), 0))
/*
编译器指令,允许程序员将最有可能执行的分支告诉编译器,让编译器在生成指令的时候,概率很高的分支指令不需要跳转,而概率低的分支指令需要经过跳转,从而使得大部分情况下都不需要经过跳转,提高执行效率.
(__builtin_expect(bool(x), 1)):表示bool(x)为真的可能性较大
(__builtin_expect(bool(x), 0)):表示bool(x)为假的可能性较大
*/
__builtin_expect(EXP, N)
- cls->ISA()->hasCustomAWZ()
这个函数是用来判断一个类是否有自定义的+allocWithZone方法。 - fastpath(!cls->ISA()->hasCustomAWZ())
这里表示,一个类没有自定义+allocWithZone方法的可能性比较大。
在LGPerson类中没有自定义+allocWithZone,那么callAlloc函数会执行到return _objc_rootAllocWithZone(cls, nil);这里
继续跳转至_objc_rootAllocWithZone源码中。
NEVER_INLINE
id
_objc_rootAllocWithZone(Class cls, malloc_zone_t *zone __unused)
{
// allocWithZone under __OBJC2__ ignores the zone parameter
return _class_createInstanceFromZone(cls, 0, nil,
OBJECT_CONSTRUCT_CALL_BADALLOC);
}
此处仍然需要跳转,跳转至_class_createInstanceFromZone源码实现
static ALWAYS_INLINE id
_class_createInstanceFromZone(Class cls, size_t extraBytes, void *zone,
int construct_flags = OBJECT_CONSTRUCT_NONE,
bool cxxConstruct = true,
size_t *outAllocatedSize = nil)
{
ASSERT(cls->isRealized());
// Read class's info bits all at once for performance
bool hasCxxCtor = cxxConstruct && cls->hasCxxCtor();
bool hasCxxDtor = cls->hasCxxDtor();
bool fast = cls->canAllocNonpointer();
size_t size;
// 1:要开辟多少内存
size = cls->instanceSize(extraBytes);
if (outAllocatedSize) *outAllocatedSize = size;
id obj;
if (zone) {
obj = (id)malloc_zone_calloc((malloc_zone_t *)zone, 1, size);
} else {
// 2;怎么去申请内存
obj = (id)calloc(1, size);
}
if (slowpath(!obj)) {
if (construct_flags & OBJECT_CONSTRUCT_CALL_BADALLOC) {
return _objc_callBadAllocHandler(cls);
}
return nil;
}
// 3: ?
if (!zone && fast) {
obj->initInstanceIsa(cls, hasCxxDtor);
} else {
// Use raw pointer isa on the assumption that they might be
// doing something weird with the zone or RR.
obj->initIsa(cls);
}
if (fastpath(!hasCxxCtor)) {
return obj;
}
construct_flags |= OBJECT_CONSTRUCT_FREE_ONFAILURE;
return object_cxxConstructFromClass(obj, cls, construct_flags);
}
此处是alloc的核心操作,该方法分为三步操作:
- 计算需要开辟的内存空间大小
- 申请内存
- 将申请的内存与isa关联
计算需要开辟的内存空间大小
调用函数cls->instanceSize(extraBytes);计算实例对象需要多少内存空间。
size_t instanceSize(size_t extraBytes) const {
if (fastpath(cache.hasFastInstanceSize(extraBytes))) {
return cache.fastInstanceSize(extraBytes);
}
size_t size = alignedInstanceSize() + extraBytes;
// CF requires all objects be at least 16 bytes.
if (size < 16) size = 16;
return size;
}
通过断点调试,会进入cache.fastInstanceSize方法,快速计算内存大小。跳转至fastInstanceSize的源码实现。
size_t fastInstanceSize(size_t extra) const
{
ASSERT(hasFastInstanceSize(extra));
//Gcc的内建函数 __builtin_constant_p 用于判断一个值是否为编译时常数,如果参数EXP 的值是常数,函数返回 1,否则返回 0
if (__builtin_constant_p(extra) && extra == 0) {
return _flags & FAST_CACHE_ALLOC_MASK16;
} else {
size_t size = _flags & FAST_CACHE_ALLOC_MASK;
// remove the FAST_CACHE_ALLOC_DELTA16 that was added
// by setFastInstanceSize
//删除由setFastInstanceSize添加的FAST_CACHE_ALLOC_DELTA16 8个字节
return align16(size + extra - FAST_CACHE_ALLOC_DELTA16);
}
}
通过断点调试,会执行到align16。
//16字节对齐算法
static inline size_t align16(size_t x) {
return (x + size_t(15)) & ~size_t(15);
}
内存字节对齐原则
- 数据成员对齐规则:struct 或者 union 的数据成员,第一个数据成员放在offset为0的地方,以后每个数据成员存储的起始位置要从该成员大小或者成员的子成员大小(只要该成员有子成员,比如数据、结构体等)的整数倍开始(例如int在32位机中是4字节,则要从4的整数倍地址开始存储)
- 数据成员为结构体:如果一个结构里有某些结构体成员,则结构体成员要从其内部最大元素大小的整数倍地址开始存储(例如:struct a里面存有struct b,b里面有char、int、double等元素,则b应该从8的整数倍开始存储)
- 结构体整体对齐规则:结构体的总大小,即sizeof的结果,必须是其内部做大成员的整数倍,不足的要补齐
16字节对齐
- 通常内存是由一个个字节组成的,cpu在存取数据时,并不是以字节为单位存储,而是以块为单位存取,块的大小为内存存取力度。频繁存取字节未对齐的数据,会极大降低cpu的性能,所以可以通过减少存取次数来降低cpu的开销
- 16字节对齐,是由于在一个对象中,第一个属性isa占8字节,当然一个对象肯定还有其他属性,当无属性时,会预留8字节,即16字节对齐,如果不预留,相当于这个对象的isa和其他对象的isa紧挨着,容易造成访问混乱
- 16字节对齐后,可以加快CPU读取速度,同时使访问更安全,不会产生访问混乱的情况
字节对齐总结
- 在字节对齐算法中,对齐的主要是对象,而对象的本质则是一个 struct objc_object的结构体
- 结构体在内存中是连续存放的,所以可以利用这点对结构体进行强转
- 苹果早期是8字节对齐,现在是16字节对齐
申请内存
当计算出对象的大小时,就可以调用calloc函数申请一段指定size的内存了。
obj = (id)calloc(1, size);
当内存申请成功后,通过lldb输出可以看到obj指向了一段内存空间
(lldb) po obj
0x00000001007645c0
将申请的内存与isa关联
经过calloc可知,内存已经申请好了,类也已经传入进来了,接下来就需要将类与地址指针即isa指针进行关联。
obj->initInstanceIsa(cls, hasCxxDtor);
当申请的内存与isa关联好之后,通过lldb可以看到obj已经是一个对象指针
(lldb) po obj
总结
alloc的主要目的是开辟一段指定大小的内存空间,并将这段内存空间关联到对象的isa指针。