译文出处:https://software.intel.com/en-us/articles/lstm-based-time-series-anomaly-detection-using-analytics-zoo-for-apache-spark-and-bigdl
摘要:宝信和英特尔相关团队利用Analytics Zoo在无监督的基于时间序列异常检测用例上进行了有益的合作探索,本文分享了合作项目的结果和经验。
背景
在工业制造行业,有多种方法来避免由于设备失效导致的生产中断。常见的方法是定期检修维护,或者提前更换设备零部件,这些方法都可能会增加设备维护和更换的投入。然而,另一个可行的方法是收集不同设备的大量振动数据,并使用这些数据自动检测设备状态的异常。因此,有效地收集大量的时间序列数据并且大规模地进行异常和失效检测,对于降低工业制造行业中的的很多不必要的成本是非常关键的。
Recurrent neural networks (RNNs)循环神经网络,特别是Long short term memory models (LSTMs)长短期记忆模型现在被广泛应用于信号处理,时间序列分析等场景。作为connectionist模型,RNNs可以提取网络节点中的动态序列。在这个项目中,我们利用LSTM来模拟震动信号的统计学规律, 并且使用了来自辛辛那提大学的IMS全生命周期数据 (http://ti.arc.nasa.gov/c/3/)来展示设备异常检测的分析流程。
Analytics Zoo解决方案
Analytics Zoo (https://github.com/intel-analytics/analytics-zoo)是一个基于Apache Spark和BigDL等构建的analytics (分析)+AI(人工智能)的平台,由英特尔开源,该平台能够方便地让用户将端到端的基于大数据的深度学习应用直接部署在已有的Hadoop/Spark的大数据集群上,而无需安装专用的GPU设备。
我们已经在Apache Spark和Analytics Zoo上创建了端到端的基于LSTM的异常检测流程,可以应用于大规模时间序列数据的无监督深度学习。作为LSTM模型的输入数据的是一系列设备震动信号,比如在当前时间点之前50秒的信号数据,通过这些信号数据,经过训练的模型可以预测下一个数据点。当下一个数据点和模型预测的数据点有较大偏差,我们认为该数据为异常数据。图1所示为一个端到端的数据处理流程。
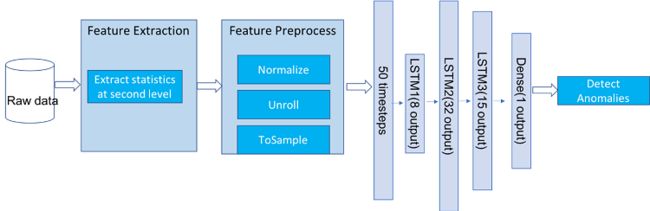
1.处理流程从Spark集群读取原始数据并构造RDD(resilient distributed datasets)弹性分布式数据集,并抽取特征,最后把特征输出到Dataframe。在原始数据集中,每个数据描述了一个检测失效(test-to-failure)的实验,并包含了时长为1秒的20K赫兹采样的即时振动信号(如图2所示)。为了训练深度学习模型,每一秒的统计数据被提取作为特征数据,包括均方根(Root Mean Square), 峰度(Kurtosis),峰值( Peak), 以及小波包分解得到的8个频段的能量值。
2.处理流程进一步在RDD中处理这些特征数据,包括数值的小波去噪处理、标准化处理(normalize)和滑动平均处理,以50秒为基准展开特征数据序列,以便于深度学习模型可以通过前50秒的模式来预测下一个数据点,并最终把数据转换为Sample RDD。(https://bigdl-project.github.io/master/#APIGuide/Data/#sample).
3.处理流程使用Analytics Zoo中提供的类Keras API来创建时间序列异常检测模型,包括如图所示的三个LSTM层和一个密集层,并通过数据训练这个模型(前50个点训练下一个点)。

4.接下来是模型评估:使用测试数据或者全部数据来检测异常。异常数据是指远离RNN模型预测的数据点。在这个项目中,我们指定异常数据为整体数据集的10%,也就是距离模型预测数值最远的那10%数据为异常数据。这个筛选比例设置为可调整参数,可以为每个单独案例进行调整。
测试结果
图3显示了原始振动数据和LSTM模型预测数据的对比。只有峰值和均方根这两个统计数值显示出来,其他统计数值具有相似的波动。图中所示红点为被识别的异常数据,橙色线条为LSTM模型的预测数值,蓝色线条为原始数值。经过训练的模型最终成功预测了设备的失效,以及在经过600个时间点之后的震动尖峰,在时间序列早期的一些波动可以作为设备失效的预警信息。


结论
通过利用无监督深度学习,以及Analytics Zoo提供的端到端处理流程,我们可以有效地在大数据集和标准大数据集群(Hadoop, Spark等)上应用时间序列异常检测。通过收集、处理大量的时间序列数据(比如日志,传感器读数等),应用RNN来学习数据模式,最终预判数据和判定异常数据,Analytics Zoo提供的端到端处理流程能够为许多新兴的智能系统如智能制造、智能运维、物联网等提供解决方案。基于时间序列的异常检测在设备的智能监控和预测性维护上可以得到重要应用。
参考文献
1. https://github.com/intel-analytics/analytics-zoo
2. https://github.com/intel-analytics/BigDL
3. https://www.kaggle.com/victorambonati/unsupervised-anomaly-detection
4. https://iwringer.wordpress.com/2015/11/17/anomaly-detection-concepts-and-techniques/