1. 利用resnet18做迁移学习
import torch
from torchvision import models
if __name__ == "__main__":
# device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
device = 'cpu'
print("-----device:{}".format(device))
print("-----Pytorch version:{}".format(torch.__version__))
input_tensor = torch.zeros(1, 3, 100, 100)
print('input_tensor:', input_tensor.shape)
pretrained_file = "model/resnet18-5c106cde.pth"
model = models.resnet18()
model.load_state_dict(torch.load(pretrained_file))
model.eval()
out = model(input_tensor)
print("out:", out.shape, out[0, 0:10])
结果输出:
input_tensor: torch.Size([1, 3, 100, 100])
out: torch.Size([1, 1000]) tensor([ 0.4010, 0.8436, 0.3072, 0.0627, 0.4446, 0.8470, 0.1882, 0.7012,0.2988, -0.7574], grad_fn=)
如果,我们修改了resnet18的网络结构,如何将原来预训练模型参数(resnet18-5c106cde.pth)迁移到新的resnet18网络中呢?
比如,这里将官方的resnet18的self.layer4 = self._make_layer(block, 512, layers[3], stride=2)改为:self.layer44 = self._make_layer(block, 512, layers[3], stride=2)
class ResNet(nn.Module):
def __init__(self, block, layers, num_classes=1000, zero_init_residual=False):
super(ResNet, self).__init__()
self.inplanes = 64
self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3,
bias=False)
self.bn1 = nn.BatchNorm2d(64)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.layer1 = self._make_layer(block, 64, layers[0])
self.layer2 = self._make_layer(block, 128, layers[1], stride=2)
self.layer3 = self._make_layer(block, 256, layers[2], stride=2)
self.layer44 = self._make_layer(block, 512, layers[3], stride=2)
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.fc = nn.Linear(512 * block.expansion, num_classes)
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
elif isinstance(m, nn.BatchNorm2d):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
# Zero-initialize the last BN in each residual branch,
# so that the residual branch starts with zeros, and each residual block behaves like an identity.
# This improves the model by 0.2~0.3% according to https://arxiv.org/abs/1706.02677
if zero_init_residual:
for m in self.modules():
if isinstance(m, Bottleneck):
nn.init.constant_(m.bn3.weight, 0)
elif isinstance(m, BasicBlock):
nn.init.constant_(m.bn2.weight, 0)
def _make_layer(self, block, planes, blocks, stride=1):
downsample = None
if stride != 1 or self.inplanes != planes * block.expansion:
downsample = nn.Sequential(
conv1x1(self.inplanes, planes * block.expansion, stride),
nn.BatchNorm2d(planes * block.expansion),
)
layers = []
layers.append(block(self.inplanes, planes, stride, downsample))
self.inplanes = planes * block.expansion
for _ in range(1, blocks):
layers.append(block(self.inplanes, planes))
return nn.Sequential(*layers)
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer44(x)
x = self.avgpool(x)
x = x.view(x.size(0), -1)
x = self.fc(x)
return x
这时,直接加载模型:
model = models.resnet18() model.load_state_dict(torch.load(pretrained_file))
这时,肯定会报错,类似:Missing key(s) in state_dict或者Unexpected key(s) in state_dict的错误:
RuntimeError: Error(s) in loading state_dict for ResNet:
Missing key(s) in state_dict: "layer44.0.conv1.weight", "layer44.0.bn1.weight", "layer44.0.bn1.bias", "layer44.0.bn1.running_mean", "layer44.0.bn1.running_var", "layer44.0.conv2.weight", "layer44.0.bn2.weight", "layer44.0.bn2.bias", "layer44.0.bn2.running_mean", "layer44.0.bn2.running_var", "layer44.0.downsample.0.weight", "layer44.0.downsample.1.weight", "layer44.0.downsample.1.bias", "layer44.0.downsample.1.running_mean", "layer44.0.downsample.1.running_var", "layer44.1.conv1.weight", "layer44.1.bn1.weight", "layer44.1.bn1.bias", "layer44.1.bn1.running_mean", "layer44.1.bn1.running_var", "layer44.1.conv2.weight", "layer44.1.bn2.weight", "layer44.1.bn2.bias", "layer44.1.bn2.running_mean", "layer44.1.bn2.running_var".
Unexpected key(s) in state_dict: "layer4.0.conv1.weight", "layer4.0.bn1.running_mean", "layer4.0.bn1.running_var", "layer4.0.bn1.weight", "layer4.0.bn1.bias", "layer4.0.conv2.weight", "layer4.0.bn2.running_mean", "layer4.0.bn2.running_var", "layer4.0.bn2.weight", "layer4.0.bn2.bias", "layer4.0.downsample.0.weight", "layer4.0.downsample.1.running_mean", "layer4.0.downsample.1.running_var", "layer4.0.downsample.1.weight", "layer4.0.downsample.1.bias", "layer4.1.conv1.weight", "layer4.1.bn1.running_mean", "layer4.1.bn1.running_var", "layer4.1.bn1.weight", "layer4.1.bn1.bias", "layer4.1.conv2.weight", "layer4.1.bn2.running_mean", "layer4.1.bn2.running_var", "layer4.1.bn2.weight", "layer4.1.bn2.bias".Process finished with
RuntimeError: Error(s) in loading state_dict for ResNet:
Unexpected key(s) in state_dict: "layer4.0.conv1.weight", "layer4.0.bn1.running_mean", "layer4.0.bn1.running_var", "layer4.0.bn1.weight", "layer4.0.bn1.bias", "layer4.0.conv2.weight", "layer4.0.bn2.running_mean", "layer4.0.bn2.running_var", "layer4.0.bn2.weight", "layer4.0.bn2.bias", "layer4.0.downsample.0.weight", "layer4.0.downsample.1.running_mean", "layer4.0.downsample.1.running_var", "layer4.0.downsample.1.weight", "layer4.0.downsample.1.bias", "layer4.1.conv1.weight", "layer4.1.bn1.running_mean", "layer4.1.bn1.running_var", "layer4.1.bn1.weight", "layer4.1.bn1.bias", "layer4.1.conv2.weight", "layer4.1.bn2.running_mean", "layer4.1.bn2.running_var", "layer4.1.bn2.weight", "layer4.1.bn2.bias".
我们希望将原来预训练模型参数(resnet18-5c106cde.pth)迁移到新的resnet18网络,当然只能迁移二者相同的模型参数,不同的参数还是随机初始化的.
def transfer_model(pretrained_file, model):
'''
只导入pretrained_file部分模型参数
tensor([-0.7119, 0.0688, -1.7247, -1.7182, -1.2161, -0.7323, -2.1065, -0.5433,-1.5893, -0.5562]
update:
D.update([E, ]**F) -> None. Update D from dict/iterable E and F.
If E is present and has a .keys() method, then does: for k in E: D[k] = E[k]
If E is present and lacks a .keys() method, then does: for k, v in E: D[k] = v
In either case, this is followed by: for k in F: D[k] = F[k]
:param pretrained_file:
:param model:
:return:
'''
pretrained_dict = torch.load(pretrained_file) # get pretrained dict
model_dict = model.state_dict() # get model dict
# 在合并前(update),需要去除pretrained_dict一些不需要的参数
pretrained_dict = transfer_state_dict(pretrained_dict, model_dict)
model_dict.update(pretrained_dict) # 更新(合并)模型的参数
model.load_state_dict(model_dict)
return model
def transfer_state_dict(pretrained_dict, model_dict):
'''
根据model_dict,去除pretrained_dict一些不需要的参数,以便迁移到新的网络
url: https://blog.csdn.net/qq_34914551/article/details/87871134
:param pretrained_dict:
:param model_dict:
:return:
'''
# state_dict2 = {k: v for k, v in save_model.items() if k in model_dict.keys()}
state_dict = {}
for k, v in pretrained_dict.items():
if k in model_dict.keys():
# state_dict.setdefault(k, v)
state_dict[k] = v
else:
print("Missing key(s) in state_dict :{}".format(k))
return state_dict
if __name__ == "__main__":
input_tensor = torch.zeros(1, 3, 100, 100)
print('input_tensor:', input_tensor.shape)
pretrained_file = "model/resnet18-5c106cde.pth"
# model = resnet18()
# model.load_state_dict(torch.load(pretrained_file))
# model.eval()
# out = model(input_tensor)
# print("out:", out.shape, out[0, 0:10])
model1 = resnet18()
model1 = transfer_model(pretrained_file, model1)
out1 = model1(input_tensor)
print("out1:", out1.shape, out1[0, 0:10])
2. 修改网络名称并迁移学习
上面的例子,只是将官方的resnet18的self.layer4 = self._make_layer(block, 512, layers[3], stride=2)改为了:self.layer44 = self._make_layer(block, 512, layers[3], stride=2),我们仅仅是修改了一个网络名称而已,就导致 model.load_state_dict(torch.load(pretrained_file))出错,
那么,我们如何将预训练模型"model/resnet18-5c106cde.pth"转换成符合新的网络的模型参数呢?
方法很简单,只需要将resnet18-5c106cde.pth的模型参数中所有前缀为layer4的名称,改为layer44即可
本人已经定义好了方法:
modify_state_dict(pretrained_dict, model_dict, old_prefix, new_prefix)
def string_rename(old_string, new_string, start, end):
new_string = old_string[:start] + new_string + old_string[end:]
return new_string
def modify_model(pretrained_file, model, old_prefix, new_prefix):
'''
:param pretrained_file:
:param model:
:param old_prefix:
:param new_prefix:
:return:
'''
pretrained_dict = torch.load(pretrained_file)
model_dict = model.state_dict()
state_dict = modify_state_dict(pretrained_dict, model_dict, old_prefix, new_prefix)
model.load_state_dict(state_dict)
return model
def modify_state_dict(pretrained_dict, model_dict, old_prefix, new_prefix):
'''
修改model dict
:param pretrained_dict:
:param model_dict:
:param old_prefix:
:param new_prefix:
:return:
'''
state_dict = {}
for k, v in pretrained_dict.items():
if k in model_dict.keys():
# state_dict.setdefault(k, v)
state_dict[k] = v
else:
for o, n in zip(old_prefix, new_prefix):
prefix = k[:len(o)]
if prefix == o:
kk = string_rename(old_string=k, new_string=n, start=0, end=len(o))
print("rename layer modules:{}-->{}".format(k, kk))
state_dict[kk] = v
return state_dict
if __name__ == "__main__":
input_tensor = torch.zeros(1, 3, 100, 100)
print('input_tensor:', input_tensor.shape)
pretrained_file = "model/resnet18-5c106cde.pth"
# model = models.resnet18()
# model.load_state_dict(torch.load(pretrained_file))
# model.eval()
# out = model(input_tensor)
# print("out:", out.shape, out[0, 0:10])
#
# model1 = resnet18()
# model1 = transfer_model(pretrained_file, model1)
# out1 = model1(input_tensor)
# print("out1:", out1.shape, out1[0, 0:10])
#
new_file = "new_model.pth"
model = resnet18()
new_model = modify_model(pretrained_file, model, old_prefix=["layer4"], new_prefix=["layer44"])
torch.save(new_model.state_dict(), new_file)
model2 = resnet18()
model2.load_state_dict(torch.load(new_file))
model2.eval()
out2 = model2(input_tensor)
print("out2:", out2.shape, out2[0, 0:10])
这时,输出,跟之前一模一样了。
out: torch.Size([1, 1000]) tensor([ 0.4010, 0.8436, 0.3072, 0.0627, 0.4446, 0.8470, 0.1882, 0.7012,0.2988, -0.7574], grad_fn=
)
3.去除原模型的某些模块
下面是在不修改原模型代码的情况下,通过"resnet18.named_children()"和"resnet18.children()"的方法去除子模块"fc"和"avgpool"
import torch
import torchvision.models as models
from collections import OrderedDict
if __name__=="__main__":
resnet18 = models.resnet18(False)
print("resnet18",resnet18)
# use named_children()
resnet18_v1 = OrderedDict(resnet18.named_children())
# remove avgpool,fc
resnet18_v1.pop("avgpool")
resnet18_v1.pop("fc")
resnet18_v1 = torch.nn.Sequential(resnet18_v1)
print("resnet18_v1",resnet18_v1)
# use children
resnet18_v2 = torch.nn.Sequential(*list(resnet18.children())[:-2])
print(resnet18_v2,resnet18_v2)
补充:pytorch导入(部分)模型参数
背景介绍:
我的想法是把一个预训练的网络的参数导入到我的模型中,但是预训练模型的参数只是我模型参数的一小部分,怎样导进去不出差错了,请来听我说说。
解法
首先把你需要添加参数的那一小部分模型提取出来,并新建一个类进行重新定义,如图向Alexnet中添加前三层的参数,重新定义前三层。
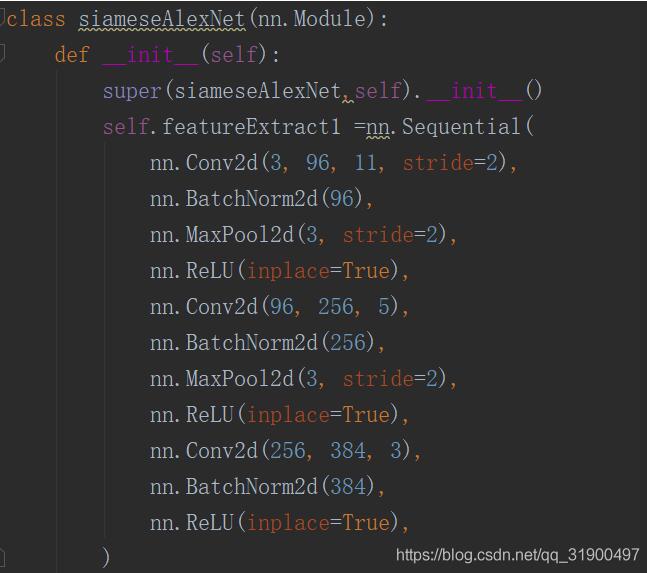
接下来就是导入参数
checkpoint = torch.load(config.pretrained_model)
# change name and load parameters
model_dict = model.net1.state_dict()
checkpoint = {k.replace('features.features', 'featureExtract1'): v for k, v in checkpoint.items()}
checkpoint = {k:v for k,v in checkpoint.items() if k in model_dict.keys()}
model_dict.update(checkpoint)
model.net1.load_state_dict(model_dict)
程序如上图所示,主要是第三、四句,第三是替换,别人训练的模型参数的键和自己的定义的会不一样,所以需要替换成自己的;第四句有个if用于判断导入需要的参数。其他语句都相当于是模板,套用即可。
以上为个人经验,希望能给大家一个参考,也希望大家多多支持脚本之家。如有错误或未考虑完全的地方,望不吝赐教。