前言
开始写OpenCV这篇文章的时候,不由想到,我的大学计算机图形学的第一门实操课程就是灰度转化,拉普拉斯锐化等。其中灰度图的转化,是计算机图形学基础中基础,这里就顺着OpenCV的灰度的转化,来看看OpenCV一些基础的api。
本文地址:https://www.jianshu.com/p/7963c7dbaf92
正文
Mat
先来看看OpenCV,基础对象Mat,矩阵。什么是矩阵,实际上没有必要解释,一般人都能够明白数学意义上矩阵的含义。
OpenCV把每一个M * N的宽高图像,看成M*N的矩阵。矩阵的每一个单元就对应着图像中像素的每一个点。
我们如果放大图中某个部分,就会发现如下情况

图像实际上就如同矩阵一样每个单元由一个像素点构成。
因为OpenCV的Mat每一个像素点,包含的数据不仅仅只有一个单纯的数字。每一个像素点中包含着颜色通道数据。
稍微解释一下颜色通道,我们可以把世间万物肉眼能识别的颜色由3种颜色(R 红色,G 绿色,B 蓝色)经过调节其色彩饱和度组成的。也就是说通过控制RGB三种的色值大小(0~255)来调配新的颜色。
当我们常见的灰度图,一般是单个颜色通道,因为只用黑白两种颜色。我们常见的图片,至少是三色通道,因为需要RGB三种颜色通道。
我们常见Android的Bitmap能够设置ARGB_8888的标志位就是指能够通过A(透明通道),R,G,B来控制图片加载的颜色通道。
OpenCV为了更好的控制这些数据。因此采用了数学上的矩阵的概念。当OpenCV要控制如RGB三色通道的Mat,本质上是一个M * N * 3的三维矩阵。
但是实际上,我们在使用OpenCV的Mat的时候,我们只需要关注每个图片的像素,而每个像素的颜色通道则是看成Mat中每个单元数据的内容即可
我们先来看看Mat的构造方法
Mat();
Mat(int rows, int cols, int type);
Mat(Size size, int type);
Mat(int rows, int cols, int type, const Scalar& s);
Mat(Size size, int type, const Scalar& s);
...
Mat(const Mat& m);
Mat(int rows, int cols, int type, void* data, size_t step=AUTO_STEP);
Mat(Size size, int type, void* data, size_t step=AUTO_STEP);
Mat(int ndims, const int* sizes, int type, void* data, const size_t* steps=0);
...
Mat(const Mat& m, const Range& rowRange, const Range& colRange=Range::all());
Mat(const Mat& m, const Rect& roi);
Mat(const Mat& m, const Range* ranges);
Mat(const Mat& m, const std::vector& ranges);
现阶段,实际上我们值得我们注意的是构造函数:
1.是通过Size或者rows和cols来设置Mat大小的方法。相当于创建一个固定宽高大小的黑色原始图片。
举个例子:
Mat mat(20,30,CV_8UC1,Scalar(255));
这个mat矩阵将会制造一个高20,宽30,一个1字节的颜色通道(也是Mat中每一个像素数据都是1字节的unchar类型的数据),同时颜色是白色的图片。
记住一点,在OpenCV中,rows是高,cols是宽。和我们传统印象是颠倒过来的。
在这里面我们能够看到一个特殊的宏CV_8UC1。实际上这是指代OpenCV中图片带的是多少颜色通道的意思。
CV_8uc1 单颜色通道 8位
CV_8uc2 2颜色通道 16位
CV_8uc3 3颜色通道 24位
CV_8uc4 4颜色通道 32位
这4个宏十分重要,要时刻记住。
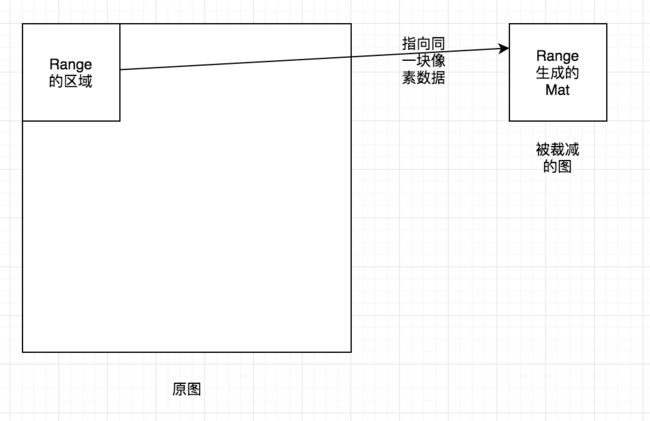
2.设置Range,来裁剪Mat中的数据范围,相当于把图片一部分裁剪出来。记得这种方式。被裁减出来的像素数据还是指向了原来Mat的像素数据。也就是说当修改了被裁减的Mat中的像素数据,同时也会更改了原来的Mat数据。如下图:
当我们需要把Mat 中的数据拷贝一份出来,我们应该调用下面这个api:
src.copyTo(mat);
这样就能拷贝一份像素数据到新的Mat中。之后操作新的Mat就不会影响原图。
Mat矩阵的创建原理
实际上,在本文中,我们能够看到OpenCV是这么调用api读取图片的数据转化为Mat矩阵。
Mat src = imread("/Users/yjy/Desktop/learningMaterials/study/test.jpg");
OpenCV会通过imread去读图片文件,并且转化为Mat矩阵。
Mat imread( const String& filename, int flags )
{
CV_TRACE_FUNCTION();
/// create the basic container
Mat img;
/// load the data
imread_( filename, flags, img );
/// optionally rotate the data if EXIF' orientation flag says so
if( !img.empty() && (flags & IMREAD_IGNORE_ORIENTATION) == 0 && flags != IMREAD_UNCHANGED )
{
ApplyExifOrientation(filename, img);
}
/// return a reference to the data
return img;
}
能看见imread,是调用imread_把图片中的数据拷贝的img这个Mat对象中。接着会做一次图片的颠倒。这个方面倒是和Glide很相似。
文件:modules/imgcodecs/src/loadsave.cpp
static bool
imread_( const String& filename, int flags, Mat& mat )
{
/// Search for the relevant decoder to handle the imagery
ImageDecoder decoder;
#ifdef HAVE_GDAL
if(flags != IMREAD_UNCHANGED && (flags & IMREAD_LOAD_GDAL) == IMREAD_LOAD_GDAL ){
decoder = GdalDecoder().newDecoder();
}else{
#endif
decoder = findDecoder( filename );
#ifdef HAVE_GDAL
}
#endif
/// if no decoder was found, return nothing.
if( !decoder ){
return 0;
}
int scale_denom = 1;
if( flags > IMREAD_LOAD_GDAL )
{
if( flags & IMREAD_REDUCED_GRAYSCALE_2 )
scale_denom = 2;
else if( flags & IMREAD_REDUCED_GRAYSCALE_4 )
scale_denom = 4;
else if( flags & IMREAD_REDUCED_GRAYSCALE_8 )
scale_denom = 8;
}
/// set the scale_denom in the driver
decoder->setScale( scale_denom );
/// set the filename in the driver
decoder->setSource( filename );
try
{
// read the header to make sure it succeeds
if( !decoder->readHeader() )
return 0;
}
catch (const cv::Exception& e)
{
std::cerr << "imread_('" << filename << "'): can't read header: " << e.what() << std::endl << std::flush;
return 0;
}
catch (...)
{
std::cerr << "imread_('" << filename << "'): can't read header: unknown exception" << std::endl << std::flush;
return 0;
}
// established the required input image size
Size size = validateInputImageSize(Size(decoder->width(), decoder->height()));
// grab the decoded type
int type = decoder->type();
if( (flags & IMREAD_LOAD_GDAL) != IMREAD_LOAD_GDAL && flags != IMREAD_UNCHANGED )
{
if( (flags & CV_LOAD_IMAGE_ANYDEPTH) == 0 )
type = CV_MAKETYPE(CV_8U, CV_MAT_CN(type));
if( (flags & CV_LOAD_IMAGE_COLOR) != 0 ||
((flags & CV_LOAD_IMAGE_ANYCOLOR) != 0 && CV_MAT_CN(type) > 1) )
type = CV_MAKETYPE(CV_MAT_DEPTH(type), 3);
else
type = CV_MAKETYPE(CV_MAT_DEPTH(type), 1);
}
mat.create( size.height, size.width, type );
// read the image data
bool success = false;
try
{
if (decoder->readData(mat))
success = true;
}
catch (const cv::Exception& e)
{
std::cerr << "imread_('" << filename << "'): can't read data: " << e.what() << std::endl << std::flush;
}
catch (...)
{
std::cerr << "imread_('" << filename << "'): can't read data: unknown exception" << std::endl << std::flush;
}
if (!success)
{
mat.release();
return false;
}
if( decoder->setScale( scale_denom ) > 1 ) // if decoder is JpegDecoder then decoder->setScale always returns 1
{
resize( mat, mat, Size( size.width / scale_denom, size.height / scale_denom ), 0, 0, INTER_LINEAR_EXACT);
}
return true;
}
这里面做了几个事情,实际上和FFmpge的设计十分相似。
1.首先在OpenCV的imagecodes模块中,存在一个ImageDecode的类。这个类会根据传进来的文件,读取头部,来找到内置在imagecodes的中jpeg/png/webp等图片格式解析器(jpeg对应grfmt_jpeg.cpp中的JpegDecoder等)。
2.接着,对着生成的解析器中就通过图片的头文件包含了该图片的中相关的参数,如宽高,颜色通道等。
3.调用readData读取解析器中的数据,把像素数据拷贝到Mat矩阵中。最后再调整大小。
其核心也是操作Mat中的像素指针,找到颜色通道,确定指针移动的步长,赋值图片的数据到Mat矩阵中。核心如下:
uchar* data = img.ptr();
for( ; m_height--; data += step )
{
jpeg_read_scanlines( cinfo, buffer, 1 );
if( color )
{
if( cinfo->out_color_components == 3 )
icvCvt_RGB2BGR_8u_C3R( buffer[0], 0, data, 0, Size(m_width,1) );
else
icvCvt_CMYK2BGR_8u_C4C3R( buffer[0], 0, data, 0, Size(m_width,1) );
}
else
{
if( cinfo->out_color_components == 1 )
memcpy( data, buffer[0], m_width );
else
icvCvt_CMYK2Gray_8u_C4C1R( buffer[0], 0, data, 0, Size(m_width,1) );
}
}
其中还涉及到jpeg的哈夫曼算法之类的东西,这里就不深入源码。毕竟这是基础学习。
Mat的像素操作与灰度图的转化
什么是灰度图,灰度度图实际上我们经常见到那些灰白的也可以纳入灰度图的范畴。实际上在计算机图形学有这么一个公式:
将RGB的多颜色图,通过的算法,将每一个像素的图像的三颜色通道全部转化为为一种色彩,通过上面的公式转为为一种灰色的颜色。
一旦了解了,我们可以尝试编写灰度图的转化。我们通过矩阵的at方法访问每一个像素中的数据。
为了形象表示矩阵指针,指向问题,可以把RGB在OpenCV的Mat看成如下分布:
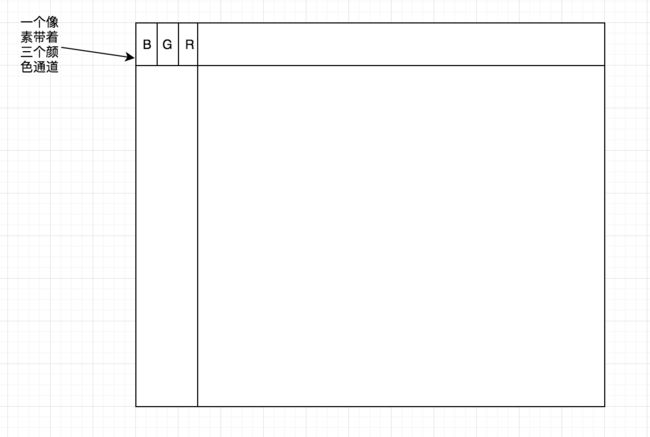
记住OpenCV的RGB的顺序和Android的不一样,是BGRA的顺序。和我们Android开发颠倒过来。
因此,我们可以得到如下的例子
int rows = src.rows;//高
int cols = src.cols;//宽
int channel = src.channels();
for(int i = 0;i(i,j)[0];
int g = src.at(i,j)[1];
int r = src.at(i,j)[2];
//所有色彩转化为一种
src.at(i,j)[0] =0.30*r + 0.59*g +0.11*b;
src.at(i,j)[1] =0.30*r + 0.59*g +0.11*b;
src.at(i,j)[2] =0.30*r + 0.59*g +0.11*b;
}
}
}
imwrite("/Users/yjy/Desktop/learningMaterials/study/gray1.png", src);
imshow("test1", src);
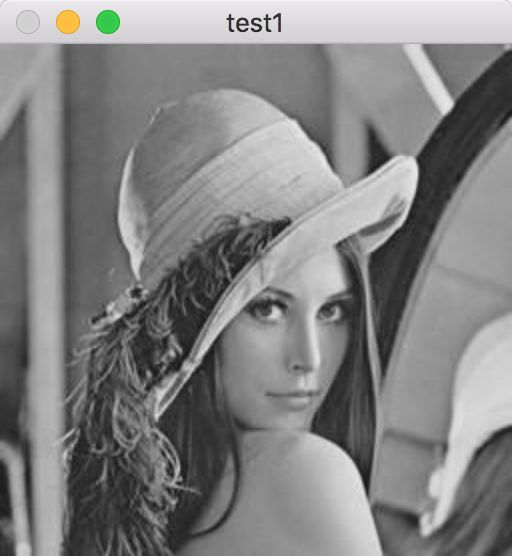
我们经过尝试之后,确实能够把一个彩色的图片转化一个灰色图片。但是这就是
这里介绍一下Mat的一个api:
Mat gray;
cvtColor(src, gray, COLOR_BGR2GRAY);
imwrite("/Users/yjy/Desktop/learningMaterials/study/gray.png", gray);
实际上OpenCV,内置了一些操作,可以把RGB的图像数据转化灰度图。
我们看看OpenCV实际上的转化出来的灰度图大小。我们通过自己写的方法,转化出来的灰度图是119kb,而通过cvtColor转化出来的是44kb。
问题出在哪里?还记得吗?因为只有灰白两种颜色,实际上只需要一种颜色通道即可,而这边还保留了3个颜色通道,也就说图片的每一个像素点中的数据出现了没必要的冗余。
Mat gray(src.rows,src.cols,CV_8UC1);
for(int i = 0;i(i,j)[0];
int g = src.at(i,j)[1];
int r = src.at(i,j)[2];
//我们要把3通道转化为1通道
gray.at(i,j) =0.30*r + 0.59*g +0.11*b;
}
}
}
这样就是44kb的大小。把三颜色通道的数据都设置到单颜色通道之后,就能进一步缩小其大小。
Android中画笔的ColorMatrix灰度变化
实际上在Android中的ColorMatrix中也有灰度图转化的api。
ColorMatrix colorMatrix = new ColorMatrix();
colorMatrix.setSaturation(0);
paint.setColorFilter(new ColorMatrixColorFilter(colorMatrix));
对画笔矩阵进行一次,矩阵变化操作。
public void setSaturation(float sat) {
reset();
float[] m = mArray;
final float invSat = 1 - sat;
final float R = 0.213f * invSat;
final float G = 0.715f * invSat;
final float B = 0.072f * invSat;
m[0] = R + sat; m[1] = G; m[2] = B;
m[5] = R; m[6] = G + sat; m[7] = B;
m[10] = R; m[11] = G; m[12] = B + sat;
}
实际上就是做了一次矩阵运算。绘制灰度的时候相当于构建了这么一个矩阵
colorMatrix = new ColorMatrix(new float[]{
0.213f,0.715f,0.072f,0,0,
0.213f,0.715f,0.072f,0,0,
0.213f,0.715f,0.072f,0,0,
0,0,0,1,0
});
接着通过矩阵之间的相乘,每一行的 0.213f,0.715f,0.072f控制像素的每个通道的色值。
对于Java来说,灰度转化的算法是:,把绿色通道的比例调大了。
图像混合
在OpenCV中有这么两个API,add和addWidget。两者都是可以把图像混合起来。
Mat logo = imread("/Users/yjy/Desktop/learningMaterials/study/ic_launcher_round.png");
Mat src = imread("/Users/yjy/Desktop/learningMaterials/study/test.jpg");
Mat dst;
add(src,logo,dst);
addWeighted(src, 0.7, logo, 0.3, 0.0, dst);
add和addWidget都是将像素合并起来。但是由于是像素直接相加的,所以容易造成像素接近255,让整个像素泛白。
而权重addWeighted,稍微能减轻一点这种问题,本质上还是像素相加,因此打水印一般不是使用这种办法。
等价于
saturate_cast(src(x)*alpha + logo(x)*beta + gamma);
saturate_cast这个是为了保证计算的值在0~255之间,防止越界。
饱和度,亮度,对比度
饱和度,图片中色值更加大,如红色,淡红,鲜红
对比度:是指图像灰度反差。相当于图像中最暗和最亮的对比
亮度:暗亮度
控制对比度,饱和度的公式: ,,
因此当我们想要控制三通道的饱和度时候,可以通过alpha来控制色值成比例增加,beta控制一个色值线性增加。
如下:
for(int i = 0;i(i,j)[0];
int g = src.at(i,j)[1];
int r = src.at(i,j)[2];
src.at(i,j)[0] = saturate_cast(b*alpha +beta);
src.at(i,j)[1] = saturate_cast(g*alpha +beta);
src.at(i,j)[2] = saturate_cast(r*alpha +beta);
}
}
}
总结
在这里,看到了OpenCV会把所有的图片看成Mat矩阵。从本文中,能看到Mat的像素操作可以能看到有两种,一种是ptr像素指针,一种是at。ptr是OpenCV推荐的更加效率的访问速度。
当然还有一种LUT的核心函数,用来极速访问Mat矩阵中的像素。其原理是对着原来的色值进行预先的变换对应(设置一个颜色通道)。用来应对设置阈值等情况。
LUT(I, lookUpTable, J);