1 浏览器的工作原理
1.2.5.3 浏览器解析与计算CSS
接第⑤章节生成DOM树的过程,如果语法分析器在解析tokens时遇到标签,浏览器就会发送请求获得该标签中标记的CSS文件(使用内联样式可以省略请求的步骤提高速度,但没有必要为了这点速度而丢失了模块化与可维护性),然后继续构建DOM树和开始把CSS属性存储到相应的DOM树节点上,在这个新的过程中,浏览器会依次检查已经出栈的DOM树节点,去看它匹配到了哪些CSS选择器(经过词法分析和语法分析后),再根据选择器的优先级,做覆盖和调整。
在第⑥章CSS语法部分,已经总结了选择器的各种符号和选择器的类型,到了这里我们可以发现,选择器的检查顺序,跟构建DOM树的顺序一致,都是从父节点到子节点(所以CSS没有父选择器)。这是一个CSS设计的原则,即保证选择器在DOM树构建到当前节点时,已经可以准确判断是否匹配,不需要后续信息;例如 “空格”、“>”、“~”、“+”、“||”这些复杂选择器符号,都是从父节点检查到子节点(或者后继节点)。
1.2.5.3.1 把CSS属性存储到DOM树上
分析以下几种选择器是怎么去匹配到DOM树节点:
① 子代选择器“ >”
div>.cls {
border:solid 1px green;
}
对应的DOM树节点:
1
2
3
4
5
在上面的例子中,当DOM树构建到 ② 后代选择器 “空格” 对应的DOM树节点: 在上面的例子中,后代选择器先会寻找能匹配 ③ 后继选择器“ ~ ” 对应的DOM树节点: 在上面的例子中,后继选择器会先寻找能匹配 自此,当DOM树构建完毕后,浏览器也流式地把处理好CSS样式信息存储到DOM树上,不一定同步完成,要看实际运行过程;而且不同的浏览器对CSS处理方式不同,上面的是Webkit的处理方式,像Gecko则是通过CSS解析生成CSS Rule Tree,然后通过比对DOM生成Style Context Tree,然后在把Style Context Tree和其Render Tree(Frame Tree)关联上,Frame是DOM结点的意思。 这个计算过程(称为排版或者布局),会和构建DOM树、处理CSS样式过程流式进行;常用排版:正常文档流(行内元素与文字从左到右排列,块级元素自身为一行从上自下排列)、flex、grid、position。 常用的 块级元素( 行内元素( 从显示结果可以看出,相邻的行内元素不换行,宽度即为内容的宽度、 行内块级元素( 行内元素与块级元素之间的转换: 行内元素与块级元素的区别: 浏览器在流式构建DOM树、处理CSS样式,计算位置与大小后,会根据这些样式信息和位置大小信息为每个元素在内存中渲染出图形,并且把它绘制到对应的位置。 渲染(把模型变成位图的过程),这里的位图指的是在内存里建立一张二维表格,把一张图片的每个像素对应的颜色保存进去(位图信息也是DOM树中占据浏览器内存最多的信息,我们在做内存占用优化时,主要就是考虑这一部分)。 这个渲染过程是非常复杂的,但是总体来说,可以分成两个大类:图形和文字。 在最普遍的情况下,渲染过程生成的位图尺寸跟它在上一步排版时占据的尺寸相同,但是理想和现实是有差距的,很多属性会影响渲染位图的大小,比如阴影,它可能非常巨大,或者渲染到非常遥远的位置,所以为了优化,浏览器实际的实现中会把阴影作为一个独立的盒来处理。 注意,我们这里讲的渲染过程,是不会把子元素绘制到渲染的位图上的,这样,当父子元素的相对位置发生变化时,可以保证渲染的结果能够最大程度被缓存,减少重新渲染。 合成是英文术语compositing的翻译,这个过程实际上是一个性能考量,它并非实现浏览器的必要一环。 合成的原理:“猜测”可能变化的元素,把它所在的位图排除到合成之外,从而减少了重绘次数。 这是浏览器绘制页面的最后一步,在之前我们已经得到了每个元素的位图,并且对它们部分进行了合成,然后浏览器只需要把最终要显示的位图交给Browser进程即可;.cls选择条件,并且指定父元素必须是当前2,并且把选择器的CSS属性存储上去。
a#b .cls {
color: green;
}
1
2
3
a#b的元素,再检查它所有的子代是否匹配.cls,然后在遇到此元素的结束标签时回退去寻找下一个匹配a#b的元素。.cls~* {
border:solid 1px green;
}
.cls的元素,和确定它的父元素是什么,再往下寻找同一层级且满足父元素是1.2.6 流式计算每个元素的位置和大小
1.2.6.1 块级元素和行内元素简介 ★
display值: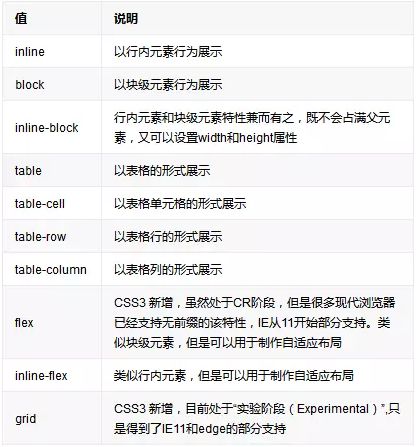
display:block):
独占一行(即使是设置了width属性也是独占一行),对宽高的属性值生效;如果不给宽度,块级元素就默认为浏览器的宽度,即就是100%宽,table元素浏览器默认的display属性为table。
display:inline):
可以多个标签存在一行,对宽高属性值不生效,完全靠内容撑开宽高。![]()
padding的4个方向都有效(从span标签可以看出,对于行内非替换元素,不会影响其行高,不会撑开父元素;而对于替换元素,则会撑开父元素)、margin只有水平方向有效(其中垂直方向的margin对行内替换元素(比如img元素)有效,对行内非替换元素无效)、不可以设置width和height属性。display:inline-block):
行内块级元素表现其实和行内元素一样,只是其可以设置width和height属性,像行内元素的img(用于向网页中嵌入一幅图像),input(用于搜集用户信息)。
① float:当把行内(块级)元素设置完float:left/right后,该元素会变成行内块级元素,且拥有浮动特性,这样设置还会去除行内元素之间的空隙(间隙),消除空隙的方法还有为父元素设置font-size:0,子元素上再设置需要的字体大小font-size;二是在行内元素之间使用空注释,填充它们之间的空白;三是为行内元素设置margin-left或margin-right 为负值,但是每个浏览器的间距不一样,所以基本不用这种方法;四是将行类元素连着写,中间不要有空格,原理和二一样,五给父元素加letter-spacing负值,然后通过子元素清除letter-spacing值;
② position:当为行内元素进行定位时,position:absolute与position:fixed,都会使得原先的行内元素变为块级元素;
③ display:修改display属性;
④ 注意:使用float和position属性会使元素脱离正常文档流,清除float浮动方法。
① text-align属性对块级元素起作用,对行内元素不起作用(除了font标签):
② 块级元素独自占一行且宽度会占满父元素宽度,行内元素不会独占一行,相邻行内元素可以排在同一行;
③ 块级元素可以设置weith和height,行内元素设置width和height无效,而且块级元素即使设置宽度也还是独占一行。注意但块级元素当没有明确指定width和height值时,块级元素尺寸由内容确定,当指定了width和height的值时,内容超出块级元素的尺寸就会溢出,这时块级元素要呈现什么行为要看其overflow的值(visible,hidden,overflow,scroll);
④ 块级元素可以设置margin(外边距)和padding(内边距)属性,行内元素水平方向的margin和padding如margin-left、padding-right可以产生边距效果,但是竖直方向的margin-top、margin-bottom不起作用;
⑤ 行内元素的padding-top和padding-bottom会起作用,不过就像脱离了标准流一样(即padding-left和padding-right的层级比其他元素高),并不会占据位置,并且还把其他元素给盖住了。但是,假如inline的元素没有内容,“padding-top、padding-bottom"将不起作用。如果想要起作用,只需要给padding-left或者padding-right设置一个值,或者当inline的元素有内容时就会起作用;
⑥ 当inline-block碰到同类inline-block时,谁的上下margin、paddin或line-height(行高)大,就会共用谁的margin、paddin和line-height。除非碰到的是inline,因为inline的margin是不起作用的。且inline的padding是不占空间的;
⑦ inline碰到inline-block会引起空隙(间隙),可以消除。1.2.7 最终步骤
1.2.7.1 渲染
浏览器中实际渲染时,会把每一个元素对应的盒变成位图。这里的元素包括HTML元素和伪元素,一个元素可能对应多个盒(比如inline元素,可能会分成多行)。每一个盒对应着一张位图。
盒的背景、边框、SVG元素、阴影等特性,都是需要绘制的图形类,需要一个底层库(Android的Skia,Windows平台则有GDI)来支持,一般的浏览器会做一个兼容层来处理掉平台差异。
盒中的文字,也需要用底层库来支持,叫做字体库,字体库提供读取字体文件的基本能力,它能根据字符的码点抽取出字形;字形分为像素字形和矢量字形两种。通常的字体,会在6px、8px等小尺寸提供像素字形,比较大的尺寸则提供矢量字形。矢量字形本身就需要经过渲染才能继续渲染到元素的位图上去。目前最常用的字体库是Freetype,这是一个C++编写的开源的字体库。1.2.7.2 合成
目前,主流浏览器一般根据position、transform等属性来决定合成策略,来“猜测”这些元素未来可能发生变化;但是这样的猜测准确性有限,所以在新的CSS标准中,规定了will-change属性,可以由业务代码来提示浏览器的合成策略,灵活运用这样的特性,可以大大提升选择合成带来的收益。1.2.7.3 绘制 ★
在浏览器需要重绘(鼠标划过浏览器显示区域也需要重绘制)时,会使用脏矩形技术,就是哪里脏了,就(仅仅)把脏了的那块区域重绘,而不是每次直接性的重绘;其基本条件是:脏矩形的计算和绘制的代价小于直接性重绘。换句话说,如果一个屏幕每一帧变化的东西太多的话,就不值得用这个算法了。