1.1 数组为什么需要指定长度
想象一下,如果不指定长度的话,内存空间一次性得开辟多少连续的空间,系统是不确定的。因为数组是内存中连续的空间,这样是为了数组的连续编号性。所以到哪里截止就是一个需要确定的问题。
优点:快速查询,所以数组最好应用于索引有语义的情形。
缺点:不能动态的开辟空间,每次开辟空间都得进行一轮复制操作。
1.2 实现动态数组
动态数组,底层数据结构就是数组类,在java中对应着ArrayList类。我们一起来看看具体的实现原理(部分细节肯定不能和java标准库中的完全一样,主要讲实现的原理)
1.2.1 添加元素add方法
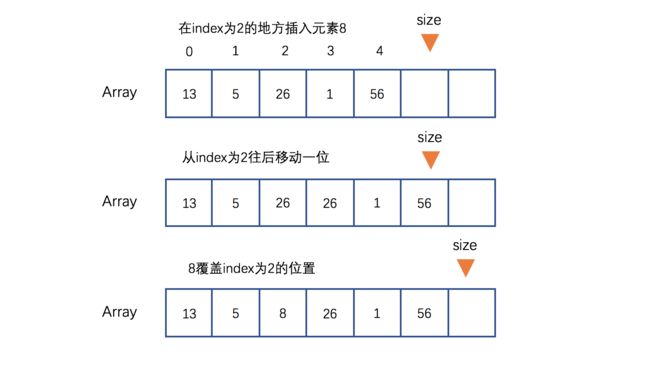
如下图,在数组中size指向的是第一个空位的地址,相当于一个指针,我们添加元素时,就是在size所标记的索引进行添加就可以了。

添加元素代码如下:
private T[] data;
private int size;
public void add(T t){
data[size] = t;
size++;
}
相信以上代码很简单,大伙应该很容易就能理解,不过上面这样实现的问题也是显而易见的。因为数组的长度是固定的,容易发生数组越界异常,所以就自然而然想到了动态改变数组长度。由此产生了所谓的动态数组。
具体动态改变数组长度的过程也是很简单,每次添加元素时,先进行判断是否当前元素个数size是否等于数组的长度。如果大于等于,则进行一次扩容操作,增至为当前数组2倍的数据量。
public void add(int index, T t) {
if (index < 0 || index > size) {
throw new IllegalArgumentException("index illegal exception");
}
// 当前元素个数大于等于数组长度
if (size >= data.length) {
resizeCapacity(2 * data.length);
}
// 当前元素个数小于数组长度的四分之一,避免一开始数据过少浪费空间
if (size <= data.length / 4 && data.length / 2 != 0) {
resizeCapacity(data.length / 2);
}
for (int i = size - 1; i >= index; i--) {
data[i + 1] = data[i];
}
data[index] = t;
size++;
}
扩容的代码也很简单,就是开辟一个新空间,然后进行一轮赋值操作。
private void resizeCapacity(int newCapacity) {
if (size > newCapacity) {
throw new IllegalArgumentException("size is bigger than newCapacity");
}
T[] newT = (T[]) new Object[newCapacity];
for (int i = 0; i < size; i++) {
newT[i] = data[i];
}
data = newT;
}
1.2.2 移除元素remove方法
同理,移除元素也是一样的对元素个数进行判断。
public T remove(int index) {
if (index < 0 || index >= size) {
throw new IllegalArgumentException("index illegal exception");
}
T delete = data[index];
System.arraycopy(data, index + 1, data, index, size - 1 - index);
size--;
data[size] = null;
// 当前元素个数小于数组长度的四分之一时,进行缩容
if (size <= data.length / 4 && data.length / 2 != 0) {
resizeCapacity(data.length / 2);
}
return delete;
}
这里你可能会问,为啥是当前元素小于四分之一才缩容一半呢,为啥不是二分之一时进行缩容呢?
其中原因很简单,我们想象一下,如果每次元素个数小于当前数组容积的一半时,我们就缩容,那么此时如果刚好又得add元素,那又得扩容,这样来回缩容扩容相当耗费性能,这种现象成为复杂度的震荡。
1.2.2 改变元素set方法
针对某个索引对元素进行修改。
public void set(int index, T t) {
if (index < 0 || index >= size) {
throw new IllegalArgumentException("index illegal exception");
}
data[index] = t;
}
1.2.3 查找某个元素find方法
对数组做一次遍历,当equals为true时,返回当前元素,否则返回-1。
public int find(T t) {
for (int i = 0; i < size; i++) {
if (data[i].equals(t)) {
return i;
}
}
return -1;
}
1.3 复杂度的分析
1.3.1 增
其实增的操作就是插入元素,复杂度和插入元素的位置有相当大的关系。
最后插入元素(我们习惯叫添加元素)
那么复杂度为O(1)级别,因为不用做元素的后移操作。
其余位置插入元素,复杂度为O(n)级别,需要移动元素。
基于链表和数组的数据结构比较
我们经常说,基于链表的数据结构插入元素比基于数组的数据结构快,其实这是有条件的。我们来看一下如下一段代码:
ArrayList arrayList = new ArrayList<>();
LinkedList linkedList = new LinkedList<>();
int count = 5000 * 10;
Random randomIndex = new Random();
long startTime = System.nanoTime();
for (int i = 0; i < count; i++) {
arrayList.add(randomIndex.nextInt(arrayList.size() + 1), i);
}
long endTime = System.nanoTime();
System.out.println("array: " + (endTime - startTime) / 1000000000.0);
startTime = System.nanoTime();
for (int i = 0; i < count; i++) {
linkedList.add(randomIndex.nextInt(linkedList.size() + 1), i);
}
endTime = System.nanoTime();
System.out.println("linked: " + (endTime - startTime) / 1000000000.0);
运行结果:
array: 0.156862527
linked: 5.517377045
是不是很惊喜!?是不是很刺激!?
如果是随机插入到ArrayList和LinkedList,虽然链表在插入元素时,只需要改变插入节点头尾指针的指向,但是这里的耗时操作存在两点:
第一,找寻插入节点的位置;
第二,不断的new出新的node节点(链表节点)
所以就得出了以上的结果,链表的主要优势场景:在于头尾两个节点进行频繁操作。
其余删,改,查,基本上分析的方法和增差不多,这里就不赘述了。