Spark的MLlib专门设计了一些工具用来对ML算法和Pipeline进行调优。比如内置的交叉验证和其他工具能够方便用户对算法和Pipeline的超参数调优。
我们知道Pipeline可以看成是多个算法的组装,比如用特征提取的算法、特征转换的算法、特征选择的算法再加上对特征学习的分类聚类回归协同过滤等等算法组合成一个Pipeline。刚刚提到的这些算法都是这个Pipeline中的一个stage,对于Pipeline调优就是对各个stage中可能需要调节的超参数进行交叉验证,然后根据评价结果做出选择。
后面的代码是对特定的一个算法进行调参,不过个人感觉从代码的API上来看,其实Spark更倾向于让用户对Pipeline调参。不过单独对算法的调参也是完全没有问题的。
模型选择(也称为调超参)
模型选择也就是调参,是非常重要的一个环节,正如上面所说,Spark支持对一个单独的Estimator调参,也支持对整个Pipeline调参。
MLlib支持模型选择的工具有: CrossValidator
和 TrainValidationSplit。这两个工具都需要下面几个设置项:
- Estimator: 一个算法或者Pipeline
- ParamMaps:一组待选择的参数集合。有时也被称为参数网格。
- Evaluator: 一个评价模型在验证集上的打分方法
整体上看,模型选择主要做以下事情:
- 将输入的数据分割成训练集和验证集
- 对于每个配对的训练集和验证集,对于ParamMaps进行遍历:
- 对于每个ParamMaps中的参数,先fit Estimator,然后使用训练后的Model在验证集上预测,最后使用Evaluator来评价模型的性能。
- 最佳性能的参数的模型做为选择的结果
Evaluator:对于回归问题它是RegressionEvaluator,对于二分类问题它是BinaryClassificationEvaluator
,对于多分类问题它是 MulticlassClassificationEvaluator。其中具体的打分方法可以通过设置setMetricName()来改变默认的评价方法。
为了创建参数的网格ParamMaps,用户需要使用ParamGridBuilder这个工具。
CrossValidator
CrossValidator 是Spark提供的一个可以用来做交叉验证的工具。它可以把数据分成若干个集合,用来分别做训练集和验证集。
比如对于对于3折交叉验证来说,就是数据集分成3份,轮流把其中的1/3拿出来做验证集,那么剩下的2/3就是训练集。评价ParamMap中一组参数的好坏,CrossValidator将会计算这组参数在3次不同的fold中的评分均值。
在得到ParamMap中的最佳参数后,CrossValidator 会重新使用这组参数在整个数据集上来再次fit得到最终的Model。
TrainValidationSplit
Spark同样提供了另一种工具TrainValidationSplit来做模型选择。与上面的CV不同的是TV只做一次数据分割,而不是像CV那样分割成多个fold进行交叉验证。所以TV代价更低,当没有足够多的数据进行交叉验证时,这个工具也可以用来给出不错的模型选择结果。
设置trainRatio,可以用来选择训练集在整个数据的比例,剩下的就是测试集。
就像CV一样,TV也会在选择最佳参数后重新在整个数据集上再次fit得到最终的Model。
代码实例
下面提供的代码实例不是Spark官网文档中的样例,而是我自己的一个实际代码示例,主要是用TV、CV分别做ALS模型的调参,并探索如何得到最佳的参数。比起官网的样例,内容会更丰富点。
-
1.构造输入数据Dataset
先看下数据的模样(取自于Spark在协同过滤时的Example数据):
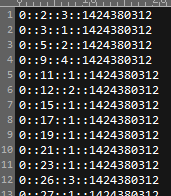
构造一个与之相匹配的Class用来后续读取数据:
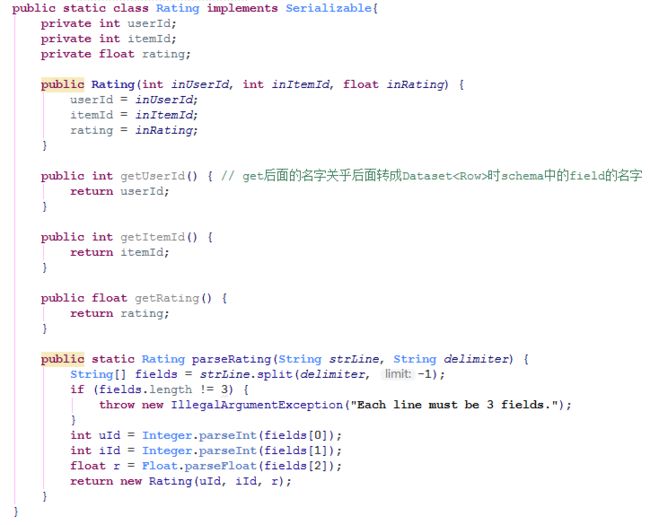
最后得到Dataset

这里需要额外强调一个事情,大家有没有想过,此时得到的样本集的DataFrame是张什么样子,它的schema是什么?

跟踪源码可以看到:
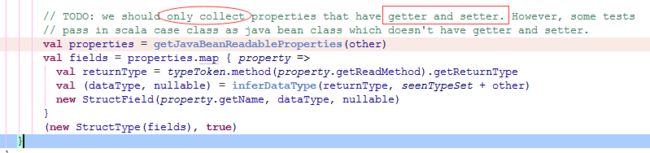
所以需要注意前面截图中的注释所写内容。
-
2.构造TV或者CV所需要的三要素
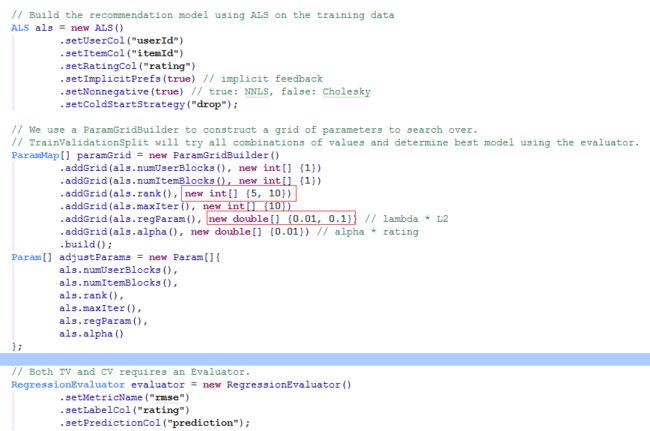
上面代码首先构造了一个ALS的Estimator,然后设置了一些不需要调的参数;然后使用ParamGridBuilder创建了一个ParamMap,把需要调整的参数设置放到数组中;最后因为是衡量Rating的差值,所以用RegressionEvaluator来作为评价标准。
-
3.选择使用调参的工具

对于TV和CV来说,返回的结果是调参后的ALS,是一个Estimator,当然也可以直接返回训练后的Model,这里没有这么做的原因是后续可能需要利用得到的最佳参数在别的训练集上训练,所以没有直接用Model。
如果不是TV或者CV就表示,直接使用指定参数的Estimator来fit训练集,得到Model。
-
4.TV调参

首先把样本集分为训练集和测试集,然后把训练集喂给TV,得到最佳模型后在测试集上看下效果。
(PS:最后两行代码是给大家提供下思路查看下模型的一些参数)
看下打印结果,方便理解:
@@@ validMetrics.len = 4, getParamGrid.len = 4
@@@ ModelGrid[0]:
@@@ Params:
@@@ numUserBlocks:1
@@@ numItemBlocks:1
@@@ rank:5
@@@ maxIter:10
@@@ regParam:0.01
@@@ alpha:0.01
@@@ [0]'s metric = 1.960791
@@@ ModelGrid[1]:
@@@ Params:
@@@ numUserBlocks:1
@@@ numItemBlocks:1
@@@ rank:5
@@@ maxIter:10
@@@ regParam:0.1
@@@ alpha:0.01
@@@ [1]'s metric = 1.964143
@@@ ModelGrid[2]:
@@@ Params:
@@@ numUserBlocks:1
@@@ numItemBlocks:1
@@@ rank:10
@@@ maxIter:10
@@@ regParam:0.01
@@@ alpha:0.01
@@@ [2]'s metric = 1.974889
@@@ ModelGrid[3]:
@@@ Params:
@@@ numUserBlocks:1
@@@ numItemBlocks:1
@@@ rank:10
@@@ maxIter:10
@@@ regParam:0.1
@@@ alpha:0.01
@@@ [3]'s metric = 1.979533

org.apache.spark.ml.tuning.TrainValidationSplitModel
shishi
coldStartStrategy: strategy for dealing with unknown or new users/items at prediction time. This may be useful in cross-validation or production scenarios, for handling user/item ids the model has not seen in the training data. Supported values: nan,drop. (default: nan, current: drop)
itemCol: column name for item ids. Ids must be within the integer value range. (default: item, current: itemId)
predictionCol: prediction column name (default: prediction)
userCol: column name for user ids. Ids must be within the integer value range. (default: user, current: userId)

-
5.CV调参
CV的内容和TV很类似,就不再详细描述了。只把代码贴一下:
private static ALS cvGetALS(Dataset rating, ALS als, ParamMap[] paramGrid, Param[] adjustParams, RegressionEvaluator evaluator) {
// Split to training and test
Dataset[] splits = rating.randomSplit(new double[]{0.8, 0.2}, 12345);
Dataset training = splits[0];
Dataset test = splits[1];
// Use CV to select hyper-parameters.
CrossValidator cv = new CrossValidator()
.setEstimator(als)
.setEvaluator(evaluator)
.setEstimatorParamMaps(paramGrid)
.setNumFolds(3)
.setSeed(54321);
// Run cross-validation, and choose the best set of parameters.
CrossValidatorModel cvModel = cv.fit(training);
// String coldStartStrategy = cvModel.bestModel().getOrDefault(als.coldStartStrategy());
// System.out.println("@@@ model's cold start strategy is : " + coldStartStrategy);
// als.setRank(cvModel.getEstimatorParamMaps()[0].apply(als.rank()));
double[] foldAvgMetrics = cvModel.avgMetrics();
ParamMap[] getParamGrid = cvModel.getEstimatorParamMaps();
System.out.printf("@@@ foldAvgMetrics.len = %d, getParamGrid.len = %d\n", foldAvgMetrics.length, getParamGrid.length);
for (int i = 0; i < getParamGrid.length; i++) {
System.out.println("\n@@@ ModelGrid[" + i + "]:");
System.out.printf("@@@ Params:\n");
for (Param param : adjustParams) {
System.out.println("@@@ " + param.name() + ":" + getParamGrid[i].apply(param));
}
System.out.printf("@@@ [%d]'s metric = %f\n", i, foldAvgMetrics[i]);
}
System.out.println(cvModel.logName());
System.out.println("shishi");
System.out.println(cvModel.bestModel().explainParams());
System.out.println("==\n@@@ Parameters of best model are:");
// for (Param param : adjustParams) {
// System.out.println("@@@ " + param.name() + ": " + cvModel.bestModel().getOrDefault(param));
// }
// Make predictions on test data. model is the model with combination of parameters that performed best.
double testMetric = evaluator.evaluate(cvModel.transform(test));
System.out.println("@@@ testMetric = " + testMetric);
System.out.println("@@@ Trial: Can getEstimator be normally work?");
ALS selectALS = (ALS) cvModel.bestModel().parent();
printALSParameters(selectALS);
return selectALS;
}
-
6.使用最佳参数模型


//最后再列下一些打印输出:
@@@ Parameters of best model are:
[Stage 1865:=================================================> (190 + 6) / 200]@@@ testMetric = 1.8407775549071754
@@@ Trial: Can getEstimator be normally work?
@@@ Print selected Estimator[ALS]'s parameters:
@@@ NumUserBlocks = 1
@@@ NumItemBlocks = 1
@@@ Rank = 5
@@@ MaxIter = 10
@@@ RegParam = 0.01
@@@ Alpha = 0.01
@@@ -- also need check the static parameters:
@@@ UserCol = userId
@@@ ItemCol = itemId
@@@ RatingCol = rating
@@@ ImplicitPrefs = true
@@@ ColdStartStrategy = drop
@@@ Nonnegative = true
@@@ Look newRating.show():
+------+------+------+----------+
|itemId|rating|userId|prediction|
+------+------+------+----------+
| 31| 1.0| 26| 0.8083524|
| 31| 1.0| 27|0.49823457|
| 31| 4.0| 12|0.74219275|
| 31| 1.0| 13| 1.0689088|
| 31| 1.0| 5|0.39859438|
| 31| 1.0| 19|0.50181335|
| 31| 1.0| 4| 0.6881375|
| 31| 3.0| 8| 1.0001528|
| 31| 3.0| 7|0.69204247|
| 31| 2.0| 25|0.21946692|
| 31| 1.0| 24|0.44250935|
| 31| 1.0| 29| 0.2875255|
| 31| 3.0| 14| 1.0763997|
| 31| 1.0| 0| 0.6548886|
| 31| 1.0| 18|0.45801058|
| 85| 1.0| 28| 0.8874159|
| 85| 1.0| 26|0.52782345|
| 85| 1.0| 12|0.58099973|
| 85| 3.0| 1|0.43520123|
| 85| 1.0| 13|0.71381164|
+------+------+------+----------+
only showing top 20 rows
@@@ New rating's Root-mean-square error = 1.6780782240247583
@@@ Look userFactors.show():
+---+--------------------+
| id| features|
+---+--------------------+
| 0|[0.83028704, 0.0,...|
| 1|[0.5547648, 0.0, ...|
| 2|[1.1125437, 0.572...|
| 3|[0.39823756, 0.10...|
| 4|[0.3549967, 0.436...|
| 5|[0.206906, 0.4185...|
| 6|[0.9881438, 0.695...|
| 7|[0.0, 0.9509129, ...|
| 8|[0.15908337, 0.01...|
| 9|[1.1426004, 0.438...|
| 10|[0.009195265, 1.1...|
| 11|[0.7475871, 1.244...|
| 12|[0.69849384, 0.28...|
| 13|[0.36948213, 0.0,...|
| 14|[0.0, 0.28214774,...|
| 15|[0.0, 0.2707359, ...|
| 16|[0.23595756, 0.0,...|
| 17|[0.794894, 0.2966...|
| 18|[0.0, 1.2907895, ...|
| 19|[0.6430788, 0.0, ...|
+---+--------------------+
only showing top 20 rows
root
|-- id: integer (nullable = false)
|-- features: array (nullable = true)
| |-- element: float (containsNull = false)
@@@ Look itemFactors.show():
+---+--------------------+
| id| features|
+---+--------------------+
| 0|[0.15326485, 0.34...|
| 1|[0.0, 0.10216009,...|
| 2|[0.3645432, 0.0, ...|
| 3|[0.0, 0.0, 0.1291...|
| 4|[0.13871889, 0.38...|
| 5|[0.0, 0.15399799,...|
| 6|[0.5057344, 0.098...|
| 7|[0.0, 0.10902989,...|
| 8|[0.13608119, 0.18...|
| 9|[0.28385615, 0.11...|
| 10|[0.09442133, 0.87...|
| 11|[0.0, 0.31362426,...|
| 12|[0.55532986, 0.0,...|
| 13|[0.0, 0.5589551, ...|
| 14|[0.0, 0.03354008,...|
| 15|[0.26341748, 0.11...|
| 16|[0.0, 0.23442663,...|
| 17|[0.047568206, 0.0...|
| 18|[0.037029687, 0.6...|
| 19|[0.4564545, 0.0, ...|
+---+--------------------+
only showing top 20 rows
@@@ Done matrixFactorizationByALS()