为什么使用Scrapy?
我们可以用requests和beautifulsoup完成一个实用的爬虫,但如果想大规模爬取的话,我们需要学习Scrapy这个优秀Python框架,学习它的哲学思想,可以帮助我们更好写自己的爬虫。
事前准备
由于Windows存在许多莫名其妙的坑,所以建议安装anaconda这个优秀的python发行版,并且在anaconda目录添加到环境变量中。
- 使用
create -n scrapy_app python=2 scrapy创建一个预装scrapy的虚拟环境。 - 在cmd下启动虚拟环境
activate scrapy_app。 conda install -c scrapinghub scrapy安装其他必须库scrapy bench验证能否正常工作
官方教程
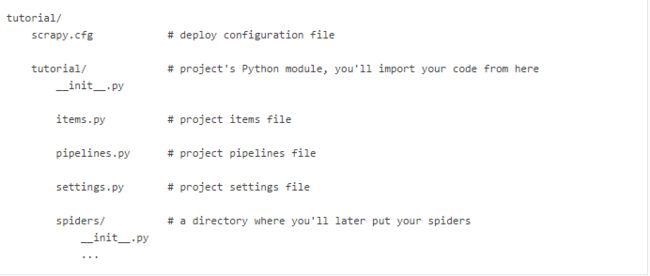
1.新建项目scrapy startproject tutorial
这个命令将会创建如下内容:
2.定义Item
items用来装scraped data,也就是从网页提取的数据,是一类简单的Python字典。比如我们想从stackoverflow提取问题名、链接和描述。那么就可以在items.py做如下定义。
import scrapy
class DmozItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
title = scrapy.Field()
link = scrapy.Field()
desc = scrapy.Field()
3.第一个爬虫(spider)
爬虫是你自定义的类,用于让Scrapy从某个网站提取信息。你需要定义起始的URL(start_urls),如何跟踪链接以及如何检索网页内容并进行提取。
我们可以在命令行中输入scrapy genspider -t basic domz dmoz.org创建一个爬虫,得到spiders/domz.py。
# -- coding: utf-8 --
import scrapy
class DomzSpider(scrapy.Spider):
name = "domz" #用于定位爬虫
allowed_domains = ["dmoz.org"] #限定域名,就不会爬到baidu.com了
start_urls =[
"http://www.dmoz.org/Computers/Programming/Languages/Python/Books/",
"http://www.dmoz.org/Computers/Programming/Languages/Python/Resources/"
] # 起始的URL
def parse(self, response):
filename = response.url.split("/")[-2]+'.html'
with open(filename,'wb') as f:
f.write(response.body)
# parse是Scarpy在请求未指定回调时,用于处理下载响应的默认回调。
进一步想了解scrapy.Spider的话看这里。
4.工作吧!爬虫
命令行下输入scrapy crawl domz。
结束后会在项目文件下载生成两个HTML文件。单单下载网页并没有意义,我们需要从网页从提取数据才有意义。
5.数据提取
Scrapy使用基于Xpath或CSS表达式的Scrapy Selectors提取网页数据。
让我们在shell下使用一下Scrapy Selectors吧。scrapy shell "http://www.dmoz.org/Computers/Programming/Languages/Python/Books/"
In [1]: response.xpath('//title')
Out[1]: [Open Directory - Computers: Progr'>]
In [2]: response.xpath('//title').extract()
Out[2]: [u'Open Directory - Computers: Programming: Languages: Python: Books ']
In [3]: response.xpath('//title/text()')
Out[3]: []
In [4]: response.xpath('//title/text()').extract()
Out[4]: [u'Open Directory - Computers: Programming: Languages: Python: Books']
In [5]: response.xpath('//title/text()').re('(\w+):')
Out[5]: [u'Computers', u'Programming', u'Languages', u'Python']
因此,我们可以改写之前dmoz.py中的parse部分。
.......
def parse(self, response):
for sel in response.xpath('//ui/li'):
title = sel.xpath('a/text()').extract()
link = sel.xpath('a/@href').extract()
desc = sel.xpath('text()').extract()
print title, link, desc
重新运行scrapy crawl domz
这里我们只是把结果打印出来,实际运行应该是把数据保存下来,首先需要用到之前定义的DmozItem先结构化数据, 继续改写。
from tutorial.items import DmozItem
...
def parse(self, response):
for sel in response.xpath('//ui/li'):
item = DmozItem()
item['title']' = sel.xpath('a/text()').extract()
item['link'] = sel.xpath('a/@href').extract()
item['desc'] = sel.xpath('text()').extract()
yield item
重新运行scrapy crawl domz
6.链接跟踪
假设你不满足爬取起始页面,想继续爬取起始页面中你感兴趣的链接,那么我么就需要进一步改写之前的爬虫了。
def parse(self, response):
for href in response.css("ul.directory.dir-col > li > a::attr('href')"):
url = response.urljoin(href.extract())#构建绝对路径的URL
yield scrapy.Request(url, callback=self.parse_dir_contents)
def parse_dir_contents(self, response):
for sel in response.xpath('//ui/li'):
item = DmozItem()
item['title']' = sel.xpath('a/text()').extract()
item['link'] = sel.xpath('a/@href').extract()
item['desc'] = sel.xpath('text()').extract()
yield item
这里我们使用parse函数获取网页的url,然后通过scrapy.Request对获取的每一个url调用parse_dir_contents函数,提取数据。
7.数据储存
数据储存有很多方式,可以放在数据库中,由于是教程,我们使用最简单的scrapy crawl domz -o items.json把数据放在json文件中。