前言
文件系统是最常用的数据存储形式,所以,常用Linux操作系统的用户必然知道ext4、xfs等单机文件系统,用Windows操作系统的用户也都知道NTFS单机文件系统。各种业务场景下,不同的数据都存储于文件系统之上,大量业务逻辑就是基于文件系统而设计和开发的。提供最常用的存储访问方式,这是我们做文件系统的出发点之一。
另一方面,单机文件系统有其明显限制,主要是容量、文件数量限制,以及可靠、可用性限制。单机文件系统毕竟存储空间有限,且掉电或坏盘等故障会带来数据不可达或丢失。通过分布式文件系统解决这些问题,这是我们的出发点之二。
但做分布式文件系统会面临很多挑战,也会面临非常多的选择。
Google GFS论文面世之后,Hadoop HDFS随之诞生,HDFS的选择是处理大文件,面向MapReduce这种非在线数据分析业务,重吞吐而非延时,对HDFS内部存储的数据进行访问,需要借助其提供的专有命令行和SDK,意味着它并不是一个通用型的文件系统。它的主要架构是元数据服务(本文统一用MetaData Service的缩写MDS来指代元数据服务)和数据服务(本文统一用Data Storage Service的缩写DSS来指代数据服务),其中MDS是单点的,单点的MDS能做出一致的决策,为了保证MDS可靠性,一般会选择再做一个备份。HDFS的DSS则可以是很多个。因为文件大小和形式固定,元数据量不会太大,因而理论上单点MDS就可以支撑,不过单MDS仍限制了集群的规模。
HDFS之后,出现了一些其他的开源分布式文件系统,比如MooseFS。它也是类似的MDS+OSS架构,区别于HDFS的是,MooseFS没有对运行其上的业务做假设,它没有假设业务是大文件或海量小文件,也就是说,MooseFS的定位是像ext4、xfs、NTFS等单机文件系统一样的通用型文件存储。其实MooseFS底下用的就是单机文件系统,可以认为它只是将多台机器上的多个单机文件系统做了一个“逻辑上”的聚合,之所以这么说,是因为从数据角度,它主要是实现了一个多副本功能,而副本间的数据一致性并没有去严肃地保障。从元数据角度,MooseFS提供了一个本质上就是单机的MDS,但为了保证元数据的可靠性,MooseFS通过某些机制,接近实时地备份了元数据。

另外一个更为知名的开源分布式文件系统就是GlusterFS了,相比MooseFS等文件系统,GlusterFS的明显特点是它的“无元”架构,即它没有独立的MDS,GlusterFS使用一致性哈希算法去定位元数据和数据。我们在设计和开发自己的文件系统时,并没有选择这样的架构,因为它的缺点非常明显,例如元数据操作性能很差,而文件系统日常使用中,对元数据的操作占日常操作的比例比极高(50%以上);此外,这种“无元”的文件系统架构对故障的应对不够灵活,服务器进入集群或退出集群都会引起一致性哈希算法的重新计算,从而带来部分数据的迁移,进而影响业务IO。
近两年来,CephFS成为开源分布式文件系统的一颗璀璨新星。Ceph的RADOS对象存储层是一个理论完备且实现优秀的系统。CephFS基于RADOS,它的元数据和数据都是存储到Ceph RADOS之中。Ceph的哲学是首要确保数据稳定性而轻性能,但现实应用中性能往往也是强需求之一,某些场景甚至要求更看重性能。CephFS架构上利用了RADOS,它的MDS数据也存储到RADOS上,而不是存储到本地硬盘,理论和实现角度上看,这种做法可以复用RADOS,但也带来了较大的性能衰减。
CephFS MDS是支持Active-Active模式的,MDS不再是单点,多个MDS共同维护一个统一的命名空间。CephFS实现了它自己提出的动态子树划分算法,其目标是根据文件系统热点情况对MDS做动态的压力均衡。不过在大规模生产环境中,这个功能会带来运维的复杂度,因而实际被开启的不多。
人工智能、移动互联时代的一大数据特征,就是海量文件,为了做一个支持百亿级文件的分布式文件系统,我们该如何思考和设计呢?
方法论
在确定“方法论”之前,我们要先建立一些原则性认识。
其一是不会有one size fits all,我们不可能兼顾所有,必须有侧重点,有侧重就会有舍弃。“取舍”,相信是大多分布式开发者的心得。比如分布式系统,我们不可能突破CAP理论限制。面对各种各样的业务需求,如果我们只满足CP,有的业务对A有强需求怎么办?如果我们只满足AP,那相信我们强调数据一致性的存储工程师就不愿意动手,因为我们深知数据稳定是要坚守的底线。因此我们会细化,会支持针对业务的CA可以进行一定程度上的配置。

其二是要围绕“主线”去做设计,否则上层的实现会积重难返。我们的核心主线之一就是支持百亿千亿级别文件海量文件。从这个主线出发,我们会去针对性地思考关键问题,去做要点设计。我们都知道,核心设计决定未来。前面讨论到的MooseFS和GlusterFS等,为我们众多分布式系统研发者提供了学习案例,在它们基础上实现不了百亿级文件,因为已经积重难返。
下面从这两个原则出发,来讨论一下我们设计自己的分布式文件系统时考虑的要点。
要点设计
要支持百亿级文件,从前面“方法论”提出的大思路出发,我们认为要实现的关键点有以下几点。
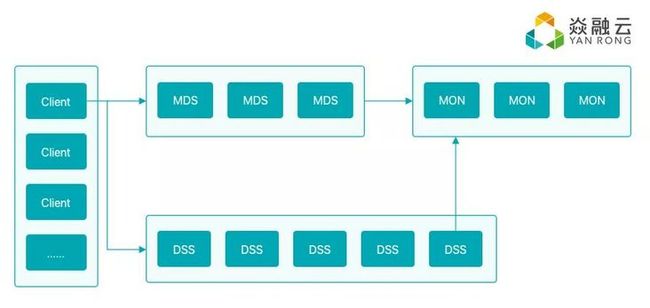
采用中心元数据服务器(即MDS)
这几乎是必然选择,只有使用了MDS,CAP中的A才更为可控,系统的整体架构也更加清晰,故障处理更加自如,数据放置策略、故障恢复策略也将更加方便和可控,因为这些行为都在MDS控制之下。
我们使用多MDS共同组成一个统一的命名空间,为了支持百亿级,对目录树必须做切分。围绕“切分”思路,我们可以做多种切分策略,不同策略有不同的效果。如何做策略就是工程实践问题了,从项目管控以及工程实现的复杂度角度考虑,我们目前实现的策略是按目录哈希切分策略,这已经能满足大多数场景的需求。在未来,我们会再实现其他策略。
MDS的另一设计要点是,是否使用本地硬盘。产生这点考虑,是借鉴到了CephFS的经验,CephFS复用RADOS,有好处也有坏处,坏处是性能受到较大影响,好处是工程实践角度更为清晰。我们认为,对元数据的操作要更重视性能,因此我们坚定地选择了MDS直接对接本地硬盘。
选择MDS使用本地硬盘后,下一个要考虑的要点是,是否直接使用本地MDS节点的文件系统,如ext4或xfs。使用本地文件系统,开发和实现会更加高效,,目前我们的选择是直接使用MDS的本地文件系统,将来,为了进一步提升MDS的操作性能,我们会直接操作裸盘的KV系统。
数据存储(即DSS)要点
DSS主要思路是bypass文件系统,跟MDS bypass文件系统类似,这里有两个阶段的考量,第一阶段利用本地文件系统,能快速实现功能。第二阶段是bypass文件系统,DSS直接操作裸盘,即做出一个独立的单机存储引擎,我们的主要考虑点是单机文件系统不利于海量小文件的存储和管理;其次,单机裸盘存储引擎,有助于我们追求更极致的性能,裸盘引擎更利于将来我们对NVMe等新型硬件和SPDK等新型技术栈做深入整合。目前,我们已经推出了基于裸盘的DSS存储引擎。
集群管理要点
分布式集群中,如何对节点是否离线、是否加入等关键事件进行判定,也是要考虑的核心问题之一。我们将这些任务交给集群管理节点,或称为monitor来处理。如何实现monitor集群,不需要多多考虑,基本上是实现一个paxos集群,近几年来用raft是一个“流行”趋势。
副本机制和CAP开关
副本机制是分布式系统实现数据可靠性的关键思路,它带来的CA问题将是面对不同业务时需要考虑的均衡点。如“方法论”所述,我们将CA的权衡做成选项,在不同应用场景中可以有不同的侧重。在这个简单思路之上,魔鬼就在复杂的细节里,难点主要在工程实践之中,充足的测试是验证这一机制的方法。
“瑞士军刀”式功能开关
要实现百亿级分布式文件存储,以上讨论了我们的出发点和“方法论”的关键要点。基于这些点做出来的系统是“骨架”完整的。
但仍如“方法论”所说,没有one size fits all的系统,我们接触的客户需求都是各种各样的,不会一个系统能满足所有业务场景和需求。因而我们的思路是在上面的核心之上,去做丰富的功能,并将主要功能做成开关式控制,某些甚至支持运行时调整。
下面讨论一些主要的功能
分池存储
一个较大规模的分布式集群中,往往会引入不同类型的存储设备。另一方面,用户的多种业务中,往往有关键业务和非关键业务之分。这两个角度,不管从哪个角度来考虑,我们都发现,有将物理资源分池管理的必要性。因此我们实现了对物理资源分池管理的功能,也可称之为分组、分zone,叫法无所谓,其核心要义是提供物理资源划分的能力。
我们实现了这个机制,目前基于这个机制,我们实现了故障域划分的效果,将资源分配到不同池,实现物理上的故障域划分,减小故障时的影响。
分层存储
有不少业务会存储大量冷数据,对冷数据,往往追求存储成本的节约。如果用户提供了SSD和HDD,并计划将海量的HDD空间用作冷存储,用少量的SSD空间用作热存储。我们可以将HDD空间分成一个池,将SSD空间分成一个池,逻辑上将SSD池架设到HDD池之上,实现一个分层存储的功能,将SSD池的冷数据转移到HDD池中去。
数据压缩
这个功能需求往往伴随分层存储存在,针对冷数据存储,用户业务往往会再使用我们的数据压缩功能先做数据压缩。
后记
本文“囫囵吞枣”般介绍了我们是如何去思考和设计百亿级分布式文件系统的。当前网络资源丰富,开源发达,通过借鉴其他系统的经验,再加上以前的积累,我们对做一个百亿级分布式文件系统形成了自己的理解。简单来说做百亿级分布式文件系统,首先是一个思路问题,其次是也很有挑战的工程实践。本文主要简单地讨论了整体“思路问题”部分,以后有机会我们再一起来讨论小模块的设计细节和实现问题。