log4j2 RollingRandomAccessFile配置
一、需求背景
1. 日志按小时压缩成zip文件。
2. 仅保存距离当前时间最近24小时的历史压缩文件。
3. 压缩封存的zip文件,按照零点为参考点纠偏。
4. 将com.roadway.acceptor.base.DebugUtils类的日志输出到指定文件,且不再输出到其他文件。
二、log4j2 配置实现
/data/gpslog
三、配置说明
1. monitorInterval,博客配置的为120,单位为秒。即在服务运行过程中发生了log4j2配置文件的修改,log4j2能够在monitorInterval时间范围重新加载配置,无需重启应用。
2. property配置文件全局属性的声明,使用方式为:${声明的属性名称}。
${sys:catalina.home}为tomcat部署路径,例如:/data/tomcat。
3. RollingRandomAccessFile基本属性
- name:Appender名称
- immediateFlush:log4j2接收到日志事件时,是否立即将日志刷到磁盘。默认为true。
- fileName:日志存储路径
- filePattern:历史日志封存路径。其中%d{yyyyMMddHH}表示了封存历史日志的时间单位(目前单位为小时,yyyy表示年,MM表示月,dd表示天,HH表示小时,mm表示分钟,ss表示秒,SS表示毫秒)。注意后缀,log4j2自动识别zip等后缀,表示历史日志需要压缩。
4. TimeBasedTriggeringPolicy
- interval:表示历史日志封存间隔时间,单位为filePattern设置的单位值
- modulate:表示是否历史日志生成时间纠偏,纠偏以零点为基准进行。比如:15:16生成了msg.2017041715.zip文件,那么纠偏后会在16:00生成msg.2017041716.zip
5. ThresholdFilter
- level,表示最低接受的日志级别,博客配置的为INFO,即我们期望打印INFO级别以上的日志。
- onMatch,表示当日志事件的日志级别与level一致时,应怎么做。一般为ACCEPT,表示接受。
- onMismatch,表示日志事件的日志级别与level不一致时,应怎么做。一般为DENY,表示拒绝。也可以为NEUTRAL表示中立。
6. 保存24小时历史日志,但不想用文件索引
备注:
1. age的单位:D、H、M、S,分别表示天、小时、分钟、秒
2. basePath表示日志存储的基目录,maxDepth=“1”表示当前目录。因为我们封存的历史日志在basePath里面的backup目录,所以maxDepth设置为2。
7. RollingRandomAccessFile设置bufferSize不生效问题
- a. log4j2配置如下:
......
- b. 使用异步Logger方式输出日志
............
- c. 验证
经过反复测试验证,日志始终实时刷新到磁盘,这是为什么?查看log4j2文档发现:
Asynchronous loggers and appenders will automatically flush at the end of a batch of events, even if immediateFlush is set to false. This also guarantees the data is written to disk but is more efficient.
因此,如果期望使用 RollingRandomAccessFile异步的方式打印输出日志,bufferSize是无法生效的且也没有必要采用buffer的方式。
请参考log4j2官网地址
RandomAccessFile的常见用法
1.RandomAccessFile的简介
1.1为什么要用到RandomAccessFile
我们平常创建流对象关联文件,开始读文件或者写文件都是从头开始的,不能从中间开始,如果是开多线程下载一个文件我们之前学过的FileWriter或者FileReader等等都无法完成,而当前介绍的RandomAccessFile他就可以解决这个问题,因为它可以指定位置读,指定位置写的一个类,通常开发过程中,多用于多线程下载一个大文件.
1.2.常用方法简介
构造方法:RandomAccessFile raf = newRandomAccessFile(File file, String mode);
其中参数 mode 的值可选 "r":可读,"w" :可写,"rw":可读性;
成员方法:
seek(int index);可以将指针移动到某个位置开始读写;
setLength(long len);给写入文件预留空间:
2.RandomAccessFile的特点和优势
这个对象有两个优点
1.既可以读也可以写
RandomAccessFile不属于InputStream和OutputStream类系的它是一个完全独立的类,所有方法(绝大多数都只属于它自己)都是自己从头开始规定的,这里面包含读写两种操作
2.可以指定位置读写
RandomAccessFile能在文件里面前后移动,在文件里移动用的seek( ),所以它的行为与其它的I/O类有些根本性的不同。总而言之,它是一个直接继承Object的,独立的类。只有RandomAccessFile才有seek搜寻方法,而这个方法也只适用于文件.
3.通过案例来熟悉RandomAccessFile的最常用的操作
首先创建一个DownLoadThread的类继承Thread
public class DownLoadThread extends Thread {
private long start;
private File src;
private long total;
private File desc;
/**
*
* @param start
* 开始下载的位置
* @param src
* 要下载的文件
* @param desc
* 要下载的目的地
* @param total
* 要下载的总量
*/
public DownLoadThread(long start, File src, File desc, long total) {
this.start = start;
this.src = src;
this.desc = desc;
this.total = total;
}
@Override
public void run() {
try {
// 创建输入流关联源,因为要指定位置读和写,所以我们需要用随机访问流
RandomAccessFile src = new RandomAccessFile(this.src, "rw");
RandomAccessFile desc = new RandomAccessFile(this.desc, "rw");
// 源和目的都要从start开始
src.seek(start);
desc.seek(start);
// 开始读写
byte[] arr = new byte[1024];
int len;
long count = 0;
while ((len = src.read(arr)) != -1) {
//分三种情况
if (len + count > total) {
//1.当读取的时候操作自己该线程的下载总量的时候,需要改变len
len = (int) (total - count);
desc.write(arr, 0, len);
//证明该线程下载任务已经完毕,结束读写操作
break;
} else if (len + count < total) {
//2.证明还没有到下载总量,直接将内容写入
desc.write(arr, 0, len);
//并且使计数器任务累加
count += arr.length;
} else {
//3.证明改好到下载总量
desc.write(arr, 0, len);
//结束读写
break;
}
}
src.close();
desc.close();
} catch (Exception e) {
e.printStackTrace();
}
}
}
然后定义主方法进行文件的测试
public class TestRandomAccess {
public static void main(String[] args) {
//关联源
File src = new File("a.txt");
//关联目的
File desc = new File("b.txt");
//获取源的总大小
long length = src.length();
// 开两条线程,并分配下载任务
new DownLoadThread(0, src, desc, length / 2).start();
new DownLoadThread(length / 2 , src, desc, length - (length / 2)).start();
}
}
4.效果展示
a.txt的内容
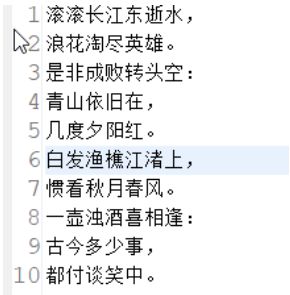
b.txt的内容

5.总结
从以上分析可以看出RandomAccessFile最大两个特点:
1.可以指定位置开始操作
2.既可以读,也可以写
所以,我们但凡遇到不是需要从文件中中间部分开始读取的时候,可以使用RandomAccessFile这个类,比如:多线程下载是最常用的应该场景
以上为个人经验,希望能给大家一个参考,也希望大家多多支持脚本之家。