作为深度学习的基础,人工神经网络模型一直是人工智能的研究热点,也在各个领域发挥着重要的作用。好的模型往往伴随着庞大的体积和海量的参数,这不利于模型的复现和部署。
拿自然语言处理领域(NLP)中最常见的词向量模型来举例。想要训练一个高质量的词向量模型,就需要大量优质的语料来支持。对于使用广泛的语种,比如英语,获取语料和训练模型相对容易。反观一些小语种,语料少,获取难,纵有再好的网络结构,训练出来的模型性能也不尽人意。
难道小语种的NLP研究就没办法推进下去了吗?
知识蒸馏
知识蒸馏算法为解决这类问题提供了一种新的思路。在化学中,蒸馏是一个有效的分离沸点不同的组分的方法,同理,简单地理解知识蒸馏,它能将复杂模型(Teacher)中的知识提取出来,迁移到另一个轻量级模型(Student),达到压缩模型的目的。 这种做法既减少了对硬件的要求,缩短了计算时间,又能学到复杂模型中的泛化能力,实现近似原模型的效果。
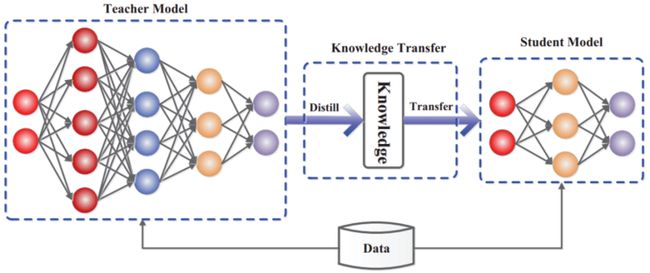
通过这种方法,小语种的词向量模型也能像英语词向量模型一样准确。
接下来让我们看看,小模型是如何解决大问题的~
词向量是什么
一切自然语言处理任务都始于文本在计算机中的表示。随着文本表示方法的不断演变,目前最热门的方法当属词向量模型。它的核心思想是通过大量的语料训练,将词转化为稠密的向量,映射到向量空间中,并且对于意思相近的词,它们对应的向量也相近。
准确的词向量模型是其他下游任务(文本相似度、情感分类、信息抽取等)的基础和保证。想要获得优质的词向量模型,需要大量高质量的语料的支持。然而,绝大多数现有的词向量方法都有一个共同点——它们只支持单语言,通常是英语。这使得它们无法直接应用到其他语言场景中。
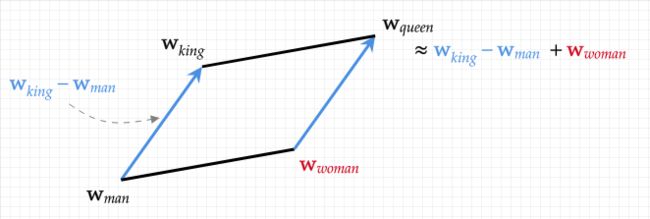
上图展示了一个词向量的简单例子:
词向量模型可以将“king”,“queen”,“man”,“woman”映射到一个向量空间中去,通过向量的基本运算(例如相加和相减),我们可以计算出这些词之间的语义关系。
在这个例子中,queen=king-man+woman
词向量+知识蒸馏=?
近年来,多语种的文本表示方法受到了广泛的关注,人们提出了很多方案试图解决这个问题。常见的方法就是分别用每种语言来训练对应的词向量模型,但由于有些语种的语料很少,难以满足模型训练的要求。
曾有学者提出使用经典的基于sequence-to-sequence的encoder-decoder框架,首先实现从一种语言到另一种语言的机器翻译模型,然后将encoder层的输出作为句子的向量(LASER模型)。
这种模型可以很好地识别出被准确翻译成不同语言的句子,但是对于没有被准确翻译的句子,该模型很难评估他们的相似度。另外,训练这种模型也需要极高的硬件条件支持,得到一个支持93种语言的词向量模型,大约需要在16块NVIDIA V100 GPUs上训练5天时间。

最近,有相关研究人员想到了一个idea来解决这个问题:对于意思相同,但是翻译成了不同语言的句子,他们映射到向量空间中的位置应该是一致的。基于此,他提出使用知识蒸馏的方法,将现有的单语言词向量模型扩展到新的语言上去。
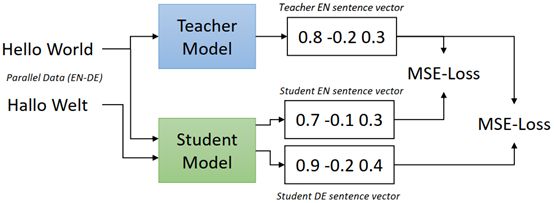
整体的解决思路如下:
我们需要一个源语言的词向量模型作为teacher model,一个从源语言s到目标语言t的平行语料库((s1,t1 ), … ,(sn , tn)),值得注意的是,ti可以是不同的语种。然后,使用均方误差作为loss,训练一个student model,使得student model的输出尽可能地靠近teacher model。
通过这样的方式,student model可以很好地学习到teacher model的泛化能力,并且拥有两条非常重要的属性:
A. 跨语言的向量空间也呈现出一致性。换言之,由同一个句子翻译成的不同语言,它们的向量是非常接近的;
B. teacher model中所包含的向量空间的属性能被很好地转移到其他语种中去。
相比于其他的训练多语言词向量模型的方法,这种方法有如下几个优点:
A. 仅仅只需要非常少量的样本,就可以将已有的模型扩展到新的语言上去;
B. 它可以更容易地在向量空间中确保达到预期的性能;
C. 整个训练过程对硬件的要求非常低。
为了验证想法的可行性,相关科研人员做了以下的实验:
在模型的选择方面,主要使用英语的SBERT模型作为teacher model,使用XLM-RoBERTa(XLM-R)作为student model。英语的SBERT模型词典包含了30k的英语tokens,在多个句向量任务中取得了state-of-the-art的效果。XLM-R使用了SentencePiece作为文本分词器,很好地回避了某些语种所需要的特殊预处理,可以直接应用到所有语言的原始文本上去,此外,它的词典包含来自一百多种语言的250k的tokens,非常适合做多语言词向量模型。
在训练数据方面,主要使用了以下的数据集:

对于某些资源较少的语言,获取平行语料是很困难的,因此也使用了一些双语词典来扩充语料,本次实验主要使用到的词典有以下两个:
• MUSE
• Wikititles
为了验证模型效果,研究人员主要在Multi- and Cross-lingual Semantic Textual Similarity (STS),Bitext Retrieval和Cross-lingual Similarity Search三个任务上进行了实验。
STS任务的主要目标是为一对句子输出一个值来反映它们之间的语义相似度。例如,可以用0分表示两个句子完全无关,5分表示两个句子的语义完全一致。
在公开数据集STS 2017 dataset上,作者使用斯皮尔曼等级相关系数来评估不同模型的效果。将多个语种的得分取平均值,我们可以发现,蒸馏模型XLM-R←SBERT-paraphrases的结果(83.7)优于其他传统算法模型LASER(67.0),mUSE(81.1),LaBSE(73.5)。
Bitext Retrieval任务旨在从两个不同语种的语料库中识别出互为翻译的句子对。作者使用BUCC mining task中的数据集来计算模型的F1值,蒸馏模型XLM-R←SBERT-paraphrases的结果(88.6)和其他传统算法模型LASER(93.0),mUSE(87.7),LaBSE(93.5)互有高低。由于蒸馏模型会把某些语义相似但是缺失部分细节元素(例如日期,地点等)的句子也判断成互为翻译的句子对,所以在这个任务下,它的结果不是最好的。但是这仍然能够说明,它非常适合寻找语义相似的句子对。
关于Cross-lingual Similarity Search任务,作者选择了在Tatoeba数据库上进行实验。这个任务需要找到与所有源语言的句子最相似的其他语言的句子,结果如下:
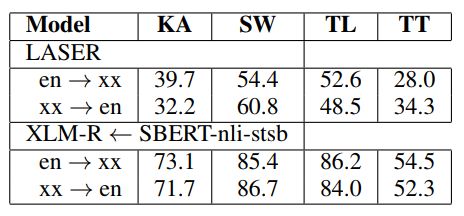
可以看到在小语种上,蒸馏模型的效果要明显好于传统模型。
今天和大家分享了一种基于蒸馏思想的训练词向量模型的方法,可以实现将一个高质量的单语言模型扩展到其他语言上去。从实验结果来看,对于常见问题,蒸馏模型也能有不错的效果,在小语种上的表现尤为突出,同时蒸馏模型也节省了很大一部分的硬件开支,是很值得尝试的一种方法。
后续我们还会分享更多相关领域的文章,感兴趣的小伙伴们不要忘了关注我们的账号 LigaAI@sf,同时欢迎点击我们的官方网站 LigaAI-新一代智能研发管理平台,了解我们~
参考文献:
[1] Reimers N , Gurevych I . Making Monolingual Sentence Embeddings Multilingual using Knowledge Distillation[J]. 2020.
[2] Artetxe M , Schwenk H . Massively Multilingual Sentence Embeddings for Zero-Shot Cross-Lingual Transfer and Beyond[J]. 2019.
[3] Chidambaram M , Yang Y , Cer D , et al. Learning Cross-Lingual Sentence Representations via a Multi-task Dual-Encoder Model[C]// Proceedings of the 4th Workshop on Representation Learning for NLP (RepL4NLP-2019). 2019.
[4] Yang Y , Cer D , Ahmad A , et al. Multilingual Universal Sentence Encoder for Semantic Retrieval[J]. 2019.
[5] Feng F , Yang Y , Cer D , et al. Language-agnostic BERT Sentence Embedding[J]. 2020.
图源:https://www.ed.ac.uk/informat...