一、前言
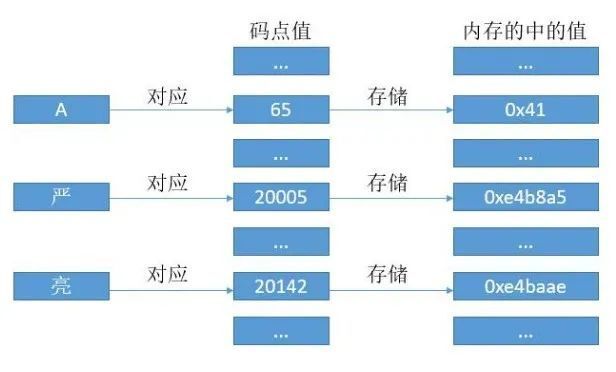
有人丢给你下面这张图,如果你能清楚地说明它们之间的关系以及用途,那么你对字符编码的理解肯定过关了。
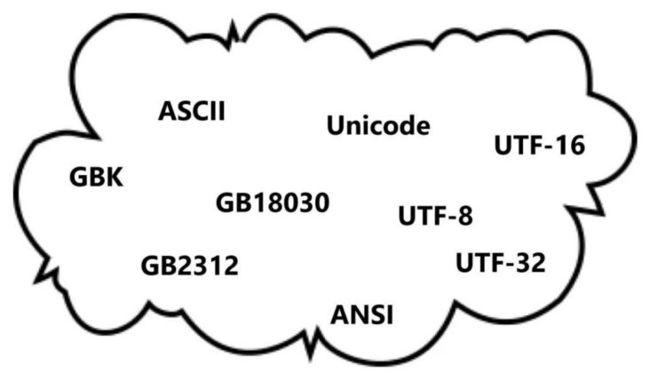
不知道看了上面这张图,是否有混乱的感觉,本文试着给你梳理、讲透这些孤立的几个单词之间联系......
二、关于字符编码,你所需要知道的
2.1 ASCII(寡头垄断时期)
计算机内部,所有信息最终都是一个二进制值。每一个二进制位(bit)有0和1两种状态,8个二进制位称之为1个字节。把键盘上(如下图)所有按键的状态。

用8位二进制共256种表示绰绰有余。把所有的空格、标点符号、数字、大小写字母分别用连续的字节状态表示,一直编到了第127号,这样计算机利用8位二进制位(1个字节)就可以用来存储英语的文字了,这就是大名鼎鼎的ASCII(美国信息互换标准代码)。当时世界上所有的计算机都用同样的ASCII方案来保存英文文字。
2.2 非 ASCII 编码(汉字编码的发展)
伴随着互联网的兴起,计算机技术的发展,世界各地都开始使用计算机,但是很多国家用的不是英文,所适用的字母里有许多是ASCII里没有的。
为了可以在计算机保存他们的文字,决定采用 127号之后的空位来表示这些新的字母、符号,还加入了很多画表格时需要用下到的横线、竖线、交叉等形状,一直把序号编到了最后一个状态255。
从128 到255这一页的字符集被称“扩展字符集”。此之后,贪婪的人类再没有新的状态可以用了。
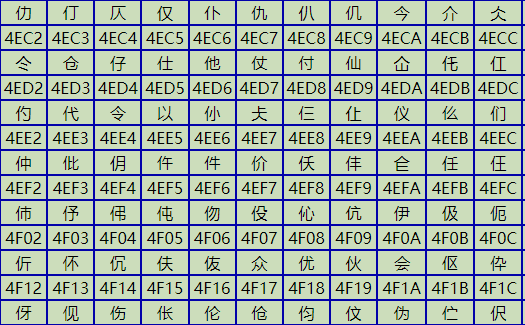
随着计算机在中国流行时,已经没有可以利用的字节状态来表示汉字,况且有6000多个常用汉字需要保存。但这难不倒智慧的中国人民,我们就把那些127号之后的奇异符号们直接取消掉,并规定:一个小于127的字符的意义与原来相同,但两个大于127的字符连在一起时,就表示一个汉字,前面的一个字节(他称之为高字节)从0xA1用到0xF7,后面一个字节(低字节)从0xA1到0xFE,这样我们就可以组合出大约7000多个简体汉字了。
在这些编码里,我们还把数学符号、罗马希腊的字母都编进去了,连在 ASCII 里本来就有的数字、标点、字母都统统重新编了两个字节长的编码,这就是常说的”全角”字符。而原来在127号以下的那些就叫”半角”字符了。中国人民看到这样很不错,于是就把这种汉字方案叫做 “GB2312”。GB2312 是对 ASCII 的中文扩展。
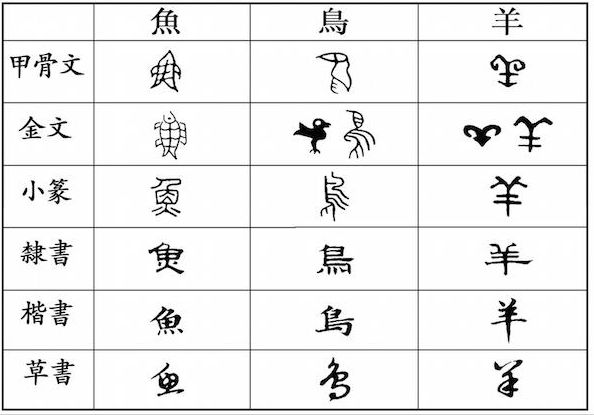
(图片来源于网络)
但是中国的汉字太多了,我们很快就就发现有许多人的人名没有办法在这里打出来。我们不得不继续把GB2312 没有用到的码位找出来老实不客气地用上。后来还是不够用,于是干脆不再要求低字节一定是127号之后的内码,只要第一个字节是大于127就固定表示这是一个汉字的开始,不管后面跟的是不是扩展字符集里的内容。
结果扩展之后的编码方案被称为 GBK 标准,GBK包括了**GB2312 **的所有内容,同时又增加了近20000个新的汉字(包括繁体字)和符号。后来少数民族也要用电脑了,于是我们再扩展,又加了几千个新的少数民族的字,GBK扩成了 GB18030。
2.3 非 ASCII 编码
百花齐放,各自编码标准带来的问题
当时各个国家都像中国这样搞出一套自己的编码标准,结果互相之间谁也不懂谁的编码,谁也不支持别人的编码,就连大陆和台湾这样只相隔了150海里,使用着同一种语言,也分别采用了不同的 DBCS 编码方案。
当时的中国人想让电脑显示汉字,就必须装上一个“汉字系统”,专门用来处理汉字的显示、输入的问题,像是那个台湾的愚昧封建人士写的算命程序就必须加装另一套支持 BIG5。
编码的什么“倚天汉字系统”才可以用,装错了字符系统,显示就会乱了套!这怎么办?
而且世界民族之林中还有那些一时用不上电脑的穷苦人民,他们的文字又怎么办?
(图片来源于维基百科)
2.4 Unicode
世界这么乱,得我来管管,大一统时期
ISO(国际标谁化组织)的国际组织决定着手解决这个问题。采用的方法很简单:废了所有的地区性编码方案,重新搞一个包括了地球上所有文化、所有字母和符号的编码!
他们打算叫它“Universal Multiple-Octet Coded Character Set”,简称UCS, 俗称 “Unicode”。Unicode相当于一个抽象层,给每个字符一个唯一的码点(code point)。
用 0x000000 - 0x10FFFF 这么多的数字去对应全世界所有的语言、公式、符号。然后把这些数字分成 17 部分,把常用的放到 0x0000 - 0xFFFF,也就是 2 个字节,叫做基本平面 (BMP);从 0x010000 - 0x10FFFF 再划分为其他平面。

(图片来源于维基百科)
栗子:「v维」
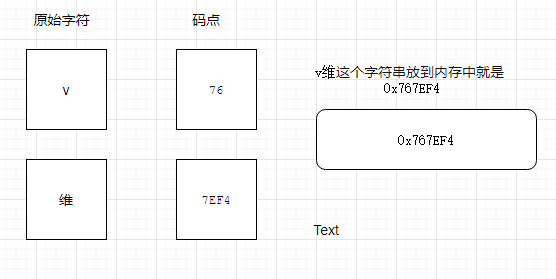
如果 「v维」 这个字符串放到内存中就是 0x767ef4。问题来了,计算机怎么知道,几个字节代表一个字符呢?是 0x76呢?还是 0x7ef4 呢?还是 0x767ef4?
Unicode只是对信源编码,对字符集数字化,解决了字符到数字化的映射。接下来面临如何解决存储和传输的问题。
三、传输和存储
用通信理论的思路可以理解为:
Unicode是信源编码,对字符集数字化;
UTF-32、UTF-16、UTF-8是信道编码,为更好的存储和传输。
3.1 UTF-32
UTF-32 编码,简单明了,码点值是多少,内存中就存多少,UTF-32 缺点很明显了,字母 A 原本只需要 1 个字节去存储,而现在却用了 4 个字节去存,大部分位置都是 0。
提问:我们为什么要多存那么多零呢?

3.2 UTF-16
问题:「亮」 码点值是 20142,换成 16 进制就是 0x4eae,内存中是按字节进行编址的。所以我们是先存4e呢?还是ae?
一个 Unicode 的码点值会对应一个数字,对于Basic平面的字符,我们直接把这个数字存到内存中。
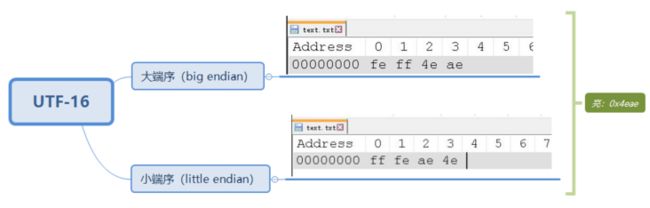
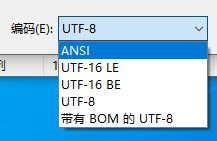
UTF - 16 编码的时候,除本身的字节,为了区分大端序和小端序,最开头还多了两个字节,ff和fe。feff代表大端序,fffe代表小端序。

(Notepad中的BOM)
小知识:feff和fffe也叫做 BOM,它可以区分不同编码。UTF-16 编码最小单位是两个字节,所以有字节序的问题,从而加了 BOM 来区分是大端序还是小端序。
3.3 UTF-8
UTF-8 顾名思义,是一套以 8 位为一个编码单位的可变长编码。会将一个码位编码为 1 到 4 个字节。一个码点值会生成 1 个或多个字节,然后把这些字节按顺序存就可以了。
小知识:UTF-8 无 BOM 或者 UTF-8 BOM。UTF - 8 的 BOM 是 EF BB BF ,UTF-8 并不存在字节序的问题,因为它的最小编码单位就是字节。
UTF-8 并不需要区分大端序还是小端序,所以可以不需要 BOM。如果加了 BOM,对于一些读取操作,它可能会把读取到的 BOM 认为是字符,从而造成一些错误。所以我们保存 UTF - 8 编码的文件时,最好选择无 BOM。
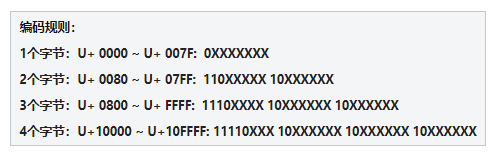
栗子:「知」
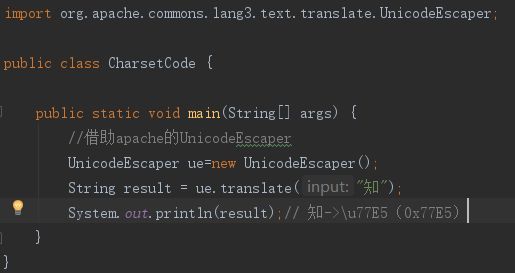
根据上表中的编码规则,「知」字的码位 U+77E5 属于第三行的范围:

这就是将U+77E5 按照 UTF-8 编码为字节序列E79FA5 的过程,反之亦然。
3.4 ANSI
「ANSI」指的是对应当前系统 locale 的遗留(legacy)编码。
Windows 里说的「ANSI」其实是 Windows code pages,这个模式根据当前 locale 选定具体的编码,比如简中 locale 下是 GBK。把自己这些 code page 称作「ANSI」是 Windows 的臭毛病。在 ASCII 范围内它们应该是和 ASCII 一致的。
3.1 扩展思考
问:在java中char 型变量中能不能存贮一个中文汉字,为什么?
答:java中使用的编码符号集是Unicode(不涉及特定的编码方式,给每个符号分配一个二进制编码,目前已容纳容纳100多万个符号),而汉字已纳入Unicode字符集, 而char类型占两个字节,用来表示Unicode编码,所以是可以存储汉字的
问:tomcat的中默认ISO-8859-1编码,如何解决web项目中的乱码问题?
答:
方式一:修改tomcat下的conf/server.xml文件
- URIEncoding=”UTF-8“:即可让Tomcat(默认ISO-8859-1编码)以UTF-8的编码处理请求参数。
- useBodyEncodingForURI="true":是指请求参数的编码方式采用请求体的编码方式。
方式二:
1)当使用字符流向浏览器发送页面信息时,默认查询的是ISO-8859-1码表
- 设置1:response.setCharacterEncoding("UTF-8")
- 设置2:response.setContentType("text/html;charset=UTF-8")
2)客户端请求服务器出现的中文乱码解决方式
POST请求方式:浏览器当前使用什么编码,表单提交的参数就是什么编码,
服务端处理:
request.setCharacterEncoding("utf-8")。
- GET请求方式:
String name=request.getParameter("name");//首先拿到参数的值
//得到的byte[] 再重新用utf-8去编码,即可得到正常的值
name=new String(name.getBytes("iso-8859-1")/**用参数的值用iso-8859-1来解码**/,"utf-8");String name=request.getParameter("name");//首先拿到参数的值//得到的byte[] 再重新用utf-8去编码,即可得到正常的值name=new String(name.getBytes("iso-8859-1")/**用参数的值用iso-8859-1来解码**/,"utf-8");
说明:tomcat的 j2ee实现对表单提交即 post方式提示时处理参数采用缺省的 iso-8859-1来处理,tomcat对 get方式提交的请求对 query-string 处理时采用了和 post方法不一样的处理方式。
四、总结
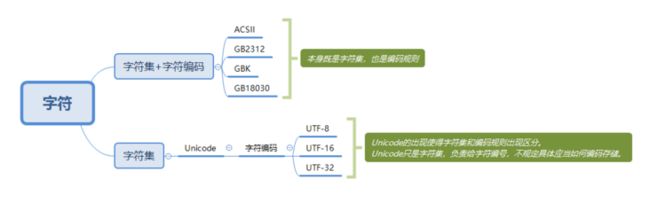
回到前言中的那个问题,整理了下面这张图,不知现在的你是否对字符编码有了更清楚的认识......
用通信理论的思路可以理解为:
Unicode是信源编码,对字符集数字化;
UTF-32、UTF-16、UTF-8是信道编码,为更好的存储和传输。
参考资料
作者:vivo互联网服务器团队-Zhu Wenjin