在王坚博士的《在线》一书中提到,单纯谈数据的“大”,意义是不大的。欧洲核子研究中心(CERN)进行一次原子对撞产生的数据大到惊人,而如何通过计算的方式去挖掘出这些数据背后的价值,才是数据意义的本身。HPC高性能计算,就是完成这种价值转换的重要手段。近年来,HPC的应用范围已经从纯学术扩展到资源勘探、气象预测、流体力学分析、计算机辅助设计等更多场景。这些HPC应用程序会产生或依赖大量数据,并将其存储在PB级别的共享的高性能文件系统中。然而,无论是HPC应用的用户,还是高性能文件系统的开发人员,对这些文件的访问模式了解都非常有限。
我们在Fast20中发现了一篇很有趣的论文《Uncovering Access, Reuse, and Sharing Characteristics of I/O-Intensive Files on Large-Scale Production HPC Systems》,这篇论文研究了超级计算机的生产环境上I/O密集型HPC应用对文件访问模式。
据论文作者所知,这是第一篇对HPC系统中IO密集型文件的访问、重复使用以及共享特性进行深入研究的论文。这篇论文第一次揭示了(1)HPC中的各个文件是读密集型,还是写密集型,或是读写密集型;(2)在多个任务中,反复访问同一个文件的时间间隔;(3)多个应用程序对同一个文件的共享行为。更进一步地,这篇论文还基于文件的IO时序,分析了导致文件系统性能低下的主要原因,这些原因导致了在单次任务和多次任务间的IO的性能波动。
论文总结了十个发现,我们结合自己的理解,补充了很多背景知识,摘要了其中的要点,和大家做个分享(前方及其高能),大家可以细细品读论文作者的研究思路和手段,也可以直接浏览论文归纳的十大发现。以下文章中未注明的图表,均来自论文原文(图表标号使用原文中的标号)。感兴趣的同学可以阅读论文原文,也欢迎大家和我们一起讨论。
01 概述
在大规模高性能计算HPC集群上,各个应用的数据读写通常都在几十上百TB。过往对于IO特征上的研究大多基于单个应用程序级别,针对特定应用提供底层存储的优化建议。而大家对于HPC系统中不同应用程序对各种文件的IO特点,了解非常有限。因为这需要在HPC生产环境中,跟踪应用在大量任务执行过程中产生的IO信息,众所周知,这种细粒度的跟踪和分析,对系统的性能是会造成很大影响的,这也正是很难在HPC的生产环境中进行类似研究的原因。然而,这种研究还是极具价值的,它对于我们存储研发人员更深入理解针对文件的IO、文件反复读写的模式、IO性能上的波动、优化文件放置策略,都非常有意义。
论文的研究使用的是轻量级的IO监控工具Darshan(Darshan旨在以最小的开销捕获应用程序IO行为的准确情况,包括文件的访问模式等特征。Darshan名称取自梵语单词“ sight”或“ vision”, https://www.mcs.anl.gov/research/projects/darshan/),论文作者团队在Top500超级计算机集群Cori的生产环境上,进行了长达四个月(累计近3600万个节点小时)的跟踪和分析。
02 研究的背景和分析方法
首先介绍一下Cori,超级计算机集群Cori在最新的世界HPC Top500中排名第十三位(https://www.top500.org/list/2019/11/),Cori具备约27 Pflop / s的峰值计算性能,包含9,688个Intel Xeon Phi和2388个Intel Haswell处理器。Cori使用的是基于磁盘的Lustre文件系统,该文件系统由约10,000块磁盘组成,这些磁盘被组织为248个Lustre OST。每个OST都配置有GridRAID,并具有用于处理IO请求的相应的OSS。文件系统的总大小约为30 PB,IO峰值带宽为744 GB / s。Cori是长这样的:

图片来自互联网
IO数据监控和采集。论文作者使用Darshan这个监控工具对应用程序进行文件IO访问模式等特征的收集。在研究期间,Cori上所有用户都默认启用了Darshan V3.10。Darshan收集了包括用户ID、作业ID、应用程序ID、开始时间戳、结束时间戳和进程数等关键信息。Darshan还针对代表性的IO接口类型 POSIX IO、MPI IO(Message Passing Interface,MPI是一种用于对并行计算机进行编程的通信协议,是一个用于进行消息传递的应用程序程序接口、协议和语义规范,MPI是当今高性能计算中被广泛使用的IO编程模型,这种编程模型需要底层存储的支持)、STD(Standard)IO的IO调用接口进行了监控和统计。统计的指标包括读/写数据量、读/写/元操作的总时间、执行IO的进程ID,以及不同应用程序进程中IO大小和IO时间的波动。最后,Darshan还收集了Lustre文件系统级别的一些指标,例如条带宽度和对文件条带化所涉及的OST ID。但是,Darshan没有记录各个文件的实际大小,而只记录了文件被传输的数据的大小。在论文研究期间,作者团队供收集了大约8400万条日志(每次任务执行对应一条日志),这些日志涵盖在8489个应用程序的5200万个日志文件中,涉及651个用户和12.8 PB的数据传输(其中6.9 PB读取数据,5.9 PB写入数据)。
在以下篇幅中,会使用到几种图表,包括:
- 热度分布图,用于显示两个指标之间特定关系的关联程度。热度分布图颜色的强度表示显示两个坐标指标上对应的文件数。
- CMF图。CMF图用于显示横轴指标的累积分布。垂直的蓝色虚线用于指示横轴指标的平均值。一些CMF图显示的是一个指标的CoV(变异波动系数(%),https://en.wikipedia.org/wiki/Coefficient_of_variation)的累计分布(简单来说,就是这个指标在多大范围内波动的累计概率情况),以突出显示这个指标的归一化波动特性。
- Violin Plot,这些图用于以垂直格式显示指标不同值的密度(以文件数表示),水平的蓝色实线用于指示密度分布的平均值。
如何选择IO密集型文件
前面提到过,Cori的Darshan日志包含了约5200万个文件。但是,分析表明,在研究期间,大多数日志文件中执行的IO操作很少。图2横坐标表示计算任务中一个文件的传输数据量(读或写),纵坐标表示一个文件在多少个任务中被读写,不同色块代表涉及的文件数量。从图中可以看出,大多数文件的IO小于100 GB,并且整个计算过程中只被访问一次。实际上,超过99%的文件传输数据少于1 GB。这并不意味着实际文件大小小于1 GB,只是文件的数据传输量小于1 GB。
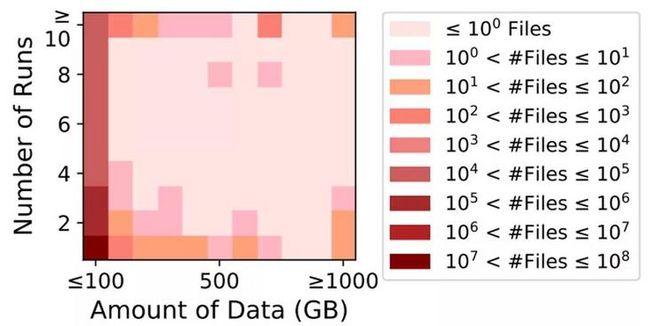
Figure 2: 超过99%(约等于5200万个)的文件传输数量<1GB,且研究期间只被访问一次
因此,大多数的文件对建立与HPC应用程序的主要IO模型有关的特征没有帮助。这些文件包括用户注释、脚本、可执行文件、非IO密集型应用程序输出以及错误日志等。而论文的研究重点是 “IO密集型”文件,这些文件在研究期间至少完成了100 GB的数据传输,并且至少被2次任务访问,作者通过研究这些IO密集型文件以捕获最主要和最具代表性的IO模式。从这里开始,将这些IO密集型文件简称为“文件”。这些IO密集型文件的日志跨越了约40万次任务、791个应用程序、149个用户、8500个文件和7.8 PB的数据传输(4.7 PB的读取数据和3.1 PB的写入数据),超过70%的用户对2个以上的文件执行IO操作,每个用户平均对57个文件执行IO。
文件分类
接下来,作者根据IO密集型文件执行的IO操作类型对这些文件进行分类,这有助于理解后续章节中针对不同类型文件访问特点所得到的发现。图3(a)显示了每个文件读取数据传输量与写入数据传输量的热力图。文件可以分为三个不同的种类,右下方的一组由22%的文件组成,这些文件在四个月内传输的大部分为读取数据,论文将这些文件称为读密集型文件或RH(Read-Heavy)文件。左上方的一组由仅传输写数据的文件(写密集型文件或WH(Write-Heavy)文件)组成,占IO密集型文件的7%。位于文件右上角的一组具有最大的占比(占71%),由读写密集型文件组成(称为RW(Read-Write)文件)。
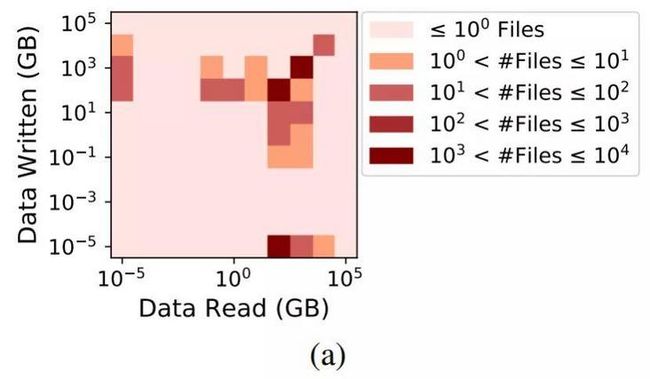
Figure 3: (a) IO密集型文件分为三组-读密集型/写密集型/读写密集型
发现1. HPC文件可分为读密集型(RH)、写密集型(WH)或读写密集型(RW) 。论文首次量化了文件中有很大一部分是读密集型的文件(占22%),小部分是写密集型文件(占7%),这7%的文件被不断写入,但未被读取。有71%的HPC文件是RW文件(即读写密集型文件)。这种的文件分类可用于设置文件放置决策,包括Burst Buffer区在内的分层存储放置策略,其中每个层分别适用于不同类型的IO操作。
读写任务分类
尽管可以将文件根据IO类型分为三种,但它们可以被多个“应用程序的任务”访问,各任务都可以执行读取和写入操作。任务是指在计算节点上运行的各种作业,由一个节点内的多个MPI进程以及可能的共享内存的线程组成。作者发现,绝大多数任务要么执行读密集型操作,要么执行写密集型。为了证明这一点,作者使用以下公式计算每次任务的读写数据量之差:|数据读取-写入数据| /(数据读取+写入数据)。该公式的值范围是0到1,1表示任务所处理的所有数据都是只读或只写,0表示读取和写入数据传输量相等。图3(b)显示所有任务中,超过82%的值非常接近1,即它们是读密集型或写密集型的。在IO上下文中,作者将读密集型任务简称为“读任务”,将写密集型任务称为“写任务”。作者发现其中69%是读密集型任务,而31%是写密集型任务。RH文件主要由读密集型任务读取,WH文件主要由写密集型任务写入,这两类任务都会对RW文件进行操作。对任务的分类有助于在后续章节中建立任务之间的生产者-消费者关系模型。
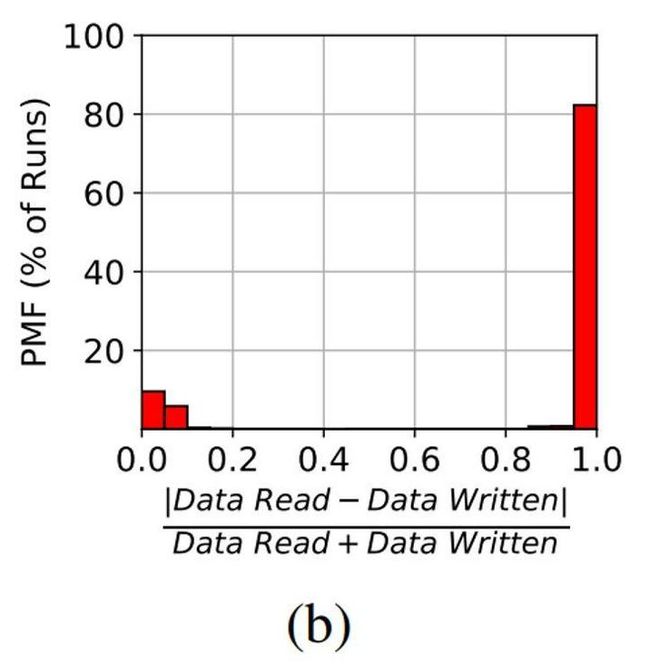
Figure 3: (b) >82% 的任务只执行读或写操作
发现2.令人惊讶的是,现代HPC应用程序在单次任务中主要倾向于仅执行一种类型的IO:要么读,要么写。这与普遍认为HPC应用程序在一个任务期间,同时具有读取和写入IO阶段的假设相反。这一发现表明,更科学的工作流逐步取代了传统的单体化应用程序(将不同工作汇集到一个任务中)的设计。非单体化应用程序的存在,为更好地调度大型工作流的不同组件提供了机会,从而避免了不同工作流之间的IO争用。
03 结果讨论和分析
接下来,论文分析了多任务重复访问数据及多应用共享数据的特点,并研究了负载是否均衡,以及任务内和不同任务间IO波动的特征。
文件复用的特点
在之前,作者将任务分为了读任务或写任务,并且发现读任务的总数约为写任务数量的2倍。接下来,为了了解复用同一文件所花费的平均时间(任务到达时间定义如图4所示),作者定义了不同任务的到达时间的概念。
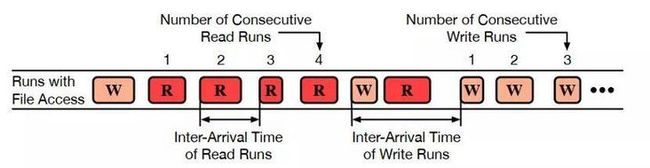
Figure 4: 同一个文件读任务或写任务间隔的定义
图5(a)显示,同一个文件经历的不同读任务的平均到达时间间隔为47小时,而写任务的平均到达时间间隔为55小时。但是,平均而言,80%的文件只有在50-55小时后才会再次被读取和写入。作者注意到,平均到达间隔时间比Cori上作业的平均运行时间长得多(这些系统上> 80%的HPC作业在不到2小时内完成)。

Figure 5(a): 大多数情况下对同一个文件的再次访问间隔时间在50-55小时
发现3.对于80%的文件,读写任务具有相似的到达时间间隔,都超过2天。论文首次发现,大多数文件重新访问时间间隔(>50小时)比作业的运行时间更长。这意味着HPC系统有时间对一些希望在一段时间内不活跃的数据进行压缩,或者将一些接下来即将访问到的数据通过预读和缓存的方式加载到Burst Buffer层中。
具有相似到达间隔时间的读写任务促使调研团队测试读写任务是否会背靠背执行,如果是这样,这种的执行次序会持续多长时间。论文计算了每个文件的连续读和写任务的平均次数(如图4所示),并将分布情况绘制在图5(b)中。
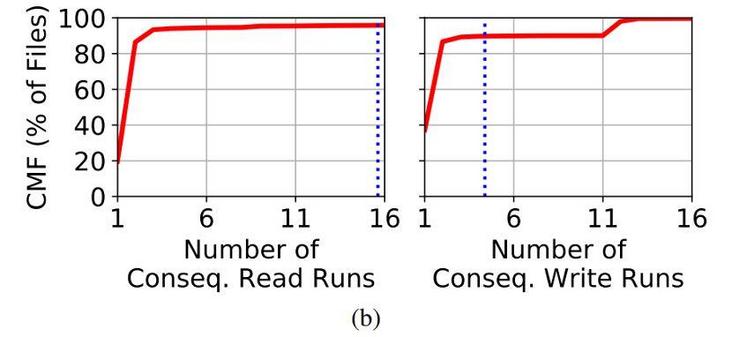
Figure 5(b): 平均连续读任务数为13,平均连续写任务数为3
超过80%的文件经历过2次或更多次连续读任务,而超过65%的文件经历2次或更多次连续写任务。大多数文件经历2次连续读运行(65%)和2次连续写运行(50%)。这表明文件是在多次读任务和多次写任务的交替中进行访问的,这与前面观察到RW文件占总体的比例(71%)是一致的。但是,许多文件会经历大量连续读任务(由于RH文件)。事实上,一个文件经历的平均连续读任务的次数超过14,而平均连续写任务的次数<4。读任务的次数仅为写任务次数的2.2倍(读写任务分类小节中提到),但是平均连续读任务次数为连续写任务次数的4.3倍。这表明对于大多数RW文件而言,数据仅生产了几次,然后被消耗了很多次。该观察结果表明,科学模拟计算通常会在某些任务期间生成数据,然后在随后的几次任务中将其用作驱动后续程序的输入,以探索不同的潜在路径或分析模拟现象。作者注意到,连续的写任务并不意味着所有先前写入的数据都被重写或丢弃。一些科学工作流可能会在两个连续的写任务中追加数据,然后在后续任务中读取该文件的一部分用作分析。
发现4. HPC文件平均经历几次连续的写任务和一长串的连续读任务。这个发现可以帮助利用MPI“hints”API来指导系统即将要执行的IO类型,以及对IO服务器进行分区,以分别提供RH文件(执行多次连续读)和RW文件(用于读取和写入任务),减少IO竞争,从而提高IO性能。
多应用程序间的文件共享特征。接下来的工作,为了将生产者与消费者的关系更进一步,从而了解生产者和消费者是相同的应用程序还是不同的应用程序。作者注意到所有访问同一个文件的应用程序均由同一用户运行。因此,对于任何文件,生产者和使用者应用程序都属于同一用户。此外,由于权限问题,默认情况下,也不会将文件在多个用户之间共享。图6(a)显示了访问文件的应用程序数量的CMF,超过67%的文件被至少2个应用程序访问共同访问,表明文件经常被多个应用程序共享。
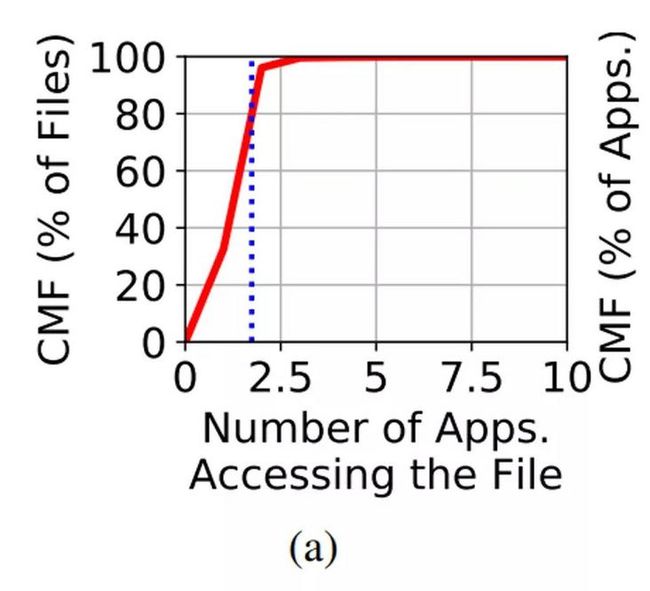
Figure 6(a): 超过65%的文件被至少两个应用程序共享访问
图6(b)展示出了对文件执行IO的每个应用的到达间隔时间的CMF。每个应用程序的平均到达间隔时间为31小时,比单个读任务的平均到达间隔时间(> 50小时)要低得多。因此,对于大多数文件,有两个或多个应用程序充当生产者和使用者,而不只是被单个应用程序访问。这与作者的发现是一致的:被多个应用程序访问的大多数文件(86%)是RW文件(这些共享文件中只有12%是RH文件,只有2%是WH文件)。
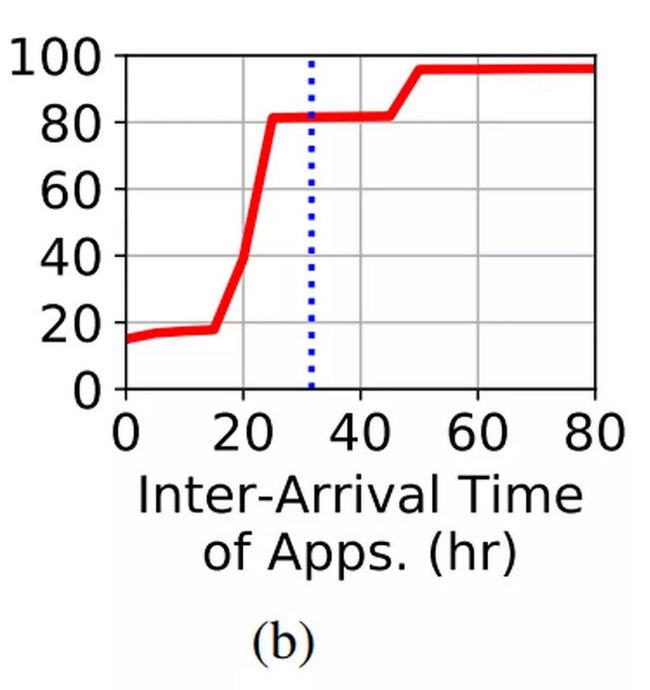
Figure 6(b): 不同应用程序对同一个文件执行IO操作的平均到达时间间隔为31小时
发现 5. HPC文件由多个应用程序共享,并且每个应用程序都会执行读取和写入操作,同时充当生产者和使用者。这些任务的到达间隔时间还表明,生产者和消费者在时间上显着分开,从而限制了跨应用程序访问时使用缓存的有效性。
IO数据访问特点
在文件复用特点中,作者研究了如何在多次任务中使用相同的文件。接下来,论文将分析在多次任务中数据访问特征会发生什么样的变化。图6(c)显示了每次通过读任务和写任务传输的数据量的CMF。可以观察到,平均而言,每次读任务传输17 GB的数据,而每次写任务传输25 GB的数据,50%的读任务传输数据量少于1 GB。
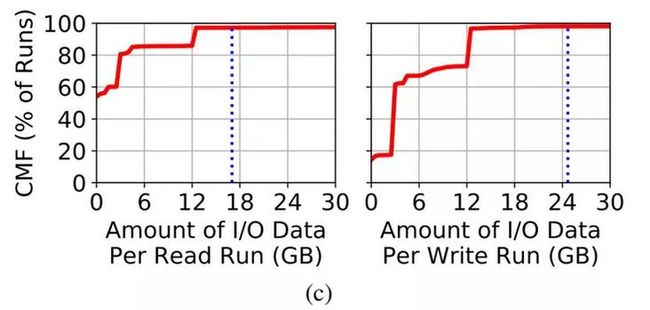
Figure 6(c) 平均每个读/写任务传输的数据量分别为17GB和25GB
发现6. 虽然读任务比写任务要多,且读任务传输的数据总量大于写任务,但是令人惊讶的是,单次写任务所传输的数据量要单次读任务要多。平均而言,每次写任务运行的IO次数是读任务的1.4倍。可以利用此发现来限制同时执行的写任务数量,从而在系统级别更好地管理IO争用问题。回想一下先前的发现,HPC应用在一次任务中会主要倾向于只执行一种类型的IO,因此,“写任务”可以轻松地被检测和分类,从而限制并发写入的数量。
既然已经发现不同的任务会传输不同数量的数据,接下来要研究的问题是这种差异会如何影响后端OST。图7显示了在研究期间每个OST传输的标准化IO数据。
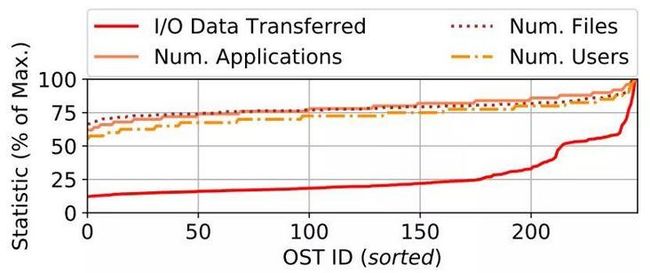
Figure 7: 每个OST传输的数据量存在很大差异,尽管文件数量、应用数量和用户数量总体是均衡的,平均每个读/写任务传输的数据量分别为17GB和25GB
有意思的是,每个OST传输多少数据有很大的不同。最不活跃的OST仅是最活跃OST的13%。另一方面,当查看每个OST上的文件数,使用这些文件的应用程序数以及生成文件的用户数时,作者发现分布范围要窄得多。
发现7. 对于在论文中研究的基于Lustre的系统,OST具有容量平衡的功能,以确保在文件创建时的利用率大致相等,但这并不能保证动态负载平衡。因此,在每个OST随时间推移观察到的负载(数据传输)方面存在很大的不均衡,这也体现出动态文件迁移(当前在Lustre文件系统中并不支持),对只读文件的副本及缓存(能让IO负载得到分摊)的重要性。
接下来,作者研究变化的OST争用将如何影响各个并发运行的进程的IO时间,这些进程可能并行访问不同的OST。在此分析中,作者分别分析了Cori使用的三种不同的IO接口:POSIX 、MPI、和STD IO。首先,看一下使用每个接口传输的数据量。图8(a)显示POSIX是最常用的I / O接口,平均每次任务每个文件传输大约260 GB数据,MPI接口平均每次任务每个文件将传输约190 GB的数据。正如并行HPC应用程序所期望的那样,STD是最不常用的接口。
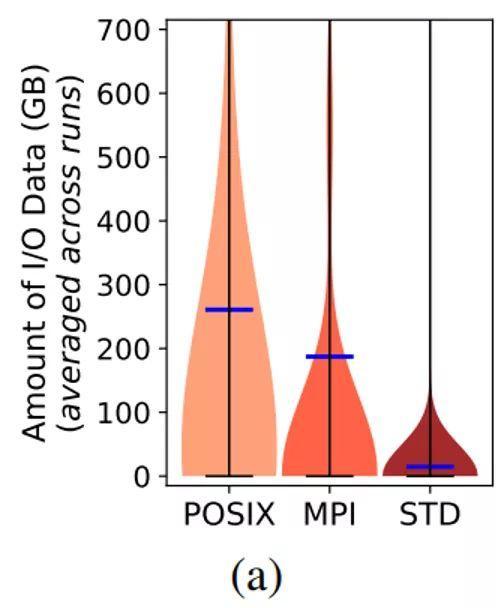
Figure 8(a): POSIX和MPI接口承担了绝大多数数据的传输任务
图8(b)显示了每次任务的单个进程上每个文件执行IO传输数据量的标准差(标准差用于描述不同进程间数据传输的偏差)。平均而言,所有三个接口的标准差都非常小。例如,进程内POSIX IO执行的数据量传输的平均标准偏差小于1.5 GB,与使用POSIX传输的平均数据量(260 GB)相比可以忽略不计。
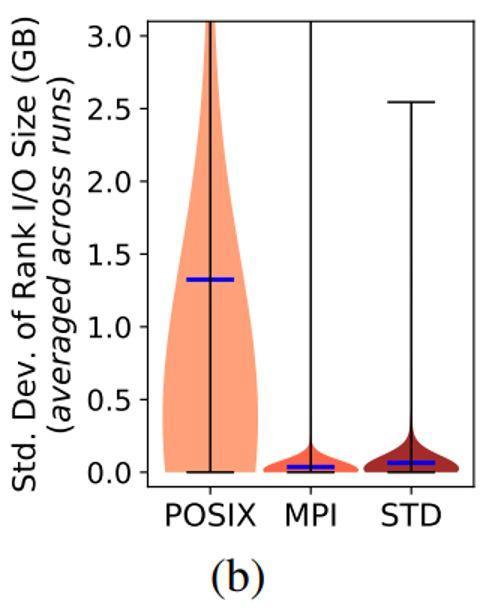
Figure 8(b): 在同一个应用程序内,不同进程间IO数据量偏差很小
另一方面,图8(c)显示了每次任务中单个进程内每个文件执行IO时间的标准差(用于描述不同进程执行IO时间的波动情况)。对于使用POSIX接口执行的IO,此标准差特别高。这是因为通常在使用POSIX接口时,每个进程对不同的文件执行IO,而在使用MPI IO接口时,所有进程对同一个共享文件执行IO。因为Cori超级计算机上的默认条带宽度为1,所以超过99%的文件仅在1个OST上进行条带化。因此,如果应用程序对多个文件并行执行IO,因为文件可能映射到不同的OST上,则这些应用很有可能对多个OST并行执行IO。因此,当使用POSIX IO时,这些OST上不同的资源争用级别会极大地影响各个进程的IO时间。
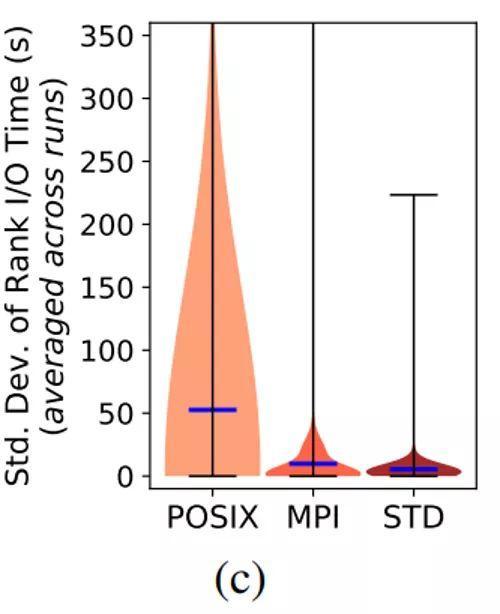
Figure 8(c): 各个进程在IO时间上的偏差很大
发现8. OST负载不平衡会导致同时执行IO的进程所消耗的IO时间波动较大,尤其是当进程对不同的OST执行IO时(例如POSIX IO)。这导致较快的进程必须等待较慢的进程完成,才能完成IO,然后才能继续进行计算,从而浪费了HPC系统上宝贵的计算周期。
IO负载在不同时间上的波动。以前,研究人员们已经发现OST IO不平衡和争用会导致单个任务的IO时间产生波动。下一步,论文探索的是IO负载在不同时间上的特性。图9(a)显示了一天中不同时间端传输的数据总量。可以观察到,最密集的IO是由本地时间凌晨3点到凌晨5点之间开始的任务触发的。
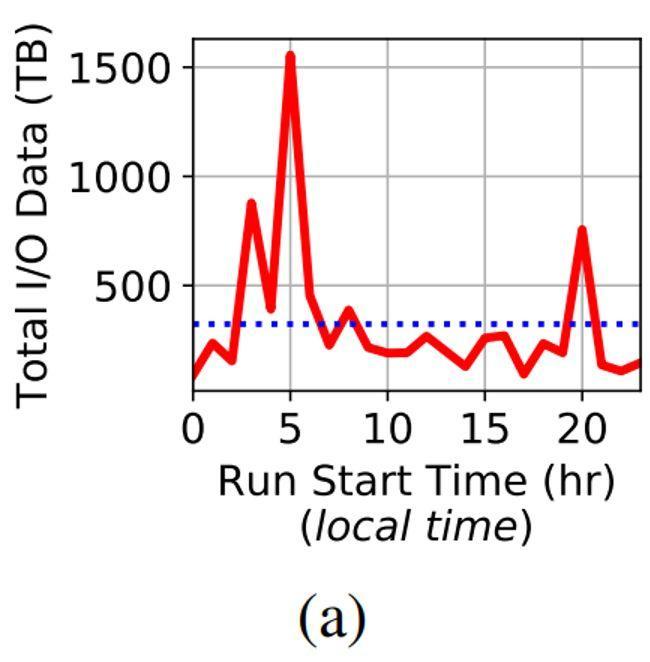
Figure 9(a): 凌晨3点到5点是数据IO的高峰期
值得注意的是,Cori的用户遍布全球,因此特定的本地时间(即凌晨)不能指示本地用户何时最活跃,下面的分析不一定在不同因素之间建立直接的因果关系,而是尝试解释观察到的趋势。在图9(b)中,展示了各个任务在一天中不同时段的IO耗时趋势。纵轴是各个任务在指定时间段,针对同一个文件执行IO所花费的时间与IO最长时间的比值(归一化),从而方便在各个文件之间进行标准化比较。由于凌晨3点到5点这段时间IO最为活跃,作者观察到从凌晨3点到5点,以及凌晨5点之后的几个小时,任务的IO耗时最长。尽管这个IO峰值时间段传输的数据最多,但相对来说,这段时间内任务的IO所花费的时间波动还是比较小的。
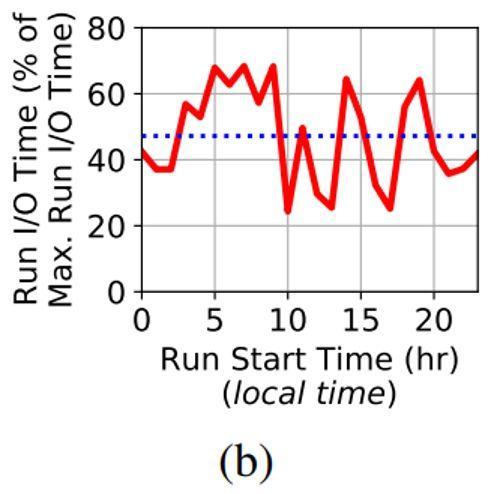
Figure 9(b): 凌晨3点到5点以及之后的几个小时,对同一个文件IO花费的时间最多
有意思的是,如图9(c)显示,尽管IO耗时的波动在全天所有时段内都非常高(> 20%),但在峰值IO期内开始的任务而言,IO耗时的波动反而最低。CoV(波动系数)是针对同一时刻开始的对同一文件的任务进行计算的。IO波动CoV趋势(图9(c))与IO耗时趋势图几乎相反(图9(b)) 。实际上,IO耗时和IO的CoV的相关指数为-0.94,这表明两者之间存在强烈的负相关性,也就是说,当IO活动最频繁的时候,用户可以预期的IO耗时变化反而会略低,即,如果用户A每天在繁忙的IO活动期间开始相同的任务,与在IO活动不那么频繁的时间段启动相同任务的用户B相比,用户A的任务IO耗时波动更小。当然,要权衡的是用户A所花费的平均IO耗时要比用户B长。这是因为当IO活动频繁时,OST竞争激烈,这可能会减慢所有IO,因此,IO耗时变化较小。但是,OST处于非竞争状态,并且IO更快时,IO耗时的波动趋势就更加明显。
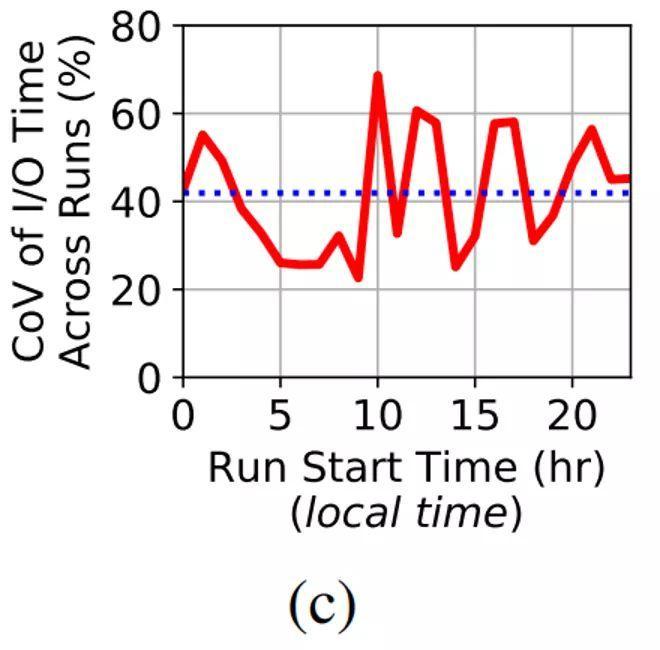
Figure 9(c): 不同任务的IO耗时CoV在最繁忙的时间段反而最小
发现9.不同时段的IO负载不平衡会导致同一任务的IO耗时在一天中的不同时段有所不同。而且,IO耗时的波动偏差在一天中的时段分布与IO耗时呈强烈的负相关性。这表明,HPC系统需要使用新的技术来降低各个任务中的IO耗时偏差(即同一应用程序的进程完成IO耗费时间偏差较大),因为目前IO耗时的偏差在全天所有时段内仍然较大(> 20%)。
不同任务的IO波动。接下来要解决的下一个问题是,如果存储系统负载存在时间分布上的不平衡,是否会导致IO耗时在不同任务上发生变化?在发现9中揭示的是同一时段内开始的任务中的IO波动。现在需要看看不论开始时间段如何,访问同一文件的不同任务的IO波动。首先,作者探讨针对同一文件,不同任务的数据传输量偏差。图10(a)显示了对于一个文件,不同任务传输数据量CoV的CMF。总体而言,超过80%的文件的CoV小于5%,这表明从不同任务的IO传输数据量的变化波动微不足道。RH文件如此,RW文件更是如此,同一个RW文件在绝大多数情况下,都会被任务产生和消耗相似数量的数据。同一个WH文件在不同任务中传输数据量的波动最大,平均CoV为35%。
图10(b)显示了每个文件在不同任务中的IO耗时的CoV。针对所有文件,即使不同任务间传输的数据量没有显着变化(上面的结论),但传输此数据所花费的时间却存在很大的差异:两次任务之间的IO耗时的平均CoV为39%。RH文件在不同任务的IO时间偏差最大,平均CoV为68%,即使它们传输的数据量变化最小。这是由于以下事实造成的:由于时间负载不平衡,OST在不同时间段竞争程度不同,由于读任务平均传输的数据量少于写任务(发现6中讨论的那样),因此这种负载不平衡的影响在其任务的IO耗时上尤为突出,进而对RH的影响最大。
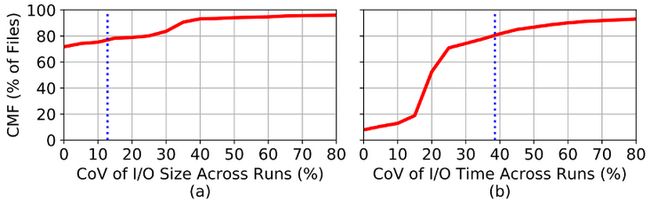
Figure 10: 针对同一文件,不同任务对只读文件传输数据量的偏最小(平均CoV 12%),但IO耗时偏差最大(平均CoV39%)
发现10. HPC文件往往在不同任务中传输的数据量相似,但是就传输数据所花费的时间而言,它们的确存在很大差异。对于RH文件而言,IO数据量的波动最小,但IO耗时波动最大,这意味着大家需要对RH文件的IO耗时波动偏差投入更多关注和改善。
04 后记
Cori特定环境和工作负载的影响。正如预期的那样,论文的各个发现受到在美国国家能源研究科学计算中心(NERSC)和Cori在NERSC系统环境中执行的HPC负载的影响,仍然具有一定的局限性。因此,论文的发现不能照原样推广到所有HPC系统中,但是论文所描述的工作提供了一种方法论,可以在其他HPC中心进行类似性质的研究,从而优化HPC中的存储系统。
我们认为,这篇论文的最大意义,并不在于其揭示了Cori中HPC负载的IO特点,而在于其描述了一种事实可行的调查IO模型及IO波动等特性的方法论。任何大型的HPC系统,都不是一蹴而就的,任何调优也不能是无根之水,只有基于科学的调研和分析,才能做出最合理的优化和配置。