prometheus初始使用min_shards运行,在运行过程中,利用sampleIn/sampleOut等指标计算新的shards,然后更新shards运行。
remote_write中shard的默认配置:
- min_shards=1;
- max_shards=1000;
按此配置,实际运行的shards值:
- 初始=min_shards=1;
- 有1个Goroutine根据当前的输入输出情况,定时计算新的desired_shards,然后进行reshard,以此动态调整shard数量;
入口
入口在上文讲到的QueueManager:
// Start the queue manager sending samples to the remote storage.
// Does not block.
func (t *QueueManager) Start() {
....
go t.updateShardsLoop() //计算新的shard
go t.reshardLoop() //更新shard
}更新shard: reshardLoop()
更新shard很简单,stop老的shard,然后start新的shard;
func (t *QueueManager) reshardLoop() {
defer t.wg.Done()
for {
select {
case numShards := <-t.reshardChan:
// We start the newShards after we have stopped (the therefore completely
// flushed) the oldShards, to guarantee we only every deliver samples in
// order.
t.shards.stop()
t.shards.start(numShards)
case <-t.quit:
return
}
}
}计算新shard: updateShardsLoop()
计算新shard的过程稍微复杂一些。
核心逻辑在t.calculateDesiredShards():
func (t *QueueManager) updateShardsLoop() {
defer t.wg.Done()
ticker := time.NewTicker(shardUpdateDuration)
defer ticker.Stop()
for {
select {
case <-ticker.C:
desiredShards := t.calculateDesiredShards() //核心逻辑在这里
if !t.shouldReshard(desiredShards) {
continue
}
// Resharding can take some time, and we want this loop
// to stay close to shardUpdateDuration.
select {
case t.reshardChan <- desiredShards:
level.Info(t.logger).Log("msg", "Remote storage resharding", "from", t.numShards, "to", desiredShards)
t.numShards = desiredShards
default:
level.Info(t.logger).Log("msg", "Currently resharding, skipping.")
}
case <-t.quit:
return
}
}
}1.依据哪些指标计算shards?
- samplesIn: 输入速率;
- samplesOut: 输出速率;
- samplesDropped: 丢弃速率;
这些指标都是ewmaRate类型,使用指标加权平均计算:
//参考:https://www.cnblogs.com/jiangxinyang/p/9705198.html
//越是最近的值,对结果的影响越大
v(t) = β(vt-1) + β*β(vt-2) + β*β*β(vt-3)+.....(β=0.2)代码实现:
const ewmaWeight = 0.2
const shardUpdateDuration = 10 * time.Second
samplesDropped: newEWMARate(ewmaWeight, shardUpdateDuration),
samplesOut: newEWMARate(ewmaWeight, shardUpdateDuration),
samplesOutDuration: newEWMARate(ewmaWeight, shardUpdateDuration),
func newEWMARate(alpha float64, interval time.Duration) *ewmaRate {
return &ewmaRate{
alpha: alpha,
interval: interval,
}
}
// 更新速率的方法
// tick assumes to be called every r.interval.
func (r *ewmaRate) tick() {
newEvents := atomic.SwapInt64(&r.newEvents, 0)
instantRate := float64(newEvents) / r.interval.Seconds() //最新的速率
r.mutex.Lock()
defer r.mutex.Unlock()
if r.init {
//指数加权平均
r.lastRate += r.alpha * (instantRate - r.lastRate)
} else if newEvents > 0 {
r.init = true
r.lastRate = instantRate
}
}2.采样何种算法计算shards?
利特尔法则:吞吐量L= λW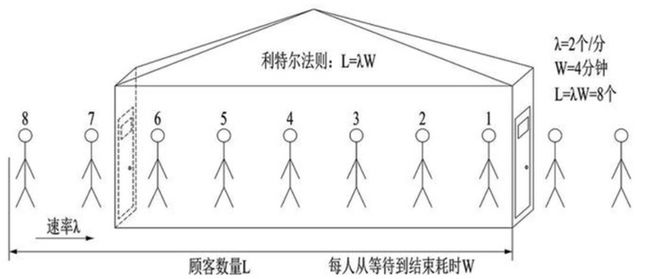
举例来讲:
- 假如我们开1个商店,平均每分钟进店2个客人(λ);
- 每个客人从进店到出店耗费4分钟(W);
- 那么我们的商店承载量=2*4=8人;
3.算法公式
直接看代码,calculateDesiredShards()计算desiredShard:
func (t *QueueManager) calculateDesiredShards() int {
//更新ewma的值
t.samplesOut.tick()
t.samplesDropped.tick()
t.samplesOutDuration.tick()
// We use the number of incoming samples as a prediction of how much work we
// will need to do next iteration. We add to this any pending samples
// (received - send) so we can catch up with any backlog. We use the average
// outgoing batch latency to work out how many shards we need.
var (
samplesInRate = t.samplesIn.rate()
samplesOutRate = t.samplesOut.rate()
samplesKeptRatio = samplesOutRate / (t.samplesDropped.rate() + samplesOutRate)
samplesOutDuration = t.samplesOutDuration.rate() / float64(time.Second)
samplesPendingRate = samplesInRate*samplesKeptRatio - samplesOutRate
highestSent = t.metrics.highestSentTimestamp.Get()
highestRecv = highestTimestamp.Get()
delay = highestRecv - highestSent
samplesPending = delay * samplesInRate * samplesKeptRatio
)
if samplesOutRate <= 0 {
return t.numShards
}
// When behind we will try to catch up on a proporation of samples per tick.
// This works similarly to an integral accumulator in that pending samples
// is the result of the error integral.
const integralGain = 0.1 / float64(shardUpdateDuration/time.Second)
var (
timePerSample = samplesOutDuration / samplesOutRate
desiredShards = timePerSample * (samplesInRate*samplesKeptRatio + integralGain*samplesPending)
)
t.metrics.desiredNumShards.Set(desiredShards)
.....
}可以看到,最终的计算公式:
desiredShards = timePerSample * (samplesInRate*samplesKeptRatio + integralGain*samplesPending)其中:
- timePerSample=samplesOutDuration/samplesOutRate: 每个sample被输出花费的时间;
- samplesInRate: 输入速率;
- samplesKeptRatio=sampleOut/(samplesOut+samplesDrop): 输出的成功率;
- integralGain*samplesPending: 修正值,将pending的数据计算进去;
整个计算过程遵循利特尔法则:承载量=输入流量*单个流量的耗费时间,只是中间加入了一些确保准确的成功率、修正值等。