import tensorflow as tf
- 防止过拟合的一个办法是设置验证集,当模型在训练集上训练完之后,利用验证集对模型进行调参优化,最终用测试集测试模型性能
print(tf.__version__)
2.5.1
一、准备数据集
import pandas as pd
df = pd.read_csv('boston.csv')
df.head()
|
CRIM |
ZN |
INDUS |
CHAS |
NOX |
RM |
AGE |
DIS |
RAD |
TAX |
PTRATIO |
LSTAT |
MEDV |
| 0 |
0.00632 |
18.0 |
2.31 |
0 |
0.538 |
6.575 |
65.2 |
4.0900 |
1 |
296 |
15.3 |
4.98 |
24.0 |
| 1 |
0.02731 |
0.0 |
7.07 |
0 |
0.469 |
6.421 |
78.9 |
4.9671 |
2 |
242 |
17.8 |
9.14 |
21.6 |
| 2 |
0.02729 |
0.0 |
7.07 |
0 |
0.469 |
7.185 |
61.1 |
4.9671 |
2 |
242 |
17.8 |
4.03 |
34.7 |
| 3 |
0.03237 |
0.0 |
2.18 |
0 |
0.458 |
6.998 |
45.8 |
6.0622 |
3 |
222 |
18.7 |
2.94 |
33.4 |
| 4 |
0.06905 |
0.0 |
2.18 |
0 |
0.458 |
7.147 |
54.2 |
6.0622 |
3 |
222 |
18.7 |
5.33 |
36.2 |
df.tail()
|
CRIM |
ZN |
INDUS |
CHAS |
NOX |
RM |
AGE |
DIS |
RAD |
TAX |
PTRATIO |
LSTAT |
MEDV |
| 501 |
0.06263 |
0.0 |
11.93 |
0 |
0.573 |
6.593 |
69.1 |
2.4786 |
1 |
273 |
21.0 |
9.67 |
22.4 |
| 502 |
0.04527 |
0.0 |
11.93 |
0 |
0.573 |
6.120 |
76.7 |
2.2875 |
1 |
273 |
21.0 |
9.08 |
20.6 |
| 503 |
0.06076 |
0.0 |
11.93 |
0 |
0.573 |
6.976 |
91.0 |
2.1675 |
1 |
273 |
21.0 |
5.64 |
23.9 |
| 504 |
0.10959 |
0.0 |
11.93 |
0 |
0.573 |
6.794 |
89.3 |
2.3889 |
1 |
273 |
21.0 |
6.48 |
22.0 |
| 505 |
0.04741 |
0.0 |
11.93 |
0 |
0.573 |
6.030 |
80.8 |
2.5050 |
1 |
273 |
21.0 |
7.88 |
11.9 |
df.describe()
|
CRIM |
ZN |
INDUS |
CHAS |
NOX |
RM |
AGE |
DIS |
RAD |
TAX |
PTRATIO |
LSTAT |
MEDV |
| count |
506.000000 |
506.000000 |
506.000000 |
506.000000 |
506.000000 |
506.000000 |
506.000000 |
506.000000 |
506.000000 |
506.000000 |
506.000000 |
506.000000 |
506.000000 |
| mean |
3.613524 |
11.363636 |
11.136779 |
0.069170 |
0.554695 |
6.284634 |
68.574901 |
3.795043 |
9.549407 |
408.237154 |
18.455534 |
12.653063 |
22.532806 |
| std |
8.601545 |
23.322453 |
6.860353 |
0.253994 |
0.115878 |
0.702617 |
28.148861 |
2.105710 |
8.707259 |
168.537116 |
2.164946 |
7.141062 |
9.197104 |
| min |
0.006320 |
0.000000 |
0.460000 |
0.000000 |
0.385000 |
3.561000 |
2.900000 |
1.129600 |
1.000000 |
187.000000 |
12.600000 |
1.730000 |
5.000000 |
| 25% |
0.082045 |
0.000000 |
5.190000 |
0.000000 |
0.449000 |
5.885500 |
45.025000 |
2.100175 |
4.000000 |
279.000000 |
17.400000 |
6.950000 |
17.025000 |
| 50% |
0.256510 |
0.000000 |
9.690000 |
0.000000 |
0.538000 |
6.208500 |
77.500000 |
3.207450 |
5.000000 |
330.000000 |
19.050000 |
11.360000 |
21.200000 |
| 75% |
3.677082 |
12.500000 |
18.100000 |
0.000000 |
0.624000 |
6.623500 |
94.075000 |
5.188425 |
24.000000 |
666.000000 |
20.200000 |
16.955000 |
25.000000 |
| max |
88.976200 |
100.000000 |
27.740000 |
1.000000 |
0.871000 |
8.780000 |
100.000000 |
12.126500 |
24.000000 |
711.000000 |
22.000000 |
37.970000 |
50.000000 |
data = df.values
data.shape
(506, 13)
x_data = data[:,:12]
y_data = data[:,12]
from sklearn.preprocessing import scale
train_num = 300
valid_num = 100
x_train = x_data[:train_num]
y_train = y_data[:train_num]
x_valid = x_data[train_num:train_num+valid_num]
y_valid = y_data[train_num:train_num+valid_num]
x_test = x_data[train_num+valid_num:]
y_test = y_data[train_num+valid_num:]
'''
tf.cast可以直接将numpy数组转换为tensor
'''
x_train = tf.cast(scale(x_train),dtype=tf.float32)
x_valid = tf.cast(scale(x_valid),dtype=tf.float32)
x_test = tf.cast(scale(x_test),dtype=tf.float32)
二、模型
import numpy as np
def line_model(x,w,b):
return tf.matmul(x,w) + b
三、训练
W = tf.Variable(tf.random.normal(shape=(12,1)))
B = tf.Variable(tf.zeros(1),dtype=tf.float32)
def loss(x,y,w,b):
loss_ = tf.square(line_model(x,w,b) - y)
return tf.reduce_mean(loss_)
def grand(x,y,w,b):
with tf.GradientTape() as tape:
loss_ = loss(x,y,w,b)
return tape.gradient(loss_,[w,b])
training_epochs = 50
learning_rate = 0.001
batch_size = 10
optimizer = tf.keras.optimizers.SGD(learning_rate)
total_steps = train_num // batch_size
loss_train_list = []
loss_valid_list = []
for epoch in range(training_epochs):
for step in range(total_steps):
xs = x_train[step*batch_size:(step+1)*batch_size]
ys = y_train[step*batch_size:(step+1)*batch_size]
grads = grand(xs,ys,W,B)
optimizer.apply_gradients(zip(grads,[W,B]))
loss_train = loss(x_train,y_train,W,B).numpy()
loss_valid = loss(x_valid,y_valid,W,B).numpy()
loss_train_list.append(loss_train)
loss_valid_list.append(loss_valid)
print(f'{
epoch+1}次 loss_train:{
loss_train} loss_valid:{
loss_valid}')
1次 loss_train:665.7977905273438 loss_valid:477.3428039550781
2次 loss_train:593.6646728515625 loss_valid:413.1649475097656
3次 loss_train:533.6004028320312 loss_valid:362.72601318359375
4次 loss_train:482.3865661621094 loss_valid:321.768310546875
5次 loss_train:438.0271911621094 loss_valid:287.7205810546875
6次 loss_train:399.220703125 loss_valid:258.9722900390625
7次 loss_train:365.0664367675781 loss_valid:234.4657745361328
8次 loss_train:334.9011535644531 loss_valid:213.4668426513672
9次 loss_train:308.20770263671875 loss_valid:195.4357147216797
10次 loss_train:284.56365966796875 loss_valid:179.9535675048828
11次 loss_train:263.6124572753906 loss_valid:166.6811065673828
12次 loss_train:245.04588317871094 loss_valid:155.3340301513672
13次 loss_train:228.59408569335938 loss_valid:145.66885375976562
14次 loss_train:214.01869201660156 loss_valid:137.47401428222656
15次 loss_train:201.10826110839844 loss_valid:130.56398010253906
16次 loss_train:189.67495727539062 loss_valid:124.77549743652344
17次 loss_train:179.55177307128906 loss_valid:119.96448516845703
18次 loss_train:170.58995056152344 loss_valid:116.00358581542969
19次 loss_train:162.65756225585938 loss_valid:112.78060913085938
20次 loss_train:155.6372833251953 loss_valid:110.1964340209961
21次 loss_train:149.42471313476562 loss_valid:108.16374969482422
22次 loss_train:143.92759704589844 loss_valid:106.60588836669922
23次 loss_train:139.0637664794922 loss_valid:105.45535278320312
24次 loss_train:134.7605743408203 loss_valid:104.65306091308594
25次 loss_train:130.95376586914062 loss_valid:104.14726257324219
26次 loss_train:127.58616638183594 loss_valid:103.89268493652344
27次 loss_train:124.60723114013672 loss_valid:103.84986114501953
28次 loss_train:121.97221374511719 loss_valid:103.98436737060547
29次 loss_train:119.64164733886719 loss_valid:104.26632690429688
30次 loss_train:117.58037567138672 loss_valid:104.66973876953125
31次 loss_train:115.75743103027344 loss_valid:105.17220306396484
32次 loss_train:114.14533233642578 loss_valid:105.7542495727539
33次 loss_train:112.71986389160156 loss_valid:106.39917755126953
34次 loss_train:111.45946502685547 loss_valid:107.09259796142578
35次 loss_train:110.34514617919922 loss_valid:107.82219696044922
36次 loss_train:109.360107421875 loss_valid:108.57747650146484
37次 loss_train:108.4894790649414 loss_valid:109.3494873046875
38次 loss_train:107.72004699707031 loss_valid:110.13068389892578
39次 loss_train:107.04024505615234 loss_valid:110.91461181640625
40次 loss_train:106.43974304199219 loss_valid:111.69599914550781
41次 loss_train:105.909423828125 loss_valid:112.47042846679688
42次 loss_train:105.44117736816406 loss_valid:113.23422241210938
43次 loss_train:105.0279312133789 loss_valid:113.9843978881836
44次 loss_train:104.66329193115234 loss_valid:114.7186508178711
45次 loss_train:104.34174346923828 loss_valid:115.43498992919922
46次 loss_train:104.05831146240234 loss_valid:116.13207244873047
47次 loss_train:103.80862426757812 loss_valid:116.80872344970703
48次 loss_train:103.58882141113281 loss_valid:117.46420288085938
49次 loss_train:103.39546966552734 loss_valid:118.0979995727539
50次 loss_train:103.22554779052734 loss_valid:118.70991516113281
import matplotlib.pyplot as plt
%matplotlib inline
plt.plot(loss_train_list)
plt.plot(loss_valid_list)
[]

四、预测
W.numpy()
array([[ 0.04078581],
[ 0.42111152],
[-1.266555 ],
[ 0.7909989 ],
[-0.7962972 ],
[ 1.6725844 ],
[-0.23721075],
[-0.900601 ],
[ 0.45604745],
[-0.51313245],
[-2.141279 ],
[-0.713085 ]], dtype=float32)
B.numpy()
array([24.265219], dtype=float32)
house_id = np.random.randint(0,x_data.shape[0]-train_num-valid_num)
y = y_test[house_id]
y_pre = int(line_model(x_test,W.numpy(),B.numpy())[house_id])
print(f'真实值:{
y},预测值:{
y_pre}')
真实值:10.2,预测值:24
plt.plot(y_test,'r')
plt.plot(line_model(x_test,W.numpy(),B.numpy()),'g')
[]
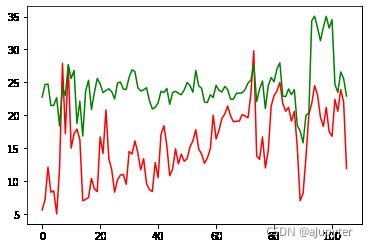
plt.plot(y_train,'r')
plt.plot(line_model(x_train,W.numpy(),B.numpy()),'g')
[]

plt.plot(y_valid,'r')
plt.plot(line_model(x_valid,W.numpy(),B.numpy()),'g')
[]
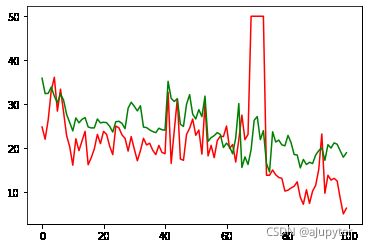
import sklearn.metrics as sm
print('R2_score:', sm.r2_score(y_test,line_model(x_test,W.numpy(),B.numpy())))
R2_score: -2.399917872887695
预测效果不是很好…略微无奈,模型本身问题,解决不了房价预测问题。由此可见,选择模型非常非常重要,如果你模型选的不对,你调多好的参数都没用。