(干货,建议收藏)备战2021年软考中级网络工程师-01计算机硬件基础
备战2021年软考中级网络工程师-01计算机硬件基础
本文目录
- 一、前言
- 二、中级网络工程师复习笔记-01计算机硬件基础
-
- (一)数据进制的转换
- (二)计算机中的原码、反码、补码和移码
- (三).计算机结构
- (四)指令系统寻址方式:
- (五)CISC与RISC:
- (六)流水线
- (七)存储系统
- (八)RAID技术
- (九)系统的可靠性
- 三、与作者更多学习交流
一、前言
近来在研究python的时候无意间了解到还可以参加软考,拿到国家工信部认定的工程师资格,既可以在北上广深申请办理北京居住证,享受积分落户的优惠政策,又可以在职场作为升职加薪的硬性条件,还可以提升自己的计算机基础能力水平,何乐而不为呢?

经查,此考试上半年考试时间为5月底(第三个周六、周日),下半年考试时间为11月中旬(第二个周六、周日)。现在已经8月,那么我只能考下半年的11月这场考试了。
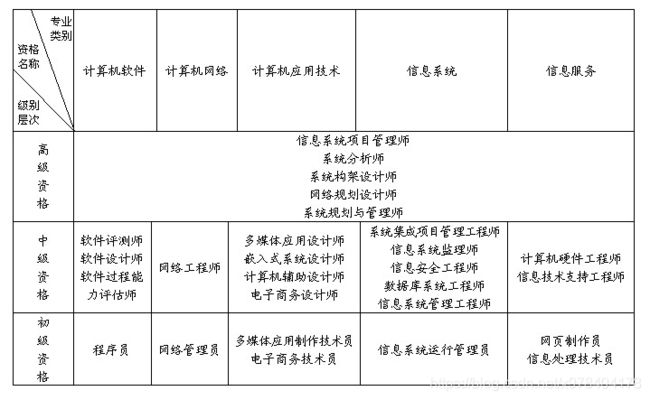
根据以上软考的分类,我选择的是中级网络工程师。听说初级的太简单了,建议直接从中级起考,而我粗略看了下这些资格的考试大纲和以前的一些真题,只有网络工程师我学过一部分内容,似乎考起来难度较小,比较适合我。
点击下方链接查看如何报名:
计算机技术与软件专业技术资格(水平)考试全国各省市考试报名
成功报名和缴费后要及时登录人事考试频道下载打印准考证,凭准考证和本人有效居民身份证原件参加考试哦。
**
二、中级网络工程师复习笔记-01计算机硬件基础
**
(一)数据进制的转换
二进制,只有0和1两个数,常用下标2表示。
八进制常用下标8或在数字后加一个英文字母O来表示。
十进制常用下标10或在数字后加一个英文字母D来表示。
十六进制,在十进制在基础上用A、B、C、D、E、F分别代表10、11、12、13、14、15,常用下标16或在数字后加一个英文字母H来表示。
无论是几进制,其实质都是不同的加权展开
一个长度为n位的x进制的数转换要成10进制,从右往左数第i位上的数字为ki,那么其10进制值为
∑ i = 1 n k i ∗ x i − 1 \displaystyle\sum_{i=1}^{n} k_i*x^{i-1} i=1∑nki∗xi−1
例如:
10110按2进制展开是1* 21+1* 22+1* 24=22
10110按16进制展开是1* 161+1* 162+1* 164=65808
而二进制/八进制/十六进制之间的转换分别对应展开每一/三/四位数字,
例如:
2进制数110110101从右往左数每3位“压缩”成8进制对应8进制数665
2进制数110110101从右往左数每4位“压缩”成16进制对应16进制数1B5
最高位不足按0补齐。
8进制数和16进制数要转换成2进制按类似方法从右往左每3/4位展开即可。
(二)计算机中的原码、反码、补码和移码
原码:是最简单的机器数表示法。用最高位表示符号位,‘1’表示负号,‘0’表示正号。其他位为二进制的绝对值
原码、反码和补码正数表示都一样,负数表示有区别。
负数的反码等于原码除符号位外,按位取反,
负数的补码等于 原码除符号位外,按位取反再加1,即反码+1.
PS:0的补码是唯一的,若机器字长为8则[0]补=00000000。
将补码的符号位取反便可获得相应的移码表示。
移码表示0也是唯一的。
原码和反码的取值范围为:
定点整数:-(2n-1-1)~2n-1-1,
定点小数:-(1-2-(n-1))~1-2-(n-1)
补码取值范围为:
定点整数:-2n-1~2n-1-1,
定点小数:-1~1-2-(n-1)
长为n的数共可表示2n个数字,原码、反码表示0有两种方式,所以原码、反码可表示的数的总数就少了一个,取值范围可以表示2n-1个数字。
而因为补码、移码表示0唯一,所以补码、移码的取值范围可以表示2n个数字。
PS:补码是可以表示到-1的,所有位全1即-1,11111111除最高位符号位“1”外其余位取反+1得到10000001,最高位符号位为“1”表示为负,后面数值表示为1,即-1.
(三).计算机结构
现代计算机都是 Von Neumann Architecture (冯诺依曼体系结构),其主要特点为,主要部分是CPU(中央处理单元,Central Processing Unit)和 内存(Memory)是计算机的主要组成成分,内存中存储着数据和指令,CPU从内存中取指令执行,有些指令让CPU进行运算,有些进行读取操作。
CPU包括运算器和控制器两大部分,
1.运算器组成:
1.算术逻辑单元(ALU,Arithmetic and Logic Unit)。运算指令会调动算术逻辑单元,且指令同时会指示结果存到哪里。
2.累加寄存器(AC),暂存中间计算结果。
3.数据缓冲寄存器,用于保存从主存中读取的数据。
4.状态条件寄存器,用于保存计算过程中的状态信息,比如借位、进位。
2.控制器组成:
1.程序计数器(PC),存放指令地址,下一条指令地址通常是PC+1。
2.指令寄存器(IR),用于保存当前正在执行的指令。
3.指令译码器,对指令操作数部分进行译码。
4.时序部件,为指令执行产生时序信号。
内存又称主存,主存储器。
通过总线交互信息,总线包括数据总线、地址总线、控制总线,每条线有1和0两种状态。
指令由操作码和地址码组成,操作码是说这条指令做什么操作,比如加减乘除,地址码是操作数存放的地址。
(四)指令系统寻址方式:
1.立即寻址,直接把操作数放在地址码部分。不用访问内存,速度快,但数字长度受地址码长度限制。
2.直接寻址,直接把操作数在内存中的地址放在地址码中,只需访问一次内存。
3.间接寻址,前往地址码中的内存地址拿到的是另一个内存地址,还需要前往新的内存地址才能拿到最终的操作数,至少需要访问两次内存。
4.变址寻址,设置一个变址寄存器,用地址码中的基地址加上变址寄存器中的地址得到操作数在内存中的地址。
5.寄存器寻址,操作数在寄存器当中,不需访问内存,速度很快。
6.寄存器间接寻址,至少需要访问两次寄存器才能得到操作数。
其中2,3,4都属于内存寻址,5,6属于寄存器寻址。
(五)CISC与RISC:
CISC(Complex Instruction Set Computers,复杂指令集计算集)和RISC(Reduced Instruction Set Computers)是两大类主流的CPU指令集类型。RISC的设计初衷针对CISC CPU复杂的弊端,选择一些可以在单个CPU周期完成的指令,以降低CPU的复杂度,将复杂性交给编译器。
CISC(复杂)和RISC(精简)的主要区别:
1.
CISC的指令能力强,数量多,使用频率差别大,指令是可变长格式;
RISC的指令大部分为单周期指令,数量少,使用频率接近,指令长度固定,操作寄存器,只有Load/Store操作内存。
2.
CISC支持多种寻址方式;
RISC支持寻址方式少。
3.
CISC通过微程序控制技术实现;
RISC增加了通用寄存器,硬布线逻辑控制为主,适合采用流水线。
4.
CISC的研制周期长;
RISC优化编译,有效支持高级语言。
(六)流水线
流水线是指在程序执行时多条指令重叠进行操作的一种准并行处理实现技术,是将一条指令分为取指、分析、执行三步骤由顺序执行变为流水执行的方式。
吞吐率:单位时间内流水线所完成的任务数量或输出结果的数量
加速比:不用流水线所用时间与用流水线处理同一 批任务所用的时间之比
效率:即流水线设备的利用率,指流水线中的设备实际使用时间与整个运行时间的比值
一条指令在取指、分析、执行三部分所需时间分别为t1=2ns,t2=2ns,t3=1ns,总共n=100条指令,流水线时间为Tk,若不用流水线时间为Ts,则:
流水线执行时间:(t1+t2+t3)+(n-1)t1
其中t1是流水线周期T,它表示执行时间最长的一段,在这里就是T=t1=2ns,
这100条指令全部执行完毕需要的时间是
Tk=(2+2+1)+(100-1)*2=203ns。
实际吞吐率:Tp=n/Tk=100/203ns
理论上最大吞吐率:Tp=1/T=1/2ns
加速比:S=Ts/Tk=(2+2+1)*100/203=500/203
效率:根据不同工作状态分别为1/3,2/3和1
如果是对流水线的基本原理还比较模糊的同学,可以看看有图的流水线原理讲解:有图的流水线原理讲解
(七)存储系统
主存:即内存,分为随机存储器RAM(掉电丢失)和只读存储器ROM(掉电不丢失)
缓存:Cache高速缓冲存储器,用于平衡CPU和主存的速度
辅存:即外存,磁盘等,用于扩充主存容量
CPU中的存储器指寄存器,寄存器速度快。
速度:CPU>Cache>主存>辅存
容量:辅存>主存>Cache>CPU
存储器存储方式:
1.顺序存取(磁带),以线性的顺序保存数据。
2.直接存取(硬盘),以磁头移到对应磁道读取数据。
3.随机存取(内存),任何时刻可对任一存储单元中任何模块进行读取数据
4.相联存取(Cache),不根据地址读取而是保存CPU要经常访问的数据,Cache要比主存速度快,可用于节约访问主存次数从而节约时间
在主存储器中,通常以word为单位进行标识,即每个字一个地址,通常采用16进制表示。
例如,按字节编址,,地址从A4000H到CBFFFH,则表示有(CBFFF-A4000)+1个字节(因为例如从2到5有5-2+1=4个数字),即28000H个字节,也即163840个字节,等于160KB。若某芯片为32k8bit,则该存储器需要160k1B/32k8bit=160k8bit/32k8bit=5片芯片组成。
Cache中根据某些算法选定的规则存储CPU经常访问的数据,但CPU要访问的数据也不一定就在Cache中,如果在Cache中则称为访问命中,未命中则要到主存中去寻找数据。如果Cache的访问命中率为h,而Cache的访问周期时间是t1,主存储器的访问周期时间是t2,则整个系统的平均访存时间是t3=ht1+(1-h)*t2。
而决定Cache中存放哪些数据的算法称为Cache淘汰算法,
Cache淘汰算法:
1.先进先出算法(FIFO),字面意思,先进来的数据就先淘汰,效果不好
2.最近最少使用算法(LRU),其核心思想是“如果数据最近被访问过,那么将来被访问的几率也更高”。淘汰掉目前Cache存放的数据中最长时间没被访问过的数据。
3.随机算法,无脑随机淘汰。
4.最长时间不使用算法(OPT),淘汰掉未来最长时间不被使用的数据,但基本无法实现,没人可以预测未来。
(八)RAID技术
RAID ( Redundant Array of Independent Disks )即独立磁盘冗余阵列,通常简称为磁盘阵列。简单地说, RAID 是由多个独立的高性能磁盘驱动器组成的磁盘子系统,从而提供比单个磁盘更高的存储性能和数据冗余的技术。
RAID2和RAID4已基本淘汰,不用考虑。
1.RAID0技术
有低成本、高读写速度、 100% 的高存储空间利用率等优点。但是它不提供数据冗余保护,一旦数据损坏,将无法恢复,可靠性差。 因此, RAID0 一般适用于对性能要求严格但对数据安全性和可靠性不高的应用,如视频生成和编辑、图像编辑和需要在传输带宽的操作等,磁盘利用率100%。
2.RAID1技术
将一个硬盘完全镜像复制到了另一个硬盘,具备容错能力。适用于财务、金融等高可用、高安全的数据存储环境,磁盘利用率50%。
3.RAID3技术
将某一整个硬盘都用来存储奇偶校验位,具有容错能力,可靠性较好。但单个硬盘失效时会产生盘I/O瓶颈效应,每往数据盘写入一个数据都需要修改校验磁盘的数据,拖慢了整个的性能,磁盘利用率=(n-1)/n。
4.RAID5技术
改进版的RAID3,将校验位分布存放到各个硬盘中,相当程度地分散了负载,性能较好,具有容错能力,可靠性好。但控制器设计复杂,磁盘重建过程比较复杂。适用于文件服务器、Email服务器、Web服务器等数据库应用,磁盘利用率=(n-1)/n。
5.RAID6技术
一些大型企业提出了RAID6作为私有RAID级别标准,实现了两个磁盘掉线容错,具有两组分布在各磁盘的校验码,磁盘利用率=(n-2)/n。
6.RAID10技术
结合了RAID1和RAID0,先镜像,再条带化。读性能很高,写性能较好,数据安全性好,允许同时有N个磁盘失效。但开销大,空间利用率只有50%。适用于要求高可用性和高安全性的数据库应用,磁盘利用率50%。
比较RAID10和RAID5:
性能:RAID10>RAID5,因为RAID10要镜像,RAID5要校验,校验要计算,比镜像更慢。
可靠性:RAID10>RAID5,RAID10可以允许坏两块及以上磁盘,而RAID5最多只能坏一块磁盘,坏了两块就读不出来了。
数据重构:RAID10>RAID5,如要恢复一块坏掉磁盘的数据,RAID10只需要读取其镜像的那个磁盘即可,而RAID5需要读取其余所有磁盘通过校验计算才能重构出坏掉的磁盘数据。
成本:RAID5>RAID10,RAID10磁盘利用率50%,而RAID5磁盘利用率最低也是66.6%,还可以更高。
所以关键性应用选择RAID10,非关键性应用选择RAID5以节约成本。
RAID数据保护方式:
1.热备盘,即备用盘,让数据重构到热备盘可加快重构速度。
2.预拷贝,监测到某磁盘参数异常,即将故障,则将其数据预先拷贝到热备盘。
3.失效重构,某磁盘失效后利用镜像或校验码将其数据重构。
4.RAID状态,磁盘能读或不能读分为有效和失效状态。
RAID技术发展:
1.传统RAID,多磁盘组成存储阵列,空间利用率不高。
2.LUN虚拟化,将多个磁盘整合成存储池,再按需划分存储资源给虚拟机,提高磁盘利用率。
3.块虚拟化,又称RAID2.0,将存储空间划为很多数据块,基于数据块处理RAID组,所有磁盘均可参与重构某失效磁盘,重构速度比传统RAID快。
RAID2.0优势:快速重构,自动负载均衡,系统性能提升,自愈合。
(九)系统的可靠性
串行系统只要有一个部件失效,那么整个系统失效,其可靠性R为每个部件可靠性R1,R2…之积
R=R1R2R3…Rn
并行系统只要还有一个部件没有失效,那么整个系统就没有失效,其可靠性R为1减去每个部件同时失效的概率,
R=1-(1-R1)(1-R2)…(1-Rn)
我目前整理的软考中级网络工程师-01计算机硬件基础笔记就这么多啦,如果各位大佬还有什么要补充的重点或者想要与作者交流,可以在下方留言哦,
跪求各位大佬一键三连,孩子可是码了一个下午的字呢。
三、与作者更多学习交流
如果想要与作者更多的学习交流,欢迎加作者微信。
作者微信号:Communistic_belief