课程向:深度学习与人类语言处理 ——李宏毅,2020 (P9)
Language Modeling For Speech Recognition
李宏毅老师2020新课深度学习与人类语言处理课程主页:
http://speech.ee.ntu.edu.tw/~tlkagk/courses_DLHLP20.html
视频链接地址:
https://www.bilibili.com/video/BV1RE411g7rQ
课件ppt已上传至资源,可免费下载使用
接下来,我们要讲语音辨识的最后一段,怎么把 Language Model 放在语音辨识里面。讲完这一段,我们将进入Voice Conversion
前言
在P5、P6中,我们明晰了HMM、CTC、RNN-T的模型细节,但都同样遇到了alignment的问题;
在P7、P8中,我们基于alignment提出并解决了四个问题:
1. 问题1:怎么穷举所有可能的alignments? (P7)
2. 问题2:怎么把所有的alignments加起来? (P8)
3. 问题3:怎么做训练?HMM用的是GMM我们不管它。而CTC,RNN-T用的是gradient descent,我们该怎么计算将这些alignment加起来的偏微分? (P8)
4. 问题4:怎么做Decoding呢?怎么最优化这个P(Y|X)呢? (P8)
而在本节我们将讲解在在语音辨识中使用Language Model的原因和方法
I Why Language Model
以下计算都以RNN-T为例,CTC、HMM同理
1 Language Model的定义、使用、数据及原因

定义:Language Model (LM) ,它要解决的问题是估测一段token sequence出现的的几率
使用:
- HMM中,使用Language Model是必需的,因为HMM的decoding的公式是 a r g m a x Y P ( X ∣ Y ) P ( Y ) argmax_{Y}P(X|Y)P(Y) argmaxYP(X∣Y)P(Y),我们要找一个Y,让 P ( X ∣ Y ) P ( Y ) P(X|Y)P(Y) P(X∣Y)P(Y)的值最大,而 P ( Y ) P(Y) P(Y)就是Language Model
- LAS中,对于使用deep learning的端到端模型来说,好像就不需要Language Model了。因为decoding的原本公式是 a r g m a x Y P ( Y ∣ X ) argmax_{Y}P(Y|X) argmaxYP(Y∣X),是没有 P ( Y ) P(Y) P(Y)的。但神奇的地方是,我们可以把decoding公式改写成 a r g m a x Y P ( Y ∣ X ) P ( Y ) argmax_{Y}P(Y|X)P(Y) argmaxYP(Y∣X)P(Y)往往会让模型的performance变好。为什么加上这个 P ( Y ) P(Y) P(Y)会使得模型效果更好,是因为这个 P ( Y ∣ X ) P(Y|X) P(Y∣X)与 P ( Y ) P(Y) P(Y)可以从不同的来源来估测。对于 P ( Y ∣ X ) P(Y|X) P(Y∣X)的估测是需要成对的资料的,比较不容易估测的好;而 P ( Y ) P(Y) P(Y)的估测数据只需要收集大量的文字,比较容易估测的好。例如,如今非常著名的Bert使用了30亿个以上的词汇来训练,当然,这不是使用词汇最多的语言模型。 这也就是为什么我们需要Language Model的原因。
这样使用Language Model的方法不是只会用在语音辨识里面,在很多应用里都会用到,基本上今天的端到端模型,输出是文字,往往加上Language Model就有用
II N-gram
那怎么估测一个 token sequence 的几率呢?在还没有deep learning的技术之前,过去最常用的技术叫做N-gram language model

1 定义
对于一串 token sequence 来说,计算它的几率,最直观的方法就是统计它在数据中出现的次数/总次数(即几率)。但问题是,人类的句子非常复杂繁多,所以随便给出一个句子,它在我们的训练数据里不一定出现,次数为0,但我们不能就认为这个句子出现的概率就是0.我们不能因为一个句子没有出现在训练资料里面,它的几率就是0,这是显然不合理的。所以就有了N-gram Language Model的想法。
P ( y 1 , y 2 , . . . , y n ) = P ( y 1 ∣ B O S ) P ( y 2 ∣ y 1 ) . . . P ( y n ∣ y n − 1 ) — — 2 − g r a m P(y1,y2,...,y_{n}) = P(y1|BOS)P(y2|y1)...P(y_{n}|y_{n-1}) ——2-gram P(y1,y2,...,yn)=P(y1∣BOS)P(y2∣y1)...P(yn∣yn−1)——2−gram
N-gram 的想法是把 token sequence的几率拆解成前后条件概率的概率累乘
举例来说,我们想算”wreck a nice beach“这个句子的几率:P(“wreck a nice beach”)
我们可以把它拆解成 P ( w r e c k ∣ B O S ) P ( a ∣ w r e c k ) P ( n i c e ∣ a ) P ( b e a c h ∣ n i c e ) P(wreck|BOS)P(a|wreck) P(nice|a)P(beach|nice) P(wreck∣BOS)P(a∣wreck)P(nice∣a)P(beach∣nice)来计算
而每一项的估测方法也很简单,举例来说, P ( b e a c h ∣ n i c e ) = C ( n i c e . b e a c h ) C ( n i c e ) P(beach|nice)=\frac{C(nice.beach)}{C(nice)} P(beach∣nice)=C(nice)C(nice.beach),直接从训练资料里统计次数即可
2-gram就是统计两个词汇计算token sequence的几率,3-gram就是统计三个词汇等等。
有趣的是,为什么要拿**“wreck a nice beach”**当作例子呢,因为这个句子跟语音辨识的英文“recognize speech”发音一模一样,所以在语音辨识上,人们在讲语言模型时都会举着个例子。
2 问题

N-gram的问题在于,就算我们今天把整个token sequence的几率拆解成很多项N component相乘,我们收集的训练资料还是远远不够,让我们准确的计算出一个句子的出现的几率。
举例来说,假设我们的训练资料有两句:
The dog ran…
The cat jumped…
则根据3-gram,我们计算 P ( j u m p e d ∣ T h e . d o g ) = 0 P(jumped|The.dog) = 0 P(jumped∣The.dog)=0, P ( r a n ∣ T h e . c a t ) = 0 P(ran|The.cat) = 0 P(ran∣The.cat)=0,这样就是说,dog后是不可能接jump的,这是不切实际的。
为了要解决这个问题,N-gram Language Model必须要搭配一个language model smoothing的技巧,也就是说,有些n gram统计出来的几率是0,但我们可以人为给定它一个较小的值而非0,它只是概率很低,那这个较小的值该是多少,这就是language model smoothing来给出的(详情请参考《数位语音处理》)
3 Language Model Smoothing
在没有deep learning技术之前,人们是如何处理language model smoothing的呢?让我们来了解一个关键的技术:Continuous LM
Continuous LM
在讲 Continuous LM 之前,让我们先超展开讲一下推荐系统

Matrix Factorization
现在假如说,有一个动漫网站,提供4种动漫,且有人为他们看过的动漫打了分。而推荐系统要做的就是补全这个打分表里的null,再根据预测的分数来给相应的人做动漫推荐。比如B这个人,他应该会喜欢第二部动漫,因为A、B、C都很喜欢第一部动漫,而A、C也都很喜欢第二部。这项技术就叫做Matrix Factorization。此时,就有人想到把这个技术用到 Language Model上来补全0概率的gram
Continuous LM
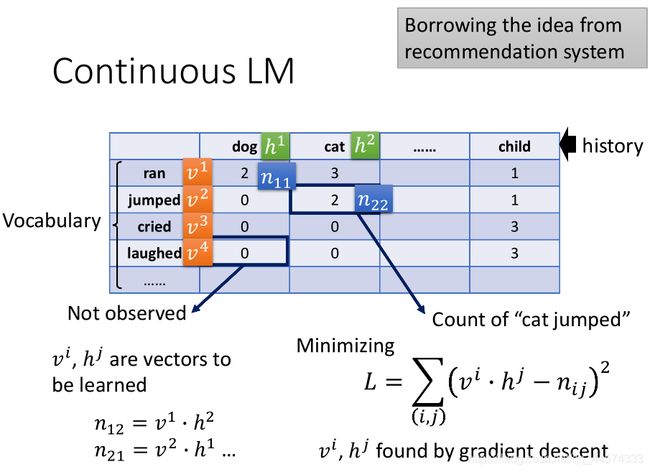
上表,横纵 轴都代表了Vocabulary的token,表中的数字代表横轴后接纵轴的统计次数
同样的,我们仿照推荐系统做一个同样的表格,我们想要估测出表中0的较小值应该填什么。我们就可以用Matrix Factorization技术来解这个问题,我们具体该怎么做呢?。
首先,将每一个词汇都对应一个向量(词向量)h和v,而这个词向量就是我们要训练的。
其次,我们将表格中非零数值n的部分当作Y,将h和v当作x
最终,最小化h和v的点积与n的差为训练目标
至此我们将得到所有词汇的词向量,而表中数值为0的部分将替换为词向量的点积,这样便解决了soothing的问题
III NN-based LM

其实 Continuous LM 可以看作是只有一个hidden layer的简单的deep network,输入的是token的1-of-N encoding。
因此,一般的NN-based的Language Model 类似,它最早是想要取代N-gram的LM,比如我们想训练一个NN-based LM去取代3-gram
首先,收集一定的资料
然后,给模型输入两个词汇,让模型去预测下一个词汇
至此,我们可以将
P ( y 1 , y 2 , . . . , y n ) = P ( y 1 ∣ B O S ) P ( y 2 ∣ y 1 ) . . . P ( y n ∣ y n − 1 ) — — 2 − g r a m P(y1,y2,...,y_{n}) = P(y1|BOS)P(y2|y1)...P(y_{n}|y_{n-1}) ——2-gram P(y1,y2,...,yn)=P(y1∣BOS)P(y2∣y1)...P(yn∣yn−1)——2−gram
n-gram里面每一项的几率换成neural network的输出即可。
1 NN-based LM起源

可以找到的最早的nn-based LM的文献就是上图这篇,2003年Bengio发表的,用network来取代n-gram,自动做smoothing,跨时代的是,在这篇论文中,它里面提到了word embedding的概念(2013年发明)。
2 RNN-based LM

接下来就进入了RNN-based的Language Model,为什么需要RNN-based的语言模型,因为我们如果想看非常长的history决定下一个token出现的几率,如果只是一般的NN的话,我们的输入将变得非常的长。因此,我们使用RNN将history读进去,最后一个hidden layer输出的隐藏层向量 h t h_{t} ht与每一个token的向量v相乘得到t+1应该出现的token。
IV How to use LM to improve LAS
那这些Language Model怎么和今天的NN-based model结合起来呢?我们以LAS当作例子
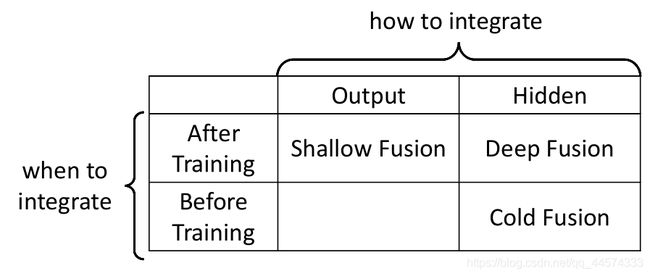
结合的方法有很多,在文献上可以看到三种
- Shallow Fusion :LAS已经训练好、LM也已经训练好;在输出端结合。
- Deep Fusion :LAS已经训练好、LM也已经训练好;在隐藏层结合,并需要另外训练一个Network来输出distribution
- Cold Fusion :LAS没有训练、LM已经训练好;在隐藏层结合,并需要训练一个LAS和Network来输出distribution
1 Shallow Fusion

我们有一个已经训练好的LAS和一个已经训练好的LM,现在我们要把这两个结合起来,这个结合想法是很直接的。
首先,LAS输出一个probability distribution P L A S ( y ) P_{LAS}(y) PLAS(y),LM输出一个probability distribution P L M ( y ) P_{LM}(y) PLM(y)
然后,把这两个 P L A S ( y ) P_{LAS}(y) PLAS(y)和 P L M ( y ) P_{LM}(y) PLM(y) log相加以后得到最终的probability distribution’
注意,在相加的时候,往往会设计一个超参数 λ \lambda λ来权衡我们是更相信LM还是LAS,即 l o g P L A S ( y ) + λ l o g P L M ( y ) logP_{LAS}(y) + \lambda logP_{LM}(y) logPLAS(y)+λlogPLM(y)
最后,decode方法和之前讲的一样,我们可能会用beam search来找到几率最大的token sequence
2 Deep Fusion

与Shallow Fusion一样,Deep Fusion的LAS和LM也是训练好的。但是,Shallow Fusion是在输出端结合,而Deep Fusion是在hidden layer的输出结合。
Deep Fusion是将LAS和LM的hidden layer的输出拿出来,放到一个另外训练的Network里,再由这个Netowork产生distribution
注意,我们将LM的hidden layer拿出来,就不能换LM,如果抽换LM我们就要重新训练Network来判断LM和LAS的hidden关系(什么时候我们需要常常抽换LM呢?在不同domain的时候,同一个词在发音虽相同,但意义往往不同,LM可以随着不同的domain来训练不同的LM)
那我们如果需要在Deep Fusion换LM该怎么办呢?有一种方法是,不要把LM的hidden layer拿出来,而是把LM跑到最后,但不过softmax得到vocabulary的distribution,将这个distribution与LAS的hidden layer结合,这样就可以随意更换LM了,当然这个distribution也可以由传统的N-gram得到,故可以将N-gram与LAS结合。
3 Cold Fusion

Cold Fusion相较于前两个方法,不同的是什么时候把LM与LAS结合。对于Cold Fusion,
首先,我们先有一个训练好的LM,但LAS还没有训练的,参数还是随机初始化的
然后,我们将两个模型接到一起,再通过数据进行训练
这样训练有什么好处呢?这样可以加快LAS的训练速度。坏处就是真的不能随便换LM。
至此,语音辨识系列将结束。