Sequential模型实现手写数字识别
Sequential模型实现手写数字识别
Sequential模型是一个神经网络的框架,只有一组输入和一组输出,各个层之间按照顺序先后堆叠。
一般来说使用Sequential搭建、使用、评估神经网络可以有以下几步:
1、建立模型
首先先导入需要的函数库和加载手写数字的训练集
import tensorflow as tf
import matplotlib.pyplot as plt
import numpy as np
mnist = tf.keras.datasets.mnist
(train_x,train_y),(test_x,test_y) = mnist.load_data()
然后开始设计神经网络结构
因为输入的每张图片是28*28的黑白图片,类型为二维数组,所以在输入的时候要指定好输入的尺寸大小,这里我们将加载的测试集拉伸为784的一维张量(也可直接用Flatten()函数),并对数据进行归一化来加快数据的处理
X_train = train_x.reshape(60000,28*28)#共60000张图片
X_test = test_x.reshape(10000,28*28)#共一万张图片
X_train,X_test=tf.cast(train_x/255.0,tf.float32),tf.cast(test_x/255.0,tf.float32)
y_train,y_test = tf.cast(train_y,tf.int16),tf.cast(test_y,tf.int16)
开始建立模型
输入层我们用Flatten()函数获取到28*28的输入
隐含层我们设置128个神经元,激活函数为relu
输出层有10个,分别为0-9的数字,因为是多分类任务,我们选择softmax作为激活函数
model = tf.keras.Sequential()
model.add(tf.keras.layers.Flatten(input_shape=(28,28)))
model.add(tf.keras.layers.Dense(128,activation='relu'))
model.add(tf.keras.layers.Dense(10,activation='softmax'))
2、配置训练方法
使用compile()函数对模型配置训练
优化器我们使用Adam
损失函数我们使用稀疏交叉熵损失函数
因为标签值为0-9的数,预测值为概率,所以准确率使用稀疏分类准确率函数
model.compile(optimizer='adam',loss='sparse_categorical_crossentropy',metrics=['sparse_categorical_accuracy'])
3、训练模型
一共60000个数据,划分出0.2作为测试数据,小批量使用64个数据,训练五轮
model.fit(X_train,y_train,batch_size=64,epochs=5,validation_split=0.2)
测试结果如下
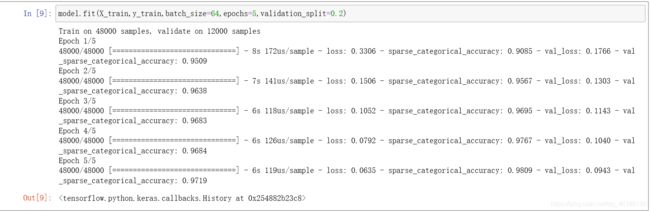
可以看到最后训练集上的损失和准确率分别为0.0635、98.09%,测试集上的损失和准确率分别为0.0943、97.19%
4、评估模型
使用evaluate函数评估模型
model.evaluate(X_test,y_test,verbose=2)
模型输出损失为0.091,准确率为97.04%
5、使用模型
我们选择一个数据进行测试,先了解第6张数据的值
plt.axis('off')
plt.imshow(test_x[5],cmap='gray')
plt.show()
print(y_test[5])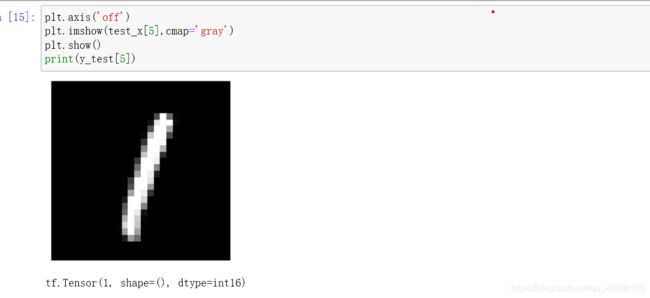
第6张图片标签值为1
使用模型进行测试
print(model.predict([[X_test[5]]]))
print(np.argmax(model.predict([[X_test[5]]])))输出结果
可以看到为1的概率最大,输出结果与标签值相同。
也可以多测试几组数据,这里就不展示了。