OpenCV-python学习笔记(二)——图像操作
为了快速学习,按照中文教程中的顺序,走一遍python接口。英文能力较强者,可以从对应的英文教程自己翻译学习。
另: 自认为挺好的一个教程博客。共有四个系列,比较全面详细,适合初学者。
一、OpenCV图像的基本操作
- 获取并修改像素值
读取一副图像,根据像素的行和列的坐标获取它的像素值,对于RGB图像而言,返回RGB的值,对于灰度图则返回灰度值。
import cv2
import numpy
img = cv2.imread('0.jpg')
px = img[100, 100]
print ("img(100, 100)的像素值:", px) #返回的值分别代表:蓝色、绿色、红色
#返回单一颜色值,如0、1、2分别对应该点蓝色、绿色、红色的值
blue = img[100, 100, 0]
print ("img(100, 100)的蓝色对应的像素值:", blue)
green = img[100, 100, 1]
print ("img(100, 100)的绿色对应的像素值:", green)
rad = img[100, 100, 2]
print ("img(100, 100)的红色对应的像素值:", rad)
img[101,101]=[255,255,255]
print(img[101,101])
注意:若读取图片的位置不正确,读取不报错,但是在下面会报错。
numpy是经过优化了的进行快速矩阵运算的包,所以不推荐逐个获取像素值并修改,能矩阵运算就不要用循环。
例如前5行的后3列,用numpy的array.item()和array.itemset()会更好。但是返回是标量,如果想获得所有RGB的值,需要使用array.item()分割他们。
#coding:utf8
import cv2
import numpy as np
img = cv2.imread('F:/picture.jpg')
#返回单一颜色值,如蓝色、绿色、红色
blue = img.item(100, 100, 0)
print ("blue:", blue)
green = img.item(100, 100, 1)
print ("green:", green)
red = img.item(100, 100, 2)
print ("red:", red)
#修改图像的像素值
px = img.itemset((100, 100, 2), 100)
print ("修改之后的像素值:", px)
- 获取图像属性
图像属性包括:行,列,通道,图像数据类型,像素数目等。
- img.shape 可以获得图像的形状,返回值是一个包含行数,列数,通道数的元组。
- img.size 可以返回图像的像素数目。
- img.dtype 返回图像的数据类型,在debug时很重要,因为OpenCV-Python代码中经常出现数据类型的不一致。
#coding:utf8
import cv2
import numpy as np
img = cv2.imread('0.jpg')
print ("访问图像属性", img.shape)
print ("像素的总数", img.size)
print ("图像色数据类型", img.dtype)
#输出结果
访问图像属性 (3000, 4000, 3)
像素的总数 36000000
图像色数据类型 uint8
- 图像ROI
对图像的特定区域操作。ROI是使用numpy索引来获得的。
import cv2
import numpy as np
img = cv2.imread('0.jpg')
ball = img[280:340, 330:390] #获取该区域
img[273:333, 100:160] = ball # 将另一区域变为该区域
- 拆分及合并图像通道
有时需要对RGB三个通道分别操作,这就需要拆分RGB为单个通道。有时需要把独立的通道的图片合成一个RGB。
r,g,b=cv2.split(img)#拆分
img=cv2.merge(r,g,b)#合并
或者
b=img[:,:,0]#拆分b通道
假如想使所有红色通道值都为0,不必拆分再赋值,可以使用numpy索引,这样更快
img[:,:,2]=0
cv2.split()是比较耗时的操作,能用numpy就尽量使用。
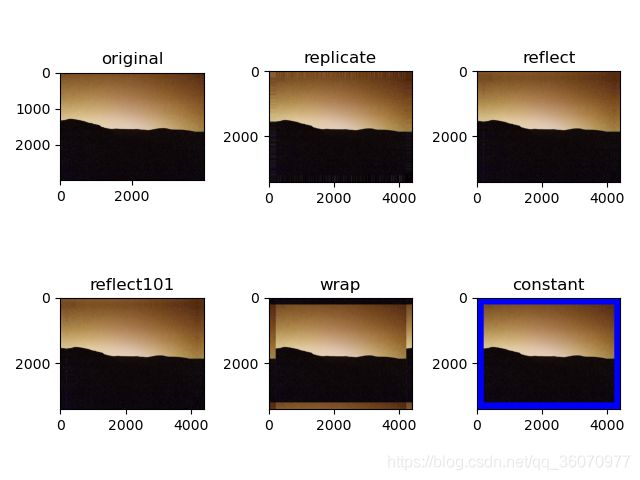
- 为图像扩边(填充)
想为图像周围建一个边可以使用cv2.copyMakeBorder()函数。这经常在卷积运算或0填充时被用到。
具体参数如下:
- src:输入图像;
- top, bottom, left, right: 在相应方向上的像素数量中的边界宽度;
- borderType -标志定义要添加的边界类型;
1、 cv2.BORDER_CONSTANT添加有颜色的常数值边界,还需要下一个参数(value)
2 、cv2.BORDER_REFLIECT边界元素的镜像。例如:fedcba | abcdefgh | hgfedcb
3、 cv2.BORDER_101或者cv2.BORDER_DEFAULT跟上面一样,但稍作改动,例如:gfedcb | abcdefgh | gfedcba
4 、cv2.BORDER_REPLICATE复后一个元素。例如: aaaaaa| abcdefgh|hhhhhhh
5 、cv2.BORDER_WRAP 不知怎么了, 就像样: cdefgh| abcdefgh|abcdefg - value边界颜色
import cv2
import numpy
from matplotlib import pyplot as plt
img = cv2.imread('roi.jpg')
blue = [255,0,0]
replicate = cv2.copyMakeBorder(img,200,200,200,200,cv2.BORDER_REPLICATE)
reflect = cv2.copyMakeBorder(img,200,200,200,200,cv2.BORDER_REFLECT)
reflect101 = cv2.copyMakeBorder(img,200,200,200,200,cv2.BORDER_REFLECT101)
wrap = cv2.copyMakeBorder(img,200,200,200,200,cv2.BORDER_WRAP)
constant = cv2.copyMakeBorder(img,200,200,200,200,cv2.BORDER_CONSTANT,value=blue)
plt.subplot(231),plt.imshow(img,'gray'),plt.title('original')
plt.subplot(232),plt.imshow(replicate,'gray'),plt.title('replicate')
plt.subplot(233),plt.imshow(reflect,'gray'),plt.title('reflect')
plt.subplot(234),plt.imshow(reflect101,'gray'),plt.title('reflect101')
plt.subplot(235),plt.imshow(wrap,'gray'),plt.title('wrap')
plt.subplot(236),plt.imshow(constant,'gray'),plt.title('constant')
plt.show()
在图片像素较大时,可以调大四周的值,现象更加明显,其效果入下:
二、图像上的算术运算
涉及函数cv2.add() ,cv2.addWeighted()
- 图像加法
使用cv2.add()将两幅图像进行加法运算,也可以直接使用numpy,res=img1+img2.两幅图像的大小,类型必须一致,或者第二个图像可以是一个简单的标量值。
openCV的加法是一种饱和操作,而numpy的加法是一种模操作。
import numpy as np
import cv2
x=np.uint8([250])
y=np.uint8([10])
print(cv2.add(x,y))#250+10=260>=255
#结果为[[255]]
print (x+y)#250+10=260%255=4
#结果为[4]
OpenCV的结果会更好,so尽量使用OpenCV中的函数。
- 图像混合
这也是加法,不同的是两幅图像的权重不同,这会给人一种混合或者透明的感觉。图像混合的计算公式如下:
g(x) = (1−α)f0 (x)+αf1 (x)
通过修改α的值(0–>1),可以实现很酷的混合。
例:将两幅图像混合,第一幅权重为0.7.第二幅权重为0.3。函数cv2.addWeighed()可以按下面的公式对图片进行混合。
dst = α·img1 + β·img2+γ
这里γ的取值为0.
import cv2
import numpy as np
img1=cv2.imread('45.jpg')
img2=cv2.imread('messigray.png')
dst = cv2.addWeighted(img1,0.7,img2,0.3,0)
cv2.imshow('dst',dst)
cv2.waitKey(0)
cv2.destroyAllWindows()
注意:读入的两个照片需要有相同的大小,格式可以不一致。
- 按位运算
这里包括按位操作有:AND,OR,NOT,XOR等,当我们提取图像的一部分,选择非矩形ROI时,会很有用(下章)。下面进行如何改变一幅图的特定区域。
import cv2
import numpy as np
img1=cv2.imread('timg.jpg')
img2=cv2.imread('google.jpg')
# I want to put logo on top-left corner, So I create a ROI
rows,cols,channels = img2.shape
roi = img1[0:rows,0:cols]
# Now create a mask of logo and create its inverse mask also
img2gray = cv2.cvtColor(img2,cv2.COLOR_BGR2GRAY)
ret,mask = cv2.threshold(img2gray,175,255,cv2.THRESH_BINARY) # ret阈值,mask二值化的图
mask_inv = cv2.bitwise_not(mask) # 按位取非
# Now black-out the area of logo in ROI
#取ROI中与mask中不为零的值对应的像素的值,其让值为0 。
#注意这里必须有mask=mask或者mask=mask_inv,其中mask=不能忽略
img1_bg = cv2.bitwise_and(roi,roi,mask=mask)
#取roi中与mask_inv中不为零的值对应的像素的值,其他值为0
# Take only region of logo from logo image.
img2_fg = cv2.bitwise_and(img2,img2,mask=mask_inv)
# Put logo in ROI and modify the main image
dst = cv2.add(img1_bg,img2_fg)
img1[0:rows,0:cols] =dst
cv2.imshow('res',img1)
cv2.waitKey(0)
cv2.destroyAllWindows()
注意: 在二值化时,根据自己的图片,对阈值要进行调节,可达到更好的效果。
bitwise_and是对二进制数据进行“与”操作,即对图像(灰度图像或彩色图像均可)每个像素值进行二进制“与”操作,1&1=1,1&0=0,0&1=0,0&0=0
bitwise_or是对二进制数据进行“或”操作,即对图像(灰度图像或彩色图像均可)每个像素值进行二进制“或”操作,1|1=1,1|0=0,0|1=0,0|0=0
bitwise_xor是对二进制数据进行“异或”操作,即对图像(灰度图像或彩色图像均可)每个像素值进行二进制“异或”操作,11=0,10=1,01=1,00=0
bitwise_not是对二进制数据进行“非”操作,即对图像(灰度图像或彩色图像均可)每个像素值进行二进制“非”操作 ~0=1 ,~0=1。
参数:
- src1 –第一个输入数组或标量。
- src2 –第二个输入数组或标量。
- src –单输入数组。
- 值–标量值。
- dst –输出数组,其大小和类型与输入数组相同。
- mask –可选的操作掩码,8位单通道数组,用于指定要更改的输出数组的元素。
三、程序性能检测及优化
涉及函数 cv2.getTickCount,cv2.getTickFrequency。
- 使用OpenCV检测程序效率
- cv2.getTickCount函数返回从参考点到这个函数被执行的时钟数。在一个函数执行前后都调用它,可以得到这个函数的执行时间。
- cv2.getTickFrequency返回时钟频率,或者说每秒钟的时钟数。
例,窗口大小不同(5,7,9)的核函数来做中值滤波,查看一个函数运行了多少秒。
import cv2
import numpy as np
import time
import datetime
img1 = cv2.imread('timg.jpg')
e1 = cv2.getTickCount()
t1 = time.time()
for i in range(5,49,2):
img1 = cv2.medianBlur(img1,i) # 中值滤波,i为滤波模板的尺寸大小,必须是大于1的奇数,如3、5、7
e2 = cv2.getTickCount()
t2 = time.time()
time = (e2-e1)/cv2.getTickFrequency()
print(time)
print(t2 - t1)
python中time模块也可以实现,调用的函数是time.time()。程序中已给出。
- OpenCV中的默认优化
cv2.useOptimized()来查看优化是否被开启,cv2.setUesOptimized()来开启优化。
import cv2
import numpy as np
# check if optimization is enabled
In [5]: cv2.useOptimized()
Out[5]: True
In [6]: %timeit res = cv2.medianBlur(img,49)
10 loops, best of 3: 34.9 ms per loop
# Disable it
In [7]: cv2.setUseOptimized(False)
In [8]: cv2.useOptimized()
Out[8]: False
In [9]: %timeit res = cv2.medianBlur(img,49)
10 loops, best of 3: 64.1 ms per loop
注意: %timeit 使用 IPython 为你提供的魔法命令%timeit,执行前需要安装解释器。
- 在IPython中检测程序效率
有时你比两个相似操作的效率时,你可以使用 IPython 为你提供的法命令%time。他会代码好几次从而得到一个准确的时间它也可以用来测单代码的。
例如你知下同一个数学算用哪种式的代码会执的更快吗?
x = 5; y = x∗∗2
x = 5; y = x∗x
x = np.uint([5]); y = x∗x
y = np.squre(x)
我们可以在 IPython 的 Shell 中使用法命令找到答案。
import cv2
import numpy as np
In [10]: x =5
In [11]: %timeit y=x**2
10000000 loops, best of 3: 73 ns per loop
In [12]: %timeit y=x*x
10000000 loops, best of 3: 58.3 ns per loop
In [15]: z = np.uint8([5])
In [17]: %timeit y=z*z
1000000 loops, best of 3: 1.25 us per loop
In [19]: %timeit y=np.square(z)
1000000 loops, best of 3: 1.16 us per loop
竟然是第一种写法它居然比 Nump 快了 20 倍。如果考到数组构建的 能到 100 倍的差。自己的测试结果也是y=x*x速度最快,由于操作失误的报错过多,就用别人测试的结果。
注意: Python 的标算比 Nump 的标算快。对于仅包含一两个 元素的操作 Python 标比 Numpy 的数组快。但是当数组稍微大一点时 Numpy 就会胜出了。
- 效率优化技术
有些技术和编程方法可以我们大的发挥 Python 和 Numpy 的威力。 我们仅仅提一下相关的你可以接查找更多细信息。我们 的的一点是先用简单的方式实现你的算法结果正确当结 果正确后再使用上的提到的方法找到程序的瓶来优化它。
- 尽免使用循环尤其双层三层循环它们天生就是常慢的。
- 算法中尽使用向操作因为 Numpy 和 OpenCV 对向操作 了优化。
- 利用缓存一致性。
- 没有必的就不复制数组。使用图来代替复制。数组复制是常浪源的。
就算了上优化如果你的程序是很慢或者大的不可免的 你你应尝使用其他的包比如 Cython来加你的程序。
四、颜色空间转换
涉及函数:
- cv2.cvtColor()
- cv2.inRange()
- 转换颜色空间
在 OpenCV 中有 超过150 种进行颜色空间转换的方法。但是你以后就会发现我们经常用到的也就两种:BGR↔Gray 和 BGR↔HSV。
我们用到的函数是cv2.cvtColor(input_imageflag),其中flag就是转换类型。
-
对于BGR↔Gray的转换,我们使用的flag就是cv2.COLOR_BGR2GRAY。
-
对于BGR↔HSV的转换我们用的flag就是cv2.COLOR_BGR2HSV。
通过以下的命令查看所有可用的 flag。(自己认为中文教程作者的程序存在小问题)
import cv2
flags=[i for i in dir(cv2) if i.startswith('COLOR_')]
print (flags)
在 OpenCV 的 HSV 格式中,H(色彩/色度)的取值范围是 [0,179], S(饱和度)的取值范围 [0,255],V(亮度)的取值范围 [0,255]。但是不同的软件使用的值可能不同。所以当你拿 OpenCV 的 HSV 值与其他软件的 HSV 值对比时,一定要记得归一化。
- 物体跟踪
现在我们知怎样将一幅图像从 BGR 换到 HSV 了,我们可以利用 一点来提取带有某个特定色的物体。在 HSV 颜色空间中要比在 BGR 空间中更容易表示一个特定颜色。在我们的程序中,我们提取的是一个蓝色的物体。下就是就是我们做的几步:
- 从视频中获取每一帧图像
- 将图像换到 HSV 空间
- 设置 HSV 阀值到蓝色范围。
- 获取蓝色物体,当然我们可以做其他任何我们想做的事,比如:在蓝色物体周围画一个圈。
在英文网站上做的是识别蓝色的瓶盖,我们可以对其进行修改。
import cv2
import numpy as np
cap = cv2.VideoCapture(0)
while(1):
#获取每一帧
ret,frame = cap.read()
#转换到HSV
hsv = cv2.cvtColor(frame,cv2.COLOR_BGR2HSV)
#设定蓝色的阀值
lower_blue = np.array([110,50,50])
upper_blue = np.array([130,255,255])
#根据阀值构建掩模
mask = cv2.inRange(hsv,lower_blue,upper_blue)
#对原图和掩模进行位运算
res = cv2.bitwise_and(frame,frame,mask=mask)
#显示图像
cv2.imshow('frame',frame)
cv2.imshow('mask',mask)
cv2.imshow('res',res)
k = cv2.waitKey(5)&0xFF
if k == 27:
break
#关闭窗口
cv2.destroyAllWindows()
完成识别蓝色区域,噪点较大。
- 怎样找到要跟踪对象的HSV值
函数cv2.cvtColor()可以用到这里,现在需要传入的参数是RGB的值而不是一幅图。例如要找到绿色的HSV值,只需在终端输入以下命令:
import cv2 import numpy as np
green=np.uint8([0,255,0]) hsv_green=cv2.cvtColor(green,cv2.COLOR_BGR2HSV)
error: /builddir/build/BUILD/opencv-2.4.6.1/ modules/imgproc/src/color.cpp:3541:
error: (-215) (scn == 3 || scn == 4) && (depth == CV_8U || depth == CV_32F) in function cvtColor
#scn (the number of channels of the source),
#i.e. self.img.channels(), is neither 3 nor 4.
# #depth (of the source),
#i.e. self.img.depth(), is neither CV_8U nor CV_32F.
# 所以不能用 [0,255,0] 而用 [[[0,255,0]]]
# 的三层括号应分别对应于 cvArray cvMat IplImage
green=np.uint8([[[0,255,0]]]) hsv_green=cv2.cvtColor(green,cv2.COLOR_BGR2HSV)
print (hsv_green )
[[[60 255 255]]]
现在可以分别用 [H-100,100,100] 和 [H+100,255,255] 做上下阀值。除了个方法之外,可以使用任何其他图像编辑软件(例如 GIMP) 或者在线换软件找到相应的 HSV 值,但是后别忘了调节 HSV 的范围。(此处的值为什么是 [H-100,100,100] 和 [H+100,255,255] ,在读了英文教程后还是没太明白,知道的大神可以评论告知。)
五、几何变换
涉及函数:
- cv2.getPerspectiveTransform
- cv2.warpAffine
- cv2.warpPersperctive
- 扩展缩放
只是改变图像的尺寸大小,cv2.resize()可以实现这个功能。在缩放时推荐cv2.INTER_AREA,在拓展时推荐cv2.INTER_CUBIC(慢)和cv2.INTER_LINEAR。默认情况下所有改变图像尺寸大小的操作使用的是插值法都是cv2.INTER_LINEAR。
cv2.resize() 放大和缩小图像
参数:
src: 输入图像对象
dsize:输出矩阵/图像的大小,为0时计算方式如下:dsize = Size(round(fx*src.cols),round(fy*src.rows))
fx: 水平轴的缩放因子,为0时计算方式: (double)dsize.width/src.cols
fy: 垂直轴的缩放因子,为0时计算方式: (double)dsize.heigh/src.rows
interpolation:插值算法
cv2.INTER_NEAREST : 最近邻插值法
cv2.INTER_LINEAR 默认值,双线性插值法
cv2.INTER_AREA 基于局部像素的重采样(resampling using pixel area relation)。对于图像抽取(image decimation)来说,这可能是一个更好的方法。但如果是放大图像时,它和最近邻法的效果类似。
cv2.INTER_CUBIC 基于4x4像素邻域的3次插值法
cv2.INTER_LANCZOS4 基于8x8像素邻域的Lanczos插值
cv2.INTER_AREA 适合于图像缩小, cv2.INTER_CUBIC (slow) & cv2.INTER_LINEAR 适合于图像放大
import cv2
img = cv2.imread('45.jpg')
#下面的None本应该是输出图像的尺寸,但是因为后面我们设置了缩放因子,所以,这里为None
res = cv2.resize(img,None,fx=2,fy=2,interpolation=cv2.INTER_CUBIC)
#or
#这里直接设置输出图像的尺寸,所以不用设置缩放因子
height , width =img.shape[:2]
res = cv2.resize(img,(2*width,2*height),interpolation=cv2.INTER_CUBIC)
while(1):
cv2.imshow('res',res)
cv2.imshow('img',img)
if cv2.waitKey(1)&0xFF == 27:
break
cv2.destroyAllWindows()
- 平移
如果想要沿(x,y)方向移动,移动的距离为(tx,ty)可以以下面方式构建移动矩阵。
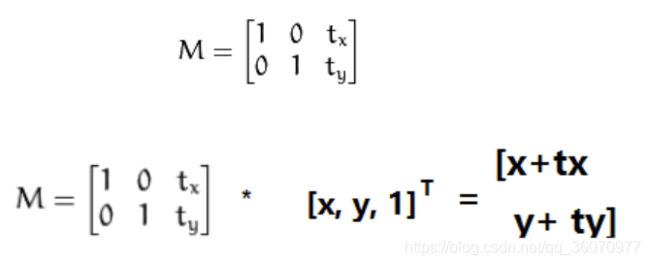
import cv2
import numpy as np
img = cv2.imread('messi5.jpg',0)
rows,cols = img.shape
M = np.float32([[1,0,100],[0,1,50]])
dst = cv2.warpAffine(img,M,(cols,rows))
cv2.imshow('img',dst)
cv2.waitKey(0)
cv2.destroyAllWindows()
可以使用Numpy数组构建矩阵,数据类型是np.float32,然后传给函数cv2.warpAffine()
函数cv2.warpAffine() 的第三个参数的是输出图像的大小,它的格式
应该是图像的(宽,高)。应该记住的是图像的宽对应的是列数,高对应的是行数。
- 旋转
将(x,y),以坐标原点为中心,顺时针方向旋转α得到(x1,y1), 有如下关系x1 = xcosα-ysinα, y1 =xsinα+ycosα; 因此可以构建对应的转变矩阵如下:
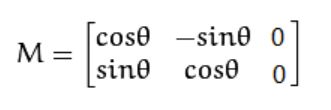
opencv将其扩展到,任意点center为中心进行顺时针旋转α,放大scale倍的,转变矩阵如下:
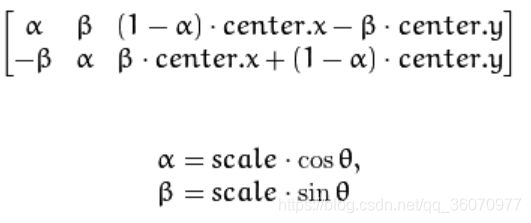
通过getRotationMatrix2D()能得到转变矩阵
cv2.getRotationMatrix2D() 返回2*3的转变矩阵(浮点型)
参数:
center:旋转的中心点坐标
angle:旋转角度,单位为度数,证书表示逆时针旋转
scale:同方向的放大倍数
import cv2
img = cv2.imread('45.jpg',0)
rows,cols=img.shape
#这里的第一个参数为旋转中心,第二个为旋转角度,第三个为旋转后的缩放因子
#可以通过设置旋转中心,缩放因子以及窗口大小来防止旋转后超出边界的问题。
M=cv2.getRotationMatrix2D((cols/2,rows/2),45,0.6)
#第三个参数是输出图像的尺寸中心
dst=cv2.warpAffine(img,M,(2*cols,2*rows))
while(1):
cv2.imshow('img',dst)
if cv2.waitKey(1)==27:
break
cv2.destroyAllWindows()
- 仿射变换
仿射变换(从二维坐标到二维坐标之间的线性变换,且保持二维图形的“平直性”和“平行性”。仿射变换可以通过一系列的原子变换的复合来实现,包括平移,缩放,翻转,旋转和剪切)
cv2.warpAffine() 仿射变换(从二维坐标到二维坐标之间的线性变换,且保持二维图形的“平直性”和“平行性”。仿射变换可以通过一系列的原子变换的复合来实现,包括平移,缩放,翻转,旋转和剪切)
参数:
img: 图像对象
M:2*3 transformation matrix (转变矩阵)
dsize:输出矩阵的大小,注意格式为(cols,rows) 即width对应cols,height对应rows
flags:可选,插值算法标识符,有默认值INTER_LINEAR,
如果插值算法为WARP_INVERSE_MAP, warpAffine函数使用如下矩阵进行图像转dst(x,y)=src(M11*x+M12*y+M13,M21*x+M22*y+M23)
borderMode:可选, 边界像素模式,有默认值BORDER_CONSTANT
borderValue:可选,边界取值,有默认值Scalar()即0
常用插值算法:
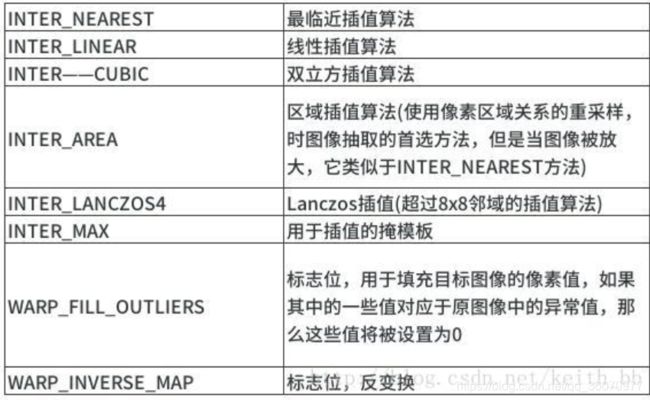
仿射变换的本质:即一个矩阵A和向量B共同组成的转变矩阵,和原图像坐标相乘来得到新图像的坐标,从而实现图像移动,旋转等。如下矩阵A和向量B组成的转变矩阵M,用来对原图像的坐标(x,y)进行转变,得到新的坐标向量T
矩阵A和向量B
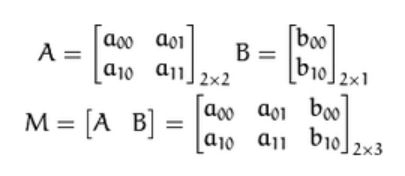
仿射变换(矩阵计算):变换前坐标(x,y)
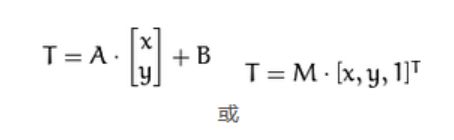
变换结果:变换后坐标(a00x+a01 y+b00, a10x+a11y+b10)
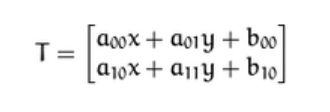
import cv2
import numpy as np
from matplotlib import pyplot as plt
img=cv2.imread(''draw.png')
rows,cols,ch = img.shape
pts1 = np.float32([[50,50],[200,50],[50,200]])
pts2 = np.float32([[10,100],[200,50],[100,250]])
#行,列,通道数
M = cv2.getAffineTransform(pts1,pts2)
dst = cv2.warpAffine(img,M,(cols,rows))
plt.subplot(121),plt.imshow(img),plt.title('Input')
plt.subplot(121),plt.imshow(img),plt.title('output')
plt.show()
(中文教程中的程序存在一点点问题,实验时注意plt的使用。)
- 透视变换
对于视角变换,我们需要一个3x3变换矩阵。在变换前后直线还是直线。需要在原图上找到4个点,以及他们在输出图上对应的位置,这四个点中任意三个都不能共线,可以有函数cv2.getPerspectiveTransform()构建,然后这个矩阵传给函数cv2.warpPerspective()
cv2.getPerspectiveTransform() 返回3*3的转变矩阵
参数:
src:原图像中的四组坐标,如 np.float32([[56,65],[368,52],[28,387],[389,390]])
dst: 转换后的对应四组坐标,如np.float32([[0,0],[300,0],[0,300],[300,300]])
cv2.wrapPerspective()
参数:
src: 图像对象
M:3*3 transformation matrix (转变矩阵)
dsize:输出矩阵的大小,注意格式为(cols,rows) 即width对应cols,height对应rows
flags:可选,插值算法标识符,有默认值INTER_LINEAR,
如果插值算法为WARP_INVERSE_MAP, warpAffine函数使用如下矩阵进行图像转dst(x,y)=src(M11*x+M12*y+M13,M21*x+M22*y+M23)
borderMode:可选, 边界像素模式,有默认值BORDER_CONSTANT
borderValue:可选,边界取值,有默认值Scalar()即0
官网代码示例:
img = cv2.imread('sudokusmall.png')
rows,cols,ch = img.shape
pts1 = np.float32([[56,65],[368,52],[28,387],[389,390]])
pts2 = np.float32([[0,0],[300,0],[0,300],[300,300]])
M = cv2.getPerspectiveTransform(pts1,pts2)
dst = cv2.warpPerspective(img,M,(300,300))
plt.subplot(121),plt.imshow(img),plt.title('Input')
plt.subplot(122),plt.imshow(dst),plt.title('Output')
plt.show()