数据产品-数据仓库的规范化建设
不积跬步无以至千里,现今很多头部企业能实现鳌头独占的一个很大原因也是基于本身长久的数据积累,进而形成数据可应用化的业务壁垒。一直以来,马云小伙所贯彻的新能源战略为“数据”的主张也引领着很多企业往数字化方向发展,而对于如何将恒河沙数的数据沉淀为数据资产,进行走通业务数据化和数据业务化的闭环,一直都是很多大企业的攻破重点。而数据仓库的建设,是企业数据资产化的必经过程已是百喙如一,本篇文章想和大家分享一下我所理解的数仓的规范化建设过程
一、建设前的注意点(非数仓建设的过程描述)
1、数据产品和老板们的矛盾点:
做过数仓的小伙伴可能比较有感知,数仓的建设周期长久,高可用的数仓建设过程都要长至半年以上,整个周期的产出是指标体系文档、数据模型、数据字典等,对于不知为何要进行数据分层设计的老板来说,这些增加了数据的存储成本,没看到给业务增长营收带来实际的产出。好在我们在做之前是和老板们讲清楚整个建设的过程
2、数据产品和数据研发的矛盾点:
作为数据产品,我们基于从产品侧的理解去设计建设规范,比如指标矩阵的设计规范、数仓分层规范、层级命名规范,对应数据研发侧也会基于他们的考虑出一套规范,所以容易撞出火花。所以最好的作法是参照行业上现在比较成熟的作法去落地实施,本次我们的建设过程就是参照阿里的建设理念和学而思网校的落地实践进行开展
二、建设前的规范化说明
1、模型概念原则
数据模型定义了数据之间关系和结构,使得我们可以有规律地获取想要的数据,数据模型是在业务需求分析之后,数据仓库工作开始时的第一步,而模型的设计需要遵循和多准则,比如:高内聚和低耦合、核心模型与扩展模型分离、公共处理逻辑下沉及单一、成本与性能平衡、数据可回滚、一致性、命名清晰可理解
但作为数据产品,更多需要输出的业务建模的指标矩阵,个人觉得最需要考虑模型整体的“高内聚低耦合”。所谓的“高内聚低耦合”,用我们业务上的数据用法就是:将业务相关的指标在底层表设计时存在一起,而对于低概率同时访问的数据分离开来,比如对于营收数据域,可以将流水相关的指标数据都放置一起进行表设计,而对于用户活跃相关的指标数据放置日志数据域。我会觉得这个点是最重要的原因,是其关系着建模之后对应的分析师和数据应用层的使用体验,这个会直接决定我们的模型好不好用
2、层级设计原则
2.1、DWD数据明细层


2.2、DWS数据汇总层

2.3、ADS数据应用层

2.4、DIM数据维表


2.5、数据映射表

2.6、数据字典表

3、公共命名规范
不使用驼峰命名法,不使用引号命名,用下划线命名法
事实表维度一般只存维度编码,不存维度中文名称
事实表字段顺序:粒度、维度、指标。
表及字段名不宜过长,优先使用约定成俗的中文与英文缩写
表及字段COMMENT信息,必须填写中文,<>注明杖举值、其他说明
区日期统一使用dt,格式YYYYMMDD
3.1、数据表后缀说明
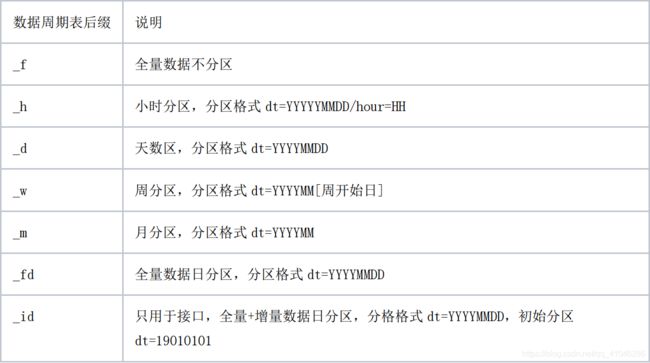
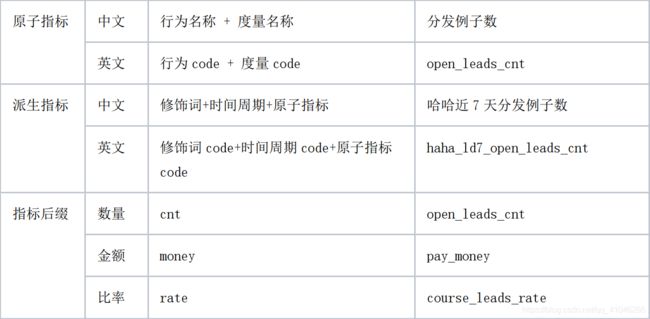
3.2、指标命名规范:
![]()
3.3、数据类型定义:

三、数仓模型体系拆解
现在的数仓建模的体系架构是已经较为明晰的,总体流程可以描述为以下几个点:
1、以“维度建模”为理论基础去构建总线型矩阵,根据实际对业务的深入了解去拆分整个公司体系下的数据域(也可以称之为主题域,两者可以单独开也可以进行融合)
2、进而基于每个数据域或主题域的特性,去拆分描述这个数据域下的核心业务过程、修饰类型和分析维度,构建所有主题域下的业务过程和分析维度的总线型矩阵
3、基于每一个业务过程,去拆解描述每一个业务过程会产生的原子指标,通过原子指标和修饰词的组合,产生对应的派生指标,聚合多种派生指标的四则运算则产生对应的复合指标
4、基于上面的步骤,我们梳理出了每个数据域下的业务动作、分析维度、原子指标、复合指标、派生指标和对应的修饰类型词条。数据研发可根据此总线型矩阵去对应构建每一个数据域应该构建的维度表和数仓分层事实表 
相关概念的说明:
①数据域:数据域是业务板块中有一定规模的且相对独立的数据业务范围。面向业务分析,将业务过程或者维度进行抽象的集合,为保障整个体系的生命力,数据域是需要抽象提炼的、并且长期维护和更新的,但不轻易变动。在划分数据域时,既能涵盖当前所有的业务需求,又能在新业务进入时无影响的被包含近已有的数据域和扩展新的数据域
②业务过程:指企业的业务活动事件,如下单、支付、退款都是业务过程。业务过程是一个不可拆分的行为事件,通俗地讲,业务过程就是企业活动中的事件
③时间周期:用来明确数据统计的时间范用或者时间点,如最近30天、自然周、截至当日等
④修饰词:指除了统计维度以外指标的业务场景限定抽象。如在日志域中,有修饰词PC端、APP端等
⑤原子指标:基于某一业务事件行为下的度量,是业务定义中不可再拆分的指标,具有明确业务含义的名词,如出勤人数
⑥派生指标:派生指标=一个原子指标+多个修饰词(可选)+时间周期。可以理解为对原子指标业务统计范围的圈定。如原子指标:
出勤人数,最近1天北京分校出勤人数则为派生指标(最近1天为时间周期,北京分校为修饰词)
⑦复合指标:原子指标或者派生指标进行数学运算得到的新的指标,比如已经存在两个指标续报人数与在班人数,两个指标相除就会生成续报率指标
⑧维度:维度是度量的环境,用来反映业务的一个属性,包括原子维度和派生维度,原子维度比如城市,通过对城市的上钻可以得到一线城市、二线城市等,则为派生维度
⑨维度项:维度项隶属于一个维度,如城市维度里面的北京、上海等
四、总线型矩阵拆解
1、业务流程的全面梳理
基于业务调研,梳理出核心的数仓主题域,并通过对业务的深度理解,梳理每一个主题域下所对应的业务过程。这是数仓建设的第一步,也是最重要的一步,因为其关系着整个数仓的建设框架和对应的底层数据域如何划分的问题
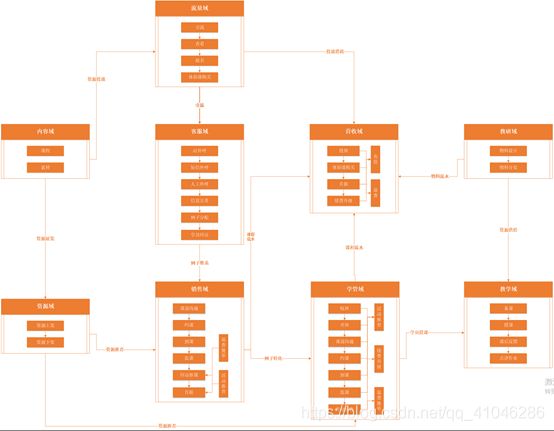
2、拆分主题域和数据域
通过对业务流程的全面梳理,我们已经能够同步输出对应我们再应用层会关注的核心模块是哪一些内容,直接可以映射到我们的主题域的划分。但通过和数据研发的沟通我们可以发现。直接按业务流程划分的主题域去构建对应的数据域是不满住“高内聚低耦合”的原则,比如:同样是活动,在销售域和教学域两处都会发生,如果两个数据都构建同样的业务模块,是不满住我们最初想表达的最重的原则的。
在这里,我们可以通过对历史报表的分析和进一步的业务调研,可以进一步对业务流程进行抽象,将关联性强的业务过程放置一起,关联性低的内容隔离出来,进而去拆分我们数仓应该搭建的数据域。而在梳理业务过程的时候,我们可以基于我们的主题域进行过程和指标相关的梳理,主要原因是在于基于主题域去梳理,能够极大的方便我们构建ADS应用层,对齐各业务线的动作和明确我们最终想呈现的内容。
主题域:
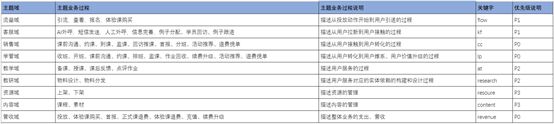
数据域:

3、拆解总线型矩形
有了主题域和对应每个主题域下的业务动作,我们需要对应去构建每个业务动作会从哪些维度进行下钻分析。一般可以基于业务调研进行信息收集,同时我们也可以基于历史的报表的分析进行维度抽离得到原子维度,通过原子维度聚合得到派生维度,然后将全部业务动作作为举证的列,抽离全部分析维度作为矩阵的行,进而构建我们的总线型矩阵

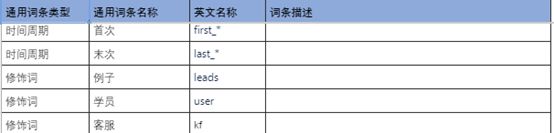
4、维度和通用词条整理
总线矩阵设计好之后,下一步则是去拆解每个业务过程的分析指标,包括原子指标、复合指标和派生指标。在此之前,我们需要对我们的维度做好管理,同时将常用的修饰通用词条进行对应的整理,便于后面三种指标维度的构建。
4.1 维度整合
维度的整合包括原子维度的整合派生维度的整合,维度的整合是为了指标数仓进行维度表的构建

4.2 通用词条整合
通用词条类型有四种,分别为时间周期、修饰词、行为、量度
①时间周期:用来明确数据统计的时间范用或者时间点,如本讲、当前学期、当日、累计等
②修饰词:指除了统计维度以外指标的业务场景限定抽象,如正价课、学科老用户、网校新用户等
③行为:用户完成的一个动作,如支付、回放等,在网校业务场景下,有一些状态类的描述也被归属到行为中,如在班、在线等
④量度:即某一行为的单位,比如人数、人次
5、指标拆解
指标的拆解包括三个模块:原子维度、派生维度和复合维度
指标的拆解详细程度关系着数仓事实表的构建和分层抽离的合理性,针对每个指标的构建需要有一定的业务依赖,并且需描述清楚对应指标的业务口径和常见的统计方法,因为其关系着数仓在对每个事实的更新频率的设计(我们不可能让每个表都做到实时更新,也不可能都T+1更新),因此我们需要提供者提供者这样的信息,保证后期数据表的可用性
5.1原子指标拆解:
原子指标的拆解是基于业务动作下进行直接拆解,不需要和任何维度和通用词条进行挂钩
对应对原子指标的管理内容包括:行为、量度、中文名称,英文code,所属数据域及业务过程、指标分级、指标口径描述等
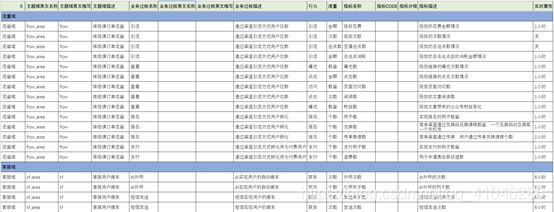
5.2派生指标拆解
派生指标的拆解是基于原子指标的基础上,结合分析维度或通用词条进行衍生构建
对应对派生指标的管理内容包括:原子指标、时间周期、其他修饰词、中文名称,英文code,所属数据域及业务过程、指标分级等。其中,英文code=原子指标+时间周期+其它修饰词,中文名=时间周期+[其它修饰词]+原子指标

5.3复合指标拆解
复合指标则是基于派生指标的四则运算构建
对应对复合指标的管理内容包括:表达式、中文名称,英文code,所属数据域及业务过程、指标分级等

基于上述的全部过程,在数据产品侧能够为数据研发侧提供维度建模所依赖的维度信息和业务动作事实信息,能够很好的帮助其开展维度表和事实表的构建
五、数据字典、元数据管理和数据门户的搭建
数仓建设过程中会形成很多产出物,对应底层构建的这些数据表都会形成我们的数据资产,供后续的一系类数据应用使用,因此我们需要对其进行标准化的管理,便于后期的持续迭代和扩展
1、数据字典
数仓在实际进行表开发的过程中会进行模型的概念设计,也就是通过建模工具进行表设计(比如:powerdesigner),对应建模工具可以导出对应的数据字典,这个能够极大的方便我们后面对表的使用,追踪表的数据血缘。在实际开发之后,比如用阿里云的Dataworks,也是可以对应查看对应表的血缘关系和对应数据地图,可以说这个就是提升生成力的生产工具了

2、元数据管理
数仓建设是一个持续迭代的过程,我们的数据生产会持续进行中,为标准化所的数据,包括指标、维度和通用词条等的管理,有对应的元数据管理平台是最好的,可以看到现在比较成熟的公司都会搭建自己的元数据管理平台,希望这一块在后面也能够搭建起来
3、数据门户
做了那么多的底层搭建,最终都是为了服务于上层的应用,而数据门户是一个公司数据方面的门面,能够洞察公司整体业务情况和走向,进行数据预警。通过数仓的搭建,能够归口公司统一的数据口径,展现精确的数据洞察看板,希望这一块在后面也能够搭建起来
最后,整个数仓的搭建过程其实都是可以参照的,我们的数仓搭建过程也是参照学而思的作法开展。但我觉得更为重要的是深入了解业务,才能知晓我们应该构建那些维表和事实表,如何做到真正的“高内聚低耦合”。同时在做数仓其实还有很多需要前瞻性和扩展性的东西需要考虑,可能在这方面自己的经验还很薄弱,比如如何将我们的离线数仓实现和实时数仓的连接,整个数仓底层所依赖的框架和技术选型等,在这方面自己的认知还是比较浅的,希望后面能够慢慢学习补上
附:相关文章的参照
1、 学而思网校数据指标体系建设https://mp.weixin.qq.com/s/_forqu4Xc0nOyegGocabmg
2、 阿里巴巴数据整合及管理提下https://zhuanlan.zhihu.com/p/149074940
3、 滴滴数据仓库建设:https://mp.weixin.qq.com/s/-pLpLD_HMiasyyRxo5oTRQ
4、 滴滴实时数仓建设:https://mp.weixin.qq.com/s__biz=MzU1ODEzNjI2NA==&mid=2247500113&idx=1&sn=07b76ddf6670dd7f10e3a2c8faa5caa2&chksm=fc29aff6cb5e26e08bdf58095918ec98e8e29f21fce772086ef394e08caecf8305eca3d36ed0&scene=21#wechat_redirect