最最最详细的C语言教程笔记零起步(4)小白必备 同笔者一起学习
C语言教程笔记
- 九. printf 函数
-
- 1. printf函数使用公式
-
- 1.1 printf是一个变参函数
- 1.2 第一个参数必须字符串
- 1.3 第一个参数包含需要输出的字符以及需要被替换的占位符
- 1.4 第二及后续参数将依次替换占位符
- 1.5 占位符的类型和数量需要与后续的参数类型和数量对应
- 2. 整型类型的占位符
-
- 2.1 有符号整型的类型提升
- 2.2 无符号整型的类型提升
- 2.3 浮点类型的类型提升
- 3. 转换规范
-
- 3.1 转换规范总览
- 3.2 转换操作
- 4. 长度指示符
- 5. 精度
- 6. 最小字段宽度
- 7. 标志
- 十. printf 函数深入讨论
-
- 1. printf 将二进制转换成字符串
-
- 1.1 aNum进入printf 后的转换情况
- 1.2 aBiggerNum进入printf后的转换情况
- 1.3 请使用对应的转换规范
- 2. printf 取用参数的问题
-
- 2.1 长度造成的转换规范与参数不匹配
- 2.2 长度指示符增加或缩短数据长度
- 2.3 缩短时先获取再丢弃
九. printf 函数
1. printf函数使用公式
printf(“XXX占位1 XXX占位2 XXX占位3”,替换1,替换2,替换3);
示例代码:
#include 
printf 的用法:
- printf 是一个变参函数。(参数的数量和类型不确定)
- printf 的第一个参数是字符串。
- printf 的第一个参数是需要输出的字符以及需要被替换的占位符。
- printf 的第二及后续参数将依次替换占位符。
- 占位符的类型和数量需要与后续的参数类型和数量对应。
1.1 printf是一个变参函数
它的参数个数是不确定的,同时参数类型也是不确定的。
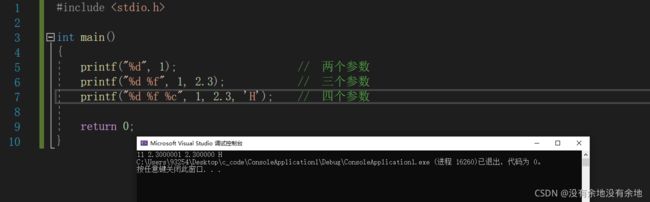
printf("%d", 1); // 两个参数
printf("%d %f", 1, 2.3); // 三个参数
printf("%d %f %c", 1, 2.3, 'H'); // 四个参数
1.2 第一个参数必须字符串
printf("整型a为%d 浮点b为%f 符号c为%c 字符c对应的ASCLL码为%d", a,b,c,d,c);
1.3 第一个参数包含需要输出的字符以及需要被替换的占位符
printf("整型a为%d 浮点b为%f 符号c为%c 字符c对应的ASCLL码为%d", a,b,c,d,c);
这个字符串包含了需要输出的字符,以及需要被替换的占位符。
1.4 第二及后续参数将依次替换占位符
printf("整型a为%d 浮点b为%f 符号c为%c 字符c对应的ASCLL码为%d", a,b,c,d,c);
1.5 占位符的类型和数量需要与后续的参数类型和数量对应
printf("整型a为%d 浮点b为%f 符号c为%c 字符c对应的ASCLL码为%d", a,b,c,d,c);
%d 整型int的占位
%f 浮点double的占位
%c 字符char的占位
2. 整型类型的占位符
在前面的 printf 函数的使用当中, %d 作为整型 int 类型的占位符。对于其他的整型类型, 它们的占位符分别都是什么呢?
printf 是一个可变参数函数,在C语言中将参数传入函数的可变参数中,变量会发生自动类型提升。
2.1 有符号整型的类型提升
对于有符号位的整型 char , short ,传入 printf 的可变参数时,会被提升为 int 。而比 int 更高级的 整型则不发生变化。
| 整数类型 | 类型提升 |
|---|---|
| char | int |
| short | int |
| int | int |
| long | long |
| long long | long long |
所以,在处理 char , short , int 时,均可使用 %d 来占位。
而在Visual Studio 2019中 int 与 long 的范围一致,按理来说也可以使用 %d 来占位。 但是为了程序的可移植性,在切换到别的平台下时, int 和 long 有可能不一致。 所以,请使用 %ld 来为 long 占位。更高级的 long long 则需要使用 %lld 来占位。
结论:
char,shor,int使用 %d
long使用 %ld
long long使用 %lld
| 整数类型 | 符号位 |
|---|---|
| char,shor,int | %d |
| long | %ld |
| long long | %lld |
2.2 无符号整型的类型提升
| 无符号整数类型 | 类型提升 |
|---|---|
| unsigned char | unsigned int |
| unsigned short | unsigned int |
| unsigned int | unsigned int |
| unsigned long | unsigned long |
| unsigned long long | unsigned long long |
对于无符号整型,需要将 d 替换成 u 表明最高位不被看做符号位,而是数值位。
忘了符号位和数值位点这里( 3. 三位二进制表示的数值范围 )
结论:
unsigned char
unsigned short
unsigned int使用 %u
unsigned long使用 %lu
unsigned long long使用 %llu
| 整数类型 | 数值位 |
|---|---|
| unsignedchar,unsigned shor,unsigned int | %u |
| unsigned long | %lu |
| unsigned long long | %llu |
2.3 浮点类型的类型提升
float 会被提升为 double , double 不发生变化。
结论: float,double均使用 %f 。
| 浮点类型 | 数据位 |
|---|---|
| unsignedchar,unsigned shor,unsigned int | %u |
3. 转换规范
为了易于理解,前面称以 % 开始的一串字符 为 占位符 。这是一个为了让大家理解的说法,其实这个说法并不准确。
更准确地说,它们应该被称为转换规范。
3.1 转换规范总览
转换规范以%百分号开始,依次具有下面这些元素:
- 零个或多个标志字符(-,+,0,#)。
- 一个可选的十进制整数常量表示的最小字段宽度。
- 一个可选的用点号表示的精度范围,它的后面可以跟一个十进制整数。
- 一个可选的长度指示符,可以用下列字母组合之一来表示:h、hh、l、LL,z。
- 由单个字符表示的转换操作,取自下面这个集合:c、d、e、E、f、i、o、s、u、x、X。
在这里插入图片描述
3.2 转换操作
转换操作由单个字符表示,取自下面这个集合: c、d、e、E、f、i、o、s、u、x、X 。 printf可以根据 转换操作 使用不同的 转换方式 ,取 n字节的二进制数据 并转换成字符。
| 转换操作 | 二进制字节长度n | 转换方式 |
|---|---|---|
| c | sizeof(int) | 数值对应的ASCII字符 |
| d | sizeof(int) | 有符号十进制整型 |
| e | sizeof(double) | 双精度浮点型,e计数法表示 |
| E | sizeof(double) | 双精度浮点型,e计数法表示 |
| f | sizeof(double) | 双精度浮点型,十进制浮点数 |
| i | sizeof(int) | 与d相同 |
| o | sizeof(unsigned int) | 无符号八进制整型 |
| s | sizeof(char *) | 字符串 |
| u | sizeof(unsigned int) | 无符号十进制整型 |
| x | sizeof(unsigned int) | 无符号十六进制整型 |
| X | sizeof(unsigned int) | 无符号十六进制整型 |
4. 长度指示符
#include 
sizeof(long long)却比sizeof(int)长得多,所以变量 ll 被错误输出
要正常输出long long数据类型,我们必须加宽转换操作获取的二进制数据长度。也就是我们即将讨论的 长度指示符。

| 长度指示符 | 转换操作 | 二进制字节长度n |
|---|---|---|
| l | d或i | sizeof(long) |
| ll | d或i | sizeof(long long) |
| l | sizeof(u或o或x或X) | sizeof(unsigned long) |
| ll | sizeof(u或o或x或X) | sizeof(unsigned long long) |
| h | sizeof( d或i) | sizeof(short) |
| hh | sizeof( d或i) | sizeof(char) |
| h | sizeof(u或o或x或X) | sizeof(unsigned short) |
| hh | sizeof(u或o或x或X) | sizeof(unsigned char) |
#include 
#include 
5. 精度
转换操作可以制定一个可选的精度范围,用一个点号以及它后面一个可选的十进制正数表示。 精度范围用于控制:
- d、i、o、u、x、X所打印的最小数字位数,不足将补齐。
- e,E,和 f 转换中小数点右边的数字位数。
#include 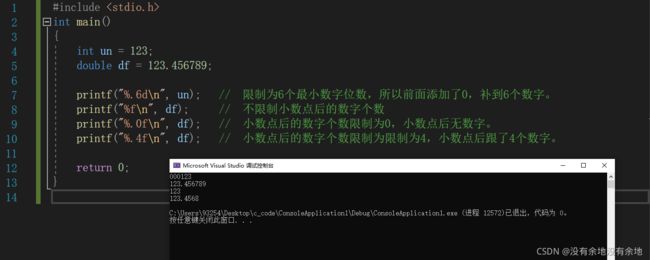
精度作用于转换操作d时,限制输出的最小数字位数,123仅有3位,因此补0到6位。 精度用于转换操作f时,限制小数点右边的数字位数。 123.456789,当使用.0精度时,小数点后不输出数字。 使用.4精度时,小数点后输出4个数字。
6. 最小字段宽度
最小字
#include 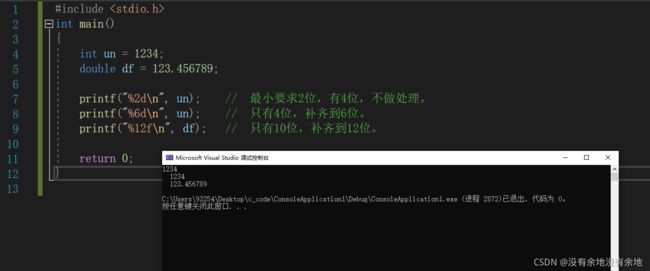
7. 标志
标志 0 使用0而不是空格作为填充字符
当我们使用了最小字段宽度时,如果字符不足最小宽度,那么将会用空格补齐到最小宽度。如果指定 了 0 作为标志,则会用字符0,来补齐到最小宽度。
#include 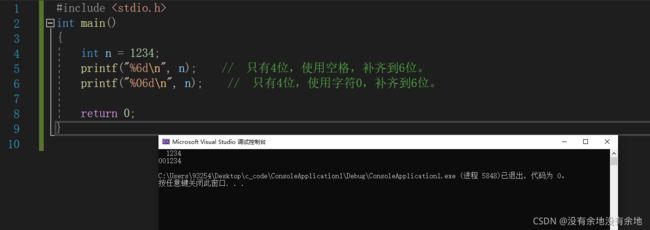
标志 - 打印的字符左对齐
#include 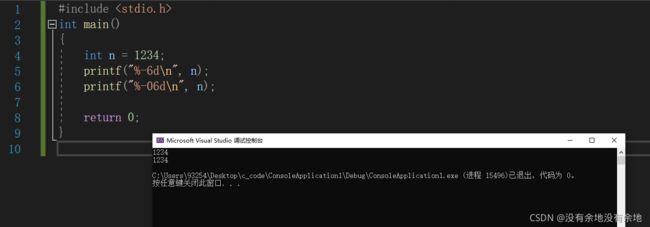
标志 + 总是产生符号,+ (正数) 或 - (负数)
#include 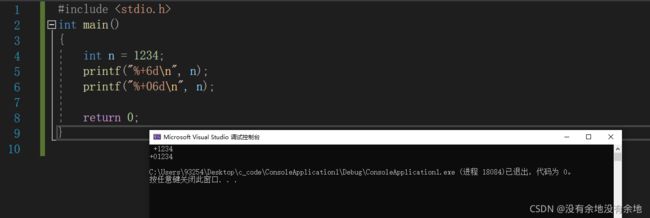
标志 # 八进制前加0,十六进制前加0x。
#include 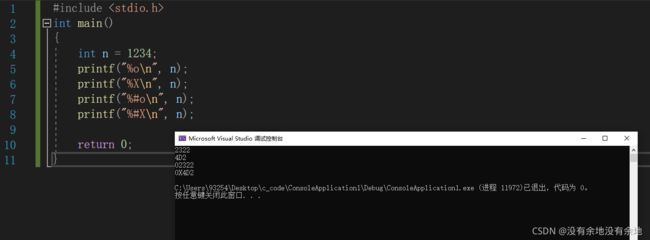
十. printf 函数深入讨论
1. printf 将二进制转换成字符串
printf函数从参数中获取二进制数据,并将它根据转换规范转换成字符串,并打印在控制台上。 运行以下代码,并根据其结果,分析其中原理,从而理解为什么将 以% 开始的一串字符称作转换规范?
#include 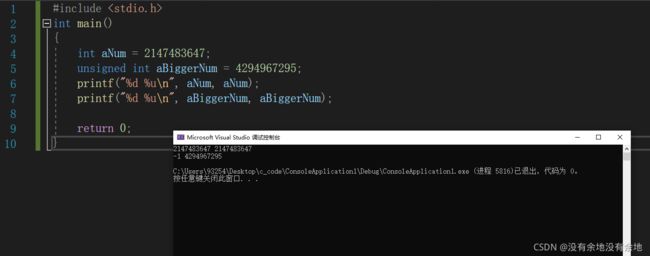
在上面的代码中,整型 int 变量 aNum ,数值为 2147483647 ,使用 %d 或 %u 均能输出正确的结果。
但是无符号整型 unsigned int ,数值为 4294967295 ,使用 %d 无法正确输出结果, %u 却可以正确输出结果。
下面通过它们的二进制表示来分析问题出现的原因,在这之前先回忆一个知识点。
整型在计算机中的存储为补码表示法。设一个十进制数为 n ,模为 mod 。若 n 为正数, n 的补码为 n 的二进制。若 n 为负数,设 dec = mod - |n| , n 的补码为 dec 的二进制。
1.1 aNum进入printf 后的转换情况


在aNum进入printf函数后,由于aNum的类型为int,所以类型并不会发生转换,仍然为4个字节。
当我们 使用 %u 来做转换规范时,printf会获取4字节的数据,并认为其为无符号整数。 它没有符号位, 因此肯定为一个正数的补码。可以直接将它转换为十进制,转换结果为字符串"2147483647"。
当我们 使用 %d 来做转换规范时,printf会获取4字节的数据,并认为其为有符号整数。 最高位看做符号位,其余为数据位。而在这个二进制中最高位为0,因此它是一个正数的补码,可以直接将它转换为十 进制,转换结果为字符串"2147483647"。
在这种情况下,使用 %u 或 %d 均可以得到正确的转换结果。
由于, 以%开始的一串字符 指示printf函数如何转换二进制数据,所以将其称为转换规则更为准确。
图片来源:你好编程
1.2 aBiggerNum进入printf后的转换情况

图片来源:你好编程
在aBiggerNum进入printf函数后,由于aBiggerNum的类型为unsigned int,所以类型并不会发生转换, 仍然为4个字节。
当我们使用 %u 来做转换规范时,printf会获取4字节的数据,并认为其为无符号整数。 它没有符号位, 因此肯定为一个正数的补码。可以直接将它转换为十进制,转换结果为4294967295。
当我们使用 %d 来做转换规范时,printf会获取4字节的数据,并认为其为有符号整数。 最高位看做符号位,其余为数据位。
而在这个二进制中最高位为1,因此它是某一个负数的补码,我们设这个负数为n。
回忆一下补码的计算规则:若 n 为负数,设 dec = mod - |n| , n 的补码为 dec 的二进制。
n 的补码为 11111111 11111111 11111111 11111111 ,则dec为4294967295。
四个字节的二进制可以表示2的32次方个数值,模mod为2的32次方4294967296。
mod - |n| = dec,则4294967296 - |n| = 4294967295。n为-1。
1.3 请使用对应的转换规范
2. printf 取用参数的问题
2.1 长度造成的转换规范与参数不匹配
#include 在第一个printf函数中,变量 l 被正确打印了。 而在第二个printf函数中,第一个 %u 获取并打印了 ll 的4个字节,第二个 %u 获取并打印了ll的另外4个字节。
unsigned long 和 unsigned long long 均为比 unsigned int 高级的类型,因此它们进入printf函数的时候仍然保持有类型。但是转换规范 %u 或 %d ,它们仅仅取了int或unsigned int类型的大小,也就是4个 字节进行转换。
2.2 长度指示符增加或缩短数据长度
#include 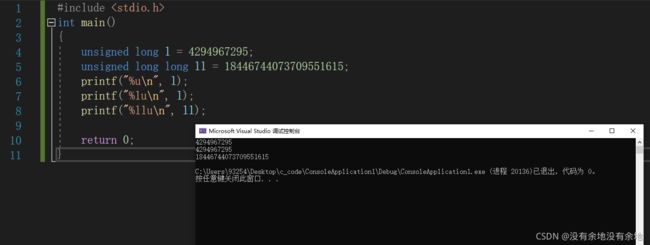
| 转换规则 | 转换数据字节长度 |
|---|---|
| u | sizeof(unsigned int) |
| d | sizeof(int) |
| lu | size(unsigned long) |
| ld | sizeof(long) |
| llu | sizeof(unsigned long long) |
| lld | sizeof(long long) |
与上面的相反,长度指示符 h hh ,可以缩短转换数据字节长度。
| 转换规则 | 转换数据字节长度 |
|---|---|
| u | sizeof(unsigned int) |
| d | sizeof(int) |
| hu | size(unsigned short) |
| hd | sizeof(short) |
| hhu | sizeof(unsigned char) |
| hhd | sizeof(char) |
#include 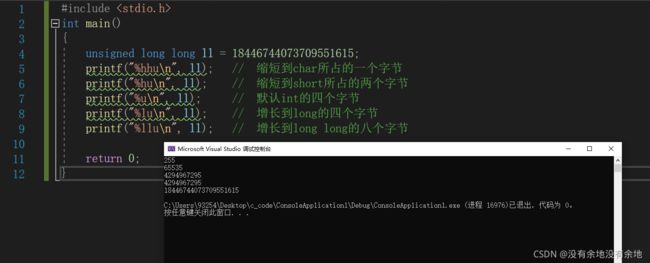
2.3 缩短时先获取再丢弃
值得注意的是,长度指示符 h hh 是通过先获取原有长度的数据,再丢弃一部分数据。从而达到缩短转换数据长度的。
#include 
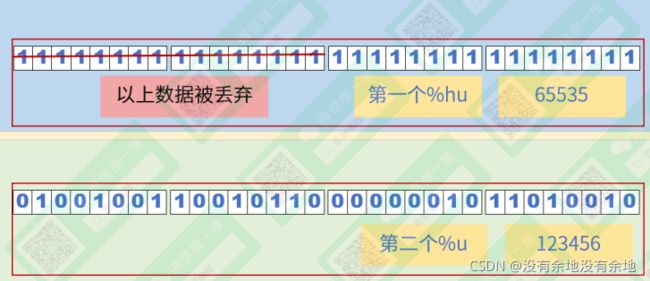
图片来源:你好编程
第一个 %hu ,根据 u 获得了n1的4个字节,而 h 导致其丢弃了已经获取的2字节。第二个 %u 正常获得了 n2的4个字节。
点个赞呗❤