PySpark线性回归与广义线性模型
PySpark线性回归与广义线性模型
-
-
- 1.线性回归
- 2.岭回归(Ridge Regression)与LASSO回归(LASSO Regression)
- 3.广义线性模型 (GLM)
-
本文为销量预测第7篇:线性回归与广义线性模型
第1篇:PySpark与DataFrame简介
第2篇:PySpark时间序列数据统计描述,分布特性与内部特性
第3篇:缺失值填充与异常值处理
第4篇:时间序列特征工程
第5篇:特征选择
第6篇:简单预测模型
第8篇:机器学习调参方法
第9篇:销量预测建模中常用的损失函数与模型评估指标
本节从原理和代码上讲解销量预测任务中使用到的Spark.ML内置线性回归模型和广义线性模型。
1.线性回归
回归分析是预测建模中最为基础的技术,通过拟合回归线(regression line)建立输入变量与目标变量之间的线性关系,构建损失函数,求解损失函数最小时的参数w和b。表达式如下:
y ^ = w x + b 其 中 , y 是 因 变 量 , x 是 自 变 量 , w 是 斜 率 , b 为 截 距 ; \hat{y}=w x+b\\ 其中,y是因变量,\ x是自变量, \ w是斜率, \ b为截距; y^=wx+b其中,y是因变量, x是自变量, w是斜率, b为截距;
损失函数为:
L ( w , b ) = 1 n ∑ i = 1 n ( w x i + b − y i ) 2 L(w, b)=\frac{1}{n} \sum_{i=1}^{n}\left(w x_{i}+b-y_{i}\right)^{2} L(w,b)=n1i=1∑n(wxi+b−yi)2
利用梯度下降(gradient descent)迭代更新(针对w和b求偏导)。
W ← W − α ∂ J ( W ) ∂ W b ← b − α ∂ L ∂ b W \leftarrow W-\alpha \frac{\partial J(W)}{\partial W} \\ b \leftarrow b-\alpha \frac{\partial L}{\partial b} W←W−α∂W∂J(W)b←b−α∂b∂L
线性回归模型计算效率高,可解释强,具有完备的数量统计理论支撑等优点,作为基础模型广泛使用在回归建模任务中,但也存在针对非正态分布的数据,线性表达能力较弱,若多个自变量间存在共线性,求解的模型参数不稳定,导致预测能力下降等问题,故有下文提到的Ridge Regression、LASSO Regression以及广义线性回归来解决或补充。
2.岭回归(Ridge Regression)与LASSO回归(LASSO Regression)
当使用最小二乘法计算线性回归模型参数时,如果数据特征之间存在多重共线性,那么最小二乘法对输入变量中的噪声非常敏感,其解会变得极为不稳定。为了解决这个问题,就有了岭回归(Ridge Regression )。
岭回归(Ridge Regression)是在一般线性回归的基础上加入L2正则项,通过限制参数权重(回归)系数,使weight不会变得特别大,则模型对输入特征中的噪声敏感度就会降低,故在保证最佳拟合误差的同时,参数尽可能的“简单”,模型的泛化能力得以增强,岭回归公式如下:
J ( θ ) = 1 m ∑ i = 1 m ( y ( i ) − ( w x ( i ) + b ) ) 2 + λ ∥ w ∥ 2 2 = M S E ( θ ) + λ ∑ i = 1 n θ i 2 J(\theta)=\frac{1}{m} \sum_{i=1}^{m}\left(y^{(i)}-\left(w x^{(i)}+b\right)\right)^{2}+\lambda\|w\|_{2}^{2}\\ =M S E(\theta)+\lambda \sum_{i=1}^{n} \theta_{i}^{2} J(θ)=m1i=1∑m(y(i)−(wx(i)+b))2+λ∥w∥22=MSE(θ)+λi=1∑nθi2
迭代优化函数如下
θ j : = θ j − α ∑ i = 1 m ( h θ ( x ( i ) ) − y ( i ) ) x j ( i ) − 2 λ θ j \theta_{j}:=\theta_{j}-\alpha \sum_{i=1}^{m}\left(h_{\theta}\left(x^{(i)}\right)-y^{(i)}\right) x_{j}^{(i)}-2 \lambda \theta_{j} θj:=θj−αi=1∑m(hθ(x(i))−y(i))xj(i)−2λθj
LASSO(Least absolute shrinkage and selection operator, Tibshirani(1996))方法是一种压缩估计。其基本思想是在构建L1正则化,在回归系数的绝对值之和小于一个常数的约束条件下,使残差平方和最小化,将一些作用较小的特征的权重系数置为0,从而获得稀疏解,实现了降维(特征筛选)的同时解决多重共线性的问题。
LASSO的代价函数为:
J ( θ ) = 1 2 m ∑ i = 1 m ( y ( i ) − ( w x ( i ) + b ) ) 2 + λ ∥ w ∥ 1 = 1 2 M S E ( θ ) + λ ∑ i = 1 n ∣ θ i ∣ J(\theta)=\frac{1}{2 m} \sum_{i=1}^{m}\left(y^{(i)}-\left(w x^{(i)}+b\right)\right)^{2}+\lambda\|w\|_{1} \\ = \frac{1}{2} M S E(\theta)+\lambda \sum_{i=1}^{n}\left|\theta_{i}\right| \quad J(θ)=2m1i=1∑m(y(i)−(wx(i)+b))2+λ∥w∥1=21MSE(θ)+λi=1∑n∣θi∣
示例代码
import sys
import datetime
from pyspark.sql import SparkSession
from pyspark.ml.regression import LinearRegression
from pyspark.ml.evaluation import RegressionEvaluator
from pyspark.ml.feature import VectorAssembler
from pyspark.ml.feature import Normalizer
from pyspark.sql.functions import *
from pyspark.sql.types import *
from pyspark.ml.feature import StringIndexer
from pyspark.ml.feature import OneHotEncoder
import warnings
warnings.simplefilter(action='ignore', category=FutureWarning)
warnings.filterwarnings('ignore')
spark = SparkSession. \
Builder(). \
config("spark.sql.crossJoin.enabled", "true"). \
config("spark.sql.execution.arrow.enabled", "false"). \
enableHiveSupport(). \
getOrCreate()
class linear_predict(object):
def __init__(self,data,importance_feature,reg, inter, elastic):
self.data=data
self.importance_feature=importance_feature
self.reg=reg
self.inter=inter
self.elastic=elastic
def prediction(self):
reg, inter, elastic=self.reg,self.inter,self.elastic
df=self.data
inputCols = self.importance_feature
df = df.na.fill(0)
df = df.withColumn('dayofweek', dayofweek('dt'))
df = df.withColumn("dayofweek", df["dayofweek"].cast(StringType()))
dayofweek_ind = StringIndexer(inputCol='dayofweek', outputCol='dayofweek_index')
dayofweek_ind_model = dayofweek_ind.fit(df)
dayofweek_ind_ = dayofweek_ind_model.transform(df)
onehotencoder = OneHotEncoder(inputCol='dayofweek_index', outputCol='dayofweek_Vec')
df = onehotencoder.transform(dayofweek_ind_)
feature_vector = VectorAssembler(inputCols=inputCols, outputCol="features")
output = feature_vector.transform(df)
features_label = output.select("shop_number", "item_number", "dt", "features", "label")
train_set =features_label.where(features_label['dt'] <='2020-08-28')
train_data, val_data = train_set.randomSplit([0.8, 0.2])
pred_data=features_label.where(features_label['dt']>'2020-08-28').where(features_label['dt']<'2020-09-01')
lr = LinearRegression(regParam=reg, fitIntercept=inter, elasticNetParam=elastic,
solver="normal")
model = lr.fit(train_data)
print('{}{}'.format('model_intercept:', model.intercept))
print('{}{}'.format('model_coeff:', model.coefficients))
feature_map=dict(zip(inputCols, model.coefficients))
print("feature_map",feature_map)
#model prediction
predictions = model.transform(pred_data)
predictions.select("shop_number", "item_number", "dt","prediction").createOrReplaceTempView('linear_predict_out')
insert_sql="""insert overwrite table scm.linear_regression_prediction partition (dt='{dt}')
select
store_code,
goods_code,
dt,
prediction
from
linear_predict_out"""
spark.sql(insert_sql)
spark.stop()
def read_importance_feature():
"""
:return: list of importance of feature
"""
importance_feature = spark.sql("""select feature from app.selection_result_v1 where cum_sum<0.95 and update_date
in (select max(update_date) as update_date from app.selection_result_v1)""").select("feature").collect()
importance_list = [row.feature for row in importance_feature]
print('..use'+str(len(importance_list))+'numbers of feature...')
return importance_list
def main():
data=spark.sql("""select * from app.dataset_input_df_v2 where dt>='2020-08-04'""")
importance_feature=read_importance_feature()
reg, inter, elastic = 0.5,False,1.0
linear_predict(data, importance_feature, reg, inter, elastic).prediction()
if __name__ == '__main__':
main()
其中LinearRegression的主要参数含义如下:
- *regParam:正则化参数。用于防止过拟合
- elasticNetParam:取值范围[0,1]。取 0时,采用L2。取 1时,采用L1正则化。
- fitIntercept:是否拟合截距项 True(默认)/False
- standardization:模型拟合前是否对训练特征进行标准化处理
- solver:求解算法的优化。支持的选项:auto, normal, l-bfgs
- aggregationDepth:树栅建议深度(>= 2)
- loss:模型待优化的损失函数。选项有:squaredError, huber。
- epsilon:对形状参数进行鲁棒性控制。必须是> 1.0。只有在损失函数是huber时才有效
弹性网络(Elastic Net),是在岭回归和Lasso回归中进行了折中,elasticNetParam=0时为Ridge Regression,elasticNetParam=1时为LASSO Regression。
L = min ( M S E + λ ( 1 − α α ∥ ω ∥ 2 + α ∥ ω ∥ ) ) = min w 1 2 n ∑ i = 1 n ( X i w − y i ) 2 + λ [ 1 − α 2 ∥ w ∥ 2 2 + α ∥ w ∥ 1 ] L=\min \left(M S E+\lambda\left(\frac{1-\alpha}{\alpha}\|\omega\|^{2}+\alpha\|\omega\|\right)\right)\\=\min _{w} \frac{1}{2 n} \sum_{i=1}^{n}\left(X_{i} w-y_{i}\right)^{2}+\lambda\left[\frac{1-\alpha}{2}\|w\|_{2}^{2}+\alpha\|w\|_{1}\right] L=min(MSE+λ(α1−α∥ω∥2+α∥ω∥))=wmin2n1i=1∑n(Xiw−yi)2+λ[21−α∥w∥22+α∥w∥1]
另外,也可以按照前文所阐述的多项式特征生成方法,放入多项式特征,从而构建多项式回归。
3.广义线性模型 (GLM)
广义线性模型,是为了克服线性回归模型缺点而出现,是对一般线性模型的扩展。首先自变量可以是离散的,也可以是连续的。离散的可以是0-1变量,也可以是多种取值的计数变量。与线性回归模型相比较,主要有以下推广:
(1)随机误差项不一定服从正态分布,可以服从二项、泊松、负二项、正态、伽马、逆高斯等指数分布族。
(2)引入联接函数。因变量和自变量通过联接函数产生影响,联接函数满足单调可导。
链接函数描述了线性预测 X β Xβ Xβ与分布期望值 E [ Y ] E[Y] E[Y]的关系: E [ Y ] = μ = g − 1 ( X β ) E[Y]=\mu=g^{-1}(X \beta) E[Y]=μ=g−1(Xβ),其中 g g g表示链接函数, μ μ μ表示均值函数。 一般情况下,高斯分布对应于恒等式,泊松分布对应于自然对数函数等。常用的联接函数有:
Y = X ∗ β Y = l n ( X ∗ β ) Y = ( X ∗ β ) l n ( Y / ( 1 − Y ) ) = X ∗ β \\ Y= X*β\\ Y=ln(X*β)\\ Y= \sqrt{(X*β)}\\ ln(Y/(1-Y))=X*β \\ Y=X∗βY=ln(X∗β)Y=(X∗β)ln(Y/(1−Y))=X∗β
针对广义线性回归在销量预测上应用,本节以泊松回归为实例进行介绍,泊松(Poisson)回归是广义线性模型中常用的一种,因变量服从Poisson分布。
在很多情况下销量数据经常计数的形式出现,如每天进店客流,或部分商品销售量会有 0, 1, 2…等计数的形式出现。如果计数值很大,销售数量分布于连续的样本空间 [100,∞),则[100,∞)与离散样本空间 {100,101,102,…}之间的差异对预测没有显著的影响,如销售数据以较小的计数值 (0,1,2,…)出现,那么就需要使用更适合非负整数的预测方法,也就是泊松回归。
在正式使用泊松回归之前,先解决一个疑问,那就是针对非正态的数据通过取对数处理把y值转成正态或者接近正态以后放入模型是否是合理的处理方式呢?而这种方法也是大多数人常用的解决办法,这里特意阐述一下取对数的弊端。
针对数据分布呈现偏态的问题,通常也有直接转对数处理,但是这种做法可能并不合理,因为在使用对数线性模型的时,隐含的一个假设就是y服从正态分布。虽然取对数能够缓解因 y y y的波动性大带来的异方差和极端值影响。针对销量数据, y y y显然只能取非负数。但销量为0或者1是经常出现的,而如果想要取对数,必须保证y>0且不等于1才有意义。当然,也可以对 y y y取对数之前加上一个值,使 y y y都大于0,比如所以的销售量加2,但是这样会导致估计量的不一致性(Santos Silva,J. M. C and S. Tenreyro ( 2006 )),并且如果0值多,那么因变量 y y y微小的调整就会导致模型估计系数波动,也降低了模型的解释力。
如图所示,销量分布呈现,右偏。如下图。
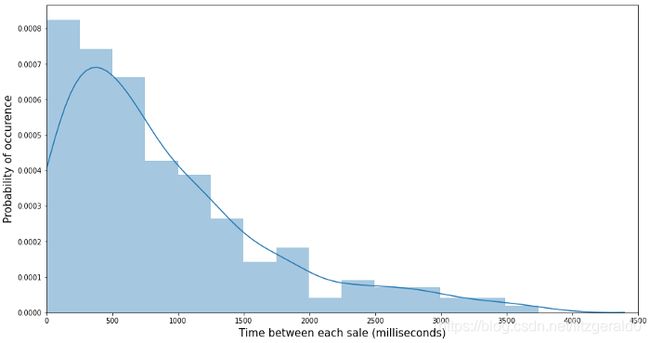
spark.ml中的广义线性回归,通过以下方式调用,其他主体部分和以上线性回归代码相同。
from pyspark.ml.regression import GeneralizedLinearRegression
glr = GeneralizedLinearRegression(family="poisson", link="log", regParam=1.0)
在广义线性回归模型中,其分布于对应的link function可选择如下:
-
gaussian : identity, log, inverse
-
binomial : logit, probit, cloglog
-
poisson : log, identity, sqrt
-
gamma:inverse, identity, log
-
tweedie : 使用tweedie分布时,需指定linkPower参数,默认为1
在销量预测领域还有一个值得关注和尝试的广义线性是tweedie分布,Tweedie分布是一种泊松分布和伽马分布的复合。
以上就是关于线下回归和广义线性回归在预测任务中的实战示例。