0001深度学习初体验-基于Tensorflow and Keras 实现卷积神经网络(CNN)Mnist数据集手写数字识别
LeNet5
- 1.、背景介绍
- 1.问题由来
- 2.环境搭建
- 3.数据特点
- 4.Tensorflow
- 2.、开始搭建
- 附录
- 总结
前言
作为机器学习与深度学习的开篇之作与经典问题-MNIST数据集识别问题由来已久,本文用来记录学习过程与分享,欢迎大家点赞,评论、收藏。
一、LeNet5是什么?
1.背景介绍
1.1问题由来
LeNet5 是 lecun(2018年图灵奖获得者)在1998年搭建的神经网络,2018年3月27日晚,ACM(美国计算机协会)宣布把2018年度图灵奖颁发给深度学习三巨头(Yoshua Bengio、Geoffrey Hinton 和 Yann LeCun),以表彰他们在深度学习神经网络的工作。



图灵奖被认为是计算机领域的“诺贝尔奖”,奖项名字设以纪念世界计算机科学先驱艾伦·图灵(A.M. Turing),于 1966 年设立,获奖者须在计算机领域具有持久而重大的先进性的技术贡献。
 Yoshua Bengio,蒙特利尔大学计算机科学与运筹学系全职教授,也是深度学习“三巨头”中唯一一位完全在学术界工作。他的诸多科研积累,包括深度学习架构、循环神经网络(RNN)、对抗算法、表征学习,影响和启发了后来的大量研究者,将深度学习应用到自然语言处理、计算机视觉等人工智能的各个主要领域,对近年来深度学习的崛起和发展起到了巨大的推动作用。目前,他是仅存的几个仍然全身心投入在学术界的深度学习教授之一,为人工智能培养了许多杰出的下一代人才。
Yoshua Bengio,蒙特利尔大学计算机科学与运筹学系全职教授,也是深度学习“三巨头”中唯一一位完全在学术界工作。他的诸多科研积累,包括深度学习架构、循环神经网络(RNN)、对抗算法、表征学习,影响和启发了后来的大量研究者,将深度学习应用到自然语言处理、计算机视觉等人工智能的各个主要领域,对近年来深度学习的崛起和发展起到了巨大的推动作用。目前,他是仅存的几个仍然全身心投入在学术界的深度学习教授之一,为人工智能培养了许多杰出的下一代人才。

Geoffrey Hinton,谷歌副总裁兼工程研究员,Vector Institute 的首席科学顾问,多伦多大学的名誉大学教授。他在80年代把以前没有受重视的反向传播(BP)算法引入了神经网络,使得复杂神经网络的训练成为可能,直到今天,反向传播算法依然是训练神经网络最重要的算法。之后,他又在1983 年发明玻尔兹曼机(Boltzmann Machines),以及在 2012 年改进了卷积神经网络,并在著名的 ImageNet 评测中取得惊人成绩,在计算机视觉领域掀起一场革命。

Yann LeCun,Facebook人工智能研究院负责人,纽约大学数据科学中心的创始人之一。他最广为人知的工作是CNN(卷积神经网络)。虽然并未直接发明CNN,但Yann LeCun将反向传播算法引入了CNN,并且发明了权值共享、池化等技巧,让CNN真正更为可用。现在,CNN已经广泛用于计算机视觉、语音识别、语音合成、图片合成以及自然语言处理等学术方向,以及自动驾驶、医学图片识别、语音助手、信息过滤等工业应用方向。他在1998年开发了LeNet5——首个被大规模商用的CNN,并制作了MNIST数据集,一个被Hinton称为“机器学习界的果蝇”的经典数据集,也是绝大多数人接触的第一个数据集。更难能可贵的是他坚持了足足有二十年,才迎来了CNN如今的繁荣。
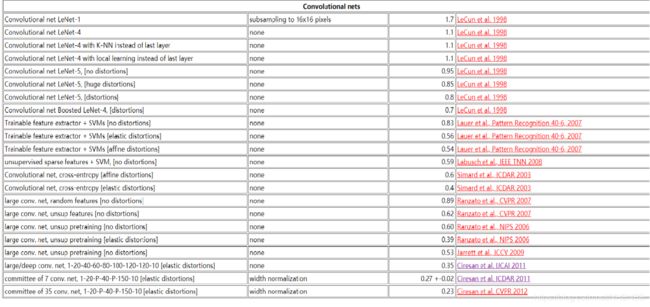
当我们开始学习编程的时候,第一件事往往是学习打印"Hello World"。就好比编程入门有Hello World,机器学习入门有MNIST数据集。 MNIST是一个入门级的计算机视觉数据集,它包含各种手写数字图片。它也包含每一张图片对应的标签,告诉我们这个是数字几。 MNIST问题由Yann LeCun和他的老师Yoshua Bengio提出,并在1998年发表了题为“Gradient-based learning applied to document recognition”(基于梯度的学习在文档识别中的应用),被用于美国银行支票手写体识别。 关键词:卷积神经网络,文档识别,有限状态传感器,基于梯度的学习,图形转换器网络,机器学习,神经网络,光学字符识别(OCR)。
LeCun Y, Bottou L, Bengio Y, et al. Gradient-based learning applied to document recognition[J]. Proceedings of the IEEE, 1998, 86(11): 2278-2324.

大家可以下载查看。
自1998年提出以来到2012年,利用卷积神经网络测试的Mnist数据集的错误率已经降至0.23%。
1.2环境搭建
环境配置:
1.Win 10操作系统
2.GPU RTX3090(哈哈,博主只有GTX 1650Ti)
3.Python 3.7 
4.Keras 
5.Anaconda 
6.Tensorflow 2.0 
1.3数据特征
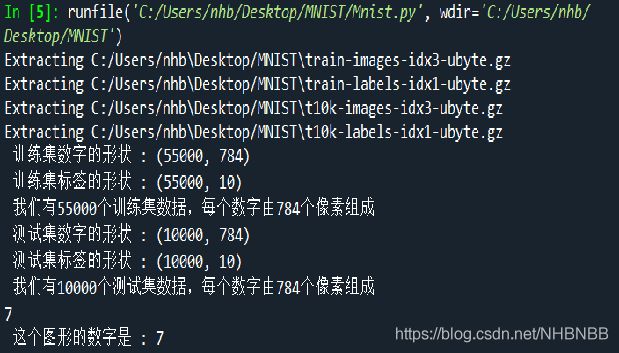
MNIST 数据集来自美国国家标准与技术研究所, Mixed National Institute of Standards and Technology (MNIST). 训练集 (training set) 由来自 250 个不同人手写的数字构成, 其中 50% 是高中学生, 50% 来自人口普查局 (the Census Bureau) 的工作人员. 测试集(test set) 也是同样比例的手写数字数据.
MNIST 数据集主要由一些手写数字的图片和相应的标签组成,图片一共有10 类,分别对应从0~9 ,共10 个阿拉伯数字。它提供了70000张手写数字的灰度图片及其标签。它的图片是被规范处理过的,是一张被放在中间部位的28px*28px的灰度图。像素(px,pixel) 对于每张图片,存储的方式是一个 28 * 28 的矩阵,但是我们在导入数据进行使用的时候会自动展平成 1 * 784(28 * 28)的向量,这在TensorFlow导入很方便。

在使用命令下载数据之后,可以看到有四个数据集:


train-images-idx3-ubyte: training set images 训练集图像
train-labels-idx1-ubyte: training set labels 训练集标签
t10k-images-idx3-ubyte: test set images 测试集图像
t10k-labels-idx1-ubyte: test set labels 测试集标签

上图就是MNIST数据集中的数字7,是不是不像?
数据集被分成两部分:60000 行的训练验证集(mnist.train)和10000行的测试数据集(mnist.test)。这样的切分很重要,在机器学习模型设计时必须有一个单独的测试数据集不用于训练而是用来评估这个模型的性能,从而更加容易把设计的模型推广到其他数据集上(泛化)。 其中:60000 行的训练验证集分拆为 55000 行的训练集和 5000 行的验证集。55000行的训练数据集是一个形状为 [55000, 784] 的张量,第一个维度数字用来索引图片,第二个维度数字用来索引每张图片中的像素点。在此张量(tensor)里的每一个元素,都表示某张图片里的某个像素的强度值,值介于 0 和 1 之间。 60000 行的训练数据集标签是介于 0 到 9 的数字,用来描述给定图片里表示的数字。称为 "one-hot vectors"。一个 one-hot 向量代表的概率除了某一位的数字是 1 以外其余都是 0,使它们的总和为1。
1维 行(列)向量 2维 矩阵 所有维 张量


2.模型搭建
下面将借助于TensorFlow框架,在Mnist数据集的基础上,通过卷积神经网络,进行手写数字识别的仿真测试。
输入层Input Layer:用于将数据输入到神经网络中
卷积层Convolution Layer:使用卷积核提取特征
激励函数Relu :对卷积操作的线性运算进行非线性映射
池化层Pooling Layer:卷积得到的特征图进行稀疏处理,减少数据量
全连接层FullConnected Layer:在网络的末端进行重新拟合,恢复特征,减少特征的损失
输出层Output Layer:输出结果,回归或分类
| Tensorflow 层 |
||
| 输入层Input Layer |
输入 |
(None,784) |
| 输出 |
(None,28*28*1) |
|
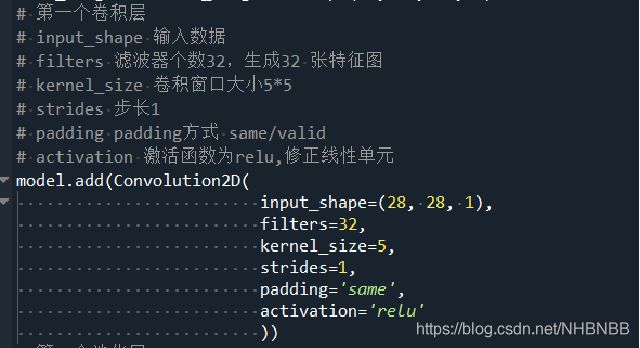
| 卷积层Convolution Layer1 |
输入 |
(None,28*28*1) |
| 卷积核 |
(5*5*1*32) |
|
| 输出 |
(None,28*28*32) |
|
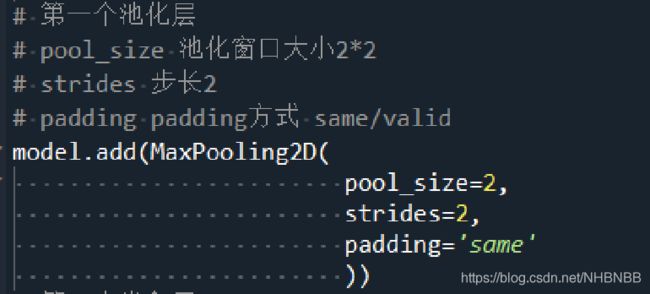
| 池化层Pooling Layer1 |
输入 |
(None,28*28*32) |
| 最大池化 |
(2*2) |
|
| 输出 |
(None,14*14*32) |
|
| 卷积层Convolution Layer2 |
输入 |
(None,14*14*32) |
| 卷积核 |
(5*5*32*64) |
|
| 输出 |
(None,14*14*64) |
|
| 池化层Pooling Layer2 |
输入 |
(None,14*14*64) |
| 最大池化 |
(2*2) |
|
| 输出 |
(None,7*7*64) |
|
| 全连接层FullConnected Layer1 |
输入 |
(None,7*7*64) |
| Dropout |
0.5 |
|
| 输出 |
(None,1024*1) |
|
| 输出预测层Output Layer |
输入 |
(None,1024*1) |
| 输出 |
(None,10*1) |
|

1.第一个卷积Convolution Layer和池化Pooling Layer
2.第二个卷积Convolution Layer和池化Pooling Layer


3.全连接层FullConnected Layer和Dropout

4.全连接层FullConnected Layer和输出预测层


5.训练后的结果保存在mnist.h5 模型中,通过10次迭代,识别准确率也提高到99.25%,超过了绝大多数的人类。测试集的准确率也达到了99.13%,我们也可以自己制作图片来让模型识别。

在mnist_test.py文件夹中,我们测试了自己手写的数字。

左上角的图片是mnist数字集中的 7
右上角的是我们手写的 7
左下角是灰度处理过的 7
右下角为通过翻转为黑底白笔的7

大功告成!!!
附录
一、背景介绍
1.1 卷积神经网络 近年来,深度学习的概念非常火热。深度学习的概念最早由Hinton等人在2006年提出。基于深度置信网络(DBN,Deep Belief Networks),提出非监督贪心逐层训练算法,为解决深层结构相关的优化难题带来希望,随后提出多层自动编码器深层结构。此外Lecun等人提出的卷积神经网络(Convolutional Neural Networks / CNNs / ConvNets)是第一个真正多层结构学习算法,它利用空间相对关系减少参数数目以提高训练性能。Alex在2012年提出的AlexNet网络结构模型引爆了神经网络的应用热潮,并赢得了2012届图像识别大赛的冠军,使得CNN成为在图像分类上的核心算法模型。
1.2 深度学习框架 随着深度学习研究的热潮持续高涨,各种开源深度学习框架也层出不穷,其中包括TensorFlow、Caffe2、Keras、CNTK、Pytorch、MXNet、Leaf、Theano、DeepLearning4等等。Google、Microsoft、Facebook等巨头都参与了这场深度学习框架大战。目前,由Google推出的TensorFlow和Facebook推出的Pytorch、Caffe2较受欢迎。下面将简单介绍这三种框架的特点。
Caffe全称为Convolutional Architecture for Fast Feature Embedding(快速特征嵌入的卷积结构),是一个被广泛使用的开源深度学习框架(在TensorFlow出现之前一直是深度学习领域GitHub star最多的项目)。Caffe的主要优势包括如下几点: 容易上手,网络结构都是以配置文件形式定义,不需要用代码设计网络。 训练速度快,能够训练state-of-the-art的模型与大规模的数据。 组件模块化,可以方便地拓展到新的模型和学习任务上。 Caffe的核心概念是Layer,每一个神经网络的模块都是一个Layer。Layer接收输入数据,同时经过内部计算产生输出数据。设计网络结构时,只需要把各个Layer拼接在一起构成完整的网络。Caffe2是caffe的升级版,在各方面均有一定提升。


Caffe,贾扬清在加州大学伯克利分校攻读博士期间创建了Caffe项目。项目托管于GitHub,拥有众多贡献者。 2017年4月,Facebook发布Caffe2,加入了递归神经网络等新功能。2018年3月底,Caffe2并入PyTorch。 2013年毕业后,他加入谷歌,是谷歌大脑 TensorFlow 的作者之一。 2016年2月加盟Facebook,并开发出Caffe2Go、Caffe2、PyTorch等深度学习框架。 2019 年 3 月正式加入阿里巴巴,担任阿里巴巴集团副总裁、阿里云智能计算平台事业部总裁,内部称为“阿里计算平台掌门人”。
2017 年初,Facebook 在机器学习和科学计算工具 Torch 的基础上,针对 Python 语言发布了一个全新的机器学习工具包 PyTorch。一经发布,这款开源工具包就受到了业界的广泛关注和讨论,经过几年的发展,目前 PyTorch 已经成为从业者最重要的研发工具之一。其最大的特点是支持动态图的创建。其他主流框架都是采用静态图创建,静态图定义的缺陷是在处理数据前必须定义好完整的一套模型,能够处理所有的边际情况。比如在声明模型前必须知道整个数据中句子的最大长度。相反动态图模型能够非常自由的定义模型。同时,PyTorch继承了Torch,支持Python,支持更加便捷的Debug,所以非常受欢迎。()


TensorFlow是相对高阶的机器学习库,用户可以方便地用它设计神经网络结构,而不必为了追求高效率的实现亲自写C++或CUDA代码。它和Theano一样都支持自动求导,用户不需要再通过反向传播求解梯度。其核心代码和Caffe一样是用C++编写的,使用C++简化了线上部署的复杂度,并让手机这种内存和CPU资源都紧张的设备可以运行复杂模型(Python则会比较消耗资源,并且执行效率不高)。除了核心代码的C++接口,TensorFlow还有官方的Python、Go和Java接口,是通过SWIG(Simplified Wrapper and Interface Generator)实现的,这样用户就可以在一个硬件配置较好的机器中用Python进行实验,并在资源比较紧张的嵌入式环境或需要低延迟的环境中用C++部署模型。


TensorFlow的另外一个重要特点是它灵活的移植性,可以将同一份代码几乎不经过修改就轻松地部署到有任意数量CPU或GPU的PC、服务器或者移动设备上。用户能够将训练好的模型方便地部署到多种硬件、操作系统平台上,支持Intel和AMD的CPU,通过CUDA支持NVIDIA的GPU,支持Linux和Mac、Windows,也能够基于ARM架构编译和优化,在移动设备(Android和iOS)上表现得很好。TensorFlow还有功能强大的可视化组件TensorBoard,能可视化网络结构和训练过程,对于观察复杂的网络结构和监控长时间、大规模的训练很有帮助。TensorFlow针对生产环境高度优化,它产品级的高质量代码和设计都可以保证在生产环境中稳定运行,同时TensorFlow广泛地被工业界使用,产生了良性循环,成为了深度学习领域的事实标准。
到底是选择Pytorch还是Tensorflow?


总结
本文讲解了LeNet5的来源与构造,是博主神经网络作业,大家有什么问题可以交流,部分网图,侵权删。