R学习笔记:《R语言入门与数据分析》
前言:这是根据B站《R语言入门与数据分析》自学整理的学习笔记。非科班出身,之前也没接触过代码,自己理解能力也比较差,所以会显得外行又笨拙,但还是希望多交流学习,才有动力持续进步。
目前这个课程笔记还没完结,会边学边更新。
文章目录
-
- P1 课程介绍
- P2 数据分析
- P3 数据挖掘
- P4 数据可视化
- P5 R语言介绍
-
- R语言的特点
- R语言的缺点
- P6 案例演示
- P7 R软件的安装
- P8 R软件的运行与设置
- P9 Rstudio
-
-
- 左上脚本窗口
- 左下控制台窗口
- 右上环境和历史记录窗口
- 右下功能模块窗口
- 快捷键
-
- P10 Rstudio 基本操作
-
-
- 图片另存
-
- P11 R包的安装
- P12 R包的使用
- P13 获取帮助
- P14 Excel案例
- P15 内置数据集
- P16 数据结构
- P17 向量
- P18 向量索引
-
-
- 正(负)整数索引
- 逻辑向量索引
- 名称索引
- 如何修改向量(包括添加、删除和修改数据)
-
- P19 向量运算
-
-
- 数值运算
- 逻辑运算
- 向量运算的函数
-
- **数学函数**
- **统计函数**
-
- P20 矩阵与数组
-
-
-
- 创建一个矩阵
- 数组
- 矩阵的索引(如何访问矩阵的数据)
- 矩阵运算
-
-
- P21 列表
- P22 数据框
- P23 因子
-
-
- 变量分类
-
- P24 缺失数据
- P25 字符串
-
-
-
- 正则表达式
- 统计字符串
- 提取字符串
- 字符串匹配
- 分割字符串
- 字符串成对组合技巧——笛卡尔积
-
-
- P26 日期和时间
- P26 常见错误
- P28 获取数据
- P29 读取文件(一)
- P30 读取文件(二)
- P31 写入文件
- P32 读写Excel文件
- P33 读写R格式文件
- P34 数据转换(一)
-
-
-
- 矩阵转换为数据框
- 数据框转换为矩阵
- is判断类型和as转换类型
- 向量转换为其他类型
-
-
- P35 数据转换(二)
-
-
-
- 取子集
- 删除固定行的数据
- 数据框的添加与合并
- 单独的行和列的添加
- 删除重复项行列
-
-
- P36 数据转换(三)
-
-
-
- 在R中的行列转换
- 单独翻转某一行
- 单位的转换
-
-
- P37 数据转换(四)
-
-
-
- apply series函数
- 数据的中心化与标准化
-
-
- P38 reshape2
- P39 tidyr包
- P40 dplyr包
- P41 R函数
-
-
-
- 输入数据类型适用函数
-
-
- P42 选项参数
-
-
-
- 1、输入控制部分
- 2、输出控制部分
- 3、调节部分
-
-
- P43 数学统计函数
- P44 描述性统计函数 ==补笔记==
- P45 频数统计函数
-
-
-
- 一维频数统计
- 多维频数统计
-
-
- P46 独立性检验函数
-
-
-
- 卡方检验
- Fisher精确概率检验
- Cochran-Mantel-Haenszel检验
-
-
- P47 相关性分析函数
P1 课程介绍
R语言用途:
- 统计
- 绘图
课程设置:
- 数据分析内容,R的目的
- R的基本操作
- 的数据结构和操作(重点)
- R对于文件的操作,读取
- R语言的实战分析
课程包含案例脚本和实战练习题
P2 数据分析
数据:指对客观事件进行记录并可以鉴别的符号,性质、状态及相互关系的记录
目的:指导决策
数据分析过程:
数据采集 --> 数据储存 --> 数据统计 --> 数据挖掘 --> 数据可视化 --> 进行决策
数据挖掘:非线性数据,一般指从大量的数据中通过算法搜索隐藏于其中信息的过程(探索的过程)
而数据统计则更注重于统计,可以通过不同的方法,但结果一样,数据挖掘则不同的人可能有不同的结果
P3 数据挖掘
- 分析与某事物相关的所有数据,而不是少部分数据,注重关联
- 接受数据的复杂性,而不过于追求精确性
- 不过分探求因果关系,转而关注事物的相关
P4 数据可视化
将数字结果用图形化展示出来
P5 R语言介绍
源自于S语言,但开源、免费,最初由做生物统计的科学家Robert开发
R语言的特点
- 有效的数据处理和保存机制
- 拥有完整数组和矩阵的操作运算符
- 一系列连贯而又完整的数据分析中间工具
- 数据可视化
- 程序设计语言:语句
- 彻底面向对象的统计编程语言
- 和其他编程语言、数据库之间有很好的接口
- 自由、开源、免费
- 具有丰富的网上资源
用于计算、统计、绘图、编程、分析(扩展包)
R语言的缺点
- R软件不够规范,不容易上手,学习成本高
- R扩展包数量太大,难以查找和上手,且这些包不如商业软件稳定
P6 案例演示
| 0.5mg | 1mg | 2mg | |
|---|---|---|---|
| 橙汁 | |||
| 维生素C |
豚鼠摄入上述两种物质对牙齿长度的影响
P7 R软件的安装
R语言官方网站(在CRAN-Mirrors里选择国内的镜像站点下载)
Rstudio官网下载(与R语言的区别在多了几个面板,操控跟容易,实质是IDE集成环境)
本人直接选择下载课程方打包放在百度云的版本(同时包含R语言和Rstudio)
P8 R软件的运行与设置
此节略过
P9 Rstudio
窗口布局如下表
| 左上窗口:R代码界面即脚本窗口 | 右上窗口:环境和历史记录 |
|---|---|
| 左下窗口:R的控制台 | 右下窗口:功能模块包括文档、绘图、帮助等 |
左上脚本窗口
- 编写代码,可直接保存,编写好的代码也是在这一模块直接导入
- 右上角的“Run”按钮直接点击是运行当前行,选中代码点击“Run”则是运行选中行
- 右上角的“Source”点击后运行所有代码,并会在左上窗口显示运行信息
- 左上角的荧光棒符号是检查语法的功能
- 左上角的放大镜是查找与替换的功能
- 左上角最左边的保存按钮可将代码保存在不同文件中
左下控制台窗口
- 练习代码用
- 包扩内置数据集、函数和扩展包的联想功能(设置中可关闭联想功能)
- 输入首字母后按“Tab”键,会出现联想功能(补齐)注意不能连续敲Tab,如果连敲两下代表默认补齐第一个函数,多加练习熟练之后可迅速反应敲几个字母排在首位的函数可直接敲Tab补齐
- 内置数据集 粉色
- 数据框 表格图案
- 函数 蓝色
右上环境和历史记录窗口
- Environment:列出当前工作空间中包含的对象,对象的值
如在左下角的控制台窗口直接输入
> mtcars可直接显示查看对象
- History:敲过的代码
右下功能模块窗口
- Files:当前工作空间所在文件
- Plots:图形展示窗口,在左下控制台中调用绘图函数时,图形会展示在此处的Plots窗口(所见即所得)
- Package:展示出系统已有的软件包,也可安装新的或者升级已有的软件包;勾选的包的名字则直接载入到左下控制台界面
上述每个窗口界面的占比都可通过鼠标移动缩放,更多的设置可点击
Tools --> Global Options --> Appearance(字体、主题)
快捷键
Ctrl + ↑
- 直接按列出历史输入记录(上下方向键进行选择)
- 再输入几个字母后按,如输入“> lib"后按Ctrl + ↑,则列出的是所有用过的包含”lib“的函数
Esc
-
在任何情况下按Esc键则中断操作
- 比如一个函数没敲完换行,出现连续几行的“+”的情况,此时可以直接按Esc中断操作
> sum(X + + + + > -
若语句太长,需要一个个删除太麻烦也可以直接按Esc中断操作
Alt + shift + K
可现实Rstudio中所有的快捷操作
P10 Rstudio 基本操作
- 设定工作目录:输入和输出文件的默认位置,包括读取和写入数据文件、打开和保存脚本文件以及保存工作空间映像等
- 可使用getwd命令查看当前默认的工作目录
> getwd()
[1] "C:/Users/Lin/Documents"
- R中的函数必须加小括号,因为在R中常量、变量、函数甚至图形都被称为对象,而对象都可以用自定义字母表示
可通过setwd函数命令更改工作目录,一般设置成文件所在的目录,结果输出也为此目录
> setwd(dir = "D:/RData/Data Practice")
> getwd()
[1] "D:/RData/Data Practice"
>
注意:调出setwd函数后,dir语句得跟双引号,且Windows默认路径中为反斜线\,R语言中路径里得改成正斜线/,且需要再输一次getwd函数
上述同样适用于修改rprofile.set文件
- 可使用list.files函数查看当前目录下包含文件
> setwd(dir = "D:/Rdata")
> getwd()
[1] "D:/Rdata"
> list.files()
[1] "2015年度中国城市GDP排名.xlsx"
[2] "Ch01.R"
[3] "Ch02.R"
[4] "Ch03.R"
[5] "Ch04.R"
[6] "Ch05.R"
[7] "Data Practice"
[8] "data.xlsx"
[9] "file.xlsx"
list.files的功能等同于
> dir()
5. 赋值操作
局部赋值
> x <- 3
> x
[1] 3
- 与其他语言一样,变量名不能是数字开头
- R语言赋值符号为一个小于号加一个连字符,中间没有空格
当然,也可以用等号进行赋值:
> x=3
> x
[1] 3
但一般不这么做,一是不专业,二是容易与计算结果符弄混
赋值符 <- 的快捷键:Alt + -
全局变量赋值
> X <<- 5
> X
[1] 5
当使用“ <<- "时表示强制赋值给一个全局变量,而不是局部变量
清屏快捷键:Ctrl + L
- 查看工作空间中已经定义的变量和函数:
> ls()
[1] "x" "X" "y" "z" "Z"
> ls.str()
x : num 6
X : num 5
y : num 30
z : num 7
Z : num 1
> str(x)
num 6
> str(y)
num 30
> str(z)
num 7
ls函数查看变量列表,str函数查看具体的变量值
如果需要查看名字中包含“.”的变量名,可使用:
> ls(all.names = TRUE)
[1] ".Random.seed" "x" "X"
[4] "y" "z" "Z"
- 删除变量(对象)
> rm (x)
> x
Error: object 'x' not found
使用rm(即remove的缩写)函数可删除一个或者多个对象:
> rm(x,y)
Warning message:
In rm(x, y) : object 'x' not found
> rm(y,z)
Warning message:
In rm(y, z) : object 'y' not found
#出现not found是因为我在上一步已经删除了这个对象
如果想一次性删除整个工作簿中的所有对象:
> rm (list=ls())
#列表和删除的组合函数
但注意,删除之后是不可撤销且没有回收站功能的
- 列出历史命令
> history(25)
#适用于清屏后,最大只支持最近25条记录,会在右上角环境窗口显示
-
保存
图片另存
为防止一次处理太多数据而导致的崩溃,可随时使用函数
> save.image(),类似word里的Ctrl + S的定期保存功能,并会在工作目录中生成一个R.Data文件,但只会保留数据和绘图函数等,绘制出来的图形不会单独保存,是另外的图片格式。保存图片可使用:> q() Save workspace image to D:/RData/Data Practice/.RData? [y/n]: #键入y即可保存
P11 R包的安装
官网包的位置:进入任意一个R的镜像下载页面(这里以中科大的镜像为例),点击左侧的“Packages”,再点击正文的“CRAN Task Views
R这个模式有点像手机操作系统,而包就是一个个的APP,通过安装不同APP来扩展手机系统的功能
R包的安装方式有两种
-
R包的在线安装(推荐)
首次安装包应打开R而不是
Rstudio,并输入:
> install.packages() #会跳出一个CRAN镜像选择框(网或者电脑卡则需要稍等一会儿才会弹出),根据地址就近选择就行,比如我选的是GuangZhou
接着会跳出一个数量巨大的 包选择对话框,从中选择需要下载安装的包即可
#接着程序会自动下载到默认目录并安装
#比如我的被安装到了C:\Users\Lin\AppData\Local\Temp\Rtmpwrn7kB\downloaded_packages
因为默认安装包下载在C盘,并不想存在此处,那么如何修改R包的默认下载储存位置呢?经过网上一番搜索找到如下答案:
1. 改变默认的安装路径:
.libPaths("new path")
#但这只是安装位置,下载保存位置依然没变,那么↓
2. 改变某一个包的保存及安装路径:
install.packages("Packagename",destdir="destdir",lib="libdir")
其中destdir为包所在位置,lib为指定的包安装路径
> install.packages("ggplot2",destdir="D:/RData/R-win-4.0.2/R-4.0.2/R-packages",lib="D:/RData/R-win-4.0.2/R-4.0.2/R-packages")#缺点是每次下载新的包都得设置一次
#我这么做的过程中出现了两次问题,一次是R版本不够新导致的安装时出现
安装程序包‘ggplot2’时退出狀態的值不是0
#解决办法是更新版本后重装即可
#第二次是安装到一半时网断了,出现
InternetOpenUrl失败:’无法与服务器建立连接'
#解决办法是重新联网……
#于是在下方学习到了一个用代码更新R的方法
R版本更新用代码命令行更新
#更新R版本-共三个命令行
> install.packages("installr")
还安装相依关系‘stringi’, ‘stringr’
下载的程序包在
‘C:\Users\Lin\AppData\Local\Temp\Rtmpwrn7kB\downloaded_packages’里
> library(installr)
To suppress this message use:
suppressPackageStartupMessages(library(installr))
> updateR()
The file was downloaded successfully into:
C:\Users\Lin\AppData\Local\Temp\Rtmpwrn7kB/R-4.0.2-win.exe
查看包的安装位置
> .libPaths()
[1] "D:/RData/R-win-4.0.2/R-4.0.2/R-packages"
[2] "D:/RData/R-win-4.0.2/R-4.0.2/library"
直接用联网安装的好处是对新手来说操作简单,自动安装,且会联动下载相关的关联包(相依关系)
查看已安装的包
在RStudio中的左下角的控制台输入> library(),则会在左上角的脚本窗口弹出一个选项卡界面显示当前已安装的包
- 源代码安装
需要手动在官网下载和设置包的源代码,并选择安装路径等一系列设置,同时还需要手动查看并处理依赖包的一系列安装,暂时不会用到,需要时再研究
可使用> update.packages()这一命令对包进行更新
P12 R包的使用
R包:实际上是函数、数据,预编译代码等以一种定义完善的方式组成的集合
- 存储包的目录称为库,函数
> .libPaths()显示包的存放位置 > library()可以在左上角弹出页面显示目前有哪些包- 可以使用
> library()或者> require()载入包,此时括号里的字符串(也就是包的名字)不需要使用引号了 - R本身内置了几个基础包,包括base datasets utils grDevices graphics stats methods splines stats4 tcltk等,提供了种类繁多的默认函数和数据集
- 函数
> search()回车可以显示出哪些包已加载并可以使用了 - 敲出的每个函数都会有提示框后面的灰色字显示来自哪个包
- 输入
> help(package="ggplot2")会在右下角的功能模块出现帮助文档:包含代码展示。实例展示等; - 也可以通过
> library(help="ggplot2")查看包的基本信息,内容会列在左上角的控制台模块里;- 在左上角内容界面的索引条目下,会出一系列的数据集,一般是为了给包中的函数作为案例使用的
- 可使用
> ls("package:vcd")命令列出当前包中所有函数- 具体函数如何使用可用命令
> data(package="vcd"),可列出R包中包含的所有数据集
- 具体函数如何使用可用命令
- 移除已经加载的包可使用
>detach("package:vcd")函数 - 克隆R包(用于换设备时转移):
- 使用
> installed.packages()列出当前环境中已安装的包(install后面有ed,注意区分); - 接着输入
> installed.packages()[,1],即使用下标访问数据的第一列; - 将所有R包的名字保存到一个文件中
Rpack <- installed.packages()[,1]和save(Rpack,file="Rpack.Rdata") - 将上面这个文件移到另一台设备中,可使用
>load()函数来打开这个文件。存到另外一个变量> Rpack中 - 在新设备中批量安装这些包可使用for循环:`> for (i in pack) install.packages(i)
- 即使新设备中已存在部分包也没关系,安装时会自动跳过已安装的包
- 使用
P13 获取帮助
- 直接点击可视化窗口菜单栏中的“Help”可查看,也可调用
>help.start()查看帮助文档 - 如果想直接查看某个函数的用途,可直接输入
> help(),会在右下角窗口出现帮助信息,也可直接输入一个问号紧接函数名,如> ?plot,效果相同 - 如果不想看那么多的函数具体信息,只想知道该函数的参数,可输入如
>args(plot)查看 - 如果想看一个函数的使用示例,可使用如
> example(mean)查看,绘图案例同理可用如> example(“hist”)查看 - 此外,R的内置函数
> demo(graphics)会列出一些==案例图== - 除了help函数查看R包的帮助外,还可以通过更详细的
> vignette函数查看,包含简介、教程、开发文档等(但不是所有包都包含这个文档) - 在未加载包的情况下查看包的帮助文档,可使用如
> ??ggplot2这个格式查找 - 在不知道具体包名,只知道一些关键词信息的情况下想查看具体的包的帮助,可使用本地搜索函数如
> help.search("heatmap") - 列出所有包含关键词的包可使用如
> apropos("sum")进行搜索 - 若函数搜索不到,或者文档太老了,可使用如
> RSiteSearch("matlab")联网搜索,结果会在默认浏览器里访问R官网并打开搜索结果 - 使用搜索引擎搜索:R搜索引擎,这是基于谷歌搜索引擎中得到的结果并提取出于R相关的结果部分(前提是能访问Google才能顺利使用该网站进行搜索
P14 Excel案例
本节为以《2015年度中国城市GDP排名》的表格为案例演示Excel数据分析的基本操作
R与Excel的比较:R与Excel最大的一个不同就是R软件不能使用鼠标。因此,在Excel中可以非常轻松完成的选择,框选,复制,粘贴,填充,排序,筛选等等操作,在R中必须使用代码来完成。(R往往用来处理大数据,使用鼠标反而更不方便)
行是观测值,列是变量值
快捷键:Alt + +
设置单元格格式:Ctrl + 1
对于需要可视化分析的数据,熟练掌握数据透视表的使用有助于提高工作效率
P15 内置数据集
- 使用函数
> help(package="datasets")可以在右下角窗口调出内置数据集文档,可点击查看详细信息,主要包含的是美国或者欧洲的数据信息 - 使用
> data()括号了里什么也不加可以在左上角窗口调出所有包含的内置数据集的列表(左列是名字,右列是介绍),包含矩阵、列表、因子、数据框以及时间序列等类型 - 直接输入数据集的名字,就会显示相关数据,如
> rivers会显示美国133条河流的长度(注意:自己的数据命名时尽量不要与内置数据集重复,避免覆盖内置数据集,但即使被覆盖也可以通过函数> data("rivers")重新加载即可) - 查看内置向量数据的属性信息
> names(euro)
[1] "ATS" "BEF" "DEM" "ESP" "FIM" "FRF" "IEP" "ITL" "LUF"
[10] "NLG" "PTE"
- 使用内置数据集构建矩阵(以美国各洲参数为例)
> state <- data.frame(state.name,state.abb,state.area,state.division,state.region)
> state
state.name state.abb state.area state.division
1 Alabama AL 51609 East South Central
2 Alaska AK 589757 Pacific
3 Arizona AZ 113909 Mountain
4 Arkansas AR 53104 West South Central
5 California CA 158693 Pacific
6 Colorado CO 104247 Mountain
7 Connecticut CT 5009 New England
8 Delaware DE 2057 South Atlantic
9 Florida FL 58560 South Atlantic
10 Georgia GA 58876 South Atlantic
11 Hawaii HI 6450 Pacific
12 Idaho ID 83557 Mountain
13 Illinois IL 56400 East North Central
14 Indiana IN 36291 East North Central
- 对内置数据集生成热图
> heatmap(volcano)
- 使用
> data(package=.packages(all.available = TRUE))可加载R包中所有可用的数据集 - 如果只想加载数据集而不是整个R包,可使用
> data(chile,package="car")(第一个参数是包的名字,第二个参数是需要加载的数据集的名字),再输入> Chile该数据集就会被加载进来
P16 数据结构
数据结构:是计算机存储、组织数据的方式。数据结构是指相互之间存在一种或多种特定关系的数据元素的集合。
- R中的数据类型
- 数值型:数值可以用于直接结算,加减乘除;
- 字符串型:可以进行连接、转换,提取等
- 逻辑型:真或者假
- 日期型等
不同的数据类型相当于基本的单词,数据结构相当于自然语言中的词汇、短语、句子甚至是文章
- 一般变成数据结构
- 普通数据结构:向量、标量、列表、数组、多维数组
- 特殊数据结构:
- perl中的哈希
- Python中的字典
- C语言中的指针等
- R对象
对象:object,是指可以赋值给变量的任何事物,包括常量、数据结构、函数,甚至图形。对象都拥有某种模式,描述了此对象是如何储存的,以及某个类。
- R中数据结构
- 向量,标量
- 矩阵
- 数组
- 列表
- 数据框
- 因子
- 时间序列
- ……
P17 向量
向量:vector,是R中最重要的一个概念,它是构成其他数据结构的基础。R中的向量概念与数学中的向量(矢量)是不同的,类似于数学上集合的概念,由一个或者多个元素构成。
向量其实是用于储存数值型、字符型或逻辑型数据的一堆数组。
用函数c来创建向量。c代表concatenate连接,也可以理解为收集collect,或者合并combine。
> x <- c(1,2,3,4,5)
> x #相当于省略print函数
[1] 1 2 3 4 5
> print(x)
[1] 1 2 3 4 5
> y <- c("one","two","three") #字符串一定要加引号
> y
[1] "one" "two" "three"
> z <- c(TRUE,T,F) #不加引号,但是字母都要大写
> z
[1] TRUE TRUE FALSE
> c(1:100) #冒号隔开表示依次列出1到100的所有整数值(向量)
[1] 1 2 3 4 5 6 7 8 9 10 11 12 13 14
[15] 15 16 17 18 19 20 21 22 23 24 25 26 27 28
[29] 29 30 31 32 33 34 35 36 37 38 39 40 41 42
[43] 43 44 45 46 47 48 49 50 51 52 53 54 55 56
[57] 57 58 59 60 61 62 63 64 65 66 67 68 69 70
[71] 71 72 73 74 75 76 77 78 79 80 81 82 83 84
[85] 85 86 87 88 89 90 91 92 93 94 95 96 97 98
[99] 99 100
> seq(from=1,to=100) #从1到100
[1] 1 2 3 4 5 6 7 8 9 10 11 12 13 14
[15] 15 16 17 18 19 20 21 22 23 24 25 26 27 28
[29] 29 30 31 32 33 34 35 36 37 38 39 40 41 42
[43] 43 44 45 46 47 48 49 50 51 52 53 54 55 56
[57] 57 58 59 60 61 62 63 64 65 66 67 68 69 70
[71] 71 72 73 74 75 76 77 78 79 80 81 82 83 84
[85] 85 86 87 88 89 90 91 92 93 94 95 96 97 98
[99] 99 100
> seq(from=1,to=100,by=2) #从1到100,间隔为2的所有向量(等差数列)
[1] 1 3 5 7 9 11 13 15 17 19 21 23 25 27 29 31 33 35 37
[20] 39 41 43 45 47 49 51 53 55 57 59 61 63 65 67 69 71 73 75
[39] 77 79 81 83 85 87 89 91 93 95 97 99
> seq(from=1,to=100,length.out = 10) #控制间隔长度,调整等差跨度
[1] 1 12 23 34 45 56 67 78 89 100
> rep(2,5) #重复某个向量,第一个参数是要被重复的向量,第二个参数是重复次数
[1] 2 2 2 2 2
> rep(x,5) #这里是重复刚刚上面定义的向量x
[1] 1 2 3 4 5 1 2 3 4 5 1 2 3 4 5 1 2 3 4 5 1 2 3 4 5
> rep(x,each=5) #设置重复方式,是整个数组重复,还是里头每一个元素集中重复
[1] 1 1 1 1 1 2 2 2 2 2 3 3 3 3 3 4 4 4 4 4 5 5 5 5 5
> rep(x,each=5,times=2) #当each和times同时存在时,出来的结果就是它们的乘积
[1] 1 1 1 1 1 2 2 2 2 2 3 3 3 3 3 4 4 4 4 4 5 5 5 5 5 1 1 1 1
[30] 1 2 2 2 2 2 3 3 3 3 3 4 4 4 4 4 5 5 5 5 5
> a <- c(1,2,"one")
> a
[1] "1" "2" "one" #输入的向量必须为同一类型,如不是则会被像如此转换
> mode(a)
[1] "character" #开头给a赋值的数字型在这里就被转换成了语句
> mode(z)
[1] "logical"
向量化编程的优势
> x <- c(1,2,3,4,5)
> y <- c(6,7,8,9,10)
> 1*2+6 #想让x向量中每一个元素都乘以2加上y向量中的每一个对应位置的元素该如何实现?
[1] 8
> x*2+y #这个语句就比其他编程语言中的for循环简单的多
[1] 8 11 14 17 20
> x[x>3] #从x中取出x>3的值
[1] 4 5
> rep(x,c(2,4,3,1,5)) #控制x中每一个元素的循环次数
[1] 1 1 2 2 2 2 3 3 3 4 5 5 5 5 5
P18 向量索引
向量索引:访问向量中的元素
-
正(负)整数索引
> x <- c(1:100)
> x
[1] 1 2 3 4 5 6 7 8 9 10 11 12 13 14
[15] 15 16 17 18 19 20 21 22 23 24 25 26 27 28
[29] 29 30 31 32 33 34 35 36 37 38 39 40 41 42
[43] 43 44 45 46 47 48 49 50 51 52 53 54 55 56
[57] 57 58 59 60 61 62 63 64 65 66 67 68 69 70
[71] 71 72 73 74 75 76 77 78 79 80 81 82 83 84
[85] 85 86 87 88 89 90 91 92 93 94 95 96 97 98
[99] 99 100
> length(x) #向量x中元素个数
[1] 100
> x[1] #向量x中第一个元素 也可以是 直接写出的这个元素 只是这里两个1刚好重复了
[1] 1
> x[0] #与其它编程语言不同,R是从1开始而不是从0开始,所以输入0则输出无效
integer(0)
> x(c(1:6)) #注意x后面第一层一定要跟中括号
Error in x(c(1:6)) : could not find function "x"
> x[c(1:6)] #输出x向量中第一到第六个元素
[1] 1 2 3 4 5 6
> x[-3] #负索引,输出x向量中除开第三个元素之外的所有元素
[1] 1 2 4 5 6 7 8 9 10 11 12 13 14 15
[15] 16 17 18 19 20 21 22 23 24 25 26 27 28 29
[29] 30 31 32 33 34 35 36 37 38 39 40 41 42 43
[43] 44 45 46 47 48 49 50 51 52 53 54 55 56 57
[57] 58 59 60 61 62 63 64 65 66 67 68 69 70 71
[71] 72 73 74 75 76 77 78 79 80 81 82 83 84 85
[85] 86 87 88 89 90 91 92 93 94 95 96 97 98 99
[99] 100
> x[c(1,3,7,44,67,89)] #输出指定元素
[1] 1 3 7 44 67 89
> x[c(1,5,5,34,34,53,53,53)] #输出重复元素
[1] 1 5 5 34 34 53 53 53
> x[c(-3,45,67)] #除去第三位后后面的元素顺序就变了,所以不能正确定义而报错,无法同时存在输出
Error in x[c(-3, 45, 67)] :
only 0's may be mixed with negative subscripts
-
逻辑向量索引
> y <- c(1:10)
> y
[1] 1 2 3 4 5 6 7 8 9 10
> y[c(T,T,F,F,T,F,T,T,F,T)] #用逻辑值作为索引,可以将TURE和FALSE缩写成T和F,这里的逻辑值对应y向量中的十个元素
[1] 1 2 5 7 8 10 #只输出了逻辑值为真的元素
> y[c(T)] #不需要与元素个数相等的逻辑值,也可以用循环
[1] 1 2 3 4 5 6 7 8 9 10 #表示向量y中所有元素都为真即全部输出
> y[c(f)] #注意逻辑值一定要大写
Error: object 'f' not found
> y[c(F)] #如果只有一个F则都不输出
integer(0)
> y[c(T,F)] #这里相当于使用“T,F”这个顺序循环
[1] 1 3 5 7 9
> y[c(T,T,F)]
[1] 1 2 4 5 7 8 10
> y[c(T,T,F,F,T,F,T,T,F,T,T)] #如果逻辑值的数量大于元素个数,则会产生缺失值
[1] 1 2 5 7 8 10 NA
> y[c(T,T,F,F,T,F,T,T,F,T,F)] #如果多的那个逻辑值为F则不输出
[1] 1 2 5 7 8 10
> y[y>4 & y<8] #条件判断表达式
[1] 5 6 7
> z <- c("one","two","three","four","five")
> z
[1] "one" "two" "three" "four" "five"
> "one" %in% z #%in%判断前面一个向量内的元素是否在后面一个向量中,返回布尔值
[1] TRUE
> z["one" %in% z]
[1] "one" "two" "three" "four" "five"
> z[z %in% C("one","two")]
Error in C("one", "two") : object not interpretable as a factor #c要小写
> z[z %in% c("one","two")]
[1] "one" "two"
> z %in% c("one","two")
[1] TRUE TRUE FALSE FALSE FALSE
> k <- z %in% c("one","two")
> z[k]
[1] "one" "two"
-
名称索引
> names(y) <- c("one","two","three","four","five","six","seven","eight","nine","ten")
> y
one two three four five six seven eight nine ten #元素名称,name的属性
1 2 3 4 5 6 7 8 9 10 #向量的元素值,即value
> names(y)
[1] "one" "two" "three" "four" "five" "six" "seven"
[8] "eight" "nine" "ten"
> euro #euro数据集,通过names函数访问向量的名称属性
ATS BEF DEM ESP FIM
13.760300 40.339900 1.955830 166.386000 5.945730
FRF IEP ITL LUF NLG
6.559570 0.787564 1936.270000 40.339900 2.203710
PTE
200.482000
如何修改向量(包括添加、删除和修改数据)
> x <- c(1:100)
> x
[1] 1 2 3 4 5 6 7 8 9 10 11 12 13 14
[15] 15 16 17 18 19 20 21 22 23 24 25 26 27 28
[29] 29 30 31 32 33 34 35 36 37 38 39 40 41 42
[43] 43 44 45 46 47 48 49 50 51 52 53 54 55 56
[57] 57 58 59 60 61 62 63 64 65 66 67 68 69 70
[71] 71 72 73 74 75 76 77 78 79 80 81 82 83 84
[85] 85 86 87 88 89 90 91 92 93 94 95 96 97 98
[99] 99 100
> x[101] <- 101 #多一个元素
> x
[1] 1 2 3 4 5 6 7 8 9 10 11 12 13 14
[15] 15 16 17 18 19 20 21 22 23 24 25 26 27 28
[29] 29 30 31 32 33 34 35 36 37 38 39 40 41 42
[43] 43 44 45 46 47 48 49 50 51 52 53 54 55 56
[57] 57 58 59 60 61 62 63 64 65 66 67 68 69 70
[71] 71 72 73 74 75 76 77 78 79 80 81 82 83 84
[85] 85 86 87 88 89 90 91 92 93 94 95 96 97 98
[99] 99 100 101
> v <- 1:3
> v[c(4,5,6)] <- c(4,5,6) #索引添加,批量赋值到具体位置
> v
[1] 1 2 3 4 5 6
> v[20] <- 4 #元素4被添加到20个元素,中间扩展没用被赋值的元素均为NA即缺失值
> v
[1] 1 2 3 4 5 6 NA NA NA NA NA NA NA NA NA NA NA NA NA
[20] 4
将数据添加到指定位置
> append(x = v,values = 99,after = 5) #将元素99添加到第五位之后
[1] 1 2 3 4 5 99 6 NA NA NA NA NA NA NA NA NA NA NA NA
[20] NA 4
> append(x=v,values = 99,after = 0) #after=0则是添加到第一位
[1] 99 1 2 3 4 5 6 NA NA NA NA NA NA NA NA NA NA NA NA
[20] NA 4
删除数据
> rm(v) #删除整个向量
> v
Error: object 'v' not found
> y[-c(1:3] #删除向量中的某个元素,可使用负整数索引的方式
four five six seven eight nine ten
4 5 6 7 8 9 10
> y <- y[-c(1:3)] #将替换掉的y重新赋值,作用相当于删除其中的元素了
> y
four five six seven eight nine ten
4 5 6 7 8 9 10
修改数据
> y["four"] <- 100 #将元素four的值改为100
> y
four five six seven eight nine ten
100 5 6 7 8 9 10
> x[2]
[1] 2
> x[2] <- 148 #将元素2改成148
> x[2]
[1] 148
> x[2] <- "one" #数值向量不能赋值给一个字符串
> x
[1] "1" "one" "3" "4" "5" "6" "7" "8" "9"
[10] "10" "11" "12" "13" "14" "15" "16" "17" "18"
[19] "19" "20" "21" "22" "23" "24" "25" "26" "27"
[28] "28" "29" "30" "31" "32" "33" "34" "35" "36"
[37] "37" "38" "39" "40" "41" "42" "43" "44" "45"
[46] "46" "47" "48" "49" "50" "51" "52" "53" "54"
[55] "55" "56" "57" "58" "59" "60" "61" "62" "63"
[64] "64" "65" "66" "67" "68" "69" "70" "71" "72"
[73] "73" "74" "75" "76" "77" "78" "79" "80" "81"
[82] "82" "83" "84" "85" "86" "87" "88" "89" "90"
[91] "91" "92" "93" "94" "95" "96" "97" "98" "99"
[100] "100" "101"
- 赋值的时候用( ),查东西的时候用[ ]
P19 向量运算
数值运算
> x <- 1:10
> x
[1] 1 2 3 4 5 6 7 8 9 10
> x+1 #每一个元素都加1
[1] 2 3 4 5 6 7 8 9 10 11
> x-3 #每一个元素都减3
[1] -2 -1 0 1 2 3 4 5 6 7
> x <- x+1 #将结果赋值更新
> x
[1] 2 3 4 5 6 7 8 9 10 11
> y <- seq(1,100,length.out = 10) #1-100差十个间隔的等差数列
> y
[1] 1 12 23 34 45 56 67 78 89 100
> x+y #每个对应位置的元素相加
[1] 3 15 27 39 51 63 75 87 99 111
> x*y #每个对应位置的元素相乘
[1] 2 36 92 170 270 392 536 702 890 1100
> x
[1] 2 3 4 5 6 7 8 9 10 11
> y
[1] 1 12 23 34 45 56 67 78 89 100
> x**y #x的y次幂
[1] 2.000000e+00 5.314410e+05 7.036874e+13 5.820766e+23
[5] 1.039456e+35 2.115876e+47 3.213876e+60 2.697216e+74
[9] 1.000000e+89 1.378061e+104
> y%%x # y除以x的余数
[1] 1 0 3 4 3 0 3 6 9 1
> y%/%x #y除以x的值
[1] 0 4 5 6 7 8 8 8 8 9
> z <- c(1,2) #元素个数不一致的计算情况,定义一个只有两个元素的z
> x
[1] 2 3 4 5 6 7 8 9 10 11
> x+z #z会被循环使用,第一次加1,第二次加2,第三次加1.第四次加2……以此类推
[1] 3 5 5 7 7 9 9 11 11 13
> x*z #乘同加
[1] 2 6 4 10 6 14 8 18 10 22
> z <- 1:3 #如果将向量z的元素定义为3个呢?
> x
[1] 2 3 4 5 6 7 8 9 10 11
> z
[1] 1 2 3
> x+z
[1] 3 5 7 6 8 10 9 11 13 12
Warning message:
In x + z : longer object length is not a multiple of shorter object length
#出现报错,提示x和z的长度不匹配,在向量运算中,元素个数必须为整数倍
逻辑运算
> x
[1] 2 3 4 5 6 7 8 9 10 11
> x>5
[1] FALSE FALSE FALSE FALSE TRUE TRUE TRUE TRUE TRUE
[10] TRUE
> y
[1] 1 12 23 34 45 56 67 78 89 100
> x>y
[1] TRUE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
[10] FALSE
> c(1,2,3) %in% c(1,2,2,4,5,6) #包含运算符%in%表示左边的值是否存在于右边,如果在则输出为TRUE
[1] TRUE TRUE FALSE
> x
[1] 2 3 4 5 6 7 8 9 10 11
> y
[1] 1 12 23 34 45 56 67 78 89 100
> x==y #两个等于号==是逻辑运算
[1] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
[10] FALSE
> x=y #一个等号=是赋值,一定要注意区分以免影响后面的运算
> x
[1] 1 12 23 34 45 56 67 78 89 100
> y
[1] 1 12 23 34 45 56 67 78 89 100
向量运算的函数
-
数学函数
> x <- -5:5
> abs(x) #求向量x的绝对值
[1] 5 4 3 2 1 0 1 2 3 4 5
> sqrt(x) #求x的平方根
[1] NaN NaN NaN NaN NaN 0.000000
[7] 1.000000 1.414214 1.732051 2.000000 2.236068
Warning message:
In sqrt(x) : NaNs produced
> sqrt(25)
[1] 5
> log(16,base = 2) #计算一2为底,16的对数
[1] 4
> log(16) #不加base默认是自然对数
[1] 2.772589
> log10(10) #以10为底10的对数
[1] 1
> exp(x) #向量x中以e为底的指数函数
[1] 6.737947e-03 1.831564e-02 4.978707e-02 1.353353e-01
[5] 3.678794e-01 1.000000e+00 2.718282e+00 7.389056e+00
[9] 2.008554e+01 5.459815e+01 1.484132e+02
> ceiling(c(-2.45,3.1415)) #天花板,向上取整
[1] -2 4
> floor(c(-2.45,3.1415)) #地板,向下取整
[1] -3 3
> trunc(c(-2.45,3.1415)) #取整,源自truncate(缩短删减、掐头去尾的意思)
[1] -2 3
> round(c(-2.45,3.1415)) #取整
[1] -2 3
> round(c(-2.45,3.1415),digits = 2) #保留小数点后两位
[1] -2.45 3.14
> signif(c(-2.45,3.1415),digits = 2) #作用类似于round,保留两位有效数字
[1] -2.4 3.1
> sin(x) #三角函数
[1] 0.9589243 0.7568025 -0.1411200 -0.9092974 -0.8414710
[6] 0.0000000 0.8414710 0.9092974 0.1411200 -0.7568025
[11] -0.9589243
> cos(x)
[1] 0.2836622 -0.6536436 -0.9899925 -0.4161468 0.5403023
[6] 1.0000000 0.5403023 -0.4161468 -0.9899925 -0.6536436
[11] 0.2836622
-
统计函数
> vec <- c(1:100) #创建一个1到100的向量
> vec
[1] 1 2 3 4 5 6 7 8 9 10 11 12 13 14
[15] 15 16 17 18 19 20 21 22 23 24 25 26 27 28
[29] 29 30 31 32 33 34 35 36 37 38 39 40 41 42
[43] 43 44 45 46 47 48 49 50 51 52 53 54 55 56
[57] 57 58 59 60 61 62 63 64 65 66 67 68 69 70
[71] 71 72 73 74 75 76 77 78 79 80 81 82 83 84
[85] 85 86 87 88 89 90 91 92 93 94 95 96 97 98
[99] 99 100
> sum(vec) #对vec求和
[1] 5050
> max(vec) #vec中的最大值
[1] 100
> min(vec) #最小值
[1] 1
> range(vec) #范围
[1] 1 100
> mean(vec) #均值
[1] 50.5
> var(vec) #方差
[1] 841.6667
> round(var(vec),digits = 2) #对方差保留两位小数
[1] 841.67
> round(sd(vec),digits = 2) #sd表示标准差
[1] 29.01
> prod(vec) #连乘的积
[1] 9.332622e+157
> median(vec) #中位数
[1] 50.5
> quantile(vec) #分位数
0% 25% 50% 75% 100%
1.00 25.75 50.50 75.25 100.00
> quantile(vec,c(0.4,0.5,0.8)) #分别计算vec的四分位数,分位数和八分位数
40% 50% 80%
40.6 50.5 80.2
> t <- c(1,4,3,5,9,7)
> t
[1] 1 4 3 5 9 7
> which.max(t) #返回的是索引值,返回的是最大值的位置
[1] 5
> which.min(t) #此处一定是索引值,这里的1同样是位置
[1] 1
> which(t==7) #索引元素7的位置
[1] 6
> which(t>3) #索引向量t中所有大于3的元素的位置
[1] 2 4 5 6
P20 矩阵与数组
矩阵(Matrix):是一个按照长方阵列排列的复数或实数集合。向量是一维的,而矩阵是二维的,需要有行和列。
在R软件中,矩阵是有维数的向量,这里的矩阵元素可以是数值型,字符型或者逻辑型,但是每个元素必须都拥有相同的模式,这个和向量一致。
常见的内置数据集> iris3和> state.77都是常见矩阵,可直接用>heatmap()绘制热图
创建一个矩阵
> x <- 1:20
> x
[1] 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
[20] 20
> m <- matrix(x,nrow = 4,ncol = 5) #nrow表示行(Row),ncol表示列(Column)
> m
[,1] [,2] [,3] [,4] [,5]
[1,] 1 5 9 13 17
[2,] 2 6 10 14 18
[3,] 3 7 11 15 19
[4,] 4 8 12 16 20
> m <- matrix(1:20,4,5) #也可以省略参数名直接创建
> m
[,1] [,2] [,3] [,4] [,5]
[1,] 1 5 9 13 17
[2,] 2 6 10 14 18
[3,] 3 7 11 15 19
[4,] 4 8 12 16 20
> m <- matrix(x,nrow = 4,ncol = 6)
Warning message: #行和列一定要满足分配
In matrix(x, nrow = 4, ncol = 6) :
data length [20] is not a sub-multiple or multiple of the number of columns [6]
> m <- matrix(x,nrow = 4,ncol = 4) #会满足行列要求自动分配
> m
[,1] [,2] [,3] [,4]
[1,] 1 5 9 13
[2,] 2 6 10 14
[3,] 3 7 11 15
[4,] 4 8 12 16
> m <- matrix(x,nrow = 3,ncol = 3) #不能满足分配所以报错
Warning message:
In matrix(x, nrow = 3, ncol = 3) :
data length [20] is not a sub-multiple or multiple of the number of rows [3]
> m <- matrix(1:20,4) #省略参数也会自动分配,但默认按列分配
> m
[,1] [,2] [,3] [,4] [,5]
[1,] 1 5 9 13 17
[2,] 2 6 10 14 18
[3,] 3 7 11 15 19
[4,] 4 8 12 16 20
> m <- matrix(1:20,4,byrow = T) #可修改为按行排列,共排四行
> m
[,1] [,2] [,3] [,4] [,5]
[1,] 1 2 3 4 5
[2,] 6 7 8 9 10
[3,] 11 12 13 14 15
[4,] 16 17 18 19 20
> m <- matrix(1:20,4,byrow = F) #改为FALSE则按列分布
> m
[,1] [,2] [,3] [,4] [,5]
[1,] 1 5 9 13 17
[2,] 2 6 10 14 18
[3,] 3 7 11 15 19
[4,] 4 8 12 16 20
> rnames <- c("R1","R2","R3","R4") #创建一个行并给行命名
> rnames
[1] "R1" "R2" "R3" "R4"
> cnames <- c("C1","C2","C3","C4","C5") #创建一个列并给列命名
> cnames
[1] "C1" "C2" "C3" "C4" "C5"
> dimnames(m) <- list(rnames,cnames) #给矩阵的行和列命名
> m
C1 C2 C3 C4 C5
R1 1 5 9 13 17
R2 2 6 10 14 18
R3 3 7 11 15 19
R4 4 8 12 16 20
> ?dim #dimension的简称,可以显示向量的维数
> dim(x)
NULL
> dim(x) <- c(4,5) #通过添加维数构建向量,4行5列
> x #由向量变成了矩阵
[,1] [,2] [,3] [,4] [,5]
[1,] 1 5 9 13 17
[2,] 2 6 10 14 18
[3,] 3 7 11 15 19
[4,] 4 8 12 16 20
数组
R的向量像其他语言中的数组,R的数组其实就是多维的矩阵
> dim(x) <- c(4,5) #将向量写成一个4行5列的数组
> x
[,1] [,2] [,3] [,4] [,5]
[1,] 1 5 9 13 17
[2,] 2 6 10 14 18
[3,] 3 7 11 15 19
[4,] 4 8 12 16 20
> x <- 1:20
> dim(x) <- c(2,2,5) #定义一个关于向量x的三维数组:一维相当于一行字,二维相当于一页纸,三维相当于一本书,但三维没法直观的在页面表示出来,于是表示成下面的样子
> x
, , 1
[,1] [,2]
[1,] 1 3
[2,] 2 4
, , 2
[,1] [,2]
[1,] 5 7
[2,] 6 8
, , 3
[,1] [,2]
[1,] 9 11
[2,] 10 12
, , 4
[,1] [,2]
[1,] 13 15
[2,] 14 16
, , 5
[,1] [,2]
[1,] 17 19
[2,] 18 20
> ?array
> dim1 <- c("A1","A2")
> dim2 <- c("B1","B2","B3")
> dim3 <- C("C1","C2","C3","C4")
Error in C("C1", "C2", "C3", "C4") : 不能把对象解释成因子 #这里上面dim3的c不小心大写了,注意
> dim3 <- c("C1","C2","C3","C4")
> z <- array(1:24,c(2,3,4),dimnames = list(dim1,dim2,dim3))
> z
, , C1
B1 B2 B3
A1 1 3 5
A2 2 4 6
, , C2
B1 B2 B3
A1 7 9 11
A2 8 10 12
, , C3
B1 B2 B3
A1 13 15 17
A2 14 16 18
, , C4
B1 B2 B3
A1 19 21 23
A2 20 22 24
#还可以创建字符型和逻辑型的矩阵或数组,也可以创建更多维的数组(复杂,用的不多)
#R内置数据集的经典矩阵 > Titanic
矩阵的索引(如何访问矩阵的数据)
> m <- matrix(1:20,4,5,byrow = T)
> m
[,1] [,2] [,3] [,4] [,5]
[1,] 1 2 3 4 5
[2,] 6 7 8 9 10
[3,] 11 12 13 14 15
[4,] 16 17 18 19 20
> m[1,2] #访问第1行第2列的元素 相当于行是i,列是j
[1] 2
> m[1,c(2,3,4)] #访问第1行,第2、3、4位的元素
[1] 2 3 4
> m[c(2:4),c(2,3)] #访问m中第2到4行以及第2到3列的元素,出来一个子集
[,1] [,2]
[1,] 7 8
[2,] 12 13
[3,] 17 18
> m[2,] #访问第2行的所有元素
[1] 6 7 8 9 10
> m[,2] #访问第2列的所有元素
[1] 2 7 12 17
> m[2] #逗号的重要性,如果没有则是第2行第1个元素
[1] 6
> m[-1,2] #第2列除第一个以外的所有元素
[1] 7 12 17
> dimnames(m)=list(rnames,cnames)
> m
C1 C2 C3 C4 C5
R1 1 2 3 4 5
R2 6 7 8 9 10
R3 11 12 13 14 15
R4 16 17 18 19 20
> m["R1","C2"] #直接通过坐标访问也可,但注意字符串要加引号
[1] 2
> head(state.x77)
Population Income Illiteracy Life Exp Murder
Alabama 3615 3624 2.1 69.05 15.1
Alaska 365 6315 1.5 69.31 11.3
Arizona 2212 4530 1.8 70.55 7.8
Arkansas 2110 3378 1.9 70.66 10.1
California 21198 5114 1.1 71.71 10.3
Colorado 2541 4884 0.7 72.06 6.8
HS Grad Frost Area
Alabama 41.3 20 50708
Alaska 66.7 152 566432
Arizona 58.1 15 113417
Arkansas 39.9 65 51945
California 62.6 20 156361
Colorado 63.9 166 103766
> state.x77[Income] #名称语句一定要加引号,同时注意大小写
Error: object 'Income' not found
> state.x77["Income"] #矩阵的查找i和j要同时索引
[1] NA
> state.x77[,"Income"] #查找Income这一列的所有值
Alabama Alaska Arizona Arkansas
3624 6315 4530 3378
California Colorado Connecticut Delaware
5114 4884 5348 4809
Florida Georgia Hawaii Idaho
4815 4091 4963 4119
Illinois Indiana Iowa Kansas
5107 4458 4628 4669
Kentucky Louisiana Maine Maryland
3712 3545 3694 5299
Massachusetts Michigan Minnesota Mississippi
4755 4751 4675 3098
Missouri Montana Nebraska Nevada
4254 4347 4508 5149
New Hampshire New Jersey New Mexico New York
4281 5237 3601 4903
North Carolina North Dakota Ohio Oklahoma
3875 5087 4561 3983
Oregon Pennsylvania Rhode Island South Carolina
4660 4449 4558 3635
South Dakota Tennessee Texas Utah
4167 3821 4188 4022
Vermont Virginia Washington West Virginia
3907 4701 4864 3617
Wisconsin Wyoming
4468 4566
> state.x77["Alabama"]
[1] NA
> state.x77["Alabama",] #查找整行
Population Income Illiteracy Life Exp Murder
3615.00 3624.00 2.10 69.05 15.10
HS Grad Frost Area
41.30 20.00 50708.00
矩阵运算
> m
C1 C2 C3 C4 C5
R1 1 2 3 4 5
R2 6 7 8 9 10
R3 11 12 13 14 15
R4 16 17 18 19 20
> m+1 #m矩阵中每个元素都加1
C1 C2 C3 C4 C5
R1 2 3 4 5 6
R2 7 8 9 10 11
R3 12 13 14 15 16
R4 17 18 19 20 21
> m*2 #m矩阵中每个元素都乘以2
C1 C2 C3 C4 C5
R1 2 4 6 8 10
R2 12 14 16 18 20
R3 22 24 26 28 30
R4 32 34 36 38 40
> m+m #每个对应位置的元素相加
C1 C2 C3 C4 C5
R1 2 4 6 8 10
R2 12 14 16 18 20
R3 22 24 26 28 30
R4 32 34 36 38 40
> n <- matrix(1:20,5,4)
> n
[,1] [,2] [,3] [,4]
[1,] 1 6 11 16
[2,] 2 7 12 17
[3,] 3 8 13 18
[4,] 4 9 14 19
[5,] 5 10 15 20
> m+n #元素位置不匹配对应无法进行计算,m是4行5列,n是5行4列
Error in m + n : non-conformable arrays
> m[1,]
C1 C2 C3 C4 C5
1 2 3 4 5
> t <- m[1,]
> sum(t) #可以利用赋值的方式对矩阵中某些具体元素进行运算,但这样显然太复杂了,利用公式更简便
[1] 15
> colSums(m) #计算m中每一列的和
C1 C2 C3 C4 C5
34 38 42 46 50
> rowSums(m) #计算m中每一行的和
R1 R2 R3 R4
15 40 65 90
> n <- matrix(1:9,3,3)
> t <- matrix(2:10,3,3)
> n
[,1] [,2] [,3]
[1,] 1 4 7
[2,] 2 5 8
[3,] 3 6 9
> t
[,1] [,2] [,3]
[1,] 2 5 8
[2,] 3 6 9
[3,] 4 7 10
> n*t #矩阵的内积
[,1] [,2] [,3]
[1,] 2 20 56
[2,] 6 30 72
[3,] 12 42 90
> n %*% t #矩阵的外积
[,1] [,2] [,3]
[1,] 42 78 114
[2,] 51 96 141
[3,] 60 114 168
> diag(n) #计算对角线
[1] 1 5 9
> diag(m)
[1] 1 7 13 19
> t(m) #对m进行转制,将行和列进行互换
R1 R2 R3 R4
C1 1 6 11 16
C2 2 7 12 17
C3 3 8 13 18
C4 4 9 14 19
C5 5 10 15 20
C1 C2 C3 C4 C5
R1 1 2 3 4 5
R2 6 7 8 9 10
R3 11 12 13 14 15
R4 16 17 18 19 20
P21 列表
列表顾名思义就是用来存储很多内容的一个集合,在其他编程语言中,列表一般和数组是等同的,但是在R语言中,列表却是R中最复杂的一种数据结构,也是非常重要的一种数据结构。
列表就是一些对象的有序集合。列表中可以存储若干向量、矩阵、数据框,甚至其他列表的组合。
向量与列表
1、在模式上和向量类似,都是一维数据集合。
2、向量只能存储一种数据类型,列表中的对象可以是R中的任何数据结构,甚至列表本身。
> state.center #内置列表
$x
[1] -86.7509 -127.2500 -111.6250 -92.2992 -119.7730
[6] -105.5130 -72.3573 -74.9841 -81.6850 -83.3736
[11] -126.2500 -113.9300 -89.3776 -86.0808 -93.3714
[16] -98.1156 -84.7674 -92.2724 -68.9801 -76.6459
[21] -71.5800 -84.6870 -94.6043 -89.8065 -92.5137
[26] -109.3200 -99.5898 -116.8510 -71.3924 -74.2336
[31] -105.9420 -75.1449 -78.4686 -100.0990 -82.5963
[36] -97.1239 -120.0680 -77.4500 -71.1244 -80.5056
[41] -99.7238 -86.4560 -98.7857 -111.3300 -72.5450
[46] -78.2005 -119.7460 -80.6665 -89.9941 -107.2560
$y
[1] 32.5901 49.2500 34.2192 34.7336 36.5341 38.6777 41.5928
[8] 38.6777 27.8744 32.3329 31.7500 43.5648 40.0495 40.0495
[15] 41.9358 38.4204 37.3915 30.6181 45.6226 39.2778 42.3645
[22] 43.1361 46.3943 32.6758 38.3347 46.8230 41.3356 39.1063
[29] 43.3934 39.9637 34.4764 43.1361 35.4195 47.2517 40.2210
[36] 35.5053 43.9078 40.9069 41.5928 33.6190 44.3365 35.6767
[43] 31.3897 39.1063 44.2508 37.5630 47.4231 38.4204 44.5937
[50] 43.0504
> a <- 1:20 #向量
> b <- matrix(1:20,4) #矩阵
> c <- mtcars #内置矩阵数据集
> d <- "This is a test list" #字符串
> a;b;c;d
[1] 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
[20] 20
[,1] [,2] [,3] [,4] [,5]
[1,] 1 5 9 13 17
[2,] 2 6 10 14 18
[3,] 3 7 11 15 19
[4,] 4 8 12 16 20
mpg cyl disp hp drat wt qsec vs am
Mazda RX4 21.0 6 160.0 110 3.90 2.620 16.46 0 1
Mazda RX4 Wag 21.0 6 160.0 110 3.90 2.875 17.02 0 1
Datsun 710 22.8 4 108.0 93 3.85 2.320 18.61 1 1
Hornet 4 Drive 21.4 6 258.0 110 3.08 3.215 19.44 1 0
Hornet Sportabout 18.7 8 360.0 175 3.15 3.440 17.02 0 0
Valiant 18.1 6 225.0 105 2.76 3.460 20.22 1 0
[1] "This is a test list"
> mlist <- list(a,b,c,d)
> mlist
[[1]]
[1] 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
[20] 20
[[2]]
[,1] [,2] [,3] [,4] [,5]
[1,] 1 5 9 13 17
[2,] 2 6 10 14 18
[3,] 3 7 11 15 19
[4,] 4 8 12 16 20
[[3]]
mpg cyl disp hp drat wt qsec vs am
Mazda RX4 21.0 6 160.0 110 3.90 2.620 16.46 0 1
Mazda RX4 Wag 21.0 6 160.0 110 3.90 2.875 17.02 0 1
Datsun 710 22.8 4 108.0 93 3.85 2.320 18.61 1 1
Hornet 4 Drive 21.4 6 258.0 110 3.08 3.215 19.44 1 0
Hornet Sportabout 18.7 8 360.0 175 3.15 3.440 17.02 0 0
Valiant 18.1 6 225.0 105 2.76 3.460 20.22 1 0
[[4]]
[1] "This is a test list"
> mlist <- list(first=a,second=b,third=c,forth=d) #创建列表
> mlist
$first
[1] 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
[20] 20
$second
[,1] [,2] [,3] [,4] [,5]
[1,] 1 5 9 13 17
[2,] 2 6 10 14 18
[3,] 3 7 11 15 19
[4,] 4 8 12 16 20
$third
mpg cyl disp hp drat wt qsec vs am
Mazda RX4 21.0 6 160.0 110 3.90 2.620 16.46 0 1
Mazda RX4 Wag 21.0 6 160.0 110 3.90 2.875 17.02 0 1
Datsun 710 22.8 4 108.0 93 3.85 2.320 18.61 1 1
Hornet 4 Drive 21.4 6 258.0 110 3.08 3.215 19.44 1 0
Hornet Sportabout 18.7 8 360.0 175 3.15 3.440 17.02 0 0
Valiant 18.1 6 225.0 105 2.76 3.460 20.22 1 0
$forth
[1] "This is a test list"
> mlist[1] #索引列表中某项
$first
[1] 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
[20] 20
> mlist[1,4] #加c
Error in mlist[1, 4] : incorrect number of dimensions
> mlist[c(1,4)] #索引第几到第几项
$first
[1] 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
[20] 20
$forth
[1] "This is a test list"
> state.center[c("x","y")] #按字符串索引
$x
[1] -86.7509 -127.2500 -111.6250 -92.2992 -119.7730
[6] -105.5130 -72.3573 -74.9841 -81.6850 -83.3736
[11] -126.2500 -113.9300 -89.3776 -86.0808 -93.3714
[16] -98.1156 -84.7674 -92.2724 -68.9801 -76.6459
[21] -71.5800 -84.6870 -94.6043 -89.8065 -92.5137
[26] -109.3200 -99.5898 -116.8510 -71.3924 -74.2336
[31] -105.9420 -75.1449 -78.4686 -100.0990 -82.5963
[36] -97.1239 -120.0680 -77.4500 -71.1244 -80.5056
[41] -99.7238 -86.4560 -98.7857 -111.3300 -72.5450
[46] -78.2005 -119.7460 -80.6665 -89.9941 -107.2560
$y
[1] 32.5901 49.2500 34.2192 34.7336 36.5341 38.6777 41.5928
[8] 38.6777 27.8744 32.3329 31.7500 43.5648 40.0495 40.0495
[15] 41.9358 38.4204 37.3915 30.6181 45.6226 39.2778 42.3645
[22] 43.1361 46.3943 32.6758 38.3347 46.8230 41.3356 39.1063
[29] 43.3934 39.9637 34.4764 43.1361 35.4195 47.2517 40.2210
[36] 35.5053 43.9078 40.9069 41.5928 33.6190 44.3365 35.6767
[43] 31.3897 39.1063 44.2508 37.5630 47.4231 38.4204 44.5937
[50] 43.0504
> mlist$first #也可直接用美元符$接名字索引
[1] 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
[20] 20
> state.center$x
[1] -86.7509 -127.2500 -111.6250 -92.2992 -119.7730
[6] -105.5130 -72.3573 -74.9841 -81.6850 -83.3736
[11] -126.2500 -113.9300 -89.3776 -86.0808 -93.3714
[16] -98.1156 -84.7674 -92.2724 -68.9801 -76.6459
[21] -71.5800 -84.6870 -94.6043 -89.8065 -92.5137
[26] -109.3200 -99.5898 -116.8510 -71.3924 -74.2336
[31] -105.9420 -75.1449 -78.4686 -100.0990 -82.5963
[36] -97.1239 -120.0680 -77.4500 -71.1244 -80.5056
[41] -99.7238 -86.4560 -98.7857 -111.3300 -72.5450
[46] -78.2005 -119.7460 -80.6665 -89.9941 -107.2560
> mlist[1] #一个中括号[ ]索引出的是列表
$first
[1] 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
[20] 20
> mlist[[1]] #两个中括号[[ ]]索引出来的是列表中的数据(类型)
[1] 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
[20] 20
> class(mlist[1])
[1] "list"
> class(mlist[[1]])
[1] "integer"
> mlist[5] <- iris
Warning message:
In mlist[5] <- iris :
number of items to replace is not a multiple of replacement length
> mlist[[5]] <- iris #添加列表项要用双中括号[[ ]]
> mlist
$first
[1] 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
[20] 20
$second
[,1] [,2] [,3] [,4] [,5]
[1,] 1 5 9 13 17
[2,] 2 6 10 14 18
[3,] 3 7 11 15 19
[4,] 4 8 12 16 20
$third
mpg cyl disp hp drat wt qsec vs am
Mazda RX4 21.0 6 160.0 110 3.90 2.620 16.46 0 1
Mazda RX4 Wag 21.0 6 160.0 110 3.90 2.875 17.02 0 1
Datsun 710 22.8 4 108.0 93 3.85 2.320 18.61 1 1
Hornet 4 Drive 21.4 6 258.0 110 3.08 3.215 19.44 1 0
Hornet Sportabout 18.7 8 360.0 175 3.15 3.440 17.02 0 0
Valiant 18.1 6 225.0 105 2.76 3.460 20.22 1 0
$forth
[1] "This is a test list"
[[5]]
Sepal.Length Sepal.Width Petal.Length Petal.Width
1 5.1 3.5 1.4 0.2
2 4.9 3.0 1.4 0.2
3 4.7 3.2 1.3 0.2
4 4.6 3.1 1.5 0.2
5 5.0 3.6 1.4 0.2
6 5.4 3.9 1.7 0.4
Species
1 setosa
2 setosa
3 setosa
4 setosa
5 setosa
6 setosa
> mlist[-5] #删除列表项用一个中括号
$first
[1] 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
[20] 20
$second
[,1] [,2] [,3] [,4] [,5]
[1,] 1 5 9 13 17
[2,] 2 6 10 14 18
[3,] 3 7 11 15 19
[4,] 4 8 12 16 20
$third
mpg cyl disp hp drat wt qsec vs am
Mazda RX4 21.0 6 160.0 110 3.90 2.620 16.46 0 1
Mazda RX4 Wag 21.0 6 160.0 110 3.90 2.875 17.02 0 1
Datsun 710 22.8 4 108.0 93 3.85 2.320 18.61 1 1
Hornet 4 Drive 21.4 6 258.0 110 3.08 3.215 19.44 1 0
Hornet Sportabout 18.7 8 360.0 175 3.15 3.440 17.02 0 0
$forth
[1] "This is a test list"
> mlist[[5]] <- NULL #也可直接NULL置空
> mlist
$first
[1] 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
[20] 20
$second
[,1] [,2] [,3] [,4] [,5]
[1,] 1 5 9 13 17
[2,] 2 6 10 14 18
[3,] 3 7 11 15 19
[4,] 4 8 12 16 20
$third
mpg cyl disp hp drat wt qsec vs am
Mazda RX4 21.0 6 160.0 110 3.90 2.620 16.46 0 1
Mazda RX4 Wag 21.0 6 160.0 110 3.90 2.875 17.02 0 1
Datsun 710 22.8 4 108.0 93 3.85 2.320 18.61 1 1
Hornet 4 Drive 21.4 6 258.0 110 3.08 3.215 19.44 1 0
Hornet Sportabout 18.7 8 360.0 175 3.15 3.440 17.02 0 0
Valiant 18.1 6 225.0 105 2.76 3.460 20.22 1 0
$forth
[1] "This is a test list"
P22 数据框
数据框是一种表格式的数据结构。数据框旨在模拟数据集,与其他统计软件例如SAS或者SPSS中的数据集的概念一致。
数据集通常是由数据构成的一个矩形数组,行表示观测,列表示变量。
不同的行业对于数据集的行和列叫法不同。
数据框特点
数据框实际上是一个列表。列表中的元素是向量,这些向量构成数据框的列,每一列必须具有相同的长度,所以数据框是矩形结构,而且数据框的列必须命名。
矩阵与数据框
1、数据框形状上很像矩阵;
2、数据框是比较规则的列表;
3、矩阵必须为同一数据类型;
4、数据框每一列必须同一类型,每一行可以不同。
矩阵所有的数据是同一类型,dataframe只是每一列同一个类型
> state <- data.frame(state.name,state.abb,state.region,state.x77) #将列表和成数据框
> state
state.name state.abb state.region
Alabama Alabama AL South
Alaska Alaska AK West
Arizona Arizona AZ West
Arkansas Arkansas AR South
California California CA West
Colorado Colorado CO West
> state[c(2,4)] #输出2/3/4列
state.abb Population
Alabama AL 3615
Alaska AK 365
Arizona AZ 2212
Arkansas AR 2110
California CA 21198
> state[,"state.abb"] #输出state.abb这一列的具体元素
[1] "AL" "AK" "AZ" "AR" "CA" "CO" "CT" "DE" "FL" "GA" "HI"
[12] "ID" "IL" "IN" "IA" "KS" "KY" "LA" "ME" "MD" "MA" "MI"
[23] "MN" "MS" "MO" "MT" "NE" "NV" "NH" "NJ" "NM" "NY" "NC"
[34] "ND" "OH" "OK" "OR" "PA" "RI" "SC" "SD" "TN" "TX" "UT"
[45] "VT" "VA" "WA" "WV" "WI" "WY"
> state[,2] #效果等同于上一句
[1] "AL" "AK" "AZ" "AR" "CA" "CO" "CT" "DE" "FL" "GA" "HI"
[12] "ID" "IL" "IN" "IA" "KS" "KY" "LA" "ME" "MD" "MA" "MI"
[23] "MN" "MS" "MO" "MT" "NE" "NV" "NH" "NJ" "NM" "NY" "NC"
[34] "ND" "OH" "OK" "OR" "PA" "RI" "SC" "SD" "TN" "TX" "UT"
[45] "VT" "VA" "WA" "WV" "WI" "WY"
> state["Alabama",] #输出Alabama这一行的元素
state.name state.abb state.region Population Income
Alabama Alabama AL South 3615 3624
Illiteracy Life.Exp Murder HS.Grad Frost Area
Alabama 2.1 69.05 15.1 41.3 20 50708
> state$Murder #直接用$索引是更为快捷常用的方式
[1] 15.1 11.3 7.8 10.1 10.3 6.8 3.1 6.2 10.7 13.9 6.2
[12] 5.3 10.3 7.1 2.3 4.5 10.6 13.2 2.7 8.5 3.3 11.1
[23] 2.3 12.5 9.3 5.0 2.9 11.5 3.3 5.2 9.7 10.9 11.1
[34] 1.4 7.4 6.4 4.2 6.1 2.4 11.6 1.7 11.0 12.2 4.5
[45] 5.5 9.5 4.3 6.7 3.0 6.9
> women
height weight
1 58 115
2 59 117
3 60 120
4 61 123
5 62 126
6 63 129
7 64 132
8 65 135
9 66 139
10 67 142
11 68 146
12 69 150
13 70 154
14 71 159
15 72 164
> plot(women$height,women$weight) #这种简写对绘图非常有效
> lm(weight ~height,data = women) #使用lm函数求线性回归
Call:
lm(formula = weight ~ height, data = women)
Coefficients:
(Intercept) height
-87.52 3.45
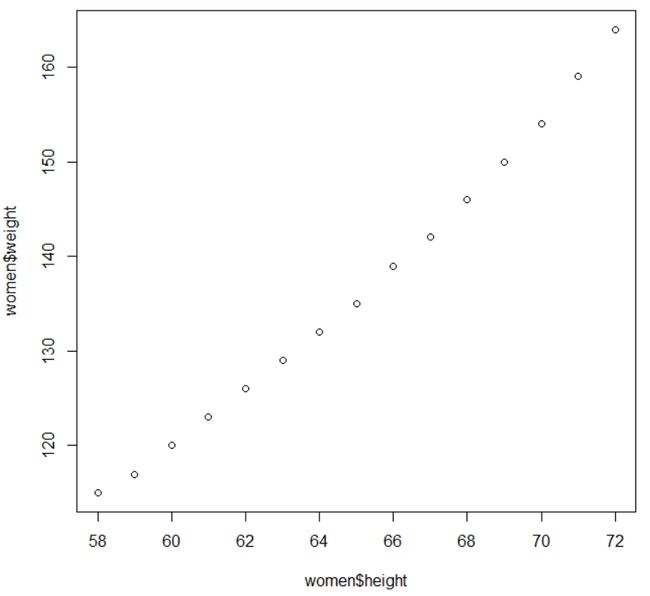
一次使用数据框的多列数据
如果一次要访问数据框的多列数据,每次使用美元符$比较麻烦,还有如下两种方法可供选择
> attach(mtcars) #加载数据框到R搜索目录中
> mpg #直接敲数据框列的名字而不需要使用$
[1] 21.0 21.0 22.8 21.4 18.7 18.1 14.3 24.4
[9] 22.8 19.2 17.8 16.4 17.3 15.2 10.4 10.4
[17] 14.7 32.4 30.4 33.9 21.5 15.5 15.2 13.3
[25] 19.2 27.3 26.0 30.4 15.8 19.7 15.0 21.4
> hp
[1] 110 110 93 110 175 105 245 62 95 123
[11] 123 180 180 180 205 215 230 66 52 65
[21] 97 150 150 245 175 66 91 113 264 175
[31] 335 109
> detach(mtcars) #使用完成后可调用detach函数取消加载
> hp
Error: object 'hp' not found
> with(mtcars,(mpg)) #with函数作用与attach相似
[1] 21.0 21.0 22.8 21.4 18.7 18.1 14.3 24.4
[9] 22.8 19.2 17.8 16.4 17.3 15.2 10.4 10.4
[17] 14.7 32.4 30.4 33.9 21.5 15.5 15.2 13.3
[25] 19.2 27.3 26.0 30.4 15.8 19.7 15.0 21.4
#也可以使用双中括号的方式访问,但返回的是向量
但一般用$查找列数据更加方便清晰
P23 因子
变量分类
- 名义型变量:城市,所属省份等 孟德尔实验中的豌豆性状
- 有序型变量:等级,定性(good/better/best)孟德尔实验中的豌豆数量(少中多)
- 连续型变量:身高,年龄等
因子:在R中名义型变量和有序型变量称为因子,factor。这些分类变量的可能值为一个水平,例如good,better,best,都称为一个level。
由这些水平构成的向量就称为因子。
因子的应用:计算频数/独立性检验/相关性检验/方差分析/主成分分析/因子分析
> mtcars$cyl #取出mtcars中气缸数cyl这一列,cyl这一列可作为因子类型,而因子的level就是4/6/8
[1] 6 6 4 6 8 6 8 4 4 6 6 8 8 8 8 8 8 4 4 4
[21] 4 8 8 8 8 4 4 4 8 6 8 4
> table(mtcars$cyl) #table函数计算频数统计
4 6 8
11 7 14
> table(mtcars$am) #am表示手档还是自动档
0 1
19 13
#名义型变量的因子示例
> f <- factor(c("red","red","blue","green","blue","green"))
> f
[1] red red blue green blue green
Levels: blue green red
#有序型变量的因子示例
> week <-factor(c("Mon","Tue","Wed","Thr","Fri","Sat","Sun")) #定义一个有序行变量week
> week #会出现level,但排序不是我们想要的
[1] Mon Tue Wed Thr Fri Sat Sun
Levels: Fri Mon Sat Sun Thr Tue Wed
> week <- factor(c("Mon","Tue","Wed","Thr","Fri","Sat","Sun"),ordered = T,levels = c( "Mon","Tue","Wed","Thr","Fri","Sat","Sun")) #手动定义level顺序
> week #按照定义排序输出
[1] Mon Tue Wed Thr Fri Sat Sun
7 Levels: Mon < Tue < Wed < Thr < ... < Sun
> fcly <- factor(mtcars$cyl) #从数据集中取出一个因子
> fcly
[1] 6 6 4 6 8 6 8 4 4 6 6 8 8 8 8 8 8 4 4 4
[21] 4 8 8 8 8 4 4 4 8 6 8 4
Levels: 4 6 8
> fcly <- mtcars$cyl
> fcly
[1] 6 6 4 6 8 6 8 4 4 6 6 8 8 8 8 8 8 4 4 4
[21] 4 8 8 8 8 4 4 4 8 6 8 4
> plot(mtcars$cyl) #散点图
> plot(factor(mtcars$cyl)) #柱状图

plot(mtcars c y l ) ∗ ∗ ∗ ∗ p l o t ( f a c t o r ( m t c a r s cyl)** **plot(factor(mtcars cyl)∗∗∗∗plot(factor(mtcarscyl))
另一种定义level的方式
> num <- c(1:100)
> num
[1] 1 2 3 4 5 6 7 8 9 10
[11] 11 12 13 14 15 16 17 18 19 20
[21] 21 22 23 24 25 26 27 28 29 30
[31] 31 32 33 34 35 36 37 38 39 40
[41] 41 42 43 44 45 46 47 48 49 50
[51] 51 52 53 54 55 56 57 58 59 60
[61] 61 62 63 64 65 66 67 68 69 70
[71] 71 72 73 74 75 76 77 78 79 80
[81] 81 82 83 84 85 86 87 88 89 90
[91] 91 92 93 94 95 96 97 98 99 100
> cut(num,c(seq(0,100,10))) #将num向量用cut函数分成(0,10] (10,20] ... (90,100]区间
[1] (0,10] (0,10] (0,10] (0,10]
[5] (0,10] (0,10] (0,10] (0,10]
[9] (0,10] (0,10] (10,20] (10,20]
[13] (10,20] (10,20] (10,20] (10,20]
[17] (10,20] (10,20] (10,20] (10,20]
[21] (20,30] (20,30] (20,30] (20,30]
[25] (20,30] (20,30] (20,30] (20,30]
[29] (20,30] (20,30] (30,40] (30,40]
[33] (30,40] (30,40] (30,40] (30,40]
[37] (30,40] (30,40] (30,40] (30,40]
[41] (40,50] (40,50] (40,50] (40,50]
[45] (40,50] (40,50] (40,50] (40,50]
[49] (40,50] (40,50] (50,60] (50,60]
[53] (50,60] (50,60] (50,60] (50,60]
[57] (50,60] (50,60] (50,60] (50,60]
[61] (60,70] (60,70] (60,70] (60,70]
[65] (60,70] (60,70] (60,70] (60,70]
[69] (60,70] (60,70] (70,80] (70,80]
[73] (70,80] (70,80] (70,80] (70,80]
[77] (70,80] (70,80] (70,80] (70,80]
[81] (80,90] (80,90] (80,90] (80,90]
[85] (80,90] (80,90] (80,90] (80,90]
[89] (80,90] (80,90] (90,100] (90,100]
[93] (90,100] (90,100] (90,100] (90,100]
[97] (90,100] (90,100] (90,100] (90,100]
10 Levels: (0,10] (10,20] ... (90,100]
P24 缺失数据
- 完全随机缺失
- 随机缺失
- 非随机缺失
为何会出现缺失数据?
1. 机器断电,设备故障导致某个测量值发生丢失。
2. 测量根本没有发生:例如在做问卷调查时,有些问题没有回答,或者有些问题是无效的回答等。
缺失值NA
R 中,NA代表缺失值,是不可用,not available的简称,用来存储缺失信息
这里的缺失值NA表示没有,但注意没有并不一定是0,NA是不知道是多少,也可能是0,也可能是任何值,缺失值和值为0是完全不同的
> 1+NA
[1] NA
> NA==0 #不知道T还是F,所以返回NA
[1] NA
> a <- c(NA,1:49)
> a
[1] NA 1 2 3 4 5 6 7 8 9 10 11 12
[14] 13 14 15 16 17 18 19 20 21 22 23 24 25
[27] 26 27 28 29 30 31 32 33 34 35 36 37 38
[40] 39 40 41 42 43 44 45 46 47 48 49
> sum(a) #缺失值存在时,在计算中会产生问题
[1] NA
> mean(a)
[1] NA
> ?sum
sum(..., na.rm = FALSE) #na.rm函数计算时跳过缺失值
> sum(a,na.rm=T)
[1] 1225
> mean(a,na.rm = T) #计算平均值时分母是否包含了NA在内的元素个数?
[1] 25
> mean(1:49) #验证得到NA是没被包含的
[1] 25
> is.na(a) #测试数据中是否包含NA,包含位置返回为TURE
[1] TRUE FALSE FALSE FALSE FALSE FALSE
[7] FALSE FALSE FALSE FALSE FALSE FALSE
[13] FALSE FALSE FALSE FALSE FALSE FALSE
[19] FALSE FALSE FALSE FALSE FALSE FALSE
[25] FALSE FALSE FALSE FALSE FALSE FALSE
[31] FALSE FALSE FALSE FALSE FALSE FALSE
[37] FALSE FALSE FALSE FALSE FALSE FALSE
[43] FALSE FALSE FALSE FALSE FALSE FALSE
[49] FALSE FALSE
> sleep
BodyWgt BrainWgt NonD Dream Sleep Span
1 6654.000 5712.00 NA NA 3.3 38.6
2 1.000 6.60 6.3 2.0 8.3 4.5
3 3.385 44.50 NA NA 12.5 14.0
4 0.920 5.70 NA NA 16.5 NA
Gest Pred Exp Danger
1 645.0 3 5 3
2 42.0 3 1 3
3 60.0 1 1 1
4 25.0 5 2 3
> is.na(sleep)
BodyWgt BrainWgt NonD Dream Sleep
[1,] FALSE FALSE TRUE TRUE FALSE
[2,] FALSE FALSE FALSE FALSE FALSE
[3,] FALSE FALSE TRUE TRUE FALSE
[4,] FALSE FALSE TRUE TRUE FALSE
Span Gest Pred Exp Danger
[1,] FALSE FALSE FALSE FALSE FALSE
[2,] FALSE FALSE FALSE FALSE FALSE
[3,] FALSE FALSE FALSE FALSE FALSE
[4,] TRUE FALSE FALSE FALSE FALSE
> rowSums(sleep) #计算行加和
[1] NA 77.700 NA NA
> colSums(sleep) #计算列加和
BodyWgt BrainWgt NonD Dream Sleep
12324.98 17554.32 NA NA NA
Span Gest Pred Exp Danger
NA NA 178.00 150.00 162.00
去除缺失值NA
> ?na.omit #删除缺失值
> c <- c(NA,1:20,NA,NA) #定义一个包含缺失值的向量
> c
[1] NA 1 2 3 4 5 6 7 8 9 10 11 12
[14] 13 14 15 16 17 18 19 20 NA NA
> d <- na.omit(c) #删除NA后赋值
> d
[1] 1 2 3 4 5 6 7 8 9 10 11 12 13
[14] 14 15 16 17 18 19 20
attr(,"na.action")
[1] 1 22 23
attr(,"class")
[1] "omit"
> is.na(d) #缺失值的部分被删除
[1] FALSE FALSE FALSE FALSE FALSE FALSE
[7] FALSE FALSE FALSE FALSE FALSE FALSE
[13] FALSE FALSE FALSE FALSE FALSE FALSE
[19] FALSE FALSE
> sum(d) #能够重新被计算
[1] 210
> mean(d)
[1] 10.5
> na.omit(sleep) #删除sleep数据集中包含NA的行
BodyWgt BrainWgt NonD Dream Sleep Span
2 1.000 6.60 6.3 2.0 8.3 4.5
5 2547.000 4603.00 2.1 1.8 3.9 69.0
6 10.550 179.50 9.1 0.7 9.8 27.0
7 0.023 0.30 15.8 3.9 19.7 19.0
8 160.000 169.00 5.2 1.0 6.2 30.4
9 3.300 25.60 10.9 3.6 14.5 28.0
10 52.160 440.00 8.3 1.4 9.7 50.0
11 0.425 6.40 11.0 1.5 12.5 7.0
12 465.000 423.00 3.2 0.7 3.9 30.0
15 0.075 1.20 6.3 2.1 8.4 3.5
16 3.000 25.00 8.6 0.0 8.6 50.0
17 0.785 3.50 6.6 4.1 10.7 6.0
18 0.200 5.00 9.5 1.2 10.7 10.4
22 27.660 115.00 3.3 0.5 3.8 20.0
23 0.120 1.00 11.0 3.4 14.4 3.9
25 85.000 325.00 4.7 1.5 6.2 41.0
27 0.101 4.00 10.4 3.4 13.8 9.0
28 1.040 5.50 7.4 0.8 8.2 7.6
29 521.000 655.00 2.1 0.8 2.9 46.0
32 0.005 0.14 7.7 1.4 9.1 2.6
33 0.010 0.25 17.9 2.0 19.9 24.0
34 62.000 1320.00 6.1 1.9 8.0 100.0
37 0.023 0.40 11.9 1.3 13.2 3.2
38 0.048 0.33 10.8 2.0 12.8 2.0
39 1.700 6.30 13.8 5.6 19.4 5.0
40 3.500 10.80 14.3 3.1 17.4 6.5
42 0.480 15.50 15.2 1.8 17.0 12.0
43 10.000 115.00 10.0 0.9 10.9 20.2
44 1.620 11.40 11.9 1.8 13.7 13.0
45 192.000 180.00 6.5 1.9 8.4 27.0
46 2.500 12.10 7.5 0.9 8.4 18.0
48 0.280 1.90 10.6 2.6 13.2 4.7
49 4.235 50.40 7.4 2.4 9.8 9.8
50 6.800 179.00 8.4 1.2 9.6 29.0
51 0.750 12.30 5.7 0.9 6.6 7.0
52 3.600 21.00 4.9 0.5 5.4 6.0
54 55.500 175.00 3.2 0.6 3.8 20.0
57 0.900 2.60 11.0 2.3 13.3 4.5
58 2.000 12.30 4.9 0.5 5.4 7.5
59 0.104 2.50 13.2 2.6 15.8 2.3
60 4.190 58.00 9.7 0.6 10.3 24.0
61 3.500 3.90 12.8 6.6 19.4 3.0
> length(rowSums(sleep)) #被删除NA行之前的行数
[1] 62
> length(rowSums(na.omit(sleep))) #含有NA的行全被删除,数据缺失严重
[1] 42
其他缺失值
- 缺失数据NaN,代表不可能的值;
- Inf表示无穷,分为正无穷Inf和负无穷Inf,代表无穷大或无穷小
不同缺失值之间的差别
- NA是存在的值,但是不知道是多少;
- NaN是不存在的;
- Inf存在,是无穷大或无穷小,但是表示不可能的值。
> 1/0
[1] Inf
> -1/0
[1] -Inf
> 0/0
[1] NaN
> is.nan(0/0)
[1] TRUE
> is.infinite(1/0)
[1] TRUE
P25 字符串
正则表达式
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-WaZUBC5y-1604480800330)(C:%5CUsers%5CZixin%20Liu%5CAppData%5CRoaming%5CTypora%5Ctypora-user-images%5Cimage-20201002151646472.png)]
统计字符串
> nchar("hello world") #用于统计字符串的字符数
[1] 11
> month.name
[1] "January" "February" "March"
[4] "April" "May" "June"
[7] "July" "August" "September"
[10] "October" "November" "December"
> nchar(month.name) #返回的是字符串数
[1] 7 8 5 5 3 4 4 6 9 7 8 8
> length(month.name) #返回的是元素个数
[1] 12
> nchar(c(2,13,123)) #对数值型向量进行字符串处理
[1] 1 2 3
> paste("Everbody","loves","stata") #合并字符串向量
[1] "Everbody loves stata"
> paste("Everbody","loves","stata",sep="-") #默认空格连接,也可用sep设置
[1] "Everbody-loves-stata"
> names <- c("Moe","Mary","David")
> paste(names,"love stars") #连接方式是元素和元素分别连接
[1] "Moe love stars" "Mary love stars"
[3] "David love stars"
> sentence <- c("loves stars","hate sun")
> paste(names,sentence) #如果元素个数不匹配,则按循环原则
[1] "Moe loves stars" "Mary hate sun"
[3] "David loves stars"
提取字符串
> month.name
[1] "January" "February" "March"
[4] "April" "May" "June"
[7] "July" "August" "September"
[10] "October" "November" "December"
> substr(x=month.name,start = 1,stop = 3) #参数(被提取字符串,起始字符位点,终止字符位点),从1开始
[1] "Jan" "Feb" "Mar" "Apr" "May" "Jun"
[7] "Jul" "Aug" "Sep" "Oct" "Nov" "Dec"
> temp <- substr(x=month.name,start = 1,stop = 3)
> toupper(temp) #字符全部大写
[1] "JAN" "FEB" "MAR" "APR" "MAY" "JUN"
[7] "JUL" "AUG" "SEP" "OCT" "NOV" "DEC"
> tolower(temp) #字符全部小写
[1] "jan" "feb" "mar" "apr" "may" "jun"
[7] "jul" "aug" "sep" "oct" "nov" "dec"
> ?sub #一次替换
> ?gsub #全局替换
> gsub("^(\\w)","\\U\\1",tolower(temp),perl = T) #perl中的正则表达式,首字母大写
[1] "Jan" "Feb" "Mar" "Apr" "May" "Jun"
[7] "Jul" "Aug" "Sep" "Oct" "Nov" "Dec"
> gsub("^(\\w)","\\L\\1",tolower(temp),perl = T) #全小写
[1] "jan" "feb" "mar" "apr" "may" "jun"
[7] "jul" "aug" "sep" "oct" "nov" "dec"
> gsub("^(\\w)","\\L\\1",toupper(temp),perl = T) #首字母小写
[1] "jAN" "fEB" "mAR" "aPR" "mAY" "jUN"
[7] "jUL" "aUG" "sEP" "oCT" "nOV" "dEC"
字符串匹配
> ?grep #在字符串中搜索某种模式,如果fixed=F则支持正则表达式,fixed=T则搜索模式为文本字符串,返回值为匹配的下标
> x <- c("b","A+","AC")
> x
[1] "b" "A+" "AC"
> grep("A+",x) #在向量x中寻找A+
[1] 2 3
> grep("A+",x,fixed = T)
[1] 2 #表示与向量中第二个元素匹配上了
> grep("A+",x,fixed = F) #+表示可以匹配1到正无穷个字符A,所以AC也满足条件
[1] 2 3
> ?match #同样用于查找匹配字符串
> match("AC",x)
[1] 3
分割字符串
> ?strsplit
> path <- "/user/local/bin/R"
> strsplit(path,"/") #返回的是列表而不是字符串,因为字符串中可以包含多个子串
[[1]]
[1] "" "user" "local" "bin" "R"
> strsplit(c(path,path),"/") #当分割多个向量时,以字符串的形式返回会更美观逻辑
[[1]]
[1] "" "user" "local" "bin" "R"
[[2]]
[1] "" "user" "local" "bin" "R"
字符串成对组合技巧——笛卡尔积
##有两个字符串向量,我们需要生成他俩组成的所有组合,这里可以用到笛卡尔积
> ?outer
> face <- 1:13
> suit <- c("spades","clubs","hearts","diamonds")
> face
[1] 1 2 3 4 5 6 7 8 9 10 11 12 13
> suit
[1] "spades" "clubs" "hearts"
[4] "diamonds"
> outer(suit,face,FUN = paste) #FUN后接一个函数,我们这里需要连接字符串所以用paste函数
[,1] [,2] [,3]
[1,] "spades 1" "spades 2" "spades 3"
[2,] "clubs 1" "clubs 2" "clubs 3"
[3,] "hearts 1" "hearts 2" "hearts 3"
[4,] "diamonds 1" "diamonds 2" "diamonds 3"
[,4] [,5] [,6]
[1,] "spades 4" "spades 5" "spades 6"
[2,] "clubs 4" "clubs 5" "clubs 6"
[3,] "hearts 4" "hearts 5" "hearts 6"
[4,] "diamonds 4" "diamonds 5" "diamonds 6"
[,7] [,8] [,9]
[1,] "spades 7" "spades 8" "spades 9"
[2,] "clubs 7" "clubs 8" "clubs 9"
[3,] "hearts 7" "hearts 8" "hearts 9"
[4,] "diamonds 7" "diamonds 8" "diamonds 9"
[,10] [,11]
[1,] "spades 10" "spades 11"
[2,] "clubs 10" "clubs 11"
[3,] "hearts 10" "hearts 11"
[4,] "diamonds 10" "diamonds 11"
[,12] [,13]
[1,] "spades 12" "spades 13"
[2,] "clubs 12" "clubs 13"
[3,] "hearts 12" "hearts 13"
[4,] "diamonds 12" "diamonds 13"
P26 日期和时间
时间序列分析
- 对时间序列的描述
- 利用前面的结果进行预测
> presidents
Qtr1 Qtr2 Qtr3 Qtr4
1945 NA 87 82 75
1946 63 50 43 32
1947 35 60 54 55
1948 36 39 NA NA
1949 69 57 57 51
1950 45 37 46 39
1951 36 24 32 23
1952 25 32 NA 32
1953 59 74 75 60
1954 71 61 71 57
1955 71 68 79 73
1956 76 71 67 75
1957 79 62 63 57
1958 60 49 48 52
1959 57 62 61 66
1960 71 62 61 57
1961 72 83 71 78
1962 79 71 62 74
1963 76 64 62 57
1964 80 73 69 69
1965 71 64 69 62
1966 63 46 56 44
1967 44 52 38 46
1968 36 49 35 44
1969 59 65 65 56
1970 66 53 61 52
1971 51 48 54 49
1972 49 61 NA NA
1973 68 44 40 27
1974 28 25 24 24
> class(presidents)
[1] "ts" #时间序列,time series(seq?)
> presidents$Qtr1 #无法提取,因为不是数据框格式
Error in presidents$Qtr1 : $ operator is invalid for atomic vectors
> airmiles #专门的时间序列格式示例,一般一个时间点对应一个数据
Time Series:
Start = 1937
End = 1960
Frequency = 1
[1] 412 480 683 1052 1385 1418
[7] 1634 2178 3362 5948 6109 5981
[13] 6753 8003 10566 12528 14760 16769
[19] 19819 22362 25340 25343 29269 30514
#时间序列中的时间点既可以时日期/年月日/小时/分钟秒
> Sys.Date() #查看当前系统时间
[1] "2020-10-03"
> class(Sys.Date())
[1] "Date"
> a <- "2020-10-03"
> as.Date(a)
[1] "2020-10-03"
> class(a)
[1] "character"
> as.Date(a,format = "%Y-%m-%d") # %Y为四位数年份;%y为年份;%m为两位数月份;%d为两位数日期
[1] "2020-10-03"
> class(as.Date(a,format = "%Y-%m-%d"))
[1] "Date"
> ?strftime #更多时间序列设置可参考这个函数
> seq(as.Date("2020-10-03"),as.Date("2020-10-08"),by=1) #设置时间间隔
[1] "2020-10-03" "2020-10-04"
[3] "2020-10-05" "2020-10-06"
[5] "2020-10-07" "2020-10-08"
> ?ts #设置成时间序列函数
> sales <- round(runif(48,min = 50,max = 100)) #随机生成50-100内的48个随机数,runif生成随机数,round取整数
> sales
[1] 77 76 84 81 65 53 77 93 96
[10] 60 75 99 83 70 72 90 76 90
[19] 86 98 60 92 87 53 75 59 63
[28] 88 100 64 61 86 98 94 57 99
[37] 61 64 59 59 72 54 99 86 92
[46] 71 86 90
> ts(sales,start = c(2010,5),end = c(2014,4),frequency = 1) #frequency设置成1为以年为单位,12以月份为单位,4以季度为单位,不存在以天为单位,一般时间序列中都不用“天”这个单位
Time Series:
Start = 2014
End = 2017
Frequency = 1
[1] 77 76 84 81
> ts(sales,start = c(2010,5),end = c(2014,4),frequency = 4)
Qtr1 Qtr2 Qtr3 Qtr4
2011 77 76 84 81
2012 65 53 77 93
2013 96 60 75 99
2014 83 70 72 90
> ts(sales,start = c(2010,5),end = c(2014,4),frequency = 12)
Jan Feb Mar Apr May Jun Jul Aug Sep
2010 77 76 84 81 65
2011 96 60 75 99 83 70 72 90 76
2012 60 92 87 53 75 59 63 88 100
2013 98 94 57 99 61 64 59 59 72
2014 92 71 86 90
Oct Nov Dec
2010 53 77 93
2011 90 86 98
2012 64 61 86
2013 54 99 86
2014
P26 常见错误
1. 定义向量时忘了加c
> x <- (1,2,3)
Error: unexpected ',' in "x <- (1,"
2. 连字符问题
> x <- c(1,2,3)
> x < -5 #尽量使用Alt + -直接生成,避免因为空格的加入而变成逻辑比较符
[1] FALSE FALSE FALSE
3. 括号问题
R中所有函数都要加括号与普通对象进行区分,对函数的所有操作都应在括号里面,尽量使用自动补齐功能避免括号漏掉
> x <- matrix(c(1:20,seq(1,12,3),4,4)
+ )
> x #缺少括号会出现加号
[,1]
[1,] 1
[2,] 2
[3,] 3
[4,] 4
[5,] 5
[6,] 6
[7,] 7
[8,] 8
[9,] 9
[10,] 10
[11,] 11
[12,] 12
[13,] 13
[14,] 14
[15,] 15
[16,] 16
[17,] 17
[18,] 18
[19,] 19
[20,] 20
[21,] 1
[22,] 4
[23,] 7
[24,] 10
[25,] 4
[26,] 4
> x <- matrix(c(1:20,seq(1,12,3),4),4) #补加括号时要注意位置
Warning message:
In matrix(c(1:20, seq(1, 12, 3), 4), 4) :
data length [25] is not a sub-multiple or multiple of the number of rows [4]
> x <- matrix(c(1:20,seq(1,12,3)),4,4)
> x
[,1] [,2] [,3] [,4]
[1,] 1 5 9 13
[2,] 2 6 10 14
[3,] 3 7 11 15
[4,] 4 8 12 16
3. 字符串的引号问题
- 字符串一定要加引号,且对数要正确
> x <- c(one,two,three,4,5)
Error: object 'one' not found
> x <- c("one","two","three",4,5)
> x
[1] "one" "two" "three" "4"
[5] "5"
- 加载R包的时候一定要加引号
> install.packages(gclus)
Error in install.packages : object 'gclus' not found
> install.packages("gclus")
trying URL 'https://cran.rstudio.com/bin/windows/contrib/4.0/gclus_1.3.2.zip'
Content type 'application/zip' length 416404 bytes (406 KB)
downloaded 406 KB
package ‘gclus’ successfully unpacked and MD5 sums checked
The downloaded binary packages are in
C:\Users\Zixin Liu\AppData\Local\Temp\RtmpEF3l31\downloaded_packages
4. 逗号问题
- 逗号和元素的对应关系
> x <- c(1,2,3,)
Error in c(1, 2, 3, ) : argument 4 is empty
> x <- c(1,2,3)
- 逗号在矩阵中的作用
> state.x77[1]
[1] 3615
> state.x77[1,]
Population Income Illiteracy
3615.00 3624.00 2.10
Life Exp Murder HS Grad
69.05 15.10 41.30
Frost Area
20.00 50708.00
> state.x77[,1]
Alabama Alaska
3615 365
Arizona Arkansas
2212 2110
California Colorado
21198 2541
Connecticut Delaware
3100 579
Florida Georgia
8277 4931
Hawaii Idaho
868 813
5. 等号问题
赋值是一个=,等于是两个==
> a=5
> b=8
> a==b
[1] FALSE
> a=b
> a
[1] 8
> b
[1] 8
> a==b
[1] TRUE
6. 路径问题
R中将反斜线/当作转义
> getwd()
[1] "D:/RData/Data Practice"
> setwd("D:\\RData\\Data Practice/") #用两个反斜线或一个正斜线
7. R扩展包问题
跟随老师视频演示时可能出现不一致状况,是因为未使用install.packages(“”)函数加载R包,包名一定记得加引号
8. 优先级问题
> x <- 1+2*3^4>5 || 15%%3>2
> x
[1] TRUE
#如果不确定优先级顺序,则多使用括号
9. 严格区分大小写
> help()
> HELP()
Error in HELP() : could not find function "HELP"
10. 学会看报错信息,擅用搜索引擎解决问题
P28 获取数据
R获取数据的三种途径:
- 利用键盘输入数据
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-4svCUl9W-1604480800333)(https://i.loli.net/2020/10/09/ZtnVg19oTGmS5sO.png)]
- 直接手动输入
> patientID <- c(1,2,3,4)
> admdate <- c("10/15/2009","11/01/2009","10/21/2009","10/28/2009")
> age <- c(25,34,28,52)
> status <- c("Poor","Improved","Excellent","Poor")
> data <- data.frame(patientID,admdate,age,diabetes,status)
> data
patientID admdate age diabetes status
1 1 10/15/2009 25 Type1 Poor
2 2 11/01/2009 34 Type2 Improved
3 3 10/21/2009 28 Type1 Excellent
4 4 10/28/2009 52 Type1 Poor
- 调用数据编辑器
> ?edit
> data2 <- data.frame(patientID=character(0),admdate=character(0),age=numeric(),diabetes=character(),status=character())
> data2 <- edit(data2) #会弹出一个编辑框,直接在表格里输入
> data2
patientID admdate age diabetes status
1 1 10/15/2009 25 Type1 Poor
2 2 NA
3 3 NA
4 4 NA
> fix(data2) #可使用fix函数直接修改保存
-
通过读取存储在外部文件上的数据
R几乎可以读取所有主流的数据文件格式,包括Excel,SPSS,SAS等软件的文件格式,可利用R扩展包读取
但为了有效的使用R进行统计,数据之前一般要经过python或者perl进行预处理
-
通过访问数据库系统来获取数据
-
R提供了多种面向数据库管理系统的接口,如SQL等
-
通过ODBC(Open Database Connectivity 开放数据库连接)访问数据库
-
加载RODBC包可以使R与通过RODBC连接的SQL数据库进行双向通信,不仅可以用R读取数据库的内容,也可以将R处理的结果写入数据库内
> install.packages("RODBC")
trying URL 'https://cran.rstudio.com/bin/windows/contrib/4.0/RODBC_1.3-17.zip'
Content type 'application/zip' length 878540 bytes (857 KB)
downloaded 857 KB
package ‘RODBC’ successfully unpacked and MD5 sums checked
The downloaded binary packages are in
C:\Users\Zixin Liu\AppData\Local\Temp\RtmpEF3l31\downloaded_packages
- 安装DPI包可以实现通过驱动程序连接至数据库 ,该包为不同的数据库提供了一种通用的语法,要使用某个数据库,需要下载其与DPI相连的包才能使用,这些包为数据库原始的驱动程序提供了API接口
P29 读取文件(一)
- 在工作目录下直接读取
> read.table("input.txt") #读取的文件一定要在工作目录下且需要加引号
Ozone Solar.R Wind Temp Month Day
1 41 190 7.4 67 5 1
2 36 118 8.0 72 5 2
3 12 149 12.6 74 5 3
4 18 313 11.5 62 5 4
5 NA NA 14.3 56 5 5
6 28 NA 14.9 66 5 6
7 23 299 8.6 65 5 7
8 19 99 13.8 59 5 8
9 8 19 20.1 61 5 9
10 NA 194 8.6 69 5 10
119 NA 153 5.7 88 8 27
120 76 203 9.7 97 8 28
121 118 225 2.3 94 8 29
145 23 14 9.2 71 9 22
146 36 139 10.3 81 9 23
147 7 49 10.3 69 9 24
148 14 20 16.6 63 9 25
149 30 193 6.9 70 9 26
150 NA 145 13.2 77 9 27
151 14 191 14.3 75 9 28
152 18 131 8.0 76 9 29
153 20 223 11.5 68 9 30
> x <- read.table("input.txt")
> head(x) #当文件表格太长时只显示头部,默认是6行
Ozone Solar.R Wind Temp Month Day
1 41 190 7.4 67 5 1
2 36 118 8.0 72 5 2
3 12 149 12.6 74 5 3
4 18 313 11.5 62 5 4
5 NA NA 14.3 56 5 5
6 28 NA 14.9 66 5 6
> tail(x) #只显示尾部
Ozone Solar.R Wind Temp Month Day
148 14 20 16.6 63 9 25
149 30 193 6.9 70 9 26
150 NA 145 13.2 77 9 27
151 14 191 14.3 75 9 28
152 18 131 8.0 76 9 29
153 20 223 11.5 68 9 30
> head(x,n=10) #可以手动修改显示行数
Ozone Solar.R Wind Temp Month Day
1 41 190 7.4 67 5 1
2 36 118 8.0 72 5 2
3 12 149 12.6 74 5 3
4 18 313 11.5 62 5 4
5 NA NA 14.3 56 5 5
6 28 NA 14.9 66 5 6
7 23 299 8.6 65 5 7
8 19 99 13.8 59 5 8
9 8 19 20.1 61 5 9
10 NA 194 8.6 69 5 10
- 读取需要分列的文件(分列符一般有“,” “空格” “-”等)
> x <- read.table("D:/RData/input.csv")
> x
V2
1 ,"mpg","cyl","disp","hp","drat","wt","qsec","vs","am","gear","carb"
2 ,21,6,160,110,3.9,2.62,16.46,0,1,4,4
3 ,21,6,160,110,3.9,2.875,17.02,0,1,4,4
4 ,22.8,4,108,93,3.85,2.32,18.61,1,1,4,1
5 ,21.4,6,258,110,3.08,3.215,19.44,1,0,3,1
6 ,18.7,8,360,175,3.15,3.44,17.02,0,0,3,2
7 ,18.1,6,225,105,2.76,3.46,20.22,1,0,3,1
8 ,14.3,8,360,245,3.21,3.57,15.84,0,0,3,4
9 ,24.4,4,146.7,62,3.69,3.19,20,1,0,4,2
10 ,22.8,4,140.8,95,3.92,3.15,22.9,1,0,4,2
11 ,19.2,6,167.6,123,3.92,3.44,18.3,1,0,4,4
12 ,17.8,6,167.6,123,3.92,3.44,18.9,1,0,4,4
13 ,16.4,8,275.8,180,3.07,4.07,17.4,0,0,3,3
14 ,17.3,8,275.8,180,3.07,3.73,17.6,0,0,3,3
##若直接读取则会因为逗号间隔未被分开而显得很乱,不好阅读
> x <- read.table("D:/RData/input.csv",sep=",") #可使用sep识别间隔符进行分列
> x
V1 V2 V3 V4 V5 V6 V7 V8 V9 V10 V11 V12
1 mpg cyl disp hp drat wt qsec vs am gear carb
2 Mazda RX4 21 6 160 110 3.9 2.62 16.46 0 1 4 4
3 Mazda RX4 Wag 21 6 160 110 3.9 2.875 17.02 0 1 4 4
4 Datsun 710 22.8 4 108 93 3.85 2.32 18.61 1 1 4 1
5 Hornet 4 Drive 21.4 6 258 110 3.08 3.215 19.44 1 0 3 1
6 Hornet Sportabout 18.7 8 360 175 3.15 3.44 17.02 0 0 3 2
7 Valiant 18.1 6 225 105 2.76 3.46 20.22 1 0 3 1
8 Duster 360 14.3 8 360 245 3.21 3.57 15.84 0 0 3 4
# Windows系统下直接用记事本打开要导入的数据文件可找到间隔符
#`header`函数的作用是是否将数据表格第一行的字符设置为变量名称,而不是当成具体的值来处理
> x <- read.table("D:/RData/input.csv",sep=",",header = TRUE)
> head(x)
X mpg cyl disp hp drat wt qsec vs am gear carb
1 Mazda RX4 21.0 6 160 110 3.90 2.620 16.46 0 1 4 4
2 Mazda RX4 Wag 21.0 6 160 110 3.90 2.875 17.02 0 1 4 4
3 Datsun 710 22.8 4 108 93 3.85 2.320 18.61 1 1 4 1
4 Hornet 4 Drive 21.4 6 258 110 3.08 3.215 19.44 1 0 3 1
5 Hornet Sportabout 18.7 8 360 175 3.15 3.440 17.02 0 0 3 2
6 Valiant 18.1 6 225 105 2.76 3.460 20.22 1 0 3 1
##跳过不想读取的数据使用`skip`函数
> x <- read.table("D:/RData/input 1.txt",sep=" ",header = TRUE,skip = 5) #从第6行开始读取
> x
Ozone Solar.R Wind Temp Month Day
1 41 190 7.4 67 5 1
2 36 118 8.0 72 5 2
3 12 149 12.6 74 5 3
4 18 313 11.5 62 5 4
5 NA NA 14.3 56 5 5
6 28 NA 14.9 66 5 6
7 23 299 8.6 65 5 7
8 19 99 13.8 59 5 8
## skip控制从哪开始读,nrow控制读多少行,组合使用可以读取数据中任何部分
> x <- read.table("D:/RData/input 1.txt",sep=" ",header = TRUE,skip = 50,nrows = 5)
> x
X45 NA. X332 X13.8 X80 X6 X14
1 46 NA 322 11.5 79 6 15
2 47 21 191 14.9 77 6 16
3 48 37 284 20.7 72 6 17
4 49 20 37 9.2 65 6 18
5 50 12 120 11.5 73 6 19
- 使用
na.string函数将原始数据中用于表示缺失值的其他符号为NA stringAsFactors控制读入字符串是否转化为因子:在R中会将数字识别成数值型格式,将字符串转换成因子类型,如果不需要时可以用该函数设置成FALSE>?read.table的帮助说明还有其他可以读取的格式供查阅(如csv【默认用逗号,分割】/delim【默认用制表符分隔】等)
P30 读取文件(二)
- 读取在线的文件
> x <- read.table("www.网址.com",sep=" ",header = TRUE)
##这里必须是可供下载的网址,如果是嵌入网页中的表格,那么应该是读取html文件
- 如何读取非文本文件
网页中一般包含大量内容,可以使用grep和gsub等函数进行筛选
#如果只读取网页中的表格数据,可使用`which`函数
>readHTMLTable("https://en.wikipedia.org/wiki/World_population",which=3) #读取该网页的第三个表格
Error in (function (classes, fdef, mtable) :
unable to find an inherited method for function ‘readHTMLTable’ for signature ‘"NULL"’
In addition: Warning message:
XML content does not seem to be XML: ''
# 网页的表格格式不一定能被正确读取出来
- 读取统计软件格式的文件
> help(package="foreign")
#包含如下多种格式,read是读取,write是写入
data.restore Read an S3 Binary or data.dump File
lookup.xport Lookup Information on a SAS XPORT Format Library
read.arff Read Data from ARFF Files
read.dbf Read a DBF File
read.dta Read Stata Binary Files
read.epiinfo Read Epi Info Data Files
read.mtp Read a Minitab Portable Worksheet
read.octave Read Octave Text Data Files
read.S Read an S3 Binary or data.dump File
read.spss Read an SPSS Data File
read.ssd Obtain a Data Frame from a SAS Permanent Dataset, via read.xport
read.systat Obtain a Data Frame from a Systat File
read.xport Read a SAS XPORT Format Library
write.arff Write Data into ARFF Files
write.dbf Write a DBF File
write.dta Write Files in Stata Binary Format
write.foreign Write Text Files and Code to Read Them
##若上述格式中仍然没有匹配的,可以另存为文本文档进行读取,或搜索相匹配的R包
> RSiteSearch("Matlab")
檢索查詢疑問已被提交给http://search.r-project.org
计算结果应很快就在瀏覽器里打开
- 直接从粘贴板复制读取
> readClipboard() #可直接复制后输入该函数
[1] "排名\t城市别\t所属省\t金额(亿元)\t增长率\t人口(万)"
[2] "1\t上海\t直辖市\t25300\t6.80%\t2425.00 "
[3] "2\t北京\t直辖市\t23000\t6.70%\t2168.00 "
[4] "3\t广州\t广东省\t18100\t8.30%\t1667.00 "
[5] "4\t深圳\t广东省\t17500\t8.90%\t1077.00 "
[6] "5\t天津\t直辖市\t17200\t9.40%\t1516.00 "
[7] "6\t重庆\t直辖市\t16100\t11.00%\t3001.00 "
> x <- read.table("clipboard",header = T,sep = "\t")
> x
排名 城市别 所属省 金额.亿元. 增长率 人口.万.
1 1 上海 直辖市 25300 6.80% 2425
2 2 北京 直辖市 23000 6.70% 2168
3 3 广州 广东省 18100 8.30% 1667
4 4 深圳 广东省 17500 8.90% 1077
5 5 天津 直辖市 17200 9.40% 1516
6 6 重庆 直辖市 16100 11.00% 3001
- 直接读取压缩文件
> read.table(gzfile("input.txt.gz")) #gzfile不用解压缩可直接读取
X mpg cyl disp hp drat wt qsec vs am gear carb
1 Mazda RX4 21.0 6 160.0 110 3.90 2.620 16.46 0 1 4 4
2 Mazda RX4 Wag 21.0 6 160.0 110 3.90 2.875 17.02 0 1 4 4
3 Datsun 710 22.8 4 108.0 93 3.85 2.320 18.61 1 1 4 1
##注意读取的文件得在工作目录下
- 读取不规则的文件
> ?readline #可以基于每一行甚至每一单元读取文件
> readLines("input.csv",n=5) #n限制读入的最大行数
[1] "\"\",\"mpg\",\"cyl\",\"disp\",\"hp\",\"drat\",\"wt\",\"qsec\",\"vs\",\"am\",\"gear\",\"carb\""
[2] "\"Mazda RX4\",21,6,160,110,3.9,2.62,16.46,0,1,4,4"
[3] "\"Mazda RX4 Wag\",21,6,160,110,3.9,2.875,17.02,0,1,4,4"
[4] "\"Datsun 710\",22.8,4,108,93,3.85,2.32,18.61,1,1,4,1"
[5] "\"Hornet 4 Drive\",21.4,6,258,110,3.08,3.215,19.44,1,0,3,1"
> ?scan #每次读取一个单元,并根据指令处理;第一个参数为文件地址,第二个参数“what”用来描述scan所希望描述的文件单元;scan可重复执行制定模式,直到读取所有需要数据
> scan("scan.txt",what = list(character(3),numeric(0),numeric(0))) #表示读取每一行头3个字符串元素,然后再读取一个数值,然后再读取另外一个数值,两个numeric交替处理,0表示直到行尾
Read 20 records
[[1]]
[1] "one" "four" "one" "four" "one" "four"
[7] "one" "four" "one" "four" "one" "four"
[13] "one" "four" "one" "four" "one" "four"
[19] "one" "four"
[[2]]
[1] 2 5 2 5 2 5 2 5 2 5 2 5 2 5 2 5 2 5 2 5
[[3]]
[1] 3 6 3 6 3 6 3 6 3 6 3 6 3 6 3 6 3 6 3 6
> scan("scan.txt",what = list(X1=character(3),X2=numeric(2),X3=numeric(2))) #给变量命名
Read 20 records
$X1
[1] "one" "four" "one" "four" "one" "four"
[7] "one" "four" "one" "four" "one" "four"
[13] "one" "four" "one" "four" "one" "four"
[19] "one" "four"
$X2
[1] 2 5 2 5 2 5 2 5 2 5 2 5 2 5 2 5 2 5 2 5
$X3
[1] 3 6 3 6 3 6 3 6 3 6 3 6 3 6 3 6 3 6 3 6
scan读取的示例文件如下图
P31 写入文件
- 文件写入与格式转换
> ?write #与read系列函数相对应,存储为纯文本文件
> x <- rivers
> cat(x) #Concatenate and Print,连接和打印
735 320 325 392 524 450 1459 135 465 600 330 336 280 315 870 906 202 329 290 1000 600 505 1450 840 1243 890 350 407 286 280 525 720 390 250 327 230 265 850 210 630 260 230 360 730 600 306 390 420 291 710 340 217 281 352 259 250 470 680 570 350 300 560 900 625 332 2348 1171 3710 2315 2533 780 280 410 460 260 255 431 350 760 618 338 981 1306 500 696 605 250 411 1054 735 233 435 490 310 460 383 375 1270 545 445 1885 380 300 380 377 425 276 210 800 420 350 360 538 1100 1205 314 237 610 360 540 1038 424 310 300 444 301 268 620 215 652 900 525 246 360 529 500 720 270 430 671 1770
> write(x,file="x.txt") #会在工作目录下生成对应文件
> getwd() #当前工作目录
[1] "D:/RData"
## 可以在写入文件时添加完整的路径目录名,但必须是已存在的目录,R不会创建新目录
> ?write.table #数据框使用该函数
> ?write.csv #存为csv格式文件
#文件格式的转换
> read.table("input.txt",header = TRUE)
Ozone Solar.R Wind Temp Month Day
1 41 190 7.4 67 5 1
2 36 118 8.0 72 5 2
3 12 149 12.6 74 5 3
4 18 313 11.5 62 5 4
5 NA NA 14.3 56 5 5
……
151 14 191 14.3 75 9 28
152 18 131 8.0 76 9 29
153 20 223 11.5 68 9 30
> write.table(x,file = "D:/RData/Data Practice/newfile.txt")
> write.table (x,file=newfile.csv,sep="\t") #设置分隔符
-
R写入文件首列序号(行号)的删除
用R进行数据写入时,会在头一列自动生成顺序编号(行号),再读写一次则又会多一行行号,反复读写则会多次添加带来不便,可使用如下方法解决
##使用row.names函数
> write.table(x,file = "D:/RData/Data Practice/newfile.txt",row.names = FALSE)
##使用负索引
-
R写入文件双引号的删除
R写入文件时字符串向量会默认添加双引号,如果不想要可使用
quote = FALSE函数删除 -
缺失值NA代替
缺失值默认用NA代替,可使用
na="NA"调整缺失值的显示 -
同名文件的覆盖与添加
如果目录下存在同名文件,R写入时会直接覆盖(没有提示),如果不想覆盖而是继续添加可使用
append=TURE添加到原文件结尾,append=FALSE则是清空原文件 -
写入压缩文件
> write.table(mtcars,gzfile("newfile.txt.gz"))
##文件名记得加上对应的压缩格式
-
写入或读取其他格式文件
R更多支持的文件格式查看
> help(package="foreign")
P32 读写Excel文件
- 使用
read函数读取csv格式文件(方便,无需配置环境,但一次只能处理一个sheet) - 在Excel中复制后,使用剪切板
readClipboard()读取,或者使用> read.table("clipboard",header = T,sep = "\t")读取 - 加载openxlsx`R包直接读取
> install.packages("openxlsx")
also installing the dependencies ‘zip’, ‘stringi’
……
The downloaded binary packages are in
C:\Users\Lin\AppData\Local\Temp\RtmpgFVKJE\downloaded_packages
> library(openxlsx)
> cars32 <- read.xlsx("mtcars.xlsx")
> cars32
X1 mpg cyl disp hp drat wt qsec vs am gear carb
1 Mazda RX4 21.0 6 160.0 110 3.90 2.620 16.46 0 1 4 4
2 Mazda RX4 Wag 21.0 6 160.0 110 3.90 2.875 17.02 0 1 4 4
3 Datsun 710 22.8 4 108.0 93 3.85 2.320 18.61 1 1 4 1
- 配置java环境后,可使用
XLConnect这个R包或者xlsx这个R包进行读写
install.packages("XLConnect")
library(XLConnect)
?loadWorkbook
#Two step Read Excel File
ex <- loadWorkbook ("data.xlsx")
edata <- readWorksheet(ex,1)
head(edata)
edata <- readWorksheet(ex,1,startRow=0,starCol=0,endRow=50,endCol=3)
#One step Read Excel File
readWorksheetFromFile ("data.xlsx",1,startRow=0,starCol=0,
endRow=50,endCol=3,header=TRUE)
#Four step Wtire Excel File
wb <- loadWorkbook("file.xlsx",create=TRUE)
createSheet(wb,"Sheet 1")
writeWorksheet(wb,data=mtcars,sheet = "Sheet 1")
saveWorkbook()
#One step Wtire Excel File
writeWorksheetToFile("file.xlsx",data = mtcars,sheet = "Sheet 1")
vignette("XLConnect")
#Packages xlsx
install.packages("xlsx")
library(xlsx)
rdata <- read.xlsx("data.xlsx",n=1,startRow = 1,endRow = 100)
write.xlsx(rdata,file = "rdata.xlsx",sheetName = "Sheet 1",append = F)
help(package="xlsx")
P33 读写R格式文件
- .RDS(单个R对象)和.RDATA(多个R对象)
- 优势:R会对存储为内部文件格式的数据进行自动压缩处理,并且会存储所有与待存储对象相关的R元数据。如果数据中包含了因子,日期和时间或者类的属性等信息
- 劣势:只能在R中打开,共享者也许安装R软件
## 存储RDS格式文件
> head(iris)
Sepal.Length Sepal.Width Petal.Length Petal.Width Species
1 5.1 3.5 1.4 0.2 setosa
2 4.9 3.0 1.4 0.2 setosa
3 4.7 3.2 1.3 0.2 setosa
4 4.6 3.1 1.5 0.2 setosa
5 5.0 3.6 1.4 0.2 setosa
6 5.4 3.9 1.7 0.4 setosa
> saveRDS(iris,file = "iris.RDS")
> x <- readRDS("iris.RDS")
> x
Sepal.Length Sepal.Width Petal.Length Petal.Width Species
1 5.1 3.5 1.4 0.2 setosa
2 4.9 3.0 1.4 0.2 setosa
3 4.7 3.2 1.3 0.2 setosa
4 4.6 3.1 1.5 0.2 setosa
5 5.0 3.6 1.4 0.2 setosa
6 5.4 3.9 1.7 0.4 setosa
- .RDATA文件类似于PS里的.psd文件,保存着项目进度,能保存所有对象但无法保存绘制出来的图形 ,图形另存可参见 图片另存
- 加载.RDATA文件的方法
- 直接双击文件打开
- 从RStudio的project处引入(使用RStudio的project可另存为包含形式更为丰富的文件)
- 使用如
load(file = "C:/Users/wangtong/Desktop/RData/Ch02.R")函数直接打开,但注意:如果在已有工作簿中打开,之前已有的对象如果和即将要加载进来的对象出现重复,load函数不会做区分,建议先查看右上角的环境窗口查找已有变量
- 保存多个对象示例
save(iris,iris3,file = "iris.Rdata"),默认存于当前工作目录 - 保存当前工作空间中所有对象可使用
save.image()
P34 数据转换(一)
利用R进行数据分析的核心部分,分析更多的交给已有的R包或者代码,最关键的就是原始数据的处理,主要包括数据结构的变化:添加/删除/修改/排序等操作。Excel分析靠鼠标,R靠代码指令。
矩阵转换为数据框
> install.packages("openxlsx")
……
> library(openxlsx)
> cars32 <- read.xlsx("mtcars.xlsx")
> cars32
X1 mpg cyl disp hp drat wt qsec vs am gear carb
1 Mazda RX4 21.0 6 160.0 110 3.90 2.620 16.46 0 1 4 4
2 Mazda RX4 Wag 21.0 6 160.0 110 3.90 2.875 17.02 0 1 4 4
3 Datsun 710 22.8 4 108.0 93 3.85 2.320 18.61 1 1 4 1
4 Hornet 4 Drive 21.4 6 258.0 110 3.08 3.215 19.44 1 0 3 1
5 Hornet Sportabout 18.7 8 360.0 175 3.15 3.440 17.02 0 0 3 2
6 Valiant 18.1 6 225.0 105 2.76 3.460 20.22 1 0 3 1
> is.data.frame(cars32) #判断是否为数据框类型,同时is函数还可判断其他多种类型数据
[1] TRUE
> is.data.frame(state.x77)
[1] FALSE
> dstate.x77 <- as.data.frame(state.x77) #使用as函数进行矩阵到数据框的强制转换
> is.data.frame(dstate.x77)
[1] TRUE
数据框转换为矩阵
数据框转换成矩阵麻烦一些,因为矩阵只能是同为数值型或同为字符串型的数据,数据框没有该限制
> data.frame(state.region,state.x77) #创建一个包含数值和字符串类型的数据框
state.region Population Income Illiteracy Life.Exp Murder HS.Grad Frost Area
Alabama South 3615 3624 2.1 69.05 15.1 41.3 20 50708
Alaska West 365 6315 1.5 69.31 11.3 66.7 152 566432
Arizona West 2212 4530 1.8 70.55 7.8 58.1 15 113417
Arkansas South 2110 3378 1.9 70.66 10.1 39.9 65 51945
> as.matrix(data.frame(state.region,state.x77)) #强制转换为矩阵,则都被转换为字符串类型
state.region Population Income Illiteracy Life.Exp Murder HS.Grad Frost Area
Alabama "South" " 3615" "3624" "2.1" "69.05" "15.1" "41.3" " 20" " 50708"
Alaska "West" " 365" "6315" "1.5" "69.31" "11.3" "66.7" "152" "566432"
Arizona "West" " 2212" "4530" "1.8" "70.55" " 7.8" "58.1" " 15" "113417"
Arkansas "South" " 2110" "3378" "1.9" "70.66" "10.1" "39.9" " 65" " 51945"
is判断类型和as转换类型
> methods(is)
[1] is.array is.atomic
[3] is.call is.character
[5] is.complex is.data.frame
[7] is.double is.element
[9] is.empty.model is.environment
[11] is.expression is.factor
[13] is.finite is.function
[15] is.infinite is.integer
[17] is.language is.leaf
[19] is.list is.loaded
[21] is.logical is.matrix
[23] is.mts is.na
[25] is.na.data.frame is.na.numeric_version
[27] is.na.POSIXlt is.na<-
[29] is.na<-.default is.na<-.factor
[31] is.na<-.numeric_version is.name
[33] is.nan is.null
[35] is.numeric is.numeric.Date
[37] is.numeric.difftime is.numeric.POSIXt
[39] is.numeric_version is.object
[41] is.ordered is.package_version
[43] is.pairlist is.primitive
[45] is.qr is.R
[47] is.raster is.raw
[49] is.recursive is.relistable
[51] is.single is.stepfun
[53] is.symbol is.table
[55] is.ts is.tskernel
[57] is.unsorted is.vector
see '?methods' for accessing help and source code
> methods(as)
[1] as.array as.array.default as.call as.character as.character.condition
[6] as.character.Date as.character.default as.character.error as.character.factor as.character.hexmode
[11] as.character.numeric_version as.character.octmode as.character.POSIXt as.character.srcref as.complex
[16] as.data.frame as.data.frame.array as.data.frame.AsIs as.data.frame.character as.data.frame.complex
[21] as.data.frame.data.frame as.data.frame.Date as.data.frame.default as.data.frame.difftime as.data.frame.factor
[26] as.data.frame.integer as.data.frame.list as.data.frame.logical as.data.frame.matrix as.data.frame.model.matrix
[31] as.data.frame.noquote as.data.frame.numeric as.data.frame.numeric_version as.data.frame.ordered as.data.frame.POSIXct
[36] as.data.frame.POSIXlt as.data.frame.raw as.data.frame.table as.data.frame.ts as.data.frame.vector
[41] as.Date as.Date.character as.Date.default as.Date.factor as.Date.numeric
[46] as.Date.POSIXct as.Date.POSIXlt as.dendrogram as.difftime as.dist
[51] as.double as.double.difftime as.double.POSIXlt as.environment as.expression
[56] as.expression.default as.factor as.formula as.function as.function.default
[61] as.graphicsAnnot as.hclust as.hexmode as.integer as.list
[66] as.list.data.frame as.list.Date as.list.default as.list.difftime as.list.environment
[71] as.list.factor as.list.function as.list.numeric_version as.list.POSIXct as.list.POSIXlt
[76] as.logical as.logical.factor as.matrix as.matrix.data.frame as.matrix.default
[81] as.matrix.noquote as.matrix.POSIXlt as.name as.null as.null.default
[86] as.numeric as.numeric_version as.octmode as.ordered as.package_version
[91] as.pairlist as.person as.personList as.POSIXct as.POSIXct.Date
[96] as.POSIXct.default as.POSIXct.numeric as.POSIXct.POSIXlt as.POSIXlt as.POSIXlt.character
[101] as.POSIXlt.Date as.POSIXlt.default as.POSIXlt.factor as.POSIXlt.numeric as.POSIXlt.POSIXct
[106] as.qr as.raster as.raw as.relistable as.roman
[111] as.single as.single.default as.stepfun as.symbol as.table
[116] as.table.default as.ts as.vector as.vector.factor
see '?methods' for accessing help and source code
向量转换为其他类型
> x <- state.abb #创建一个字符串类型的向量
> x
[1] "AL" "AK" "AZ" "AR" "CA" "CO" "CT" "DE" "FL" "GA" "HI"
[12] "ID" "IL" "IN" "IA" "KS" "KY" "LA" "ME" "MD" "MA" "MI"
[23] "MN" "MS" "MO" "MT" "NE" "NV" "NH" "NJ" "NM" "NY" "NC"
[34] "ND" "OH" "OK" "OR" "PA" "RI" "SC" "SD" "TN" "TX" "UT"
[45] "VT" "VA" "WA" "WV" "WI" "WY"
> dim(x) <- c(5,10) #定义一个二维空间变成一个5行10列的矩阵
> x
[,1] [,2] [,3] [,4] [,5] [,6] [,7] [,8] [,9] [,10]
[1,] "AL" "CO" "HI" "KS" "MA" "MT" "NM" "OK" "SD" "VA"
[2,] "AK" "CT" "ID" "KY" "MI" "NE" "NY" "OR" "TN" "WA"
[3,] "AZ" "DE" "IL" "LA" "MN" "NV" "NC" "PA" "TX" "WV"
[4,] "AR" "FL" "IN" "ME" "MS" "NH" "ND" "RI" "UT" "WI"
[5,] "CA" "GA" "IA" "MD" "MO" "NJ" "OH" "SC" "VT" "WY"
> x <- state.abb
> as.factor(x) #变成因子类型
[1] AL AK AZ AR CA CO CT DE FL GA HI ID IL IN IA KS KY LA ME
[20] MD MA MI MN MS MO MT NE NV NH NJ NM NY NC ND OH OK OR PA
[39] RI SC SD TN TX UT VT VA WA WV WI WY
50 Levels: AK AL AR AZ CA CO CT DE FL GA HI IA ID IL ... WY
> as.list(x) #转换成列表
[[1]]
[1] "AL"
[[2]]
[1] "AK"
[[3]]
[1] "AZ"
[[4]]
[1] "AR"
> class(state.region)
[1] "factor"
> class(state.x77)
[1] "matrix" "array"
> class(x)
[1] "character"
> state <- data.frame(x,state.region,state.x77) #创建一个包含多种数据类型的数据框
> state$Income #提取出某一列的值
[1] 3624 6315 4530 3378 5114 4884 5348 4809 4815 4091 4963
[12] 4119 5107 4458 4628 4669 3712 3545 3694 5299 4755 4751
[23] 4675 3098 4254 4347 4508 5149 4281 5237 3601 4903 3875
[34] 5087 4561 3983 4660 4449 4558 3635 4167 3821 4188 4022
[45] 3907 4701 4864 3617 4468 4566
> state["Nevada",] #提取出具体某一行,一定记得加逗号,!!!!
x state.region Population Income Illiteracy Life.Exp Murder HS.Grad Frost Area
Nevada NV West 590 5149 0.5 69.03 11.5 65.2 188 109889
> is.data.frame(state["Nevada",]) #每一行提取出来也是单独的数据框,且包含列名
[1] TRUE
> y <- state["Nevada",]
> unname(y) #去除列名
Nevada NV West 590 5149 0.5 69.03 11.5 65.2 188 109889
> unlist(y) #适用于将列表结构转换成向量
x state.region Population Income Illiteracy Life.Exp Murder HS.Grad Frost Area
"NV" "4" "590" "5149" "0.5" "69.03" "11.5" "65.2" "188" "109889"
> class(unlist(y))
[1] "character"
> as.vector(y) #强制转换成向量,元素所有原本属性都被删除
x state.region Population Income Illiteracy Life.Exp Murder HS.Grad Frost Area
Nevada NV West 590 5149 0.5 69.03 11.5 65.2 188 109889
> class(as.vector(y))
[1] "data.frame"
P35 数据转换(二)
取子集
##连续提取
> who <- read.csv("WHO.csv",header = T) #引入示例里一个世卫组织的表格
> head(who) #头六行,列数多省略,可在右上角环境窗口中查看
> who1 <- who[c(1:50),c(1:10)] #取出1到50行和1到10列
> who1 #当控制台内因数据框太大不便显示时,可查看右上角环境窗口,点击对应目标会在左上角新选项卡页面显示
##不连续提取
> who2 <- who[c(1,3,5,8),c(2,14,16,18)]
> View(who2) #右上角点击后会显示的命令
##逻辑值提取
> who$Continent #取出WHO表格中大洲这一行的数据
[1] 1 2 3 2 3 4 5 2 6 2 2 4 1 7 4 2 2 5 3 4 7 5 2 3 5 6 2 3
[29] 3 7 3 4 1 3 3 5 7 5 3 3 3 6 5 3 2 5 2 2 2 1 5 5 5 1 5 3
[57] 3 2 3 6 2 2 6 3 3 2 2 3 2 5 5 3 3 5 5 5 6 2 2 7 6 1 1 2
[85] 1 2 5 6 1 2 3 6 6 6 1 2 6 2 3 3 3 1 2 2 6 2 3 3 6 7 3 1
[113] 6 3 3 4 6 2 2 6 2 1 3 6 3 6 7 2 5 6 6 5 3 3 6 2 1 7 6 5
[141] 6 5 5 6 2 2 5 1 2 2 3 5 5 5 6 2 3 1 3 2 3 3 6 2 2 6 3 3
[169] 2 7 3 5 3 2 2 1 6 2 3 6 6 3 6 5 1 2 2 6 3 2 1 2 4 5 2 6
[197] 5 6 1 1 3 3
> who3 <- who[which(who$Continent==7),] #取出符合Continent值为7的所有行,右上角显示
> who3 #
> who4 <- who[which(who$CountryID>50 & who$CountryID<=100),] #取CountryID大于50小于100的行列值,此处注意布尔符与数字之间不要有空格,闭合端加等号=,记得加逗号区分行列!!!
> ?subset #更为方便的取子集函数
> who4 <- subset(who,who$CountryID>50 & who$CountryID<=100)
> who4
##随机抽样函数,有放回或无放回
> ?sample
> x <- 1:100
> sample(x,30) #无放回的随机抽30个数
[1] 14 55 65 40 83 71 96 45 21 77 97 28 98 18
[15] 93 31 85 88 74 20 100 9 48 2 89 26 86 80
[29] 30 52
> sample(x,60,replace = T) #有放回的抽60个数
[1] 50 3 98 54 45 69 49 30 42 74 79 82 90 42 9 90 53 36 76
[20] 84 73 2 29 43 24 83 91 47 22 68 47 31 30 83 26 45 15 42
[39] 37 8 7 76 34 78 37 13 8 94 57 46 94 86 89 89 19 51 23
[58] 93 79 74
> sort(sample(x,60,replace = T)) #从小到大进行排序,有重复数字,与上面结果不一样是因为这一次又进行了一次随机抽取
[1] 5 6 8 10 13 13 14 18 18 21 23 25 25 26 28 29 30 34 34
[20] 34 35 37 37 38 39 39 39 44 49 51 51 51 56 56 58 62 62 63
[39] 64 68 70 72 73 74 74 75 76 77 78 78 80 81 83 86 89 90 94
[58] 94 97 97
##用sample对数据框进行抽样
> sample(who$CountryID,30,replace = F)
[1] 146 74 12 161 11 30 55 177 21 44 70 50 138 156
[15] 88 149 142 145 28 173 102 175 162 59 34 99 31 29
[29] 92 126
> who[sample(who$CountryID,30,replace = F),] #随机取子集
删除固定行的数据
##使用负索引的方式
> mtcars[-1:-5,] #删除mtcars数据集中前5行,逗号在后删除行,逗号在前删除列,不加逗号默认为删除列
> mtcars$wt <- NULL #清空该行(列)的数据
> mtcars
mpg cyl disp hp drat qsec vs am gear
Mazda RX4 21.0 6 160.0 110 3.90 16.46 0 1 4
Mazda RX4 Wag 21.0 6 160.0 110 3.90 17.02 0 1 4
数据框的添加与合并
> USArrests #美国50个州犯罪率的数据框
Murder Assault UrbanPop Rape
Alabama 13.2 236 58 21.2
Alaska 10.0 263 48 44.5
Arizona 8.1 294 80 31.0
Arkansas 8.8 190 50 19.5
California 9.0 276 91 40.6
……
> state.division #美国50个州的分区数据框(相当于我国的东北/华北/华中/华南等)
[1] East South Central Pacific Mountain
[4] West South Central Pacific Mountain
[7] New England South Atlantic South Atlantic
> data.frame(USArrests,state.division) #合并成一个数据框
Murder Assault UrbanPop Rape state.division
Alabama 13.2 236 58 21.2 East South Central
Alaska 10.0 263 48 44.5 Pacific
Arizona 8.1 294 80 31.0 Mountain
Arkansas 8.8 190 50 19.5 West South Central
##单独的行和列的添加
> ?cbind #Columns-bind完成行对行的连接,相当于增加列数
> cbind(USArrests,state.division) #效果同上
##合并行时要求新合并的数据与原有数据具有同一列名
> data1 <- head(USArrests,20) #取USArrests中前20行
> data2 <- tail(USArrests,20) #取后20行
> rbind(data1,data2) #Rows-bind合并列,列对列的连接,相当于增加行数
单独的行和列的添加
> ?cbind #Columns-bind完成行对行的连接,相当于增加列数
> cbind(USArrests,state.division) #效果同上
##合并行时要求新合并的数据与原有数据具有同一列名
> data1 <- head(USArrests,20) #取USArrests中前20行
> data2 <- tail(USArrests,20) #取后20行
> rbind(data1,data2) #Rows-bind合并列,列对列的连接,相当于增加行数
##如果行列数不匹配进行合并演示
> head(cbind(USArrests,state.division),20)
Murder Assault UrbanPop Rape state.division
Alabama 13.2 236 58 21.2 East South Central
Alaska 10.0 263 48 44.5 Pacific
Arizona 8.1 294 80 31.0 Mountain
Arkansas 8.8 190 50 19.5 West South Central
> data3 <- head(cbind(USArrests,state.division),20)
> data2
Murder Assault UrbanPop Rape
New Mexico 11.4 285 70 32.1
New York 11.1 254 86 26.1
North Carolina 13.0 337 45 16.1
North Dakota 0.8 45 44 7.3
> rbind(data2,data3)
Error in rbind(deparse.level, ...) : 变量的列数不对
删除重复项行列
> data1 <- head(USArrests,30)
> data2 <- tail(USArrests,30)
> data4 <- rbind(data1,data2) #data1和data2有10行的重复项
> length(rownames(data4)) #合并时会完整合并而不删除重复项
[1] 60
> duplicated(data4) #查看重复部分
[1] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
[10] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
[19] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
[28] FALSE FALSE FALSE TRUE TRUE TRUE TRUE TRUE TRUE
[37] TRUE TRUE TRUE TRUE FALSE FALSE FALSE FALSE FALSE
[46] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
[55] FALSE FALSE FALSE FALSE FALSE FALSE
> data4[duplicated(data4),] #取出重复部分,R会对重复行名加个数字1
Murder Assault UrbanPop Rape
Massachusetts1 4.4 149 85 16.3
Michigan1 12.1 255 74 35.1
Minnesota1 2.7 72 66 14.9
Mississippi1 16.1 259 44 17.1
……
> data4[!duplicated(data4),] #添加感叹号!是取反,即取出非重复部分
Murder Assault UrbanPop Rape
Alabama 13.2 236 58 21.2
Alaska 10.0 263 48 44.5
Arizona 8.1 294 80 31.0
Arkansas 8.8 190 50 19.5
California 9.0 276 91 40.6
……
> length(rownames(data4[!duplicated(data4),])) #这时已经删除掉了重复的那10行
[1] 50
最简便快捷的去重复项指令是使用> unique(),可直接删除所有重复行或元素
P36 数据转换(三)
调换行和列的顺序
-
Excel中的转换:复制表格 --> 在新的sheet中Ctrl + Alt + V -->在弹出的对话框中选择右下角的“转置”,确定即可
-
在R中的行列转换
> sracmt <- t(mtcars) #直接使用t函数
> sracmt
Mazda RX4 Mazda RX4 Wag Datsun 710 Hornet 4 Drive
mpg 21.00 21.00 22.80 21.40
cyl 6.00 6.00 4.00 6.00
-
单独翻转某一行
(比如基因序列的反向和互补)
> ?rev #reverse反转的简称
> letters
[1] "a" "b" "c" "d" "e" "f" "g" "h" "i" "j" "k" "l" "m" "n"
[15] "o" "p" "q" "r" "s" "t" "u" "v" "w" "x" "y" "z"
> rev(letters)
[1] "z" "y" "x" "w" "v" "u" "t" "s" "r" "q" "p" "o" "n" "m"
[15] "l" "k" "j" "i" "h" "g" "f" "e" "d" "c" "b" "a"
##翻转某一列
> women
height weight
1 58 115
2 59 117
3 60 120
4 61 123
5 62 126
6 63 129
7 64 132
8 65 135
9 66 139
10 67 142
11 68 146
12 69 150
13 70 154
14 71 159
15 72 164
> rownames(women)
[1] "1" "2" "3" "4" "5" "6" "7" "8" "9" "10" "11"
[12] "12" "13" "14" "15"
> rev(rownames(women))
[1] "15" "14" "13" "12" "11" "10" "9" "8" "7" "6" "5"
[12] "4" "3" "2" "1"
> women[rev(rownames(women)),] #另一列顺序也随之变化
height weight
15 72 164
14 71 159
13 70 154
12 69 150
11 68 146
10 67 142
9 66 139
8 65 135
7 64 132
6 63 129
5 62 126
4 61 123
3 60 120
2 59 117
1 58 115
-
单位的转换
##例如将women数据集中的英寸单位转化成厘米
> women$height
[1] 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72
> women$height*2.54 #英寸转厘米×2.54
[1] 147.32 149.86 152.40 154.94 157.48 160.02 162.56 165.10
[9] 167.64 170.18 172.72 175.26 177.80 180.34 182.88
> data.frame(women$height*2.54,women$weight)
women.height...2.54 women.weight
1 147.32 115
2 149.86 117
3 152.40 120
4 154.94 123
> ?transform #转换,修改任何列的值
> transform(women,height=height*2.54) #直接在原数据上修改
height weight
1 147.32 115
2 149.86 117
3 152.40 120
4 154.94 123
……
> transform(women,height.cm=height*2.54) #将修改的值新存一列
height weight height.cm
1 58 115 147.32
2 59 117 149.86
3 60 120 152.40
4 61 123 154.94
- 排序
> ?sort
> sort(rivers) #数值按从小打到排
[1] 135 202 210 210 215 217 230 230 233 237 246
[12] 250 250 250 255 259 260 260 265 268 270 276
[23] 280 280 280 281 286 290 291 300 300 300 301
……
> sort(state.name) #字符串按字母顺序排
[1] "Alabama" "Alaska" "Arizona"
[4] "Arkansas" "California" "Colorado"
[7] "Connecticut" "Delaware" "Florida"
[10] "Georgia" "Hawaii" "Idaho"
[13] "Illinois" "Indiana" "Iowa"
[16] "Kansas" "Kentucky" "Louisiana"
##配合rev函数可实现升序和降序
> sort(mtcars) # sort函数无法直接对数据框进行排序
Error in `[.data.frame`(x, order(x, na.last = na.last, decreasing = decreasing)) :
选择了未定义的列
> mtcars[sort(rownames(mtcars)),] #但可通过索引行名或列名进行排序
mpg cyl disp hp drat qsec vs am gear
AMC Javelin 15.2 8 304.0 150 3.15 17.30 0 0 3
Cadillac Fleetwood 10.4 8 472.0 205 2.93 17.98 0 0 3
Camaro Z28 13.3 8 350.0 245 3.73 15.41 0 0 3
Chrysler Imperial 14.7 8 440.0 230 3.23 17.42 0 0 3
Datsun 710 22.8 4 108.0 93 3.85 18.61 1 1 4
Dodge Challenger 15.5 8 318.0 150 2.76 16.87 0 0 3
Duster 360 14.3 8 360.0 245 3.21 15.84 0 0 3
Ferrari Dino 19.7 6 145.0 175 3.62 15.50 0 1 5
> mtcars[sort(mtcars$mpg),] #如这里是按mpg这列升序排
> ?order #返回的是向量的位置,而不是排序的结果
> sort(rivers)
[1] 135 202 210 210 215 217 230 230 233 237 246
[12] 250 250 250 255 259 260 260 265 268 270 276
[23] 280 280 280 281 286 290 291 300 300 300 301
> order(rivers) #即排名,索引值
[1] 8 17 39 108 129 52 36 42 91 117 133 34 56 87
[15] 76 55 41 75 37 127 138 107 13 30 72 53 29 19
[29] 49 61 103 124 126 46 94 123 116 14 2 3 35 18
> rivers[8] #因rivers返回的是索引值,可以利用这点间接的对数据框进行排序
[1] 135
> order(mtcars$mpg)
[1] 15 16 24 7 17 31 14 23 22 29 12 13 11 6 5 10 25 30 1
[20] 2 4 32 21 3 9 8 27 26 19 28 18 20
> mtcars[order(mtcars$mpg),]
mpg cyl disp hp drat qsec vs am gear carb
Cadillac Fleetwood 10.4 8 472.0 205 2.93 17.98 0 0 3 4
Lincoln Continental 10.4 8 460.0 215 3.00 17.82 0 0 3 4
Camaro Z28 13.3 8 350.0 245 3.73 15.41 0 0 3 4
Duster 360 14.3 8 360.0 245 3.21 15.84 0 0 3 4
Chrysler Imperial 14.7 8 440.0 230 3.23 17.42 0 0 3 4
> mtcars[order(-mtcars$mpg),] #在列名前直接加“-”则得到逆序
mpg cyl disp hp drat qsec vs am gear carb
Toyota Corolla 33.9 4 71.1 65 4.22 19.90 1 1 4 1
Fiat 128 32.4 4 78.7 66 4.08 19.47 1 1 4 1
Honda Civic 30.4 4 75.7 52 4.93 18.52 1 1 4 2
##对多个条件进行排序
> mtcars[order(mtcars$mpg,mtcars$disp),] #在消耗的每加仑汽油行驶里程(mpg)一致的情况下,排量(disp)小的排在前面
mpg cyl disp hp drat qsec vs am gear carb
Lincoln Continental 10.4 8 460.0 215 3.00 17.82 0 0 3 4
Cadillac Fleetwood 10.4 8 472.0 205 2.93 17.98 0 0 3 4
Camaro Z28 13.3 8 350.0 245 3.73 15.41 0 0 3 4
Duster 360 14.3 8 360.0 245 3.21 15.84 0 0 3 4
Chrysler Imperial 14.7 8 440.0 230 3.23 17.42 0 0 3 4
Maserati Bora 15.0 8 301.0 335 3.54 14.60 0 1 5 8
> ?rank #返回的是向量的排名,涉及到秩次概念
P37 数据转换(四)
> WorldPhones #全球八个区域七年中的电话数量
N.Amer Europe Asia S.Amer Oceania Africa Mid.Amer
1951 45939 21574 2876 1815 1646 89 555
1956 60423 29990 4708 2568 2366 1411 733
1957 64721 32510 5230 2695 2526 1546 773
1958 68484 35218 6662 2845 2691 1663 836
1959 71799 37598 6856 3000 2868 1769 911
1960 76036 40341 8220 3145 3054 1905 1008
1961 79831 43173 9053 3338 3224 2005 1076
> worldphones <- as.data.frame(WorldPhones)
> rs <- rowSums(worldphones) #计算每一行的加和值
> rs
1951 1956 1957 1958 1959 1960 1961
74494 102199 110001 118399 124801 133709 141700
> cm <- colMeans(worldphones) #计算每一列的平均值
> cm
N.Amer Europe Asia S.Amer Oceania
66747.5714 34343.4286 6229.2857 2772.2857 2625.0000
Africa Mid.Amer
1484.0000 841.7143
> total <- cbind(worldphones,Total=rs) #增添加和值rs这一列
> total
N.Amer Europe Asia S.Amer Oceania Africa Mid.Amer Total
1951 45939 21574 2876 1815 1646 89 555 74494
1956 60423 29990 4708 2568 2366 1411 733 102199
1957 64721 32510 5230 2695 2526 1546 773 110001
1958 68484 35218 6662 2845 2691 1663 836 118399
1959 71799 37598 6856 3000 2868 1769 911 124801
1960 76036 40341 8220 3145 3054 1905 1008 133709
1961 79831 43173 9053 3338 3224 2005 1076 141700
> rbind(total,cm) #增添平均值cm这一列
N.Amer Europe Asia S.Amer Oceania Africa Mid.Amer Total
1951 45939.00 21574.00 2876.000 1815.000 1646 89 555.0000 74494.00
1956 60423.00 29990.00 4708.000 2568.000 2366 1411 733.0000 102199.00
1957 64721.00 32510.00 5230.000 2695.000 2526 1546 773.0000 110001.00
1958 68484.00 35218.00 6662.000 2845.000 2691 1663 836.0000 118399.00
1959 71799.00 37598.00 6856.000 3000.000 2868 1769 911.0000 124801.00
1960 76036.00 40341.00 8220.000 3145.000 3054 1905 1008.0000 133709.00
1961 79831.00 43173.00 9053.000 3338.000 3224 2005 1076.0000 141700.00
8 66747.57 34343.43 6229.286 2772.286 2625 1484 841.7143 66747.57#此处该数据错误,由于计算平均值时未计入加和值Total这列,导致行列不匹配,Total这列的平均值错误
##解决方法是先输出计算完行加和值的整个数据框,再计算列平均值,如下
> cm <- colMeans(total)
> cm
N.Amer Europe Asia S.Amer Oceania Africa Mid.Amer Total
66747.5714 34343.4286 6229.2857 2772.2857 2625.0000 1484.0000 841.7143 115043.2857
> rbind(total,cm)
> rbind(total,mean=cm) #mean是重新命名新添加行
N.Amer Europe Asia S.Amer Oceania Africa Mid.Amer Total
1951 45939.00 21574.00 2876.000 1815.000 1646 89 555.0000 74494.0
1956 60423.00 29990.00 4708.000 2568.000 2366 1411 733.0000 102199.0
1957 64721.00 32510.00 5230.000 2695.000 2526 1546 773.0000 110001.0
1958 68484.00 35218.00 6662.000 2845.000 2691 1663 836.0000 118399.0
1959 71799.00 37598.00 6856.000 3000.000 2868 1769 911.0000 124801.0
1960 76036.00 40341.00 8220.000 3145.000 3054 1905 1008.0000 133709.0
1961 79831.00 43173.00 9053.000 3338.000 3224 2005 1076.0000 141700.0
mean 66747.57 34343.43 6229.286 2772.286 2625 1484 841.7143 115043.3
apply series函数
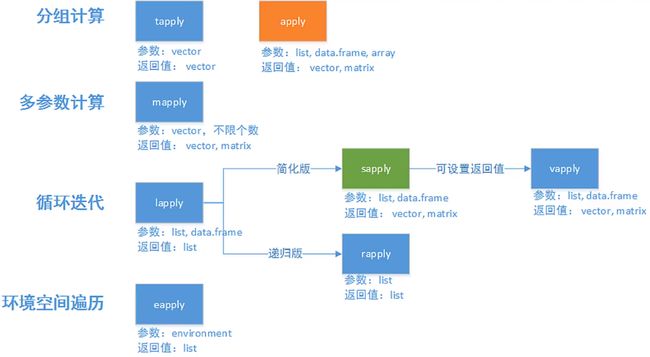
> ?apply ##三个参数:X表示被处理的对象;MARGIN表示向量下标,1表示行,2表示列,c(1,2)表示行和列;FUN表示此处可调用函数。
> apply(WorldPhones,MARGIN = 1,FUN = sum) #对每行求和
1951 1956 1957 1958 1959 1960 1961
74494 102199 110001 118399 124801 133709 141700
> apply(WorldPhones,MARGIN = 2,FUN = mean) #对每列求平均值
N.Amer Europe Asia S.Amer Oceania Africa Mid.Amer
66747.5714 34343.4286 6229.2857 2772.2857 2625.0000 1484.0000 841.7143
##与第一种方法相比,可以计算更多的类型值,如方差/log值等,但将结果合并时仍需注意上一种方法出现的行列匹配以及值的对应问题(先计算行加和合并表,再计算合并后的表的列平均值)
> apply(WorldPhones,MARGIN = 2,FUN = var)
N.Amer Europe Asia S.Amer Oceania Africa Mid.Amer
127181160.6 51776902.0 4512287.6 246698.6 273595.0 419524.3 31019.9
> apply(WorldPhones,MARGIN = 2,FUN = log)
N.Amer Europe Asia S.Amer Oceania Africa Mid.Amer
1951 10.73507 9.979244 7.964156 7.503841 7.406103 4.488636 6.318968
1956 11.00913 10.308619 8.457018 7.850883 7.768956 7.252054 6.597146ong
1957 11.07784 10.389303 8.562167 7.899153 7.834392 7.343426 6.650279
1958 11.13436 10.469313 8.804175 7.953318 7.897668 7.416378 6.728629
1959 11.18163 10.534706 8.832879 8.006368 7.961370 7.478170 6.814543
1960 11.23896 10.605124 9.014325 8.053569 8.024207 7.552237 6.915723
1961 11.28767 10.672971 9.110851 8.113127 8.078378 7.603399 6.981006
#lapply and sapply
> ?lapply # list apply返回的是列表
> sapply # simplify apply 返回的是向量或矩阵
> state.center
$x
[1] -86.7509 -127.2500 -111.6250 -92.2992 -119.7730
[6] -105.5130 -72.3573 -74.9841 -81.6850 -83.3736
[11] -126.2500 -113.9300 -89.3776 -86.0808 -93.3714
[16] -98.1156 -84.7674 -92.2724 -68.9801 -76.6459
[21] -71.5800 -84.6870 -94.6043 -89.8065 -92.5137
[26] -109.3200 -99.5898 -116.8510 -71.3924 -74.2336
[31] -105.9420 -75.1449 -78.4686 -100.0990 -82.5963
[36] -97.1239 -120.0680 -77.4500 -71.1244 -80.5056
[41] -99.7238 -86.4560 -98.7857 -111.3300 -72.5450
[46] -78.2005 -119.7460 -80.6665 -89.9941 -107.2560
$y
[1] 32.5901 49.2500 34.2192 34.7336 36.5341 38.6777 41.5928
[8] 38.6777 27.8744 32.3329 31.7500 43.5648 40.0495 40.0495
[15] 41.9358 38.4204 37.3915 30.6181 45.6226 39.2778 42.3645
[22] 43.1361 46.3943 32.6758 38.3347 46.8230 41.3356 39.1063
[29] 43.3934 39.9637 34.4764 43.1361 35.4195 47.2517 40.2210
[36] 35.5053 43.9078 40.9069 41.5928 33.6190 44.3365 35.6767
[43] 31.3897 39.1063 44.2508 37.5630 47.4231 38.4204 44.5937
[50] 43.0504
> lapply(state.center,FUN = length) #计算上述列表的元素个数,返回值依然是列表形式
$x
[1] 50
$y
[1] 50
> sapply(state.center,FUN = length) #与上方类似,但返回值是向量
x y
50 50
> class(sapply(state.center,FUN = length))
[1] "integer"
#tapply
> ?tapply #tapply(X, INDEX, FUN = NULL, ..., default = NA, simplify = TRUE),注意第二个参数为因子
> state.name #美国50个洲的名字
[1] "Alabama" "Alaska" "Arizona" "Arkansas" "California" "Colorado" "Connecticut" "Delaware" "Florida"
[10] "Georgia" "Hawaii" "Idaho" "Illinois" "Indiana" "Iowa" "Kansas" "Kentucky" "Louisiana"
……
> state.division #每个州的分区
[1] East South Central Pacific Mountain West South Central Pacific Mountain New England South Atlantic
[9] South Atlantic South Atlantic Pacific Mountain East North Central East North Central West North Central West North Central
……
Levels: New England Middle Atlantic South Atlantic East South Central West South Central East North Central West North Central Mountain Pacific
> tapply(state.name,state.division,FUN = length) #统计每个分区有多少个州
New England Middle Atlantic South Atlantic East South Central West South Central East North Central West North Central Mountain
6 3 8 4 4 5 7 8
Pacific
5
数据的中心化与标准化
数据中心化,是指数据集中的各项数据减去数据集的均值。
数据标准化,是指在中心化之后在除以数据集的标准差,即数据集中的各项数据减去数据集的均值再除以数据集的标准差。
避免量纲(单位)差异。
> state.x77
Population Income Illiteracy Life Exp Murder HS Grad Frost Area
Alabama 3615 3624 2.1 69.05 15.1 41.3 20 50708
Alaska 365 6315 1.5 69.31 11.3 66.7 152 566432
Arizona 2212 4530 1.8 70.55 7.8 58.1 15 113417
Arkansas 2110 3378 1.9 70.66 10.1 39.9 65 51945
California 21198 5114 1.1 71.71 10.3 62.6 20 156361
……
> heatmap(state.x77) #各列直接单位不同数值差异太大,绘制出来的热图没有意义
> x <- c(1,2,3,6,3)
> mean(x)
[1] 3
> x-mean(x) #中心化后数值差异依然有点大
[1] -2 -1 0 3 0
> sd(x)
[1] 1.870829
> (x-mean(x))/sd(x) #继续进行数据标准化
[1] -1.0690450 -0.5345225 0.0000000 1.6035675 0.0000000 #得到的值相对稳定都在0附近
scale(x, center = TRUE, scale = TRUE) #后两个参数分别为中心化处理和标准化处理
> x <- scale(state.x77,scale = T,center = T)
> head(x)
Population Income Illiteracy Life Exp Murder HS Grad Frost Area
Alabama -0.1414316 -1.3211387 1.525758 -1.3621937 2.0918101 -1.4619293 -1.6248292 -0.2347183
Alaska -0.8693980 3.0582456 0.541398 -1.1685098 1.0624293 1.6828035 0.9145676 5.8093497
Arizona -0.4556891 0.1533029 1.033578 -0.2447866 0.1143154 0.6180514 -1.7210185 0.5002047
Arkansas -0.4785360 -1.7214837 1.197638 -0.1628435 0.7373617 -1.6352611 -0.7591257 -0.2202212
California 3.7969790 1.1037155 -0.114842 0.6193415 0.7915396 1.1751891 -1.6248292 1.0034903
Colorado -0.3819965 0.7294092 -0.771082 0.8800698 -0.1565742 1.3361400 1.1838976 0.3870991
> head(state.x77)
Population Income Illiteracy Life Exp Murder HS Grad Frost Area
Alabama 3615 3624 2.1 69.05 15.1 41.3 20 50708
Alaska 365 6315 1.5 69.31 11.3 66.7 152 566432
Arizona 2212 4530 1.8 70.55 7.8 58.1 15 113417
Arkansas 2110 3378 1.9 70.66 10.1 39.9 65 51945
California 21198 5114 1.1 71.71 10.3 62.6 20 156361
Colorado 2541 4884 0.7 72.06 6.8 63.9 166 103766
> heatmap(x)#结果明显
heatmap(state.x77) #意义不大 heatmap(x)#结果清晰
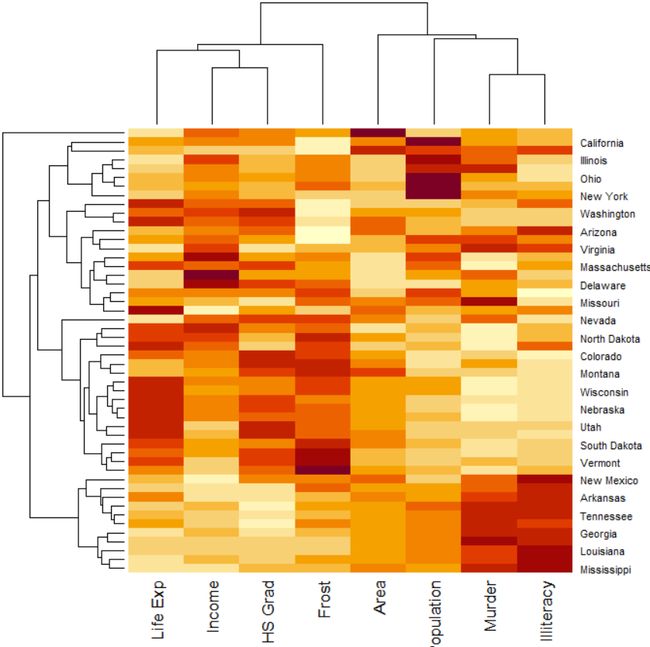
P38 reshape2
> x <- data.frame(k1 = c(NA,NA,3,4,5), k2 = c(1,NA,NA,4,5),
+ data = 1:5)
> y <- data.frame(k1 = c(NA,2,NA,4,5), k2 = c(NA,NA,3,4,5),
+ data = 1:5)
> x
k1 k2 data
1 NA 1 1
2 NA NA 2
3 3 NA 3
4 4 4 4
5 5 5 5
> y
k1 k2 data
1 NA NA 1
2 2 NA 2
3 NA 3 3
4 4 4 4
5 5 5 5
> rbind(x,y) #直接连接合并分不出哪些数据来自哪个数据框
k1 k2 data
1 NA 1 1
2 NA NA 2
3 3 NA 3
4 4 4 4
5 5 5 5
6 NA NA 1
7 2 NA 2
8 NA 3 3
9 4 4 4
10 5 5 5
> merge(x, y, by = "k1") #x,y中k1相同的有:(NA,4,5),所以保留二者中包含(NA,4,5)的所有行
k1 k2.x data.x k2.y data.y
1 4 4 4 4 4
2 5 5 5 5 5
3 NA 1 1 NA 1
4 NA 1 1 3 3
5 NA NA 2 NA 1
6 NA NA 2 3 3
> merge(x, y, by = "k2",comparables=T) #以k2为准合并,不匹配的部分用NA表示,即comparables=NA
k2 k1.x data.x k1.y data.y
1 4 4 4 4 4
2 5 5 5 5 5
3 NA NA 2 NA 1
4 NA NA 2 2 2
5 NA 3 3 NA 1
6 NA 3 3 2 2
> merge(x, y, by = c("k1","k2")) #按k1,k2共有的元素合并
k1 k2 data.x data.y
1 4 4 4 4
2 5 5 5 5
3 NA NA 2 1
- reshape2:类似于Excel中数据透视表的功能,利用melt函数将数据“揉开”并“重造”的过程 这节重学
> install.packages("reshape2")
> library(reshape2)
> airquality #reshape2的演示数据集
Ozone Solar.R Wind Temp Month Day
1 41 190 7.4 67 5 1
2 36 118 8.0 72 5 2
3 12 149 12.6 74 5 3
4 18 313 11.5 62 5 4
5 NA NA 14.3 56 5 5
6 28 NA 14.9 66 5 6
7 23 299 8.6 65 5 7
8 19 99 13.8 59 5 8
9 8 19 20.1 61 5 9
10 NA 194 8.6 69 5 10
11 7 NA 6.9 74 5 11
12 16 256 9.7 69 5 12
……
> head(airquality)
Ozone Solar.R Wind Temp Month Day
1 41 190 7.4 67 5 1
2 36 118 8.0 72 5 2
3 12 149 12.6 74 5 3
4 18 313 11.5 62 5 4
5 NA NA 14.3 56 5 5
6 28 NA 14.9 66 5 6
> names(airquality) <- tolower(names(airquality)) #改成小写方便输入
> head(airquality)
ozone solar.r wind temp month day
1 41 190 7.4 67 5 1
2 36 118 8.0 72 5 2
3 12 149 12.6 74 5 3
4 18 313 11.5 62 5 4
5 NA NA 14.3 56 5 5
6 28 NA 14.9 66 5 6
> melt(airquality) #将宽数据改成长数据,即“融合数据”
No id variables; using all as measure variables
variable value
1 ozone 41.0
2 ozone 36.0
3 ozone 12.0
4 ozone 18.0
5 ozone NA
6 ozone 28.0 #数据变成三列
……
[ reached 'max' / getOption("max.print") -- omitted 418 rows ]
> aql <- melt(airquality)
No id variables; using all as measure variables
> head(aql)
variable value
1 ozone 41
2 ozone 36
3 ozone 12
4 ozone 18
5 ozone NA
6 ozone 28
> aql <- melt(airquality, id.vars = c("month", "day")) #确定哪部分用作行的观测,哪部分作为列的观测值
#month和day作为ID(用来区分不同行数据的变量),其余四个(ozone solar.r wind temp)作为变量值
> head(aql)
month day variable value
1 5 1 ozone 41
2 5 2 ozone 36
3 5 3 ozone 12
4 5 4 ozone 18
5 5 5 ozone NA
6 5 6 ozone 28
> aqw <- dcast(aql, month + day ~ variable) #dcast函数用来处理数据框,“~”表示相关联(二者有关系,但不一定是相等) #acast函数返回向量/矩阵/数组
> head(aqw) #与原始数据相比只是把month day两列提前
month day ozone solar.r wind temp
1 5 1 41 190 7.4 67
2 5 2 36 118 8.0 72
3 5 3 12 149 12.6 74
4 5 4 18 313 11.5 62
5 5 5 NA NA 14.3 56
6 5 6 28 NA 14.9 66
> head(airquality)
ozone solar.r wind temp month day
1 41 190 7.4 67 5 1
2 36 118 8.0 72 5 2
3 12 149 12.6 74 5 3
4 18 313 11.5 62 5 4
5 NA NA 14.3 56 5 5
6 28 NA 14.9 66 5 6
> dcast(aql, month ~ variable) #去掉day变量提示:当一个月的数据合并后,不知道对每一天的值如何处理,是计算总和/平均值/中位数等
Aggregation function missing: defaulting to length
month ozone solar.r wind temp
1 5 31 31 31 31
2 6 30 30 30 30
3 7 31 31 31 31
4 8 31 31 31 31
5 9 30 30 30 30
> dcast(aql, month ~ variable, fun.aggregate = mean, na.rm = TRUE) #aggregate合并,na.rm去除NA值
month ozone solar.r wind temp
1 5 23.61538 181.2963 11.622581 65.54839
2 6 29.44444 190.1667 10.266667 79.10000
3 7 59.11538 216.4839 8.941935 83.90323
4 8 59.96154 171.8571 8.793548 83.96774
5 9 31.44828 167.4333 10.180000 76.90000
> head(aqw)
month day ozone solar.r wind temp
1 5 1 41 190 7.4 67
2 5 2 36 118 8.0 72
3 5 3 12 149 12.6 74
4 5 4 18 313 11.5 62
5 5 5 NA NA 14.3 56
6 5 6 28 NA 14.9 66
> aqw <- dcast(aql, month ~ variable, fun.aggregate = sum, na.rm = TRUE)
> head(aqw)
month ozone solar.r wind temp
1 5 614 4895 360.3 2032
2 6 265 5705 308.0 2373
3 7 1537 6711 277.2 2601
4 8 1559 4812 272.6 2603
5 9 912 5023 305.4 2307
##dcast(data,formula,fun.aggregate = NULL,……)
##formula需要融合后的数据格式,描述重铸数据形状:左边表示id.variable,右边表示major.variable可观测的值
P39 tidyr包
Tidyr data 处理整洁的数据
- 每一列代表一个变量
- 每一行代表一个观测
- 每一个观测的值在表中的一个单元格中
即一个变量和一个观测确定一个唯一的值
有相同的行名和列名则会引起识别混乱,不属于tidyr data
tidyr包主要包含四个常用重要函数:
- gather:将宽数据转换为长数据,类似于reshape2中的melt函数,gather的好处是固定列不变,其他列进行转换
> mtcars #以这个标准规范的数据集为例
> tdata <- mtcars[1:10,1:3]
> tdata
mpg cyl disp
Mazda RX4 21.0 6 160.0
Mazda RX4 Wag 21.0 6 160.0
Datsun 710 22.8 4 108.0
Hornet 4 Drive 21.4 6 258.0
Hornet Sportabout 18.7 8 360.0
Valiant 18.1 6 225.0
Duster 360 14.3 8 360.0
Merc 240D 24.4 4 146.7
Merc 230 22.8 4 140.8
Merc 280 19.2 6 167.6
> tdata <- data.frame(name=rownames(tdata),tdata)
> tdata
name mpg cyl disp
Mazda RX4 Mazda RX4 21.0 6 160.0
Mazda RX4 Wag Mazda RX4 Wag 21.0 6 160.0
Datsun 710 Datsun 710 22.8 4 108.0
Hornet 4 Drive Hornet 4 Drive 21.4 6 258.0
Hornet Sportabout Hornet Sportabout 18.7 8 360.0
Valiant Valiant 18.1 6 225.0
Duster 360 Duster 360 14.3 8 360.0
Merc 240D Merc 240D 24.4 4 146.7
Merc 230 Merc 230 22.8 4 140.8
Merc 280 Merc 280 19.2 6 167.6
##gather(data,key = "key",value = "value",
##key是宽数据变为长数据时存放需要编码的变量的变量名称,需要自己定义新的名字
##value需要数据转换的变量的数值,也需要自己重新定义,后面接对哪些列进行处理
> gather(tdata,key = "Key",value = "Value",cyl,disp,mpg)
name Key Value
1 Mazda RX4 cyl 6.0
2 Mazda RX4 Wag cyl 6.0
3 Datsun 710 cyl 4.0
4 Hornet 4 Drive cyl 6.0
5 Hornet Sportabout cyl 8.0
6 Valiant cyl 6.0
7 Duster 360 cyl 8.0
8 Merc 240D cyl 4.0
9 Merc 230 cyl 4.0
10 Merc 280 cyl 6.0
11 Mazda RX4 disp 160.0
12 Mazda RX4 Wag disp 160.0
13 Datsun 710 disp 108.0
14 Hornet 4 Drive disp 258.0
15 Hornet Sportabout disp 360.0
16 Valiant disp 225.0
17 Duster 360 disp 360.0
18 Merc 240D disp 146.7
19 Merc 230 disp 140.8
20 Merc 280 disp 167.6
21 Mazda RX4 mpg 21.0
22 Mazda RX4 Wag mpg 21.0
23 Datsun 710 mpg 22.8
24 Hornet 4 Drive mpg 21.4
25 Hornet Sportabout mpg 18.7
26 Valiant mpg 18.1
27 Duster 360 mpg 14.3
28 Merc 240D mpg 24.4
29 Merc 230 mpg 22.8
30 Merc 280 mpg 19.2
> gather(tdata,key = "Key",value = "Value",cyl:disp) #“:”从XX到XX
name mpg Key Value
1 Mazda RX4 21.0 cyl 6.0
2 Mazda RX4 Wag 21.0 cyl 6.0
3 Datsun 710 22.8 cyl 4.0
4 Hornet 4 Drive 21.4 cyl 6.0
5 Hornet Sportabout 18.7 cyl 8.0
6 Valiant 18.1 cyl 6.0
7 Duster 360 14.3 cyl 8.0
8 Merc 240D 24.4 cyl 4.0
9 Merc 230 22.8 cyl 4.0
10 Merc 280 19.2 cyl 6.0
11 Mazda RX4 21.0 disp 160.0
12 Mazda RX4 Wag 21.0 disp 160.0
13 Datsun 710 22.8 disp 108.0
14 Hornet 4 Drive 21.4 disp 258.0
15 Hornet Sportabout 18.7 disp 360.0
16 Valiant 18.1 disp 225.0
17 Duster 360 14.3 disp 360.0
18 Merc 240D 24.4 disp 146.7
19 Merc 230 22.8 disp 140.8
20 Merc 280 19.2 disp 167.6
> gather(tdata,key = "Key",value = "Value",mpg,-disp) #“-”表示删除某列
name cyl disp Key Value
1 Mazda RX4 6 160.0 mpg 21.0
2 Mazda RX4 Wag 6 160.0 mpg 21.0
3 Datsun 710 4 108.0 mpg 22.8
4 Hornet 4 Drive 6 258.0 mpg 21.4
5 Hornet Sportabout 8 360.0 mpg 18.7
6 Valiant 6 225.0 mpg 18.1
7 Duster 360 8 360.0 mpg 14.3
8 Merc 240D 4 146.7 mpg 24.4
9 Merc 230 4 140.8 mpg 22.8
10 Merc 280 6 167.6 mpg 19.2
> gather(tdata,key = "Key",value = "Value",2:4) #也可以直接输入列所在序号
name Key Value
1 Mazda RX4 mpg 21.0
2 Mazda RX4 Wag mpg 21.0
3 Datsun 710 mpg 22.8
4 Hornet 4 Drive mpg 21.4
5 Hornet Sportabout mpg 18.7
6 Valiant mpg 18.1
7 Duster 360 mpg 14.3
8 Merc 240D mpg 24.4
9 Merc 230 mpg 22.8
10 Merc 280 mpg 19.2
11 Mazda RX4 cyl 6.0
12 Mazda RX4 Wag cyl 6.0
13 Datsun 710 cyl 4.0
14 Hornet 4 Drive cyl 6.0
15 Hornet Sportabout cyl 8.0
16 Valiant cyl 6.0
17 Duster 360 cyl 8.0
18 Merc 240D cyl 4.0
19 Merc 230 cyl 4.0
20 Merc 280 cyl 6.0
21 Mazda RX4 disp 160.0
22 Mazda RX4 Wag disp 160.0
23 Datsun 710 disp 108.0
24 Hornet 4 Drive disp 258.0
25 Hornet Sportabout disp 360.0
26 Valiant disp 225.0
27 Duster 360 disp 360.0
28 Merc 240D disp 146.7
29 Merc 230 disp 140.8
30 Merc 280 disp 167.6
- spread:将长数据转换为宽数据,类似于reshape2中的cast函数
> gdata <- gather(tdata,key = "Key",value = "Value",2:4)
> gdata
name Key Value
1 Mazda RX4 mpg 21.0
2 Mazda RX4 Wag mpg 21.0
3 Datsun 710 mpg 22.8
4 Hornet 4 Drive mpg 21.4
5 Hornet Sportabout mpg 18.7
6 Valiant mpg 18.1
7 Duster 360 mpg 14.3
8 Merc 240D mpg 24.4
9 Merc 230 mpg 22.8
10 Merc 280 mpg 19.2
11 Mazda RX4 cyl 6.0
12 Mazda RX4 Wag cyl 6.0
13 Datsun 710 cyl 4.0
14 Hornet 4 Drive cyl 6.0
15 Hornet Sportabout cyl 8.0
16 Valiant cyl 6.0
17 Duster 360 cyl 8.0
18 Merc 240D cyl 4.0
19 Merc 230 cyl 4.0
20 Merc 280 cyl 6.0
21 Mazda RX4 disp 160.0
22 Mazda RX4 Wag disp 160.0
23 Datsun 710 disp 108.0
24 Hornet 4 Drive disp 258.0
25 Hornet Sportabout disp 360.0
26 Valiant disp 225.0
27 Duster 360 disp 360.0
28 Merc 240D disp 146.7
29 Merc 230 disp 140.8
30 Merc 280 disp 167.6
> spread(gdata,key = "Key",value = "Value") #重新回到tidyr格式
name cyl disp mpg
1 Datsun 710 4 108.0 22.8
2 Duster 360 8 360.0 14.3
3 Hornet 4 Drive 6 258.0 21.4
4 Hornet Sportabout 8 360.0 18.7
5 Mazda RX4 6 160.0 21.0
6 Mazda RX4 Wag 6 160.0 21.0
7 Merc 230 4 140.8 22.8
8 Merc 240D 4 146.7 24.4
9 Merc 280 6 167.6 19.2
10 Valiant 6 225.0 18.1
- separate:将一列分成多列
> df <- data.frame(x = c(NA, "a.b", "a.d", "b.c"))
> df
x
1
2 a.b
3 a.d
4 b.c
> separate(df,col=x,into = c("A","B"))
A B
1
2 a b
3 a d
4 b c
> df <- data.frame(x = c(NA, "a.b-c", "a-d", "b-c")) #加上连字符-再试一次
> separate(df,col=x,into = c("A","B")) #分割出现错误,-c都未显示
A B
1
2 a b
3 a d
4 b c
Warning message:
Expected 2 pieces. Additional pieces discarded in 1 rows [2].
> separate(df,x,into = c("A","B"),sep = "-") #重新设置分隔符
A B
1
2 a.b c
3 a d
4 b c
- unite:将多列合并为一列
> x <- separate(df,x,into = c("A","B"),sep = "-")
> x
A B
1
2 a.b c
3 a d
4 b c
> unite(x,col ="AB",A,B,sep="-")
AB
1 NA-NA
2 a.b-c
3 a-d
4 b-c
P40 dplyr包
## 以鸢尾花数据集iris(总共150行数据)为例
> dplyr::filter (iris,Sepal.Length >7) ##filter过滤,过滤掉长度大于7的数据
Sepal.Length Sepal.Width Petal.Length Petal.Width Species
1 7.1 3.0 5.9 2.1 virginica
2 7.6 3.0 6.6 2.1 virginica
3 7.3 2.9 6.3 1.8 virginica
4 7.2 3.6 6.1 2.5 virginica
5 7.7 3.8 6.7 2.2 virginica
6 7.7 2.6 6.9 2.3 virginica
7 7.7 2.8 6.7 2.0 virginica
8 7.2 3.2 6.0 1.8 virginica
9 7.2 3.0 5.8 1.6 virginica
10 7.4 2.8 6.1 1.9 virginica
11 7.9 3.8 6.4 2.0 virginica
12 7.7 3.0 6.1 2.3 virginica
> dplyr::distinct(rbind(iris[1:10,],iris[1:15,])) #distinct去除重复数据
Sepal.Length Sepal.Width Petal.Length Petal.Width Species
1 5.1 3.5 1.4 0.2 setosa
2 4.9 3.0 1.4 0.2 setosa
3 4.7 3.2 1.3 0.2 setosa
4 4.6 3.1 1.5 0.2 setosa
5 5.0 3.6 1.4 0.2 setosa
6 5.4 3.9 1.7 0.4 setosa
7 4.6 3.4 1.4 0.3 setosa
8 5.0 3.4 1.5 0.2 setosa
9 4.4 2.9 1.4 0.2 setosa
10 4.9 3.1 1.5 0.1 setosa
11 5.4 3.7 1.5 0.2 setosa
12 4.8 3.4 1.6 0.2 setosa
13 4.8 3.0 1.4 0.1 setosa
14 4.3 3.0 1.1 0.1 setosa
15 5.8 4.0 1.2 0.2 setosa
> dplyr::slice(iris,10:15) #取出函数任意行
Sepal.Length Sepal.Width Petal.Length Petal.Width Species
1 4.9 3.1 1.5 0.1 setosa
2 5.4 3.7 1.5 0.2 setosa
3 4.8 3.4 1.6 0.2 setosa
4 4.8 3.0 1.4 0.1 setosa
5 4.3 3.0 1.1 0.1 setosa
6 5.8 4.0 1.2 0.2 setosa
> dplyr::sample_n(iris,10) #用于随机取样
Sepal.Length Sepal.Width Petal.Length Petal.Width Species
1 6.7 3.1 4.4 1.4 versicolor
2 5.1 3.8 1.6 0.2 setosa
3 7.2 3.6 6.1 2.5 virginica
4 4.8 3.1 1.6 0.2 setosa
5 6.6 3.0 4.4 1.4 versicolor
6 6.9 3.1 4.9 1.5 versicolor
7 6.7 3.3 5.7 2.5 virginica
8 6.5 3.2 5.1 2.0 virginica
9 6.2 2.8 4.8 1.8 virginica
10 5.5 4.2 1.4 0.2 setosa
> dplyr::sample_frac(iris,0.1) #随机按比例选取,比如这里是取10%
Sepal.Length Sepal.Width Petal.Length Petal.Width Species
1 7.1 3.0 5.9 2.1 virginica
2 6.1 2.8 4.0 1.3 versicolor
3 5.0 3.5 1.6 0.6 setosa
4 5.0 2.0 3.5 1.0 versicolor
5 4.9 2.5 4.5 1.7 virginica
6 5.8 2.8 5.1 2.4 virginica
7 7.7 3.8 6.7 2.2 virginica
8 6.4 2.8 5.6 2.1 virginica
9 6.6 2.9 4.6 1.3 versicolor
10 4.8 3.0 1.4 0.1 setosa
11 7.2 3.2 6.0 1.8 virginica
12 6.3 2.5 4.9 1.5 versicolor
13 5.3 3.7 1.5 0.2 setosa
14 6.3 2.9 5.6 1.8 virginica
15 5.7 2.5 5.0 2.0 virginica
> dplyr::arrange(iris,Sepal.Length) #按照花萼长度进行排序
Sepal.Length Sepal.Width Petal.Length Petal.Width Species
1 4.3 3.0 1.1 0.1 setosa
2 4.4 2.9 1.4 0.2 setosa
3 4.4 3.0 1.3 0.2 setosa
4 4.4 3.2 1.3 0.2 setosa
5 4.5 2.3 1.3 0.3 setosa
> dplyr::arrange(iris,desc(Sepal.Length)) #descend降序排列
Sepal.Length Sepal.Width Petal.Length Petal.Width Species
1 7.9 3.8 6.4 2.0 virginica
2 7.7 3.8 6.7 2.2 virginica
3 7.7 2.6 6.9 2.3 virginica
4 7.7 2.8 6.7 2.0 virginica
5 7.7 3.0 6.1 2.3 virginica
6 7.6 3.0 6.6 2.1 virginica
7 7.4 2.8 6.1 1.9 virginica
##取子集
> ?select #比R自带的subset取子集功能更为强大
> example("select") #具体可查看帮助文档中的案例演示
- 使用dplyr中的统计函数
##依然以iris数据集为例
> summarise(iris,avg=mean(Sepal.Length)) #计算花萼平均值
avg
1 5.843333
> summarise(iris,sum=sum(Sepal.Length)) #计算花萼总长度
sum
1 876.5
#还包含其他类似函数
summarise Summarise each group to fewer rows
summarise_all Summarise multiple columns
summarise_at Summarise multiple columns
summarise_if Summarise multiple columns
summarize Summarise each group to fewer rows
summarize_all Summarise multiple columns
summarize_at Summarise multiple columns
summarize_if Summarise multiple columns
- 链式操作符%>%
两个百分号中间夹着一个大于号,称为链式操作符,它功能是用于实现将一个函数的输出传递给下一个函数,作为下一个函数的输入。
在Rstudio中可以使用ctrl+shift+M快捷键输出出来。
## %>%示例
> head(mtcars,20) %>% tail() #从mtcars的前20行中取出后6行
mpg cyl disp hp drat wt qsec vs am gear carb
Cadillac Fleetwood 10.4 8 472.0 205 2.93 5.250 17.98 0 0 3 4
Lincoln Continental 10.4 8 460.0 215 3.00 5.424 17.82 0 0 3 4
Chrysler Imperial 14.7 8 440.0 230 3.23 5.345 17.42 0 0 3 4
Fiat 128 32.4 4 78.7 66 4.08 2.200 19.47 1 1 4 1
Honda Civic 30.4 4 75.7 52 4.93 1.615 18.52 1 1 4 2
Toyota Corolla 33.9 4 71.1 65 4.22 1.835 19.90 1 1 4 1
## %>%的应用
> dplyr::group_by(iris,Species) #通过species对iris进行分组,共分成了三组
# A tibble: 150 x 5
# Groups: Species [3]
Sepal.Length Sepal.Width Petal.Length Petal.Width Species
1 5.1 3.5 1.4 0.2 setosa
2 4.9 3 1.4 0.2 setosa
3 4.7 3.2 1.3 0.2 setosa
4 4.6 3.1 1.5 0.2 setosa
5 5 3.6 1.4 0.2 setosa
6 5.4 3.9 1.7 0.4 setosa
7 4.6 3.4 1.4 0.3 setosa
8 5 3.4 1.5 0.2 setosa
9 4.4 2.9 1.4 0.2 setosa
10 4.9 3.1 1.5 0.1 setosa
# ... with 140 more rows
> iris %>% group_by(Species) #同样实现上述分组效果
> iris %>% group_by(Species) %>% summarise(avg=mean(Sepal.Width)) #分组后计算花萼宽度的平均值
`summarise()` ungrouping output (override with `.groups` argument)
# A tibble: 3 x 2
Species avg
1 setosa 3.43
2 versicolor 2.77
3 virginica 2.97
> iris %>% group_by(Species) %>% summarise(avg=mean(Sepal.Width)) %>% arrange(avg) #依照花萼宽度的平均值对分出的三组进行排序
`summarise()` ungrouping output (override with `.groups` argument)
# A tibble: 3 x 2
Species avg
1 versicolor 2.77
2 virginica 2.97
3 setosa 3.43
> dplyr::mutate(iris,new=Sepal.Length+Petal.Length) #mutate添加新的变量,花萼与花瓣长度的总和
Sepal.Length Sepal.Width Petal.Length Petal.Width Species new
1 5.1 3.5 1.4 0.2 setosa 6.5
2 4.9 3.0 1.4 0.2 setosa 6.3
3 4.7 3.2 1.3 0.2 setosa 6.0
4 4.6 3.1 1.5 0.2 setosa 6.1
……
- 链接
> a=data.frame(x1=c("A","B","C"),x2=c(1,2,3))
> b=data.frame(x1=c("A","B","D"),x3=c(T,F,T))
> a
x1 x2
1 A 1
2 B 2
3 C 3
> b
x1 x3
1 A TRUE
2 B FALSE
3 D TRUE
> dplyr::left_join(a,b,by="x1") #左链接,以左边的表为基础,x1列输出的是a表的值;b表中没有C行所以是NA
x1 x2 x3
1 A 1 TRUE
2 B 2 FALSE
3 C 3 NA
> dplyr::right_join(a,b,by="x1") #右链接
x1 x2 x3
1 A 1 TRUE
2 B 2 FALSE
3 D NA TRUE
##内链接是取x1的交集,全链接是取x1的并集
> dplyr::full_join(a,b,by="x1") #全链接
x1 x2 x3
1 A 1 TRUE
2 B 2 FALSE
3 C 3 NA
4 D NA TRUE
> dplyr::semi_join(a,b,by="x1") #半集,根据b表对a表进行过滤,取ab的交集,即a中含有b的项
x1 x2
1 A 1
2 B 2
> dplyr::anti_join(a,b,by="x1") #反链接,根据右侧表b输出ab的补集,即a中b不含有的行
x1 x2
1 C 3
## 交和补都是以a为基础
- 几个数据集的合并
> first <- slice(mtcars,1:20) #取出mtcars头20行
> first #slice取出默认缺少行名(即第一列)
mpg cyl disp hp drat wt qsec vs am gear carb
Mazda RX4 21.0 6 160.0 110 3.90 2.620 16.46 0 1 4 4
Mazda RX4 Wag 21.0 6 160.0 110 3.90 2.875 17.02 0 1 4 4
Datsun 710 22.8 4 108.0 93 3.85 2.320 18.61 1 1 4 1
……
> mtcars <- mutate(mtcars,Model=rownames(mtcars))#利用mutate函数添加行名
> first <- slice(mtcars,1:20)
> second <- slice(mtcars,10:30)
> first
mpg cyl disp hp drat wt qsec vs am gear carb Model
1 21.0 6 160.0 110 3.90 2.620 16.46 0 1 4 4 Mazda RX4
2 21.0 6 160.0 110 3.90 2.875 17.02 0 1 4 4 Mazda RX4 Wag
3 22.8 4 108.0 93 3.85 2.320 18.61 1 1 4 1 Datsun 710
4 21.4 6 258.0 110 3.08 3.215 19.44 1 0 3 1 Hornet 4 Drive
……
> second
mpg cyl disp hp drat wt qsec vs am gear carb Model
1 19.2 6 167.6 123 3.92 3.440 18.30 1 0 4 4 Merc 280
2 17.8 6 167.6 123 3.92 3.440 18.90 1 0 4 4 Merc 280C
3 16.4 8 275.8 180 3.07 4.070 17.40 0 0 3 3 Merc 450SE
4 17.3 8 275.8 180 3.07 3.730 17.60 0 0 3 3 Merc 450SL
……
> intersect(first, second) #取交集
mpg cyl disp hp drat wt qsec vs am gear carb Model
1 19.2 6 167.6 123 3.92 3.440 18.30 1 0 4 4 Merc 280
2 17.8 6 167.6 123 3.92 3.440 18.90 1 0 4 4 Merc 280C
3 16.4 8 275.8 180 3.07 4.070 17.40 0 0 3 3 Merc 450SE
4 17.3 8 275.8 180 3.07 3.730 17.60 0 0 3 3 Merc 450SL
……
> union_all(first, second) #取并集
mpg cyl disp hp drat wt qsec vs am gear carb Model
1 21.0 6 160.0 110 3.90 2.620 16.46 0 1 4 4 Mazda RX4
2 21.0 6 160.0 110 3.90 2.875 17.02 0 1 4 4 Mazda RX4 Wag
3 22.8 4 108.0 93 3.85 2.320 18.61 1 1 4 1 Datsun 710
4 21.4 6 258.0 110 3.08 3.215 19.44 1 0 3 1 Hornet 4 Drive
……
> union(first, second) #取非冗余的并集,即去掉并集中的重复项
mpg cyl disp hp drat wt qsec vs am gear carb Model
1 21.0 6 160.0 110 3.90 2.620 16.46 0 1 4 4 Mazda RX4
2 21.0 6 160.0 110 3.90 2.875 17.02 0 1 4 4 Mazda RX4 Wag
3 22.8 4 108.0 93 3.85 2.320 18.61 1 1 4 1 Datsun 710
4 21.4 6 258.0 110 3.08 3.215 19.44 1 0 3 1 Hornet 4 Drive
……
> setdiff(first, second) #取frist的补集
mpg cyl disp hp drat wt qsec vs am gear carb Model
1 21.0 6 160.0 110 3.90 2.620 16.46 0 1 4 4 Mazda RX4
2 21.0 6 160.0 110 3.90 2.875 17.02 0 1 4 4 Mazda RX4 Wag
3 22.8 4 108.0 93 3.85 2.320 18.61 1 1 4 1 Datsun 710
4 21.4 6 258.0 110 3.08 3.215 19.44 1 0 3 1 Hornet 4 Drive
5 18.7 8 360.0 175 3.15 3.440 17.02 0 0 3 2 Hornet Sportabout
6 18.1 6 225.0 105 2.76 3.460 20.22 1 0 3 1 Valiant
7 14.3 8 360.0 245 3.21 3.570 15.84 0 0 3 4 Duster 360
8 24.4 4 146.7 62 3.69 3.190 20.00 1 0 4 2 Merc 240D
9 22.8 4 140.8 95 3.92 3.150 22.90 1 0 4 2 Merc 230
> setdiff(second, first) #取second的补集
P41 R函数
类似于Linux操作系统的命令,每一条命令相当于一个软件,有其对应的功能,但R函数的纷繁众多,需要多加练习才能慢慢掌握部分。下面列出部分常用的函数。
##以state.x77为例演示R进行回归分析的优势
> state <- as.data.frame(state.x77[,c("Murder","Population","Illiteracy","Income","Frost")])
> class(state)
[1] "data.frame"
> fit<- lm (Murder ~ Population+Illiteracy+Income+Frost,data=state)
> summary(fit)
Call:
lm(formula = Murder ~ Population + Illiteracy + Income + Frost,
data = state)
Residuals:
Min 1Q Median 3Q Max
-4.7960 -1.6495 -0.0811 1.4815 7.6210
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 1.235e+00 3.866e+00 0.319 0.7510
Population 2.237e-04 9.052e-05 2.471 0.0173 *
Illiteracy 4.143e+00 8.744e-01 4.738 2.19e-05 ***
Income 6.442e-05 6.837e-04 0.094 0.9253
Frost 5.813e-04 1.005e-02 0.058 0.9541
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 2.535 on 45 degrees of freedom
Multiple R-squared: 0.567, Adjusted R-squared: 0.5285
F-statistic: 14.73 on 4 and 45 DF, p-value: 9.133e-08
##“Illiteracy 4.143e+00”文盲率的回归系数是4.14,表示在人口、收入、温度不变的情况下,文盲率上升1%,谋杀率上升4.14%,且它的系数在P < 0.001的情况下显著不为0
返回值
> ls() #当前环境中R的对象
[1] "a" "airquality" "aql" "aqw"
[5] "b" "df" "first" "fit"
[9] "gdata" "mtcars" "second" "state"
[13] "tdata" "x"
> Sys.Date() #返回当前系统时间
[1] "2020-10-12"
> rm(a) #删除对象,如果成功则不出现返回值,否则会出现错误提示
> rm(t)
Warning message:
In rm(t) : object 't' not found
##注意返回值的类型,选用不同的适用函数处理这些类型
> ?heatmap #只能处理矩阵而不能处理数据框类型
> plot() #向量和向量绘制成散点图;向量和因子绘制成条形图;
输入数据类型适用函数
向量:sum,mean,sd,range,median,sort,order
矩阵或数据框:cbind,rbind
数字矩阵:heatmap
P42 选项参数
将选项参数类比于买菜:去买菜/买啥/买多少
| 名字 | 概念 |
|---|---|
| 软件 | 相当于菜市场菜篮子 |
| 选项 | 相当于菜,选还是不选 |
| 参数 | 相当于量,选多少 |
一般选项参数分为:
1、输入控制部分
常用输入选项参数:
file:接一个文件
data:一般指要输入一个数据框;
x:表示单独的一个对象,一般都是向量,也可以是矩阵或者列表;
x和y:函数需要两个输入变量;
x,y,z:函数需要三个输入变量;
formula:公式;多用”~“连接,表示相关
na.rm:删除缺失值;
在R的帮助文档中,经常可以在选项参数部分看见”…“符号,它一般表示:
1、 如plot选项参数中的”…“表示参数可传递,也就是这部分参数与其他函数的参数是相重合的,可以通用,尤其是在R的绘图函数中,跨函数的参数几乎都适用于其他绘图函数;有”…“出现的地方表示这里省略,详细可查看后面的链接,会有详细信息。
2、 有一些函数中”…“表示没有数量限制,比如
data.frame可支持多个向量合并,rbind和cbind也是同理,一次可以给数据框或者矩阵等添加多行或者多列
2、输出控制部分
一般在R中结果直接出现在图形界面,可供调节的参数较少
3、调节部分
-
根据名字判断选项的作用
color 选项和明显用来控制颜色
select 与选择有关
font与字体有关
font.axis 就是坐标轴的字体
Ity 是line type的简写
lwd 是line width
method 软件算法
…… -
选项接受哪些参数
main:字符串,不能是向量
na.rm: TRUE或者FALSE
axis: 控制坐标轴的方向,side参数只能是1到4
fig:控制图形区域的位置,包含四个元素的向量包含row或者col的选项:表示行和列
method:如果一个统计多种算法,一般都是通过message选项设置
……
P43 数学统计函数
> x <- 1:100
> sum(x) #求和
[1] 5050
> mean(x) #求平均值
[1] 50.5
> var(x) #方差
[1] 841.6667
> sd(x) #标准差
[1] 29.01149
> log(x) #取对数
[1] 0.0000000 0.6931472 1.0986123 1.3862944 1.6094379 1.7917595 1.9459101 2.0794415 2.1972246 2.3025851 2.3978953 2.4849066 2.5649494 2.6390573 2.7080502 2.7725887
[17] 2.8332133 2.8903718 2.9444390 2.9957323 3.0445224 3.0910425 3.1354942 3.1780538 3.2188758 3.2580965 3.2958369 3.3322045 3.3672958 3.4011974 3.4339872 3.4657359
……
> abs(x) #取绝对值
[1] 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40
……
- 概率论
概率论是统计学的基础,R有许多用于处理概率,概率分布以及随机变量的函数。R对每一个概率分布都有一个简称,这个名称用于识别与分布相联系的函数。这部分涉及到很多统计学基础的理论知识,比如随机试验,样本空间,对立与互斥,随机事件与必然事件,概率密度,概率分布等。
| 字母 | 含义 |
|---|---|
| d | density 概率密度函数 |
| p | distribution 分布函数,因为d被密度函数占用,所以此处用p |
| q | quantile 分布函数的反函数,分位数 |
| r | random 产生相同分布的随机数 |
给正态分布函数Normal加上前缀d/p/q/r就构成了在R中的函数名
dnorm(x, mean = 0, sd = 1, log = FALSE) 正态概率密度函数
pnorm(q, mean = 0, sd = 1, lower.tail = TRUE, log.p = FALSE) 正态分布函数
qnorm(p, mean = 0, sd = 1, lower.tail = TRUE, log.p = FALSE) 正态分位数函数
rnorm(n, mean = 0, sd = 1) 正态分布的随机数函数
##生成满足正态分布的一组数字
> rnorm(n=100,mean=15,sd=2) #生成均值为5,方差为2的100个随机数
[1] 16.20994 13.86703 13.57459 17.59804 13.42786 14.81579 13.90097 13.66559 12.89780 14.32336 11.90792 14.13920 14.29006 12.13283 15.33791 18.00150 17.38731
[18] 13.21296 13.47545 16.59991 16.15427 16.39127 15.29226 11.78472 15.90156 15.04438 11.67756 14.90671 16.86426 17.37126 14.13865 13.65865 13.15860 13.50412
[35] 13.38559 16.48209 15.02913 14.19975 14.30231 14.69572 14.14901 15.64589 17.51535 13.16878 18.07479 14.31368 16.74095 16.46288 16.24363 16.03831 16.18030
[52] 11.86904 11.79376 13.80910 12.48360 14.28414 16.19988 14.82331 16.40078 12.90084 15.28390 17.53258 13.21655 13.10790 15.12662 16.44574 18.14601 18.08835
[69] 16.61745 18.23243 15.40259 13.84561 17.17225 17.18257 15.60987 12.78682 14.58842 14.25293 19.35957 15.03703 12.65416 10.27531 15.65968 18.58215 16.49182
[86] 16.19389 12.07531 14.94625 16.81830 14.42129 15.90670 17.67030 14.71304 17.89933 17.71255 15.39059 17.55040 12.38186 16.34006 19.95524
> round(rnorm(n=100,mean = 15,sd=2)) #取整
[1] 12 15 15 16 14 15 18 18 18 12 11 14 16 17 11 13 15 13 16 14 18 15 16 15 15 15 15 15 13 14 15 15 13 16 13 14 18 14 13 15 14 19 16 16 14 18 15 15 17 13 16 17 15
[54] 17 18 12 13 15 19 16 15 16 15 15 14 16 16 16 15 17 14 14 13 16 17 16 14 19 14 18 20 11 14 16 18 17 14 15 16 18 17 16 14 14 16 17 15 13 14 14
> ?Geometric #几何分布
> ?Hypergeometric #超几何分布
####等等许多数学概率模型,可以用于检验数据集是否符合上述这些分布
##随机数的生成
runif(1)
runif(50)
runif(10)*10
runif(50,min=1,max=100)
dgamma(c(1:9),shape = 2,rate = 1)
set.seed(666)
runif(50)
runif(50)
set.seed(666)
runif(50)
P44 描述性统计函数 补笔记
> myvars <- mtcars[c("mpg", "hp", "wt", "am")]
> summary(myvars) #能一次得到以下几种统计数据
mpg hp wt am
Min. :10.40 Min. : 52.0 Min. :1.513 Min. :0.0000 #最小值
1st Qu.:15.43 1st Qu.: 96.5 1st Qu.:2.581 1st Qu.:0.0000 #第一个四分位数
Median :19.20 Median :123.0 Median :3.325 Median :0.0000 #中位数(即第二四分位数)
Mean :20.09 Mean :146.7 Mean :3.217 Mean :0.4062 #数值型变量的均值
3rd Qu.:22.80 3rd Qu.:180.0 3rd Qu.:3.610 3rd Qu.:1.0000 #第三四分位数
Max. :33.90 Max. :335.0 Max. :5.424 Max. :1.0000 #最大值
> fivenum(myvars$mpg) #和上面的summary类似,输出除平均值以外的五个值
[1] 10.40 15.35 19.20 22.80 33.90
P45 频数统计函数
一维频数统计
描述不同组之间的差异等要用到频数统计,有因子才能分组,针对因子类型直接分组:
> mtcars
mpg cyl disp hp drat wt qsec vs am gear carb Model
1 21.0 6 160.0 110 3.90 2.620 16.46 0 1 4 4 Mazda RX4
2 21.0 6 160.0 110 3.90 2.875 17.02 0 1 4 4 Mazda RX4 Wag
3 22.8 4 108.0 93 3.85 2.320 18.61 1 1 4 1 Datsun 710
4 21.4 6 258.0 110 3.08 3.215 19.44 1 0 3 1 Hornet 4 Drive
5 18.7 8 360.0 175 3.15 3.440 17.02 0 0 3 2 Hornet Sportabout
6 18.1 6 225.0 105 2.76 3.460 20.22 1 0 3 1 Valiant
7 14.3 8 360.0 245 3.21 3.570 15.84 0 0 3 4 Duster 360
8 24.4 4 146.7 62 3.69 3.190 20.00 1 0 4 2 Merc 240D
9 22.8 4 140.8 95 3.92 3.150 22.90 1 0 4 2 Merc 230
10 19.2 6 167.6 123 3.92 3.440 18.30 1 0 4 4 Merc 280
11 17.8 6 167.6 123 3.92 3.440 18.90 1 0 4 4 Merc 280C
12 16.4 8 275.8 180 3.07 4.070 17.40 0 0 3 3 Merc 450SE
13 17.3 8 275.8 180 3.07 3.730 17.60 0 0 3 3 Merc 450SL
14 15.2 8 275.8 180 3.07 3.780 18.00 0 0 3 3 Merc 450SLC
15 10.4 8 472.0 205 2.93 5.250 17.98 0 0 3 4 Cadillac Fleetwood
16 10.4 8 460.0 215 3.00 5.424 17.82 0 0 3 4 Lincoln Continental
17 14.7 8 440.0 230 3.23 5.345 17.42 0 0 3 4 Chrysler Imperial
18 32.4 4 78.7 66 4.08 2.200 19.47 1 1 4 1 Fiat 128
19 30.4 4 75.7 52 4.93 1.615 18.52 1 1 4 2 Honda Civic
20 33.9 4 71.1 65 4.22 1.835 19.90 1 1 4 1 Toyota Corolla
21 21.5 4 120.1 97 3.70 2.465 20.01 1 0 3 1 Toyota Corona
22 15.5 8 318.0 150 2.76 3.520 16.87 0 0 3 2 Dodge Challenger
23 15.2 8 304.0 150 3.15 3.435 17.30 0 0 3 2 AMC Javelin
24 13.3 8 350.0 245 3.73 3.840 15.41 0 0 3 4 Camaro Z28
25 19.2 8 400.0 175 3.08 3.845 17.05 0 0 3 2 Pontiac Firebird
26 27.3 4 79.0 66 4.08 1.935 18.90 1 1 4 1 Fiat X1-9
27 26.0 4 120.3 91 4.43 2.140 16.70 0 1 5 2 Porsche 914-2
28 30.4 4 95.1 113 3.77 1.513 16.90 1 1 5 2 Lotus Europa
29 15.8 8 351.0 264 4.22 3.170 14.50 0 1 5 4 Ford Pantera L
30 19.7 6 145.0 175 3.62 2.770 15.50 0 1 5 6 Ferrari Dino
31 15.0 8 301.0 335 3.54 3.570 14.60 0 1 5 8 Maserati Bora
32 21.4 4 121.0 109 4.11 2.780 18.60 1 1 4 2 Volvo 142E
> mtcars$cyl <- as.factor(mtcars$cyl) #cyl的4/6/8这几类可作为因子分组
> split(mtcars,mtcars$cyl) #split分组函数
$`4`
mpg cyl disp hp drat wt qsec vs am gear carb Model
3 22.8 4 108.0 93 3.85 2.320 18.61 1 1 4 1 Datsun 710
8 24.4 4 146.7 62 3.69 3.190 20.00 1 0 4 2 Merc 240D
9 22.8 4 140.8 95 3.92 3.150 22.90 1 0 4 2 Merc 230
18 32.4 4 78.7 66 4.08 2.200 19.47 1 1 4 1 Fiat 128
19 30.4 4 75.7 52 4.93 1.615 18.52 1 1 4 2 Honda Civic
20 33.9 4 71.1 65 4.22 1.835 19.90 1 1 4 1 Toyota Corolla
21 21.5 4 120.1 97 3.70 2.465 20.01 1 0 3 1 Toyota Corona
26 27.3 4 79.0 66 4.08 1.935 18.90 1 1 4 1 Fiat X1-9
27 26.0 4 120.3 91 4.43 2.140 16.70 0 1 5 2 Porsche 914-2
28 30.4 4 95.1 113 3.77 1.513 16.90 1 1 5 2 Lotus Europa
32 21.4 4 121.0 109 4.11 2.780 18.60 1 1 4 2 Volvo 142E
$`6`
mpg cyl disp hp drat wt qsec vs am gear carb Model
1 21.0 6 160.0 110 3.90 2.620 16.46 0 1 4 4 Mazda RX4
2 21.0 6 160.0 110 3.90 2.875 17.02 0 1 4 4 Mazda RX4 Wag
4 21.4 6 258.0 110 3.08 3.215 19.44 1 0 3 1 Hornet 4 Drive
6 18.1 6 225.0 105 2.76 3.460 20.22 1 0 3 1 Valiant
10 19.2 6 167.6 123 3.92 3.440 18.30 1 0 4 4 Merc 280
11 17.8 6 167.6 123 3.92 3.440 18.90 1 0 4 4 Merc 280C
30 19.7 6 145.0 175 3.62 2.770 15.50 0 1 5 6 Ferrari Dino
$`8`
mpg cyl disp hp drat wt qsec vs am gear carb Model
5 18.7 8 360.0 175 3.15 3.440 17.02 0 0 3 2 Hornet Sportabout
7 14.3 8 360.0 245 3.21 3.570 15.84 0 0 3 4 Duster 360
12 16.4 8 275.8 180 3.07 4.070 17.40 0 0 3 3 Merc 450SE
13 17.3 8 275.8 180 3.07 3.730 17.60 0 0 3 3 Merc 450SL
14 15.2 8 275.8 180 3.07 3.780 18.00 0 0 3 3 Merc 450SLC
15 10.4 8 472.0 205 2.93 5.250 17.98 0 0 3 4 Cadillac Fleetwood
16 10.4 8 460.0 215 3.00 5.424 17.82 0 0 3 4 Lincoln Continental
17 14.7 8 440.0 230 3.23 5.345 17.42 0 0 3 4 Chrysler Imperial
22 15.5 8 318.0 150 2.76 3.520 16.87 0 0 3 2 Dodge Challenger
23 15.2 8 304.0 150 3.15 3.435 17.30 0 0 3 2 AMC Javelin
24 13.3 8 350.0 245 3.73 3.840 15.41 0 0 3 4 Camaro Z28
25 19.2 8 400.0 175 3.08 3.845 17.05 0 0 3 2 Pontiac Firebird
29 15.8 8 351.0 264 4.22 3.170 14.50 0 1 5 4 Ford Pantera L
31 15.0 8 301.0 335 3.54 3.570 14.60 0 1 5 8 Maserati Bora
针对非因子类型分组
##以mtcars中mpg这一列为例
> cut(mtcars$mpg,c(seq(10,50,10)))
[1] (20,30] (20,30] (20,30] (20,30] (10,20] (10,20] (10,20] (20,30] (20,30] (10,20] (10,20] (10,20] (10,20] (10,20] (10,20] (10,20] (10,20] (30,40] (30,40] (30,40]
[21] (20,30] (10,20] (10,20] (10,20] (10,20] (20,30] (20,30] (30,40] (10,20] (10,20] (10,20] (20,30]
Levels: (10,20] (20,30] (30,40] (40,50]
> ?table # 进行频数统计,有一维列联表和多维列联表 > table(mtcars$cyl)
4 6 8
11 7 14
> table(cut(mtcars$mpg,c(seq(10,50,10))))
(10,20] (20,30] (30,40] (40,50]
18 10 4 0
> prop.table(table(mtcars$cyl)) #proportion比率=频数除以总数
4 6 8
0.34375 0.21875 0.43750
> prop.table (table(cut(mtcars$mpg,c(seq(10,50,10)))))
(10,20] (20,30] (30,40] (40,50]
0.5625 0.3125 0.1250 0.0000
> prop.table(table(mtcars$cyl))*100 #频率✖100即所占百分比
4 6 8
34.375 21.875 43.750
多维频数统计
##多维频数统计
> library(grid)
> library(vcd)
> head(Arthritis)
ID Treatment Sex Age Improved
1 57 Treated Male 27 Some
2 46 Treated Male 29 None
3 77 Treated Male 30 None
4 17 Treated Male 32 Marked
5 36 Treated Male 46 Marked
6 23 Treated Male 58 Marked
> table(Arthritis$Treatment,Arthritis$Improved) #返回的是二维列联表
None Some Marked
Placebo 29 7 7
Treated 13 7 21
> with(data = Arthritis,{table(Treatment,Improved)}) #变量多可以用with函数提前加载数据
Improved
Treatment None Some Marked
Placebo 29 7 7
Treated 13 7 21
> ?xtabs #处理二维列联表,可使用formula参数
> xtabs(~ Treatment+Improved, data=Arthritis)#~ Treatment+Improved表示根据这两个参数进行计算
Improved
Treatment None Some Marked
Placebo 29 7 7
Treated 13 7 21
> ?margin.table #边际频数统计,单独按照行或者列来统计处理(对于数组形式的列联表,请计算给定边距或一组边距的表项总和。)
> x <- xtabs(~ Treatment+Improved, data=Arthritis)
> margin.table(x) #不给定第二个参数则计算的是总和
[1] 84
> margin.table(x,1) # 1表示行总和row sums
Treatment
Placebo Treated
43 41
> margin.table(x,2) # 2表示列总和colnum sums
Improved
None Some Marked
42 14 28
> prop.table(x,1) #以行总和为分母计算频率
Improved
Treatment None Some Marked
Placebo 0.6744186 0.1627907 0.1627907
Treated 0.3170732 0.1707317 0.5121951
> addmargins(x) #将边际和添加到频数表中
Improved
Treatment None Some Marked Sum
Placebo 29 7 7 43
Treated 13 7 21 41
Sum 42 14 28 84
> addmargins(x,1) #同样可以设置只添加行或者列
Improved
Treatment None Some Marked
Placebo 29 7 7
Treated 13 7 21
Sum 42 14 28
> addmargins(x,2)
Improved
Treatment None Some Marked Sum
Placebo 29 7 7 43
Treated 13 7 21 41
##三维列联表的频数统计
> x <- xtabs(~ Treatment+Improved+Sex, data=Arthritis)
> x
, , Sex = Female
Improved
Treatment None Some Marked
Placebo 19 7 6
Treated 6 5 16
, , Sex = Male
Improved
Treatment None Some Marked
Placebo 10 0 1
Treated 7 2 5
> ftable(xtabs(~ Treatment+Improved+Sex, data=Arthritis)) #转换成屏幕式更为简洁的列联表
Sex Female Male
Treatment Improved
Placebo None 19 10
Some 7 0
Marked 6 1
Treated None 6 7
Some 5 2
Marked 16 5
P46 独立性检验函数
独立性检验是根据频数信息判断两类因子彼此相关或相互独立的假设检验。所谓独立性就是指变量之间是独立的,没有关系。
比如一种药物单独对男性起作用或者单独对女性起作用,这就是独立性,反之就是相关性
假设检验
假设检验(Hypothesis Testing)是数理统计学中根据一定假设条件由样本推断总体的一种方法。原假设——没有发生;备择假设——发生了;
具体作法是:根据问题的需要对所研究的总体作某种假设,记作HO;选取合适的统计量,这个统计量的选取要使得在假设HO成立时,其分布为已知;由实测的样本,计算出统计量的值,并根据预先给定的显著性水平进行检验,作出拒绝或接受假设HO的判断。
假设检验中两个假设的选取是个重要问题,通常应遵循以下原则:
-
应当把如果它成立但是误判为不成立时后会造成严重后果的命题选为原假设。
例如,要检验治疗心脏病的药是否有效。原假设应当选为该药无效,因为如果该药本身的确是无效的,但是误判为有效,那么心脏病人急用时因为它无效会造成病人死亡,这属于严重后果。
-
应当把分析人员想证明它正确的命题作为备择假设,把分析人员努力证明它不正确的命题作为原假设.
例如,据说有一种新方法可能够改进生产效率,我们想知道这是否是真的。我们希望这是真的,并努力证明这是真的,所以应把这种新方法能改进生产效率作为备择假设。
-
应当把大众普遍认为它成立的命题作为原假设。因为原假设不能轻易拒绝,除非有足够的证据表明它不对。
例如,据说跑步有益健康,我们想知道这是否是真的。因为是常识,所以应把跑步有益健康选作原假设。
p-value
p-value就是Probability的值,它是一个通过计算得到的概率值,也就是在原假设为真时,得到最大的或者超出所得到的检验统计量值的概率。
一般将p值定位到0.05,当p<0.05拒绝原假设,p>0.05,不拒绝原假设。原假设:研究者想收集证据予以反对的假设。
备择假设:研究者想收集证据予以支持的假设。
总而言之,P值越大越靠谱(符合原假设),越小越不靠谱
P值可根据数据噪音大小调整,背景噪音大临界值可以是0.1,对于要求精确的数据临界值可以是0.01
卡方检验
卡方检验是一种用途很广的计数资料的假设检验方法。它属于非参数检验的范畴,主要是比较两个及两个以上样本率( 构成比)以及两个分类变量的关联性分析。其根本思想就是在于比较理论频数和实际频数的吻合程度或拟合优度问题。
通俗解释就是检验两个参数之间有没有关系
> library(grid)
> library(vcd)
mytable <- table(Arthritis$Treatment,Arthritis$Improved) #依然以风湿病数据集为例,H0:变量之间独立
> ?chisq.test #列联表的卡方检验与拟合
> chisq.test(mytable)
Pearson's Chi-squared test
data: mytable
X-squared = 13.055, df = 2, p-value = 0.001463
##原假设是没有效果,这里P值小于0.05,说明有效
> mytable <- table(Arthritis$Sex,Arthritis$Improved)
> chisq.test(mytable)
Pearson's Chi-squared test
data: mytable
X-squared = 4.8407, df = 2, p-value = 0.08889 #P值大于0.05,说明Sex和Improved两个因素可能独立
Warning message:
In chisq.test(mytable) : Chi-squared近似算法有可能不准
Fisher精确概率检验
Fisher精确概率检验是用来判断两bai个变量之间是否存du在非随机相关性zhi的一种统计学检验方法。
> mytable <- xtabs(~Treatment+Improved, data=Arthritis)
> fisher.test(mytable)
Fisher's Exact Test for Count Data
data: mytable
p-value = 0.001393 ##和卡方检验的P值0.0014稍有出入,但都小于0.05,说明变量不独立,拒绝原假设
alternative hypothesis: two.sided
Cochran-Mantel-Haenszel检验
> ?mantelhaen.test #假设不存在三向交互作用,则对两个标称变量在每个层中有条件独立的零值执行Cochran-Mantel-Haenszel卡方检验。(即三个变量相互独立,进行检验)
> mytable <- xtabs(~Treatment+Improved+Sex, data=Arthritis)
> mytable
, , Sex = Female
Improved
Treatment None Some Marked
Placebo 19 7 6
Treated 6 5 16
, , Sex = Male
Improved
Treatment None Some Marked
Placebo 10 0 1
Treated 7 2 5
> mantelhaen.test(mytable)
Cochran-Mantel-Haenszel test
data: mytable
Cochran-Mantel-Haenszel M^2 = 14.632, df = 2, p-value
= 0.0006647 ##P值小于0.005,拒绝原假设,三个变量不独立
> mytable <- xtabs(~Treatment+Sex+Improved, data=Arthritis) #调换变量顺序会出现不同结果
> mantelhaen.test(mytable)
Mantel-Haenszel chi-squared test with continuity
correction
data: mytable
Mantel-Haenszel X-squared = 2.0863, df = 1, p-value =
0.1486
alternative hypothesis: true common odds ratio is not equal to 1
95 percent confidence interval:
0.8566711 8.0070521
sample estimates:
common odds ratio
2.619048
> mytable #出现不同结果的原因是分组依据上的变化
, , Improved = None
Sex
Treatment Female Male
Placebo 19 10
Treated 6 7
, , Improved = Some
Sex
Treatment Female Male
Placebo 7 0
Treated 5 2
, , Improved = Marked
Sex
Treatment Female Male
Placebo 6 1
Treated 16 5
课程外=
Mann-Whitney U 检验是用得最广泛的两独立样本秩和检验方法。简单的说,该检验是与独立样本t检验相对应的方法,当正态分布、方差齐性等不能达到t检验的要求时,可以使用该检验。其假设基础是:若两个样本有差异,则他们的中心位置将不同。
P47 相关性分析函数
相关性分析是指对两个或多个具备相关性的变量元素进行分析,从而衡量两个变量因素的相关密切程度。相关性的元素之间需要存在一定的联系或者概率才可以进行相关性分析。简单来说就是变量之间是否有关系。
相关性衡量指标:Pearson相关系数、Spearman相关系数、Kendall相关系数、偏相关系数、多分格(polychoric)相关系数和多系列(polyserial)相关系数
> ?cor #var,cov和cor计算x的方差以及x和y的协方差或相关性(如果它们是向量)。 如果x和y是矩阵,则计算x列与y列之间的协方差(或相关性)。可选是否删除NA以及选用哪种相关系数进行衡量。
> cor(state.x77)
Population Income Illiteracy Life Exp Murder HS Grad Frost Area
Population 1.00000000 0.2082276 0.10762237 -0.06805195 0.3436428 -0.09848975 -0.3321525 0.02254384
Income 0.20822756 1.0000000 -0.43707519 0.34025534 -0.2300776 0.61993232 0.2262822 0.36331544
Illiteracy 0.10762237 -0.4370752 1.00000000 -0.58847793 0.7029752 -0.65718861 -0.6719470 0.07726113
Life Exp -0.06805195 0.3402553 -0.58847793 1.00000000 -0.7808458 0.58221620 0.2620680 -0.10733194
Murder 0.34364275 -0.2300776 0.70297520 -0.78084575 1.0000000 -0.48797102 -0.5388834 0.22839021
HS Grad -0.09848975 0.6199323 -0.65718861 0.58221620 -0.4879710 1.00000000 0.3667797 0.33354187
Frost -0.33215245 0.2262822 -0.67194697 0.26206801 -0.5388834 0.36677970 1.0000000 0.05922910
Area 0.02254384 0.3633154 0.07726113 -0.10733194 0.2283902 0.33354187 0.0592291 1.00000000
##在R中进行相关性的计算很容易,但关键在于分析,也就是数据的挖掘,比如计算得到的结果这是一个典型的斜对角数据集,相关性的区间[-1,1],每个因素跟自己比较相关性都是1,比如看Murder这一列,跟收入Illiteracy的相关性达到0.7,以及跟高中毕业与否HS Grad因素相关性达到0.58,都有很强的相关关系,说明教育程度和谋杀存在关联