opencv手写数字识别(未完待续...)
1. 准备工作
下载MNIST数字集 : http://yann.lecun.com/exdb/mnist/
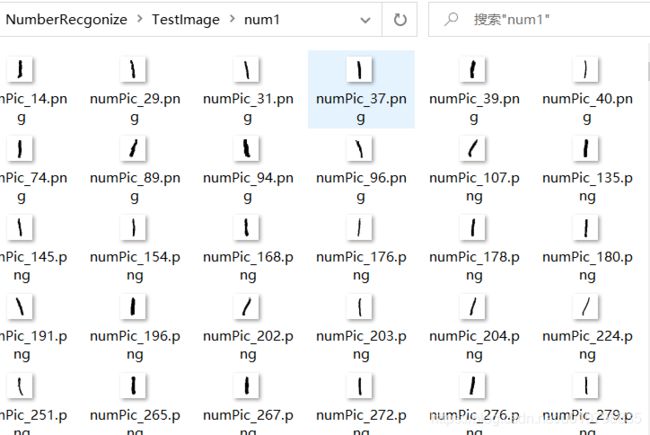
使用python将数据集提取出来,转换成图片,转化后图片像这样的
数据集解读和保存如下(代码以测试文件为例):
import numpy as np
import struct
import matplotlib
import matplotlib.pyplot as plt
savePath = r'pictures\NumberRecgonize\TestImage'
#测试集文件
t10kImages = r'pictures\NumberRecgonize\t10k-images.idx3-ubyte'
t10kILabels = r'pictures\NumberRecgonize\t10k-labels.idx1-ubyte'
#训练集文件
trainImages = r'pictures\NumberRecgonize\train-images.idx3-ubyte'
trainLabels = r'pictures\NumberRecgonize\train-labels.idx1-ubyte'
f=open(savePath+ r"\imgpathAndLabel.csv","w+")
#读取bin文件
bin_image_data = open(t10kImages, 'rb').read()
bin_label_data = open(t10kILabels, 'rb').read()
#文件偏移和image、label的头文件格式
image_offset = 0
label_offset = 0
fmt_image_header = '>iiii'
fmt_label_header = '>ii'
magic_number, num_images, num_rows, num_cols = struct.unpack_from(fmt_image_header, bin_image_data, image_offset)
print('魔数:%d, 图片数量: %d张, 图片大小: %d*%d' % (magic_number, num_images, num_rows, num_cols))
#magic_number, num_images, num_rows, num_cols = struct.unpack_from(fmt_label_header, bin_label_data, label_offset)
#print('魔数:%d, 图片数量: %d张, 图片大小: %d*%d' % (magic_number, num_images, num_rows, num_cols))
image_size = num_rows * num_cols
image_offset += struct.calcsize(fmt_image_header)
label_offset += struct.calcsize(fmt_label_header)
print(image_offset)
#文件占用多少存储空间 , 一张图片28*28 = 784; 数字标签 1
fmt_image = '>' + str(image_size) + 'B'
fmt_lable = '>B'
print(fmt_image, image_offset, struct.calcsize(fmt_image))
print(fmt_lable, label_offset, struct.calcsize(fmt_lable))
images = np.empty((num_images, num_rows, num_cols)) #大内存申请尽量避免呢,不过MNIST不是很大
labels = np.empty(num_images)
for i in range(num_images):#num_images
if(i + 1) % 1000 == 0 :
print('已解析 %d' % (i+1) + '张')
print(image_offset)
images[i] = np.array(struct.unpack_from(fmt_image, bin_image_data, image_offset)).reshape(num_rows, num_cols)
#黑色背景转换为黑色背景 白字,当然根据自己的需要调整 黑纸白字也可以
images[i] = 255 - images[i]
labels[i] = np.array(struct.unpack_from(fmt_lable, bin_label_data, label_offset))[0]
#保存图片路径
imageSavePath = savePath+r'\num%d\numPic_%d'%(int(labels[i]),i) + '.png'
matplotlib.image.imsave(imageSavePath, images[i], cmap='gray')
#写入图片路径和标签
f.write(imageSavePath+';%d\n'%(int(labels[i])))
#print(int(labels[i]))
image_offset += struct.calcsize(fmt_image)
label_offset += struct.calcsize(fmt_lable)
f.close()2. KNN数字识别
2.1. 原理: 每一张图片是28 * 28大小的图片, 如果训练数据有500张图片,其中每一个阿拉伯数字出现的次数大致相同(叫训练图片可能不太妥当,没有训练过程可以叫“已知标签的图片”), 待测图片的大小也为28*28的大小, 测试时候计算 待检测图片和每一张训练图片的距离,这样就得到了待测图片与所有训练图片的距离(一个500的数组), 找到前K个距离最短的图片,K个图片中标签出现次数最多的就可以假设为这一张待测图片中的标签。 比如 算出K个最近图片中标签为3的图片出现超过K/2,则可以认为待检测图片中的数字为3。
2.2 OpenCV代码
#include
#include
using namespace std;
using namespace cv;
using namespace cv::ml;
int main()
{
string filename = string("NumberRecgonize/TestImage/imgpathAndLabel.csv");
string modelPath = string("NumberRecgonize/TestImage/testData.xml");
ifstream file(filename.c_str(), ifstream::in);
if (!file)
{
cout << "could not load file correctlly ..." << endl;
getchar();
return -1;
}
bool trainSelect = false; // 已经生成好模型就不用训练了
Ptr knn = KNearest::create();
knn->setDefaultK(10);
knn->setIsClassifier(true);
if (trainSelect)
{
string line, path, label;
Mat images, labels;
char separator = ';';
Mat readImg, grayImg, reshapImg;
while (getline(file, line))
{
stringstream liness(line);
getline(liness, path, separator);
getline(liness, label);
if (!path.empty() && !label.empty())
{
//cout << "path : " << path << endl;
readImg = imread(path, 0);
//int tmp = readImg.channels();
// 读取的图片本身是gray的
grayImg = readImg;
//cvtColor(readImg, grayImg, CV_BGR2GRAY);
threshold(grayImg, grayImg, 0, 255, CV_THRESH_OTSU);
reshapImg = grayImg.reshape(1, 1);
reshapImg.convertTo(reshapImg, CV_32FC1);
images.push_back(reshapImg);
//labels.push_back(path);
labels.push_back(atoi(label.c_str()));
}
}
// 训练数据和标签 进行训练
Ptr trainData = TrainData::create(images, ROW_SAMPLE, labels);
// 训练生成模型
knn->train(trainData);
knn->save(modelPath);
}
else
{
// 模型保存下来了,下一次进行训练后可以直接加载
// knn->read(modelPath); --- no function
knn = StatModel::load(modelPath);
}
Mat src = imread("NumberRecgonize/numPic_97.png");
Mat grayImg, input;
cvtColor(src, grayImg, CV_BGR2GRAY);
threshold(grayImg, grayImg, 0,255, CV_THRESH_OTSU);
imshow("train src", grayImg);
input = grayImg.reshape(1,1);
input.convertTo(input, CV_32FC1);
float r = knn->predict(input);
cout << r << endl;
waitKey(0);
return 0;
} 2.3 结果展示 可以看出这一种方法还是有一定计算错误,毕竟需要大量的数据去测试,而且一张图片数字可能出现再不同的位置,这样计算距离的时候可能也有很大的差异。
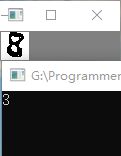
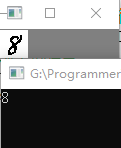
2.4. KNN 数字识别Python 代码,使用tensorflow计算,python代码如下
# -*- coding: utf-8 -*-
"""
Created on Mon Apr 13 16:36:18 2020
@author: Administrator
"""
import tensorflow as tf
import numpy as np
import random
from tensorflow.examples.tutorials.mnist import input_data
#load pictures
mnist = input_data.read_data_sets('MNIST_data', one_hot = True)
trainNum = 55000
testNum = 10000
trainSize = 5000
testSize = 5
k = 4 #KNN 中与哪几个图片相似,这几张图片中属于哪一个标签更多,就属于哪一个类别
#数据获取和分解,将数据全部分解
trainIdx = np.random.choice(trainNum, trainSize, replace=False)
testIdx = np.random.choice(testNum, testSize, replace=False)
trainData = mnist.train.images[trainIdx]
trainLabel = mnist.train.labels[trainIdx]
testData = mnist.test.images[testIdx]
testLabel = mnist.test.labels[testIdx]
print('trainData.shape=',trainData.shape)
print('trainLabel.shape=',trainLabel.shape)
print('testData.shape=',testData.shape)
print('testLabel.shape=',testLabel.shape)
# tf input tensorflow里对于暂时不进行赋值的元素有一个称呼叫占位符。所谓占位符,顾名思义,先占着茅坑不拉屎,等需要时再赋值。所需要的命令为tf.placeholder
# feed_dict就是用来赋值的,格式为字典型
trainDataInput = tf.placeholder(shape=[None, 784], dtype=tf.float32)
trainLabelInput = tf.placeholder(shape=[None,10], dtype = tf.float32)
testDataInput = tf.placeholder(shape=[None, 784], dtype=tf.float32)
testlableInput = tf.placeholder(shape=[None,10], dtype=tf.float32)
#knn distance 5*784
f1 = tf.expand_dims(testDataInput,1)
f2 = tf.subtract(trainDataInput,f1)
f3 = tf.reduce_sum(tf.abs(f2),reduction_indices=2)
f4 = tf.negative(f3) ## 取反
# f55 存放最近的距离, f6存放数组的下标与最近四个样本对应
f5,f6 = tf.nn.top_k(f4,k=4)
#f7 收集最近标签信息
f7 = tf.gather(trainLabelInput, f6)
#f8 数据的累加,将可能数据进行累加; f9 num的获取,为预测结果
f8 = tf.reduce_sum(f7, reduction_indices=1)
f9 = tf.argmax(f8,dimension=1)
#获取测试数据真是的结果
f10 = tf.argmax(testlableInput,dimension=1)
with tf.Session() as sess:
#f1 <- testData
p1 = sess.run(f1,feed_dict={testDataInput:testData[0:5]})
print('p1=', p1.shape)
p2 = sess.run(f2,feed_dict={trainDataInput:trainData, testDataInput:testData[0:5]})
print('p2=', p2.shape)
p3 = sess.run(f3,feed_dict={trainDataInput:trainData, testDataInput:testData[0:5]})
print('p3=',p3.shape)
print('p3[0,0]=',p3[0,0])
p4 = sess.run(f4, feed_dict={trainDataInput:trainData, testDataInput:testData[0:5]})
print('p4=', p4.shape)
p5,p6 = sess.run((f5,f6),feed_dict={trainDataInput:trainData, testDataInput:testData[0:5]})
print('p5.shape=', p5.shape)
print('p6.shape=', p6.shape)
print('p5[0,0]=',p5[0,0])
print('p6[0,0]=',p6[0,0])
p7 = sess.run(f7,feed_dict={trainDataInput:trainData, testDataInput:testData[0:5], trainLabelInput:trainLabel})
print('p7.shape=',p7.shape)
p8 = sess.run(f8,feed_dict={trainDataInput:trainData, testDataInput:testData[0:5], trainLabelInput:trainLabel})
print('p8.shape = ', p8.shape)
print('p8[]', p8)
p9 = sess.run(f9,feed_dict={trainDataInput:trainData, testDataInput:testData[0:5], trainLabelInput:trainLabel})
#print('p9.shape = ', p9.shape)
print('p9[]', p9)
p10 = sess.run(f10, feed_dict={testlableInput:testLabel})
#print('p10.shape = ', p10.shape)
print('p10[]', p10)
结果展示 python代码中 trainSize = 5000,训练样本足够,得到的结果准确率够高
p9[] [8 0 3 1 1]
p10[] [8 0 3 1 1]
如果将 trainSize 更改更小一些,trainSize = 500,有时候还是会出现识别错误的
p9[] [4 1 6 4 6]
p10[] [4 1 6 4 0]
ps:代码中下载 mnist 如果没有网络可能会出现错误,可以事先下载好放在工程目录/MNIST_data下面(不用解压出来),下载MNIST数字集 : http://yann.lecun.com/exdb/mnist/
3. 神经网络数字识别 tensorflow2.1版本
具体代码讲解见大牛的: 简单粗暴 TensorFlow 2
迭代进行以下步骤:
-
从 DataLoader 中随机取一批训练数据;
-
将这批数据送入模型,计算出模型的预测值;
-
将模型预测值与真实值进行比较,计算损失函数(loss)。这里使用
tf.keras.losses中的交叉熵函数作为损失函数; -
计算损失函数关于模型变量的导数;
-
将求出的导数值传入优化器,使用优化器的
apply_gradients方法更新模型参数以最小化损失函数
import numpy as np
import tensorflow as tf
class MNISTLoader():
def __init__(self):
mnist = tf.keras.datasets.mnist
(self.train_data, self.train_label), (self.test_data, self.test_label) = mnist.load_data()
self.train_data = np.expand_dims(self.train_data.astype(np.float32) / 255.0, axis=-1)
self.test_data = np.expand_dims(self.test_data.astype(np.float32) / 255.0, axis=-1)
self.train_label = self.train_label.astype(np.int32)
self.test_label = self.test_label.astype(np.int32)
self.num_train_data, self.num_test_data = self.train_data.shape[0], self.test_data.shape[0]
def get_batch(self, batch_size):
index = np.random.randint(0, self.num_train_data, batch_size)
return self.train_data[index, :], self.train_label[index]
class MLP(tf.keras.Model):
def __init__(self):
super().__init__()
self.flatten = tf.keras.layers.Flatten()
self.dense1 = tf.keras.layers.Dense(units=100, activation=tf.nn.relu)
self.dense2 = tf.keras.layers.Dense(units=10)
def call(self, inputs):
x = self.flatten(inputs)
x = self.dense1(x)
x = self.dense2(x)
output = tf.nn.softmax(x)
return output
class CNN(tf.keras.Model):
def __init__(self):
super().__init__()
self.conv1 = tf.keras.layers.Conv2D(
filters=32,
kernel_size=[5,5],
padding='same',
activation=tf.nn.relu
)
self.pool1 = tf.keras.layers.MaxPool2D(pool_size=[2,2], strides=2)
self.conv2 = tf.keras.layers.Conv2D(
filters=64,
kernel_size=[5,5],
padding='same',
activation=tf.nn.relu
)
self.pool2 = tf.keras.layers.MaxPool2D(pool_size=[2,2], strides=2)
self.flatten = tf.keras.layers.Reshape(target_shape=(7*7*64, ))
self.dense1 = tf.keras.layers.Dense(units=1024, activation=tf.nn.relu)
self.dense2 = tf.keras.layers.Dense(units=10)
def call(self, inputs):
x = self.conv1(inputs)
x = self.pool1(x)
x = self.conv2(x)
x = self.pool2(x)
x = self.flatten(x)
x = self.dense1(x)
x = self.dense2(x)
output = tf.nn.softmax(x)
return output
num_epochs = 5
batch_size = 50
learning_rate = 0.001
model = CNN() # or model = MLP()
data_loader = MNISTLoader()
optimizer = tf.keras.optimizers.Adam(learning_rate = learning_rate)
num_batches = int(data_loader.num_train_data // batch_size * num_epochs)
for batch_index in range(num_batches):
X,y = data_loader.get_batch(batch_size)
with tf.GradientTape() as tape:
y_pred = model(X)
loss = tf.keras.losses.sparse_categorical_crossentropy(y_true=y, y_pred=y_pred)
loss = tf.reduce_mean(loss)
print("batch %d; loss %f" %(batch_index, loss.numpy()))
grads = tape.gradient(loss, model.variables)
optimizer.apply_gradients(grads_and_vars=zip(grads, model.variables))
sparse_categorical_accuracy = tf.keras.metrics.SparseCategoricalAccuracy()
num_batches = int(data_loader.num_test_data // batch_size)
for batch_index in range(num_batches):
start_index, end_index = batch_index * batch_size, (batch_index + 1) * batch_size
y_pred = model.predict(data_loader.test_data[start_index : end_index])
sparse_categorical_accuracy.update_state(y_true=data_loader.test_label[start_index: end_index],y_pred=y_pred)
print("test accuracy: %f" % sparse_categorical_accuracy.result())
4.