Spark GraphX图计算入门
一.什么是图计算
图计算,可以简单理解为以图这种数据结构为基础,整合相关算法来实现对应应用的计算模型。社交网络中人与人之间的关系,如果用计算机数据结构表示,最合适的就是图了。其中图的顶点表示社交中的人,边表示人与人之间的关系。所以要做社交网络分析,先要了解图计算,这是整个分析的基础。也正如此,Spark的图计算库叫GraphX。
二.图的基本概念
图是基础的数据结构,和链表、树不同,它是一种非线性数据结构。其基本结构很简单,如下图:
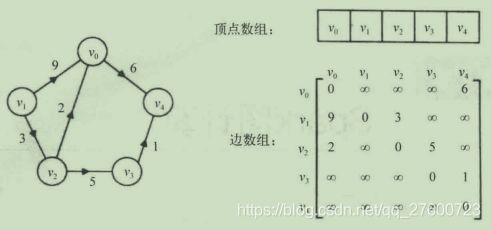
一个图由定点集V和定点间的关系集合E组成,可以用二元组定义为G=(V,E)。图中各数据元素之间的关系可以是任意的,且它描述的是多对多的关系。
例如,上图中定点的基础就表示为:
![]()
边的集合则表示为:
![]()
这是一个有向图。边有方向,(v1,v2)和(v2,v1)表示不同的两条边。若边无方向,则是无向图。
基于图的数据结构衍生出了很多基础算法,例如遍历、最小生成树、最短路径等。比如,著名的Prim算法和Kruskal算法,就是计算最小生成树。
业界也有很多开源的图计算库,常见的如Python的NetworkX、Spark的GraphX等。这些库基本都提供3类API接口,如下:
- 图生成。将文本、日志等数据转换为图的数据结构。
- 访问图数据。查询顶点数、边数;计算某个顶点的出度和入度等。
- 图算法。遍历节点和边、计算图的连通性、计算最大子图、图的合并等基本算法。
三.图计算的应用
基于图的结构有很多应用场景,比如淘宝的商品推荐、腾讯的好友推荐,再比如一些网络路由算法、SNA、Language Modeling等也都会用到图计算。
图的计算量一般都比较大,而且通常会有多次迭代。比如,若简单地计算顶点出入度,时间复杂度就是O(n * m)。想腾讯这种公司的数据级别,基本是不可完成的任务。如果能将算法并行化,利用机器数量弥补速度,这将是件美好的事情。
四.Spark GraphX简介
为了提高图计算的速度,很多企业、社区都提供了并行的图计算解决方案,常见的有Pregel、PowerGraph、Graphlib等。当然,Spark的GraphX是其中的新秀和佼佼者。它依托Spark的强大计算能力,提供了图计算需要的便捷API,同时兼具并行计算的性能,是做大规模图计算的一把利器。
五.GraphX实现
总所周知,Spark抽象了一个通用的数据结构RDD来代表运算中需要的各种数据类型。GraphX的核心数据结构则是GraphX,这是一种携带每个点属性和边属性的有向多重图。所谓多重图,就是一对源、目的节点之间允许存在多条边,以便表示不同的关系【如既是同学,又是同事】。下面是GraphX的定义:
/**
1. The Graph abstractly represents a graph with arbitrary objects
2. associated with vertices and edges. The graph provides basic
3. operations to access and manipulate the data associated with
4. vertices and edges as well as the underlying structure. Like Spark
5. RDDs, the graph is a functional data-structure in which mutating
6. operations return new graphs.
7. 8. @note [[GraphOps]] contains additional convenience operations and graph algorithms.
9. 10. @tparam VD the vertex attribute type
11. @tparam ED the edge attribute type
*/
abstract class Graph[VD: ClassTag, ED: ClassTag] protected () extends Serializable {
/**
12. An RDD containing the vertices and their associated attributes.
13. 14. @note vertex ids are unique.
15. @return an RDD containing the vertices in this graph
*/
val vertices: VertexRDD[VD]
/**
16. An RDD containing the edges and their associated attributes. The entries in the RDD contain
17. just the source id and target id along with the edge data.
18. 19. @return an RDD containing the edges in this graph
20. 21. @see `Edge` for the edge type.
22. @see `Graph#triplets` to get an RDD which contains all the edges
23. along with their vertex data.
24. */
val edges: EdgeRDD[ED]
}
Graph的数据结构比较简单,由VertexRDD[VD]和EdgeRDD[ED]组成,VD和ED分别表示顶点和边的抽象数据结构,实际等价于RDD[(VertexID, VD)]和RDD[Edge[ED]]这两种RDD。
GraphX内部是如何存储一个图的?它借鉴了PowerGraph,使用了Vertex-Cut【点分割】方式,即将图的顶点集合划分好不同的计算节点上,这样可以减少分布式计算时的通信和存储消耗。
一个图的点分割存储方式如下:
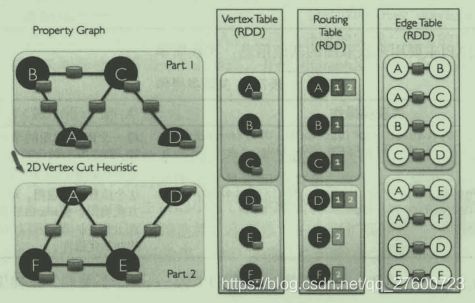
GraphX内部维护了3个RDD来存储一个图:一个是顶点表,存储顶点信息;一个是边表,存储边信息;一个是路由表,用来存储顶点在哪个计算节点上。按照Vertex-Cut方式,顶点信息仅存储一份,A,B,C顶点存储在节点1上,D,E,F存储在节点2上。当需要把边和顶点做关联计算时,比如计算出入度,则按如下方式计算:
- 遍历边表,获取每条表的顶点ID。
- 根据顶点ID查询路由表,找到该顶点的存储节点。
- 将边信息广播到顶点所属的存储节点上,做并行计算。
- 输出每个顶点的计算结果。
六.GraphX常用API介绍
GraphX的API分为几类:数据查询、数据转换、结构转换、关联聚合、缓存操作等。基本上图的操作,只需要一个函数调用即可完成,大大精简了图计算的程序设计。这样一来,可以聚焦在算法的实现逻辑上,而不用太关心数据结构本身。
在图计算中最常用的API有3类:数据查询类、关联类和聚合类。
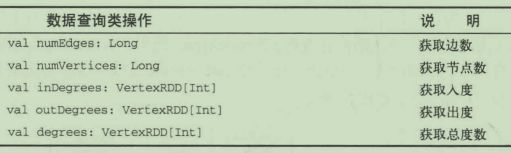
数据查询类API主要用来获取图的基础信息,比较简单。
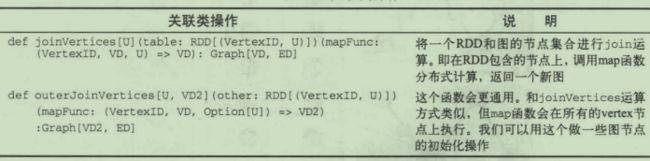
关联类API是将一个图和一个RDD通过节点ID关联,使图获得RDD中的信息。

聚合类API的作用不太容易理解。它的一个典型应用场景就是计算每个节点的出度和入度:sendMsg会把边EdgeContext的权值信息Msg分别发送到该有向边的源节点和目的节点,通过mergeMsg累加即可得到各节点的出度和入度。
//计算每个目的节点的入度,作为权值
//(Long, Long)表示这个节点的入度和出度
val nodeWeightMapFuncEx = (ctx : EdgeContext[VD, Long, (Long, Long)]) => {
ctx.sendToDst((ctx.attr, 0L))
ctx.sendSrc((0L, ctx.attr))
}
//对一个节点的边信息做聚合。入度相加,出度相加
val nodeWeightReduceFuncEx = (e1 : (Long, Long), e2 : (Long, Long)) => (e1._1 + e2._1, e1._2 + e2._2)
val nodeWeights = graph.aggregageMessages(nodeWeightMapFuncEx, nodeWeightReduceFuncEx)
这样nodeWeights : VertexRDD[(Long, Long)]就包含了每个节点的入度、出度值。
七.PageRank代码案例
package spark2.graphx
import org.apache.log4j.{
Level, Logger}
import org.apache.spark.graphx.GraphLoader
import org.apache.spark.sql.SparkSession
/**
* Created by Administrator on 2020/8/18.
*/
object PageRankExample {
/**
* 设置日志级别
*/
Logger.getLogger("org").setLevel(Level.WARN)
def main(args: Array[String]) {
val spark = SparkSession.builder().appName(s"${this.getClass.getSimpleName}").master("local[2]").getOrCreate()
val sc = spark.sparkContext
// 构建图
val graph = GraphLoader.edgeListFile(sc, "D:\\software\\spark-2.4.4\\data\\graphx\\followers.txt")
// 执行PageRank
val ranks = graph.pageRank(0.0001).vertices
// 加载顶点属性数据
val users = sc.textFile("D:\\software\\spark-2.4.4\\data\\graphx\\users.txt").map(row => {
val fields = row.split(",")
(fields(0).toLong, fields(1))
})
/**
* 关联数据
*/
val ranksByUsername = users.join(ranks).map(row => (row._2._1, row._2._2))
// 打印结果
ranksByUsername.foreach(println)
// 关闭入口
spark.stop()
}
}
执行结果:
