Leetcode.1743.从相邻元素对还原数组之HashMap取值为什么这么快?
Leetcode.1743.从相邻元素对还原数组之HashMap取值为什么这么快?
- 一、Leetccode1743多种处理方式
- 二、各种处理方法详解
-
- 1、带头尾指针的单向链表
-
- 1、理论知识
- 2、源代码
- 2、ArrayList
-
- 1、理论知识
- 2、源代码
- 3、HashMap
-
- 1、理论知识
- 2、源代码
- 三、扩展--为什么HashMap查找元素这么快?
一、Leetccode1743多种处理方式
刷题打卡第三天,中等题。
秉承着培养算法思维与独立思考的能力,其实第一次就是对的,只是它的测试数据确实太大,我点开看详情,发现输入数据有平时训练神经网络的样本数据那样大了。
独立思考路线:
->自己写链表,想用带头指针和尾指针的单向链表实现。
->对输出的数据用ArrayList
->输入数据输出数据都用ArrayList
->HashMap
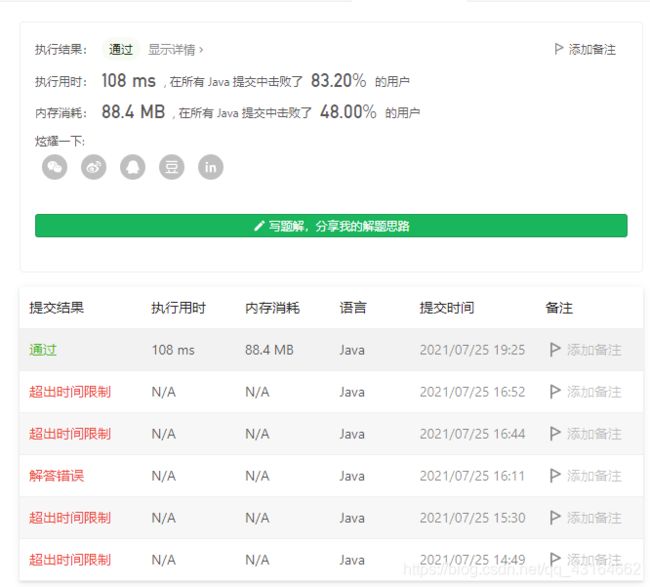
二、各种处理方法详解
1、带头尾指针的单向链表
第一次尝试,这种想法是没有错的,只是这是一个中等难度的题,对时间复杂度的要求很高。
1、理论知识
1、建立带头尾指针的单向链表
2、通过循环来寻找左右想领元素
3、通过头插法尾插法来进行左右元素插入
4、时间复杂度:a. 运行次数k=(n-1)*n/2
b. 时间复杂度为O(n^2)
2、源代码
class Node {
private int data;
private Node next;
public Node() {
}
public Node(int data, Node next) {
this.data = data;
this.next = next;
}
public int getData() {
return data;
}
public void setData(int data) {
this.data = data;
}
public Node getNext() {
return next;
}
public void setNext(Node next) {
this.next = next;
}
}
public static int[] restoreArray(int[][] adjacentPairs) {
Node l = new Node();
l.setNext(null);
Node r = new Node();
r.setNext(null);
Node lp = new Node();
Node rp = new Node();
lp = l;
rp = r;
l.setData(adjacentPairs[0][0]);
r.setData(adjacentPairs[0][1]);
l.setNext(r);
adjacentPairs[0][0] = adjacentPairs[0][1] = 0;
for (int i = 1; i < adjacentPairs.length; i++) {
Node data = new Node();
for (int j = 0; j < adjacentPairs.length; j++) {
if (adjacentPairs[j][0] == adjacentPairs[j][1])
continue;
if (adjacentPairs[j][0] != lp.getData() && adjacentPairs[j][0] != rp.getData() && adjacentPairs[j][1] != lp.getData() && adjacentPairs[j][1] != rp.getData())
continue;
if (adjacentPairs[j][0] == lp.getData()) {
data.setData(adjacentPairs[j][1]);
data.setNext(lp);
lp = data;
} else if (adjacentPairs[j][0] == rp.getData()) {
rp.setNext(data);
data.setNext(null);
data.setData(adjacentPairs[j][1]);
rp = data;
} else if (adjacentPairs[j][1] == lp.getData()) {
data.setNext(lp);
data.setData(adjacentPairs[j][0]);
lp = data;
} else {
rp.setNext(data);
data.setNext(null);
data.setData(adjacentPairs[j][0]);
rp = data;
}
adjacentPairs[j][0] = adjacentPairs[j][1] = 0;
break;
}
}
int[] nums = new int[adjacentPairs.length + 1];
int i = 0;
while (lp != null) {
nums[i] = lp.getData();
lp = lp.getNext();
i++;
}
return nums;
}
2、ArrayList
第二次尝试和第三次尝试都差不多,只是使用ArrayList的次数不同。我这里就记录在一起了。
1、理论知识
- 与上面的逻辑思路类似,只是用了ArrayLIst去存储以及用ArrayList的特性去实现头插和尾插。
- 时间复杂度:O(n^2)
2、源代码
public static int[] restoreArray(int[][] adjacentPairs) {
ArrayList<Integer> a = new ArrayList<>();
a.add(adjacentPairs[0][0]);
a.add(adjacentPairs[0][1]);
List<List<Integer>> b = new ArrayList<>();
for (int i = 0; i < adjacentPairs.length - 1; i++) {
ArrayList<Integer> c = new ArrayList<>();
c.add(0, adjacentPairs[i + 1][0]);
c.add(1, adjacentPairs[i + 1][1]);
b.add(i, c);
}
//adjacentPairs[0][0] = adjacentPairs[0][1] = 0;
int n = adjacentPairs.length;
for (int i = 1; i < n; i++) {
for (int j = 0; j < b.size(); j++) {
if (!b.get(j).get(0).equals(a.get(0)) && !b.get(j).get(0).equals(a.get(a.size() - 1)) && !b.get(j).get(1).equals(a.get(0)) && !b.get(j).get(1).equals(a.get(a.size() - 1))) {
continue;
}
if (b.get(j).get(0).equals(a.get(0))) {
a.add(0, b.get(j).get(1));
} else if (b.get(j).get(0).equals(a.get(a.size() - 1))) {
a.add(b.get(j).get(1));
} else if (b.get(j).get(1).equals(a.get(0))) {
a.add(0, b.get(j).get(0));
} else {
a.add(b.get(j).get(0));
}
b.remove(j);
//adjacentPairs[j][0] = adjacentPairs[j][1]=0;
break;
}
}
int[] nums = new int[n + 1];
for (int i = 0; i < a.size(); i++) {
nums[i] = a.get(i);
}
return nums;
}
3、HashMap
说实话,我已经有点忘了这个Map了,独立思考已经尽力了,秉着学而不思则罔,思而不学则殆的学习习惯,我去看了评论解法,看到有Hash Map的字眼,这才点醒了我,大概看了一下源码,于是自己思考HashMap的方式来提高了运行速度。
1、理论知识
- 创建HashMap,将自己存为key,将相邻元素存为value(ArrayList)。
- 通过第一个元素或最后一个元素只有一个前驱和后继元素寻找到第一个元素。
- 通过HashMap快速查找拿到的元素的后继元素,然后这样循环下去。
- 时间复杂度:O(n),不考虑HashMap的复杂度,毕竟散列冲突下查找元素肯定小于O(n)。
2、源代码
public static int[] restoreArray(int[][] adjacentPairs) {
Map<Integer, ArrayList<Integer>> m = new HashMap<>();
for (int i = 0; i < adjacentPairs.length; i++) {
m.computeIfAbsent(adjacentPairs[i][0], row -> new ArrayList<>()).add(adjacentPairs[i][1]);
m.computeIfAbsent(adjacentPairs[i][1], row -> new ArrayList<>()).add(adjacentPairs[i][0]);
}
int[] nums = new int[adjacentPairs.length + 1];
for (Map.Entry<Integer, ArrayList<Integer>> entry : m.entrySet()) {
if (entry.getValue().size() == 1) {
nums[0] = entry.getKey();
nums[1] = entry.getValue().get(0);
break;
}
}
for (int i = 0; i < adjacentPairs.length - 1; i++) {
ArrayList<Integer> data = m.get(nums[i + 1]);
nums[i + 2] = data.get(0) != nums[i] ? data.get(0) : data.get(1);
}
return nums;
}
注:computeIfAbsent()
// 方法定义
default V computeIfAbsent(K key, Function<? super K, ? extends V> mappingFunction) {
...
}
// jdk8之前。从map中根据key获取value操作可能会有下面的操作
Object key = map.get("key");
if (key == null) {
key = new Object();
map.put("key", key);
}
// jdk8之后。上面的操作可以简化为一行,若key对应的value为空,会将第二个参数的返回值存入并返回
Object key2 = map.computeIfAbsent("key", k -> new Object());
三、扩展–为什么HashMap查找元素这么快?
当我们用线性表和树表的查找中,记录在表中的位置与记录的关键字之间不存在确定关系,因此在这些表中查找记录时需要进行一系列的关键字比较,查找的效率与比较次数成正比。
而散列表里面的散列函数:将查找表中的关键字映射成该关键字对应的地址。Hash(key)=Addr(这里的地址可以是数组下标、索引或内存地址等)。这就起到了快速查找的功能。
当然散列函数存在的关键问题就是冲突,冲突的解决办法也有很多。