图神经网络入门(五)不同类型的图
本文是清华大学刘知远老师团队出版的图神经网络书籍《Introduction to Graph Neural Networks》的部分内容翻译和阅读笔记。
个人翻译难免有缺陷敬请指出,如需转载请联系翻译作者
作者:Riroaki
原文:https://zhuanlan.zhihu.com/p/147696322
目录
往期文章传送门
有向图(Directed Graph)
异构图(HETEROGENEOUS GRAPHS)
带有边信息的图(GRAPHS WITH EDGE INFORMATION)
动态图(Dynamic Graphs)
多重边图(Multi-dimensional Graphs)
往期文章传送门
图神经网络入门(一)GCN 图卷积网络
图神经网络入门(二)GRN 图循环网络
图神经网络入门(三)GAT 图注意力网络
图神经网络入门(四)GRN图残差网络
在此前介绍的所有工作基本上都围绕无向的、节点自带标签信息的简单图结构展开,而这一部分我们将探讨更多种类的图结构与相关的工作。
有向图(Directed Graph)
第一个变种,有向图,在边上增加了方向信息。实例如知识图谱中头实体指向尾实体的关系就是一个有向的边,它说明对两个方向的传播应当区别对待。
关于有向图,这里介绍密集图传播(Dense Graph Propagation,DGP)。对于每个目标节点,它都从其所有后代和祖先那里接收知识信息,为此设计了两个权重矩阵 来引入更精确的结构信息:

在上述传播过程中, 分别是正则化的父节点/子节点邻接矩阵;此外,DGP 提出一种对邻居节点的权重分配方式,可以使不同距离的节点产生不同的影响力:

其中 是邻接矩阵中包含父节点传播 步的子矩阵,而 是邻接矩阵中包含子节点传播 步的子矩阵,而 则为对应的度矩阵。
异构图(HETEROGENEOUS GRAPHS)
异构图指的是图中存在不同类型的节点和边(节点和边至少有一个具有多种类型),常见于知识图谱的场景。最简单的处理异构信息的方式是使用独热编码类型信息并拼接在节点原有表示上。
GraphInception在传播过程中引入元路径(meta-path)来处理异构图的关系分类问题。元路径是指任意一条包含边类型(或者,在知识图谱中是关系类型)序列的路径,这条路径的长度为其连接的节点个数。有了元路径,我们就可以根据节点的边类型和距离将邻居节点分类,如此就可以将异构图分解为一个同构图的集合(这也被称为多通道网络)。形式上,有了元路径的集合 ,一个异构图可以转化为如下的多通道网络:
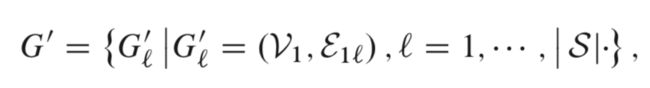
其中 代表包含 种不同类型的节点分别组成的集合, 表示目标类型的节点集合, 表示符合 模式的一个实例,并且两端节点都在目标节点集合中。
Q:这里为什么会出来一个“目标节点”?
A:因为这篇论文《Deep Collective Classification in Heterogeneous Information Networks》提出的GI是为了解决collective classification问题(对一堆互相联系的实例做关系分类,而在通常情况我们认为实例之间是独立的)。文章只在一种类型的节点上研究集体分类问题,而不是在HIN中的所有节点上进行集体分类。因为不同类型节点的标签空间是不同的,假设所有类型的节点共享同一套标签是不合理的。
对每一个邻居节点组成的团体,GI 将其视为一个同构图中的子图进行传播,最终将不同的同构图得到的表示进行拼接得到最终的表示。
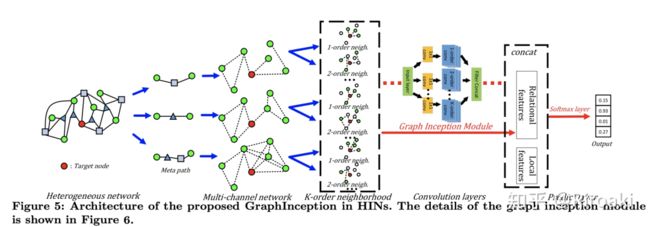
补充:这里综述太简略了,我基本看不明白 “元路径”在讲什么,怎么就变成同构图了? 对比原论文里的图才明白这个元路径只是用来表示目标节点之间的连接方式的工具。
见下图,第一种元路径(圆圈-正方形-圆圈)将第一个图中和target node按照这种方式相连的节点组成的子图,那很明显就是同构图。
HAN(Heterogeneous Graph Attention Network)使用了节点和语义信息的注意力机制。对于每个元路径,HAN在节点层面进行注意力计算学习节点的表示;接着基于这种元路径相关的表示上,HAN再做注意力学习一个更综合的节点表示。这样以来,模型可以同时考虑节点重要性和元路径重要性。
PP-GCN(Pairwise Popularity Graph Con- volutional Network)用于事项抽取(event detection),在社交网络上抽取信息。模型首先对事项图中,事项的不同元路径计算一个加权平均,并构建一个带权的事项邻接矩阵,最终使用GCN来学习事项嵌入。
ActiveHNE(Active Heterogeneous Network Embedding)在异构图学习中引入主动学习(active learning)来降低学习成本。基于不确定性和表达力,ActivaHNE选择最重要的节点作为训练集。这一步骤显著降低了查询成本,同时在现实数据集中成为了SOTA。
补充:主动学习,允许模型对输入样本进行可交互地选择(而不是被动接受所有样本),在标注样本成本较高的领域(比如NLP),已标注的样本很少,而主动学习能够以较少样本达到较好的效果。——来自维基百科的定义,具体的我也不是很明白……
带有边信息的图(GRAPHS WITH EDGE INFORMATION)
这一类图的边包含一定的信息,如边的权重/类型。这里列举两种处理方式:
其一为 Levi graph transformation,将原有的图变为二分图——左侧为原有节点,右侧为边,如下图:
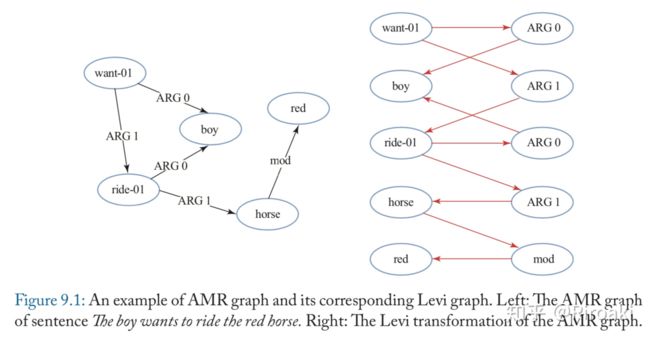
这样做的好处在于把边的类型转化为节点类型,在新的图中是不存在边的类型的。这么做的有G2S网络,把AMR(Abstract Meaning Representation)图转化为Levi图并使用GGNN(Gated Graph Neural Network,是一种图循环网络GRN,在之前的文章里有简单介绍)。G2S的节点编码部分传播过程如下:
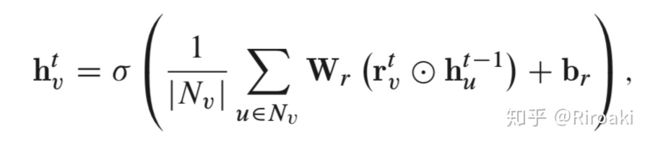
其中 为关系类型相关的参数。
其二为R-GCN(Relational GCN),就是对不同关系的边提供不同的权重矩阵。在关系类型较多的图上,R-GCN提出两种降低模型参数量的约束方法:基分解(basis-decomposition)和块对角分解(block-diagonal-decomposition)。
基分解时,每个关系相关的卷积层矩阵如下:
如此, 表示为共享的基矩阵 加权(权重为 )的组合,这一步将原本参数量为 降低到了 ,而 。
块分解的操作是累加:
这一种分解比基分解需要的参数量更大,,可以使得生成的矩阵更稀疏。
RGCN在KG里算是一个效果很一般的baseline,体感貌似transe都比它的效果好……
动态图(Dynamic Graphs)
空间上的时序预测是一个很重要的任务,对应现实中的交通预测、人体动作识别和气候预测。其中的某些问题可以建模为动态图上的预测,对应着静态的图结构和动态的信号输入。下图展示了基于现有图状态预测接下来的状态的任务:
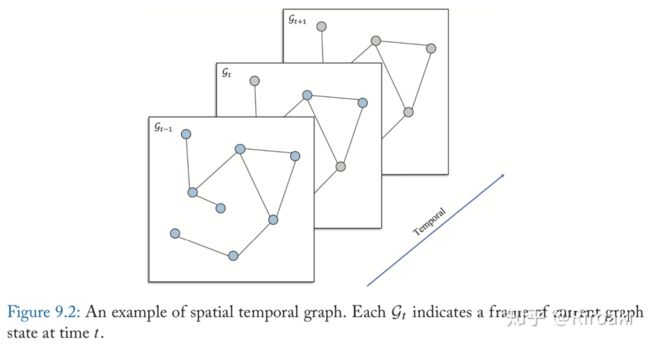
DCRNN(Diffusion Convolutional Recurrent Neural Network)和STGCN(Spatio-Temporal Graph Convolutional Networks)使用了独立的模块对空间信息和时序信息两方面信息进行学习。
DCRNN建模图中的流(flow)为传播(diffusion)的过程,传播层将空间信息进行传播并更新节点表示。在时序依赖上,DCRNN使用RNN结构,不同之处在于将其中的矩阵相乘过程替换为diffusion convolution的过程。
STGCN包含多个空间-时序卷积块,每一个卷积块中使用两个时序门控卷积层(temporal gated convolutional layer)和一个空间图卷积层(spatial graph convolutional layer)夹在其中。在层内部还使用了残差连接和瓶颈策略(bottleneck strategy),如下图:

补充:瓶颈策略经常和残差一起出现,在这里是指卷积块中三个层之间先降低通道数再提升的操作。
在动作捕捉任务,Structural-RNN 和 ST-GCN(同一个英文全称,但是和上面那个不是一个网络!)则同时采集空间和时序信息。这两个网络使用时序连接拓展静态图,并在拓展后的图上使用GNN。
Structural-RNN在同一个节点的前后时间点之间建立连接,然后对节点和边分别构建RNN(nodeRNN和edgeRNN),两部分RNN构成一个二分图进行传播。
这篇文章有点复杂,暂时不深入探究了,先贴一下链接:Structural-RNN: Deep Learning on Spatio-Temporal Graphs(https://arxiv.org/abs/1511.05298)
ST-GCN 将所有时间节点的图堆叠起来构建一个ST图,并将图分类,为每一个节点学习一个权重向量,最终直接在上面进行图卷积。
留下链接,日后填坑:Spatial Temporal Graph Convolutional Networks for Skeleton-Based Action Recognition(https://arxiv.org/abs/1801.07455)
此外,Graph WaveNet 考虑了一个更困难的场景:节点的邻接矩阵不能如实反映真正的空间依赖信息,比如一些缺失和欺骗信息。同时上述的网络难以捕捉较长距离的信息。因而,它提出了一种自适应性的邻接矩阵,这种矩阵通过由 TCN(Temporal Convolution Network)和 GCN 结合成的框架来学习得到。
多重边图(Multi-dimensional Graphs)
在实际生活中,多重图很常见——例如youtube视频和用户的交互过程可以包含订阅、分享、评论等等,考虑到这些关系并不一定是独立的,直接应用单重边图上的网络(例如R-GCN等)可能不是最好的选择。
早期工作主要集中于解决社群分析和聚类问题,提出了这一问题和相关的定义等等。多重图示意图如下:
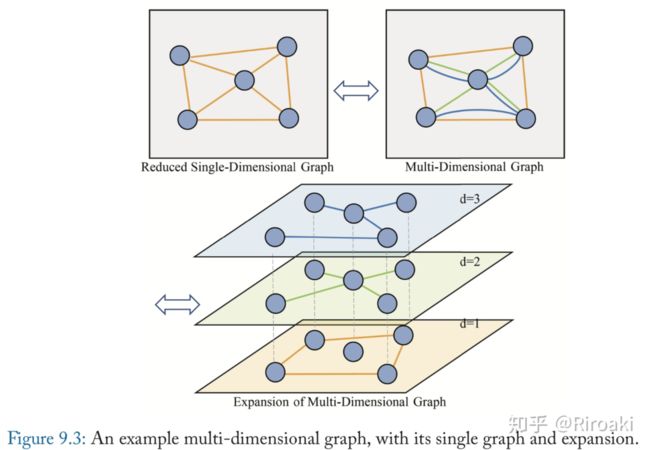
目前有人提出了GCN的特殊变种以适应这一问题(《Multi-dimensional graph con- volutional networks》),使用不同的表示来描述不同关系维度的同一个节点,而这些表示被视为更泛化的表示在这些维度上的投影,并设计了一种聚合方式可以同时考虑同层不同节点的交互和不同层统一节点的交互。

《Graph convolutional networks for multi-view networks, with applications to global poverty》提出了将多重图降维到单重图的方案,使用子空间分析(subspace analysis)进行并对图进行裁剪,从而合并到一个单重图。此后使用简单GCN就可以处理了。
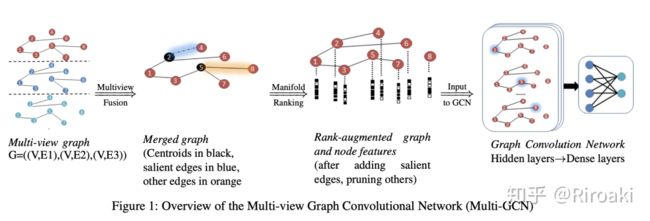
《Multi-view network embedding via graph factorization clustering and co-regularized multi-view agreement》虽然没有提出新的网络结构,但是将旧的节点表示学习方法(SVNE,single view network embedding)拓展到这一类图上。
简略得不能再简略,待补充……