如何将一棵LSM-Tree塞进NVM
简介: 随着非易失内存产品的商业化推广,我们对于其在云原生数据库中大规模推广的潜力越来越有兴趣。X-Engine是阿里云数据库产品事业部PolarDB新型存储引擎团队研发的一个LSM-tree存储引擎,目前在阿里云PolarDB产品上提供对外服务。我们以X-Engine为基础结合非易失内存的优势与限制,重新设计并实现了存储引擎的主要内存数据结构、事务处理和持久化内存分配器等基础组件,最终实现了不需要记录预写式日志的高性能事务处理,降低了整体系统的写入放大并提高了存储引擎的故障恢复速度。

作者 | 百叶
来源 | 阿里技术公众号
引言:随着非易失内存产品的商业化推广,我们对于其在云原生数据库中大规模推广的潜力越来越有兴趣。X-Engine是阿里云数据库产品事业部PolarDB新型存储引擎团队研发的一个LSM-tree存储引擎,目前在阿里云PolarDB产品上提供对外服务。我们以X-Engine为基础结合非易失内存的优势与限制,重新设计并实现了存储引擎的主要内存数据结构、事务处理和持久化内存分配器等基础组件,最终实现了不需要记录预写式日志的高性能事务处理,降低了整体系统的写入放大并提高了存储引擎的故障恢复速度。该研究成果以论文《Revisiting the Design of LSM-tree Based OLTP Storage Engine with Persistent Memory》发表到VLDB2021。论文容量较大,无论是对于后续的研究还是应用落地都具有较高的参考价值。作为一个持续深耕数据库基础技术的团队,我们在事务存储引擎/高性能事务处理/新型存储器件/异构计算设备/AIforDB上均有涉猎及研究,欢迎海内外有志之士加盟或交流。
一 背景介绍
1 持久化内存简介
PM在提供相比DRAM更大容量、更低功耗的同时,还具备字节寻址等诸多特点,旨在大幅度提升设备内存容量以及降低设备静态功耗的同时,提供可持久化字节寻址等特性以简化系统的设计,为数据库存储引擎的设计带来了新的契机。Optane DCPMM采用DDR4 DIMM的产品形态,亦被称之为“持久内存模组”Persistent Memory Module/PMM。当前DCPMM单条容量提供三种选择128GB、256GB、512GB,实际可用容量分别为126.4GiB、252.4GiB、502.5GiB。Optane DCPMM当前仅适用于Intel Cascade Lake处理器,其和传统的的DRAM类似,通过Intel iMC(integrated Memory Controller)连接到处理器。DCPMM虽然提供和DRAM相同的字节寻址能力,但其I/O表现与DRAM存在较大差异,主要体现在介质访问粒度、cache控制、并发访问以及跨NUMA节点访问等方面。感兴趣的读者可以参考本文后续的文献[1,2]。
2 X-Engine简介
X-Engine是一种基于LSM-tree架构的OLTP数据库存储引擎,其实现架构如图2所示,其中单个数据库可由多个LSM-tree实例组成(称为subtable),每个实例存储一个表或者索引或者分区表(table/index/table-partition),具体可参考2019年SIGMOD的论文[3]。LSM-tree将数据分为多个按照一定比例增长的层(level),分别位于内存以及磁盘,数据从上层到下层通过合并(compaction)的方式流动。鉴于DRAM是掉电易失的,其采用写前日志(WAL)的方式将要写入的数据提前写入到磁盘中持久化,在内存中的数据刷入(flush)或者合并到磁盘后再清除对应的WAL。在典型的设计中,内存中的数据通常采用跳表(skiplist)实现,在大小超过限制后会被冻结(图中Swtich操作以及immutable内存表)并转储到磁盘中并创建新的内存表。磁盘中的每层数据采用多个有序字符串表(SST,Sorted String Table)存储,每个SST相当于一颗B树。通常情况下同一层中的不同SST的键值对的范围不发生交叠。但实际的系统中为了加速内存表的刷盘操作,通常允许部分层的SST存在范围交叠,如LevelDB,RocksDB等均允许Level0存在交叠,但乱序的Level0层数据布局会降低读取效率。

图 2 X-Engine主要架构
3 机遇与挑战
现有的基于LSM-tree架构的OLTP存储引擎的设计通常存在以下几个问题:(1)WAL位于写入关键路径中,尤其是为了满足事务的ACID属性,WAL通常以同步的方式写入到磁盘,因而拖慢写入的速度。此外,由于DRAM的易失性,设置过大的内存表虽然会提高系统的性能,但会导致WAL过大,影响系统的恢复时间。(2)level0数据块通常允许乱序,以加快内存中数据的刷盘速度。但乱序的数据块如果堆积过多,会严重影响读取性能,尤其是范围读取性能。直观上,可持久化字节寻址的PM可以用来实现持久化内存表,代替DRAM中的易失性内存表,从而减少维护WAL的开销。然而实际上,由于PM本身的特性,实现高效的持久化索引依然存在较大挑战,包括相应的PM内存管理。另外,当前PM硬件仅能保持8字节原子写入,导致为了实现原子写入语义,传统方法依然需要引入额外的日志(又称为PM内部日志)。
为了应对这些挑战,该论文设计针对LSM-tree专用优化的高效PM内存管理器Halloc,提出了优化的基于PM的半持久化内存表用以替换传统方案DRAM中的内存表,使用ROR无锁免日志算法去除传统方案依赖WAL保持事务的ACID属性,设计全局有序的Global Index持久化索引层以及存内合并策略替换传统方案的Level0层,提高查询效率以及降低Level0数据维护的CPU和I/O开销。论文中主要改进点如图3所示,其中mem表示active memtable,imm表示immutable memtable,sp-前缀表示半持久化。这些设计主要带来以下三点好处:(1)避免了WAL写入以及PM编程库引入额外内部日志,实现更快速的写入;(2)PM中的数据直接持久化,避免了频繁的刷盘以及level0的合并操作,且容量可以设置更大而不用担心恢复时间;(3)level0数据全局有序,不必担心level0的数据堆积问题。

图 3 论文中的主要方案和传统方案的对比
二 半持久化内存表

持久化索引的更新以及添加操作通常涉及PM中多个超过8字节的小的随机写入,因此引入用于维护一致性的开销以及随机写入导致的写放大问题。实际上,基于PM的索引的设计可以分为上表中的三类。无持久化是指将PM当作DRAM使用,此种方法可以保证索引处于最高的性能,但掉电数据即丢失。第二类是采用全持久化的方式,即索引所有的数据(索引节点以及叶子节点等)做持久化,如BzTree, wBtree等。该种方式可做到极速恢复,但持久化的开销一般较大,性能通常较低。一个比较折中的方法是仅持久化必要的数据以换取性能和恢复时间的折中,例如NV-Tree和FPTree仅持久化叶子节点,索引节点在重启时重建。而在LSM-tree结构中,内存表通常较小,因此采用半持久化的索引设计思想较为合适。论文中采用两种方法用以降低维护持久化索引的维护开销。
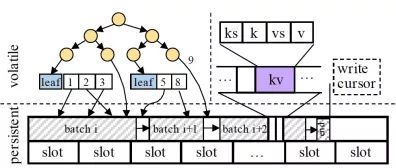
图4 半持久化内存表结构图
仅持久化叶子结点。在实际的应用场景中,云上基于LSM-tree的OLTP引擎通常不会设计较大的内存表,通常为256MB,这主要是由于以下两个原因:(1)云上用户通常会购买较小内存的数据库实例;(2)LSM-tree需要维持小的内存表以保证快速的刷盘操作。对于256MB的内存表,我们发现将仅持久化叶子结点时重启恢复非叶子结点的开销小于10毫秒,其恢复时间相对于所研究的数据库系统已足够快。其次,该索引的设计中采用序列号以及用户键分离的方式用于加速键的查找以及满足内存表的MVCC (Multi-Version Concurrent Control)并发控制约束。如图4所示,对于仅有一个版本的值(9)将直接在索引中存储一个指向PM具体位置的指针,对于有多个版本的值,设计中使用可伸缩的数组用于存储多版本序列号及其具体的指针。由于索引是易失的,键并不显式存储在索引中,且索引在重启时通过扫描PM中的键值对重建。
批量顺序写入以降低写放大。在PM中,小的随机写会被硬件控制器转换成随机的256字节的大块写,导致写放大问题,进而消耗PM硬件的带宽资源。鉴于内存表设计为顺序追加的写入方式,为了避免该问题,半持久化内存表通过将小的写打包成大块的写(WriteBatch),并且顺序地将该WriteBatch写入到PM中,之后分别将其中的记录写入到易失性索引中。如图4所示,batch表示一个大块的WriteBatch写入,slot用于记录从Halloc分配器中分配的zone对象的ID。
三 ROR无锁免日志事务提交算法
由于本文中memtable中的索引无需持久化,因此仅需保证数据的原子持久化即可。PM虽然可以提供字节寻址的可久化写入,但其仅能提供8字节的原子化写入(仅指intel optane DCPMM)。因此大于8字节的写入操作存在部分写(torn write)的风险。传统的方案是采用数据即日志(log-as-data)保证原子写入,如图5所示,日志项顺序写入,且每个日志项写入完成后更新8字节的head指针。由于head的更新总能由硬件保证原子性,因此head之前的日志项可以看作成功写入;head之后的日志项存在部分写风险,重启时被丢弃。
该种方案存在两个问题:(1)日志仅能顺序写入,不利于发挥多核系统的并行写的能力;(2)日志项中存在不同生命周期的数据,导致日志项的回收较为困难。如图5所示,log1中的数据写入3个LSM-tree实例中,而其中不同的LSM-tree实例中memtable刷盘的时间不同,可能会导致某个LSM-tree实例写入较少,进而刷盘周期较长,导致对应的log1长时间不能有效回收,降低PM的内存空间的利用率。

图 5 传统方案存在的问题
为了解决这些问题,文章提出ROR算法,其使用ChainLog数据结构分离数据生命周期,利用无锁环(lock-free ring)实现日志的并发写入。其中,为了进一步减针对PM的随机写入提高写入的性能,ROR算法中采用batch的方式将小的ChainLog合并成更大的数据块。如图6所示,ChainLog保证任意大小数据写入PM的原子性;batching用于聚合小的事务缓存批量写入PM以减少PM的随机写;并发环提供针对ChainLog无锁的流水线化写入到PM中以提高多核系统的伸缩性。

图 6 ROR算法整体框架
对于一个待提交的事务,其首先被封装成一个WriteBatch。一个或者多个WriteBatch被进一步封装成一个ChainLog,以批量写入到PM中。本文中沿用LSM-tree原初的两阶段锁2PL以及MVCC的事务并发控制策略。如图6所示,ROR使用固定可调大小并发桶(bucket)用于控制并发写入,其中第一个进入某个bucket的线程成为leader线程用于执行具体的写入,其余进入该bucket的线程成为follow线程。Leader将自己以及属于该bucket的所有follow线程的WriteBatch聚合成一个更大的WriteBatch用于实际的写入。
ROR重点之一是ChainLog,其通过在8字节的head中加入识别日志生命周期的域以及标识写入位置的域。可以通过标识写入位置的域信息,定位到哪些ChainLog发生了部分写,从而在重启时丢弃。通过日志生命周期的域信息,可以使得ChainLog中写入不同LSM-tree实例中的数据写入到不同的内存空间相互隔离。另外,ChainLog在高层视角上总是串行的写入,即一个ChainLog项仅当所有以前的ChainLogs都已持久化在PM中时才会被持久化。串行化的提交使得在系统恢复期间仅需检查最后一个ChainLog项,以确保最后一个ChainLog的写入是否发生部分写。
首先考虑数据生命周期的分离,一种较为直观的做法是针对每个LSM-tree实例设置单独的head指针,如图7所示,每个head负责指示其对应的内存空间的写入位置。不同的内存空间相互分离,具有独立的生命周期,其对应的LSM-tree中的memtable刷盘后可以立即回收而不需要等待其他LSM-tree实例。但该种做法存在一个明显的问题,单个事务可能会写入到多个LSM-tree,因此导致单次更新涉及到多个head的更新,进而硬件上无法保证写入的原子性。

图 7 日志项生命周期示例
为了解决这个问题,ROR在每个LSM-tree实例中用于指示写入位置的8字节的head中加入如下的位置信息,图8中的gidx即对应原始的8字节head指针。gidx指针中高4字节用于记录上次写入的位置,低4字节用于记录当前写入的位置。每4字节中6bit用于记录memtable的slot,26字节用于记录对应slot的偏移,总共可以寻址4GB的空间。一个ChainLog项写入的数据分为n个子项,每个子项分别写入对应的LSM-tree实例。每个子项中均记录子项的个数以及当前ChainLog的LSN。

图 8 gidx的结构示意图
图 9 中的例子展示了该过程,其中ChainLog2(R2)已经被成功提交,R3等待被提交。但在R3提交的过程中系统发生异常掉电,导致R3中子项r31被成功提交,但r32未能成功提交。在系统恢复时,通过扫描所有LSM-tree实例中的最后一个ChainLog子项,可以获知当前最大的LSN为3。而r31已经成功提交,但其记录的子项数为2,但r32未能成功写入,因此其LSM-tree实例1的gidx会被回滚(通过简单快速的右移运算)。回滚后r31被丢弃,LSN回退到2,此时系统恢复到全局一致性状态。

图 9 断电恢复示意图
由于ChainLog需要满足串行化写入语义,进而保证在重启恢复时仅需扫描所有LSM-tree的最后一个ChainLog子项即可正确建立全局一致的状态。保证串行化写入语义的一种方法是串行写入,但该方式无法利用多核平台的高并发写入的特性,其本质上是先建序后写入的思想。ROR算法中采用写入后建序,即每个线程在写入的时候不关注序的问题。ROR算法会在此过程中动态的选择主线程收集当前已写完的ChainLog并建序。由于建序仅涉及到ChainLog元数据的更新,因此显著提高写入性能。主线程建完序后退出,ROR算法继续动态选择其他主线程进行该过程。该过程由lock-free ring以及lock-free的动态选主算法控制,具体细节读者可以参考原始论文中的描述。
四 Global Index与轻量级存内合并
GI(Global Index)主要用于在PM中维护一个可变索引化的数据层用以替换磁盘中无序化的level0层数据。为了简化实现,GI采用和内存表相同的易失性索引,并将数据放置在PM中。由于内存表同样将数据放置在索引中,因此内存表的数据转移到GI时无需数据拷贝,仅需更新GI索引中的指针指向内存表中的数据。值得注意的是,GI可以采用任意的范围索引,或者持久化索引用以提高系统的恢复速度。鉴于GI的更新并不需要设计多个KV更新以及写入的事务性需求,现有的无锁免日志的范围索引均可以应用到GI中。
存内合并:存内合并是指从内存表到GI的合并。GI采用和内存表相同的索引设计,即将键值对存储到PM中,叶子结点采用伸缩的带数据版本的数组用于存储来自同一个键的数据。在存内合并时,如果在GI中不存在相同的键,则直接将该键插入到GI中;如果已存在,则需要在GI中检查属于该键多个版本并在需要时执行多版本清除操作,以节省内存空间。由于PM中的键值对都由Halloc管理,因此键值对粒度的内存释放是不允许的。完成存内合并时,仅释放内存表的内存。仅当GI中的所有键值对合并到磁盘时才批量释放GI中的PM内存。
快照:通过快照技术,可以确保在GI合并到磁盘时,存内合并操作可以同时进行,以避免阻塞前段的操作。在快照的实现中,GI会冻结当前的数据并在内部创建一个新的索引用以吸收来自内存表的合并数据。该种设计避免了阻塞前端的操作,但由于查询可能会涉及到两个索引,导致额外的查询开销。
PM到磁盘的compaction:由于合并到磁盘的GI数据是不可变且全局有序的,因此PM到磁盘的合并操作并不会阻碍前端的操作。而且由于GI的全局有序性,合并操作可以通过范围且分并行化,进而加快PM到磁盘的合并速度。
数据一致性:PM到磁盘的合并涉及到数据库状态的改变,可能在系统宕机时出现数据一致性问题。针对该问题,本文通过在磁盘中维护描述日志(manifest log)的方式保证数据库状态改变的数据一致性。由于描述日志不在前端写入的关键路径中,因此并不会影响系统写入的性能。
五 Halloc内存分配器
Halloc是针对LSM-tree专用的PM内存分配器,其通过三个关键技术以解决传统通用PM内存分配器存在的效率低、碎片化等问题,基于对象池的内存预留方案、应用亲和的内存管理以及统一化地址空间管理。其主要架构如图10所示,halloc通过直接创建DAX文件划分自己的内存地址以及管理自己内部的元数据信息,在地址空间上划分为四个区域分别存储Halloc元数据信息、subtable元数据信息、内存表元数据信息以及若干内存快用于具体的内存使用。

图 10 Halloc内存分配器总体架构图
基于对象池的内存预技术。Halloc通过静态预留固定大小的对象池且内存地址互不交叠的地址空间以减少PM管理中存在的内存碎片问题。每个对象池包含元数据区用于记录对象的分配情况,freelist持久化链表用于追踪空闲的对象,固定大小的对象区且其大小由创建对象池时显式指定。由于对持久化链表的操作设计到多个不连续的大于8字节的PM写入操作,因此存在数据不一致的风险。传统的方案使用PMDK以及Mnemosyne等内部日志保证操作的事务性,但改种方案会引入额外的日志开销。为了消除该日志开销,本文提出以下方案保证freelist操作的数据一致性。
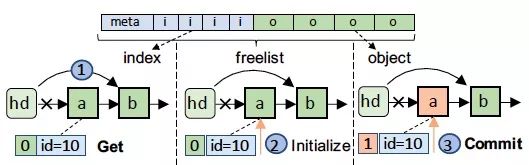
图 11 freelist内部结构图
如图11所示,对于一个freelist,其在内存空间上是连续存储的,包括元数据区用于记录分配情况,通过索引区用于索引空闲的对象,以及对象区用于存储具体的对象。每个对象对应一个8字节的索引,每个索引的最高位用于标记该对象的持久化情况以确保原子化的对象分配与释放。Freelist提供四个接口用于完成一个对象的分配与释放:Get用于从freelist中获取一个对象,Commit用于通知Halloc该对象已完成初始化可以从freelist中移除,Check用于检测某个对象是否已被持久化避免故障重启时出现对象错误引用,Release用于释放一个对象。核心思想是通过在对象的索引设置持久化标志,已在重启时通过扫描识别出泄漏的对象。
对于对象池的启动恢复,Halloc首先扫描freelist的对象并在bitmap中标记,之后在扫描index域确认该对象是否在freelist中可达。对于不可达的对象将被回收。该种设计一定程度上增加了重启的开销,但实际上该过程扫描很快,实验中扫描数百万个对象仅花费几毫秒时间。重启开销在所研究的系统中可以忽略不计。
应用亲和的内存管理。Halloc对于LSM-tree提供两种对象池服务:自定义对象池以及zone对象池。该种设计主要基于LSM-tree对于内存使用的独有的追加写以及批量回收的方式,对于内存的管理有较大的简化。对于自定义对象池,如图 8 所示,Halloc维护了memtable以及subtable池分别用于存储引擎中的内存表元数据和subtable元数据。一个subtable对象包含一个链表用于记录其所有拥有的memtable对象(通过memlist链接),其中第一个memtable对象为活动内存表,其余为冻结内存表。每个memtable对象索引有限个zone对象,每个zone对象记录具体的memtable数据。zone对象池是Halloc内建的对象池用于应用自己按照自己的方式管理内存,该设计主要是因为自定义对象池仅能存储有限的且固定大小的对象。鉴于Halloc并非针对于通用PM内存分配,对于可变大小且为止数量对象的管理,应用需要自己基于zone对象池实现自己的内存管理方案。
统一化地址空间管理。 为了便于易失性以及可持久性内存的联合管理,Halloc在单一DAX文件地址空间上同时支持持久化内存分配以及易失性内存分配,从而大大简化了PM资源使用。类似于libmemkind,Halloc同样适用jemalloc用于接管具体可变大小的易失性内存的分配。不同的是,Halloc使用zone作为jemalloc的基本内存管理单元,即jemalloc总是从zone pool中获取zone对象并进一步细化管理。其从zone pool中分配的对象不再调用Commit,从而其所有分配的zone对象在系统重启后将全部被回收。该种设计方案的一个较大的限制是用户分配的易失性内存大小不能超过单个zone的大小,因为zone对象池仅能保证单个的zone的内存地址的连续性。然而对于较大的内存分配,用户可以选择拆分的方式多次分配,或者如果对象大小固定且数量有限使用自定义对象池进行静态分配。
六 实验评估
实验平台。实验采用阿里云实例规格为ecs.ebmre6p.26xlarg。该实例具有两颗Intel(R) Xeon(R) Platinum 8269CY CPUs,每个CPU具有52个核心,共104核心。每个核心有一个32KB的L1缓存,一个1MB的L2缓存。每个CPU上所有的核心共享一个32MB的L2缓存。实例另有187GB的DRAM以及1TB的PM。PM被平均分配到两颗CPU,即每个CPU装备512GB的PM。实例总共配置2TB的ESSD作为云硬盘。实验中将所有的PM配置为两个linux设备,每个设备分别属于一个CPU。所有的实验运行的linux内核版本为4.19.81。
参数配置。如无特别说明,实验中设置单个内存表的大小为256MB,单个subtable的GI的最大为8GB,单个subtable的level1为8GB。改进前的系统配置256MB的level0。所有的实验均采用同步的WAL,使用Direct I/O以旁路掉page cache对系统的影响,关闭压缩以尽量评测系统的最大性能表现。
1 综合评估
该实验首先采用YCSB标准的测试基准,共预先在数据库中加载80亿记录,平均分配到16的subtable,每个记录有8字节的key以及500字节的value,总共约500GB的数据量。实验中配置了4种配置:(1)基准系统且所有数据均放置到ESSD中(标记为XS),(2)改进的方案且配置使用200GB的PM空间由Halloc管理(标记为XP),(3)基准系统且将所有的数据放置在速度更快的PM中(标记为XS-PM),(4)改进的方案且将原先放置于ESSD中的数据放在PM中(标记为XP-PM)。配置(1)以及配置(2)是系统实际使用时的标准配置;而配置(3)以及配置(4)是主要用于评估移除ESSD后的系统性能表现。每个实验使用32个client线程,设置50GB row cache以及50GB的block cache,且运行30分钟以保证系统compaction得到及时的运行。
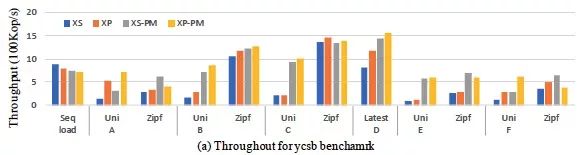
图 12 YCSB实验结果
实验结果如图12所示,对于写密集型的负载A且随机请求下,XP/XP-PM的性能是XS/XS-PM的3.8以及2.3倍;在写密集型的负载F且随机请求下,XP/XP-PM的性能是XS/XS-PM的2.7以及2.2倍。且在图10中显示,XP的平均访问延迟要比XS低36%。在负载倾斜的情况下(Zipf=1),XP与XS性能表现接近,并且XP-PM表现要比XS-PM更低。这些结果表明,本文的方案对比基准系统在整体上性能表现更优异且产生更少的磁盘I/O。然而XP-PM的表现和XS-PM的表现差距不大,尤其是在负载倾斜下,XP-PM表现的不如基准系统XS-PM。但实际上该配置将数据全部放置于PM中,因为成本较为高昂,实际中不会采用。
对于读密集型的应用(B,C,D,E),在负载B且随机请求下,XP/XP-PM比XS/XS-PM性能分别高1.7倍及1.2倍,在负载D中分别高1.4倍以及1.1倍,并且拥有更低的延迟,负载B的平均延迟降低39%,负载D的平均延迟降低26%。这主要是因为XP不需要写WAL日志,因此具有更低的写入延迟。负载倾斜时,XP的性能收益降低。在负载B中,XP/XP-PM性能对比XS/XS-PM仅提高1.1倍以及1.5倍。在负载C以及负载E中,由于写入较少,此时数据全部被合并到ESSD中,因此XP/XP-PM对比XS/XS-PM性能表现相似。

图 12(续) 系统延迟以及CPU、IO开销
CPU以及I/O消耗。图12(c)中展示了在运行YCSB load以及A负载时的CPU消耗以及累积I/O情况。结果展示,XP拥有更好的CPU使用效率,且在运行A负载时,其I/O的消耗相对基线系统降低了94%。主要原因为XP采用更大的GI用于缓存更多的更新在PM中,因而减少数据的刷盘操作。

图 13 系统延迟以及CPU、IO开销
数据库大小敏感性。为了测试改进系统的性能收益与数据库大小的关系,实验分别注入100-600GB大小的数据,之后运行D负载。结果表明,如图13所示,数据库大小从100GB增大到600GB时,基线系统XS的性能下降了88%,而XP仅下降27%。主要是因为负载D尽可能读取最近的更新,而XP会将热数据放置在高速的持久化的PM中,而基线系统XS在每次启动系统进行测试时均需要从慢速磁盘中读取数据。

图 14 单LSM-tree实例的实验结果(40GB dataset)
单个LSM-tree实例测试。为了同现有的最新的使用PM改进LSM-tree的方案进行对比,实验中选择SLMDB以及NoveLSM进行对比。鉴于SLMDB以及NoveLSM均不支持同一个数据库中运行多个LSM-tree实例,本次仅设置单个subtable。实验中使用4个client且加载40GB的数据。测试结果表明,如图14所示,XP拥有更高的数据加载性能,为SLMDB的22倍,NoveLSM的7倍。主要是因为SLMDB以及NoveLSM虽然使用持久化skiplist作为内存表,但涉及到事务处理时,仍然依赖WAL以保证事务的原子性,另外两者均不支持并发写入。SLMDB使用单层的结构以及全局的持久化B+tree用于索引磁盘上具体的数据。该种设计虽然能够提高数据的读取性能,但写入时涉及到磁盘以及PM中持久化索引的一致性维护,因而写入性能较低。NoveLSM仅引入持久化内存表,因此性能提升较为有限(PS:不是很novel)。

图 15 TPC-C实验评估结果
TPC-C性能表现。实验中将改进的方案集成到MySQL中作为一个存储引擎的插件,并预先加载80GB的初始数据库大小,之后启动TPC-C测试30分钟。实验结果显示(如图15),XP相对XS的TPS性能提高到2x,且P95延迟降低了62%。主要是因为XP避免了WAL的写入,且拥有更大的PM以缓存更多的数据。然而XP在TPS的表现上相对于XS抖动更大,主要是因为XP更倾向于执行level0到level1的all-to-all compaction策略,从而导致更剧烈的cache淘汰行为。如何平衡compaction和cache的淘汰策略是未来一个比较重要的方向。
2 半持久化内存表评估
为了评估改进的方案中半持久化内存表的性能,实验中关闭系统所有后台的flush以及compaction操作,设置ROR的batch=50以尽量旁路掉ROR的影响(batch=50已接近PM硬件性能极限)。实验中主要对以下索引方案:(1)基于DRAM的skiplist,基线系统默认的内存表索引类型(标记为SLM);(2)基于FAST&FAIR实现持久化内存表(标记为FFM);(3)基于FPTree的变种(本实验中采用OLC实现并发操作,原始的FPTree采用HTM以及leaf lock实现并发操作)实现的半持久化内存表(标记为FPM);(4)本文方案,且使DRAM存储索引节点(标记为SPM-D);(5)本文方案,且使用PM存储索引节点(标记为SPM-P)。方案(4)以及(5)用于检测将PM作为非持久化使用时的内存表性能表现。FAST&FAIR以及FPTree是一种针对PM优化的持久化B+tree,其中FPTree仅持久化叶子结点,因而同样为半持久化索引的一种。由于FAST&FAIR以及FPTree均不支持可变大小的key,因此本实验对于这两种内存表添加一个运行时KV解析的流程,即索引中仅存储固定大小的KV对的指针。实验中插入3000万个KV对,8字节key,32字节value,总计约1.5GB数据。KV对在内存表中将被转换成17字节的key,以及33字节的value。

图 16 内存表性能评估结果
insert性能:图16(a)(b)展示了不同内存表在并发线程从1增加到32时的写入性能表现。结果显示,在写入时SPM-D以及SPM-P的差别很小,即使SPM-P将索引节点放置在速度更慢的PM中,主要是因为持久化开销相对较大,是主要影响因素。另外,对于SLM/FFM/FPM,SPM-D在顺序写入上分别提升5.9x/5.8x/8.3x,在随机写入上分别提升2.9x/5.7x/6.0x。即使LSM将索引放置在速度更快的DRAM中,SPM-D/SPM-P相比依然具有较大的性能提升,主要是因为SPM采用基数树索引,具有更好的读写效率。即使FPM同样将索引节点放置在速度更快的DRAM中,但其在本文实现中依赖运行时的KV解析以从速度更慢的PM中加载具体的KV数据。
lookup性能:表16(c)展示了点读的性能表现,在该实验中SPM-D相对SLM/FFM/FPM性能提升分别达到最高2.7x/14x/16x。对于点读场景,SPM采用前缀匹配,然而SLM/FFM/FPM均采用二分查找的方式。对于key普遍较短的场景下,基数树显然具备更高的读取效率。虽然FPM在叶子结点中采用基于哈希的指纹标识技术以加速点读性能,实际在内存表中,点读会被转换成短的范围查询用以获取对应key的最新的版本,因此FPM中的指纹技术难以发挥作用。此外,FPM叶子结点采用乱序存放的策略以牺牲一定的读取效率换取写入速度的提升。SPM-D在点读场景下比SPM-P更高,其主要因为SPM-P将索引节点放置在速度更慢的PM中,在读取时,索引性能受限于PM的读取带宽限。对于范围查询性能(图16(d)),SPM-D以及SPM-P表现均不如SLM。虽然在DRAM中基数树的范围查询性能普遍不高,但在本次实验中发现其性能更多是受限于PM的读取带宽。实际上,在进行系统分析表明,在范围查询时,SPM-D从PM读取数据消耗了70%的时间占比。
3 ROR评估
ROR主要影响系统的写入性能。为了减少系统后台任务的干扰,实验中关闭所有的flush以及compaction操作,关闭内存表中的建索引操作。每个线程写入100万个大小为24字节的KV对。实验通过设定不同的线程数以及batch的大小用以评估这些参数对系统写入性能的影响。

图 17 ROR算法评估结果
batch的影响:在表17(a)对应的实验中,通过固定线程数为32,改变batch size的大小以测试batch size对系统写入性能以及延迟的影响。结果表明,调节batch size从1到90时,系统的写入吞吐增长到49x,而平均延迟以及P99延迟分别净增加1.3x以及1.7x。在batch size=90时,其写入的吞吐量甚至超过PM硬件的随机写入24字节的吞吐,主要是因为ROR总是尽量采用顺序写的方式。当batch size从50增加到90时,其性能收益增长较为缓慢,而延迟增加较大,主要是因为此时PM的硬件接近饱和。当batch size大于90时,系统的吞吐量不升反降,这主要是由于大的batch会导致ROR阻塞,进而影响写入的吞吐。
线程数的影响:实验中固定batch size=50,调节线程数从1增加到64。图17(b)中的结果表明,在线程数从1增加到16时,其吞吐量呈线性增加。但当线程数大于16时,性能增长较为缓慢,比如线程数从16增加到64时,吞吐增加到1.1x,但P99延迟上升到2.9x。主要是因为较多的线程并发写入导致对PM硬件的访问竞争加大。实际中,选取合适的线程数以及batch size需要根据具体的硬件设备以及工作负载。
4 Global Index评估

图 18 全局索引GI评估结果
实验中关闭level0到level1的compaction,以评估GI相对于XS的乱序level0的优势,其中XS-PM表示将基线系统的level0以及WAL放入PM中。实验首先随机写入不同大小的KV对,大小从64字节到4KB,总计50GB的数据,并测试随机点读以及范围查询的性能表现。图15(a)表明,对于不同大小的KV对的随机写,XP都优于XS以及XS-PM。在图18(b)(c)中,XP相对于XS以及XS-PM有巨大提升,随机读性能为XS-PM的113x,随机范围查询是XS-PM的21x。其主要是因为实验中关闭了level0到level1的compaction,导致level0堆积过多的乱序的数据块(实验中观测超过58的乱序数据块)。由于XP中GI是全局有序的,因此具备较高的查询性能。
另一个实验使用32个client线程采用读写比为1:1的方式高压力写入数据,运行10分钟并观察系统性能随时间的变化。图18(d)并表明,XP相对于XS/XS-PM性能提升高达15x,并且性能表现更稳定。在实验中,XS以及XS-PM性能降低了85%,而XP仅降低35%。虽然XS-PM将数据放在速度更快的PM中(将PM用作普通磁盘),但其性能表现相对于XP仍具有较大差距,并且level0数据堆积依然会产生较大的影响。而XP采用全局有序的GI以及更高效的in-memory compaction,大大降低level0的数据堆积的影响。
5 Halloc评估

图 19 Halloc评估结果
本实验通过对比Ralloc以及pmemobj以评估Halloc的持久化内存分配性能。Halloc将非持久化内存的管理托管到jemalloc中,因此其性能表现与同类方法相似。读者可以进一步参考文献[4]以了解更多将PM用作非持久化内存的分配器的性能表现。实验运行在单线程下,通过执行100万次内存分配计算单次分配的延迟,分配对象的大小从128字节到16KB。由于Halloc并非通用内存分配器,实验中通过从对象池中分配(Halloc-pool)以及通过grant(Halloc-zone)分别模拟通用内存分配的malloc操作。图19表明,Halloc-pool以及Halloc-zone在所有的测试中分配对象的延迟均小于1us,主要是因为Halloc对每次分配仅使用一个flush以及fence指令。但Halloc仅被设计用来支持基于LSM-tree的系统,通用性不如Ralloc以及pmemobj。
6 重启恢复表现

图 20 重启恢复性能表现评
为了评估系统的恢复性能,实验中写入32GB的数据,其中key/value的大小分别为8字节/500字节,总计7000万个KV对。实验中GI采用非持久化索引,并保持数据全部落在GI。非持久化的GI使得系统重新启动时需要恢复GI中的所有索引,因而等价于需要恢复32GB的内存表。对于基线系统XS以及XS-PM(将WAL放置在PM中),系统关闭flush,因而保证至少32GB的有效WAL。由于XP可以并行的重建索引,实验中设置恢复线程的数量从1逐渐增加到104(所有的CPU core)。图20表明,XP通过并行重建索引可以实现近秒级启动,然而XS以及XS-PM均需要耗费数分钟级的时间,其中一个比较重要的原因是基线系统仅支持单线程恢复。由于XP可以并行恢复,因此可以在系统启动时利用全部的CPU资源以加快启动速度。实际的应用场景中,内存表的大小通常远小于32GB,因此恢复时间可达秒级以下。极速的数据库可恢复性也许可以改变现有的通过主备等方式实现HA的方案,进而省略备用节点,具备降低一半的ECS实例潜能。
七 后记
本文仅仅是应用PM等新硬件,针对基于LSM-tree的OLTP存储引擎进行优化探索而迈出的一小步。实际上实现一个可用的工业级存储引擎涉及很多方面,如可靠性、可用性、稳定性、性价比等,更多是寻找多方面因素的一个平衡的过程。而就本文中的方案,在实际的工业落地中依然存在以下亟待解决的问题。
- 数据可靠性问题。对于数据库系统,数据可靠性处于极其重要的位置。PM虽然能够提供持久化的字节寻址能力,但其依然存在设备写入磨损、硬件失效等影响数据可靠性的问题。云上数据库实例中,传统的持久化存储层通过多副本及分布式共识协议等方式实现高可靠性的数据存储,因此将PM作为持久化存储时依然需要解决该问题。一种可期望的解决方案是构建基于PM的高可靠的分布式持久化内存池,但分布式化的PM内存池如何设计,可能具有何种I/O特性等仍需要进一步探索。面对工业化落地时,在OLTP存储引擎设计中针对单机PM硬件优化持久化索引意义可能不是很大。
- PM内存使用效率问题。在该论文中,PM的内存可以用于持久化目的以及非持久化目的,但在固定PM容量下,如何确定多少内存空间分配给持久化使用,多少空间用于非持久化目的等是一个值得进一步探索的问题。例如,根据负载自动调节空间的分配比例,在写密集的负载中分配更多的PM内存用于持久化存储,在读密集型负载分配更多的内存用于cache等非持久化目的。
- 性能抖动问题。对于基于LSM-tree的存储引擎,一个让人头疼的问题就是性能抖动问题,而产生抖动的一个重要原因是后台compaction导致的cache批量剧烈的失效。在分布式场景中可以通过smart cache[5]等方式缓解该问题,在单机情况下,是否可以通过在PM中分配单独的缓存空间用于临时缓存compaction的旧数据,之后缓慢的执行cache的替换?
延伸阅读
[1] J. Yang, J. Kim, M. Hoseinzadeh, J. Izraelevitz, and S. Swanson, “An empirical guide to the behavior and use of scalable persistent memory,” in Proceedings of the 18th USENIX Conference on File and Storage Technologies (FAST ’20), 2020, pp. 169–182.
[2] B. Daase, L. J. Bollmeier, L. Benson, and T. Rabl, “Maximizing Persistent Memory Bandwidth Utilization for OLAP Workloads,” Sigmod, no. 1, p. 13, 2021.
[3] G. Huang et al., “X-Engine: An optimized storage engine for large-scale e-commerce transaction processing,” in Proceedings of the ACM SIGMOD International Conference on Management of Data, Jun. 2019, pp. 651–665.
[4] D. Waddington, M. Kunitomi, C. Dickey, S. Rao, A. Abboud, and J. Tran, “Evaluation of intel 3D-Xpoint NVDIMM technology for memory-intensive genomic workloads,” in ACM International Conference Proceeding Series, Sep. 2019, pp. 277–287.
[5] M. Y. Ahmad and B. Kemme, “Compaction management in distributed keyvalue datastores,” Proc. VLDB Endow., vol. 8, no. 8, pp. 850–861, 2015.
原文链接
本文为阿里云原创内容,未经允许不得转载。