概述
从今天开始我们将开启一段自然语言处理 (NLP) 的旅程. 自然语言处理可以让来处理, 理解, 以及运用人类的语言, 实现机器语言和人类语言之间的沟通桥梁.
RNN
RNN (Recurrent Neural Network), 即循环神经网络. RNN 相较于 CNN, 可以帮助我们更好的处理序列信息, 挖掘前后信息之间的联系. 对于 NLP 这类的任务, 语料的前后概率有极大的联系. 比如: “明天天气真好” 的概率 > “明天天气篮球”.
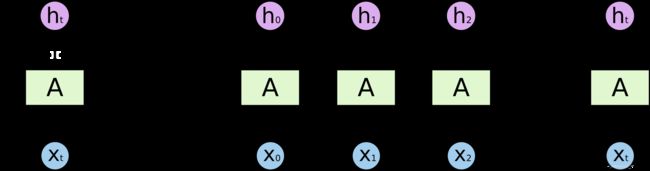
权重共享
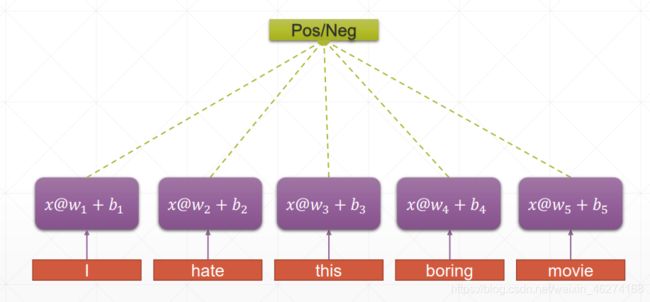
传统神经网络:
RNN:
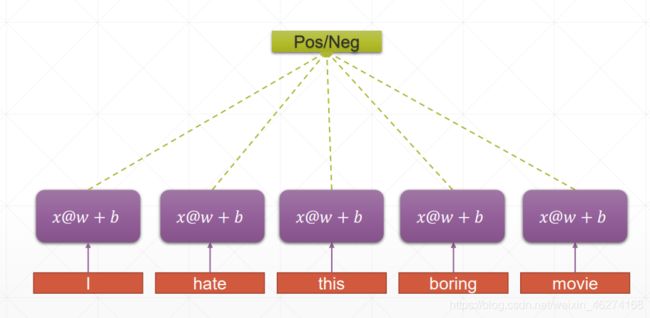
RNN 的权重共享和 CNN 的权重共享类似, 不同时刻共享一个权重, 大大减少了参数数量.
计算过程
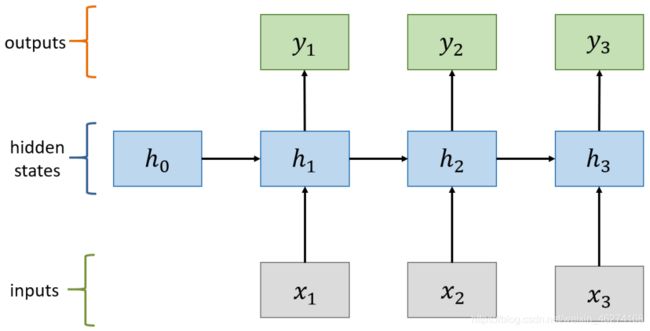
计算状态 (State)
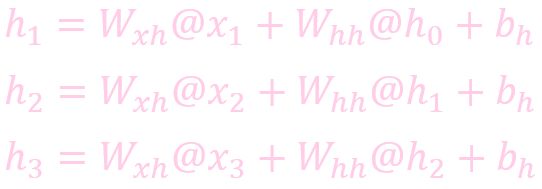
计算输出:
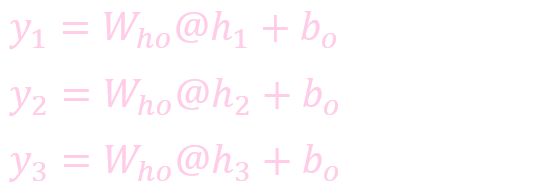
LSTM
LSTM (Long Short Term Memory), 即长短期记忆模型. LSTM 是一种特殊的 RNN 模型, 解决了长序列训练过程中的梯度消失和梯度爆炸的问题. 相较于普通 RNN, LSTM 能够在更长的序列中有更好的表现. 相比 RNN 只有一个传递状态 ht, LSTM 有两个传递状态: ct (cell state) 和 ht (hidden state).

阶段
LSTM 通过门来控制传输状态。
LSTM 总共分为三个阶段:
- 忘记阶段: 对上一个节点传进来的输入进行选择性忘记
- 选择记忆阶段: 将这个阶段的记忆有选择性的进行记忆. 哪些重要则着重记录下来, 哪些不重要, 则少记录一些
- 输出阶段: 决定哪些将会被当成当前状态的输出
代码
预处理
import pandas as pd
import re
from bs4 import BeautifulSoup
from sklearn.model_selection import train_test_split
import tensorflow as tf
# 停用词
stop_words = pd.read_csv("data/stopwords.txt", index_col=False, quoting=3, sep="\n", names=["stop_words"])
stop_words = [word.strip() for word in stop_words["stop_words"].values]
# 用pandas读取训练数据
def load_data():
# 语料
data = pd.read_csv("data/labeledTrainData.tsv", sep="\t", escapechar="\\")
print(data[:5])
print("评论数量:", len(data))
return data
def pre_process(text):
# 去除网页链接
text = BeautifulSoup(text, "html.parser").get_text()
# 去除标点
text = re.sub("[^a-zA-Z]", " ", text)
# 分词
words = text.lower().split()
# 去除停用词
words = [w for w in words if w not in stop_words]
return " ".join(words)
def split_data():
# 读取文件
data = pd.read_csv("data/train.csv")
print(data.head())
# 实例化
tokenizer = tf.keras.preprocessing.text.Tokenizer()
# 拟合
tokenizer.fit_on_texts(data["review"])
# 词袋
word_index = tokenizer.word_index
print(word_index)
print(len(word_index))
# 转换成数组
sequence = tokenizer.texts_to_sequences(data["review"])
# 填充
character = tf.keras.preprocessing.sequence.pad_sequences(sequence, maxlen=200)
# 标签转换
labels = tf.keras.utils.to_categorical(data["sentiment"])
# 分割数据集
X_train, X_test, y_train, y_test = train_test_split(character, labels, test_size=0.2,
random_state=0)
return X_train, X_test, y_train, y_test
if __name__ == '__main__':
# #
# data = load_data()
# data["review"] = data["review"].apply(pre_process)
# print(data.head())
#
# # 保存
# data.to_csv("data.csv")
split_data()
主函数
import tensorflow as tf
from lstm_pre_processing import split_data
def main():
# 读取数据
X_train, X_test, y_train, y_test = split_data()
print(X_train[:5])
print(y_train[:5])
# 超参数
EMBEDDING_DIM = 200 # embedding 维度
optimizer = tf.keras.optimizers.RMSprop() # 优化器
loss = tf.losses.CategoricalCrossentropy(from_logits=True) # 损失
# 模型
model = tf.keras.Sequential([
tf.keras.layers.Embedding(73424, EMBEDDING_DIM),
tf.keras.layers.LSTM(200, dropout=0.2, recurrent_dropout=0.2),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Dense(64, activation="relu"),
tf.keras.layers.Dense(2, activation="softmax")
])
model.build(input_shape=[None, 20])
print(model.summary())
# 组合
model.compile(optimizer=optimizer, loss=loss, metrics=["accuracy"])
# 训练
model.fit(X_train, y_train, validation_data=(X_test, y_test), epochs=2, batch_size=32)
# 保存模型
model.save("movie_model.h5")
if __name__ == '__main__':
# 主函数
main()
输出结果:
2021-09-14 22:20:56.974310: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcudart.so.11.0
Unnamed: 0 id sentiment review
0 0 5814_8 1 stuff moment mj ve started listening music wat...
1 1 2381_9 1 classic war worlds timothy hines entertaining ...
2 2 7759_3 0 film starts manager nicholas bell investors ro...
3 3 3630_4 0 assumed praised film filmed opera didn read do...
4 4 9495_8 1 superbly trashy wondrously unpretentious explo...
73423
[[15958 623 12368 4459 622 835 30 152 2097 2408 35364 57143
892 2997 766 42223 967 266 25276 157 108 696 1631 198
2576 9850 3745 27 52 3789 9503 696 526 52 354 862
474 38 2 101 11027 696 6456 22390 969 5873 5376 4044
623 1401 2069 718 618 92 96 138 1345 714 96 18
123 1770 518 3314 354 983 1888 520 83 73 983 2
28 28635 1044 2054 401 1071 85 8565 8957 7226 804 46
224 447 2113 2691 5742 10 5 3217 943 5045 980 373
28 873 438 389 41 23 19 56 122 9 253 27176
2149 19 90 57144 53 4874 696 6558 136 2067 10682 48
518 1482 9 3668 1587 3786 2 110 10 506 25150 20744
340 33 316 17 4824 3892 978 14 10150 2596 766 42223
5082 4784 700 198 6276 5254 700 198 2334 696 20879 5
86 30 2 583 2872 30601 30 86 28 83 73 32
96 18 2 224 708 30 167 7 3791 216 45 513
2 2310 513 1860 4536 1925 414 1321 578 7434 851 696
997 5354 57145 162 30 2 91 1839]
[ 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 1 357 684
28 3027 10371 5801 20987 21481 19800 1 3027 10371 21481 19800
1719 204 49 168 250 7355 1547 374 401 5415 24 1719
24 49 168 7355 1547 3610 21481 19800 123 204 49 168
1102 1547 656 213 5432 5183 61 4 66166 20 36 56
7 5183 2025 116 5031 11 45 782]
[ 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 2189 1 586
2189 15 1855 615 400 5394 3797 23866 2892 481 2892 810
22020 17820 1 741 231 20 746 2028 1040 6089 816 5555
41772 1762 26 811 288 8 796 45]
[ 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 85 310 1734 78 1906 78 1906 1412 1985
78 7644 1412 244 9287 7092 6374 2584 6183 3795 3080 1288
2217 3534 6005 4851 1543 762 1797 26144 699 237 6745 7
1288 1415 9003 5623 237 1669 17987 874 421 234 1278 347
9287 1609 7100 1065 75 9800 3344 76 5021 47 380 3015
14366 6523 1396 851 22330 3465 20861 7106 6374 340 60 19035
3089 5081 3 7 1695 10735 3582 92 6374 176 8348 60
1491 11540 28826 1847 464 4099 22 3561 51 22 1538 1027
38926 2195 1966 3089 33 19894 287 142 6374 184 37 4025
67 325 37 421 549 21976 28 7744 2466 31533 27 2836
1339 6374 14805 1670 4666 60 33 12]
[ 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 1 27 52
4639 9 5774 1545 8575 855 10463 2688 21019 1542 1701 653
9765 9 189 706 2212 18342 566 437 2639 4311 4504 26110
307 496 893 317 1 27 52 587]]
[[0. 1.]
[0. 1.]
[0. 1.]
[1. 0.]
[0. 1.]]
2021-09-14 22:21:02.212681: I tensorflow/compiler/jit/xla_cpu_device.cc:41] Not creating XLA devices, tf_xla_enable_xla_devices not set
2021-09-14 22:21:02.213245: W tensorflow/stream_executor/platform/default/dso_loader.cc:60] Could not load dynamic library 'libcuda.so.1'; dlerror: /usr/lib/x86_64-linux-gnu/libcuda.so.1: file too short; LD_LIBRARY_PATH: /usr/local/nvidia/lib:/usr/local/nvidia/lib64:/usr/local/cuda/lib64/:/usr/lib/x86_64-linux-gnu
2021-09-14 22:21:02.213268: W tensorflow/stream_executor/cuda/cuda_driver.cc:326] failed call to cuInit: UNKNOWN ERROR (303)
2021-09-14 22:21:02.213305: I tensorflow/stream_executor/cuda/cuda_diagnostics.cc:156] kernel driver does not appear to be running on this host (5aa046a4f47b): /proc/driver/nvidia/version does not exist
2021-09-14 22:21:02.213624: I tensorflow/core/platform/cpu_feature_guard.cc:142] This TensorFlow binary is optimized with oneAPI Deep Neural Network Library (oneDNN) to use the following CPU instructions in performance-critical operations: AVX512F
To enable them in other operations, rebuild TensorFlow with the appropriate compiler flags.
2021-09-14 22:21:02.216309: I tensorflow/compiler/jit/xla_gpu_device.cc:99] Not creating XLA devices, tf_xla_enable_xla_devices not set
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding (Embedding) (None, None, 200) 14684800
_________________________________________________________________
lstm (LSTM) (None, 200) 320800
_________________________________________________________________
dropout (Dropout) (None, 200) 0
_________________________________________________________________
dense (Dense) (None, 64) 12864
_________________________________________________________________
dense_1 (Dense) (None, 2) 130
=================================================================
Total params: 15,018,594
Trainable params: 15,018,594
Non-trainable params: 0
_________________________________________________________________
None
2021-09-14 22:21:02.515404: I tensorflow/compiler/mlir/mlir_graph_optimization_pass.cc:116] None of the MLIR optimization passes are enabled (registered 2)
2021-09-14 22:21:02.547745: I tensorflow/core/platform/profile_utils/cpu_utils.cc:112] CPU Frequency: 2300000000 Hz
Epoch 1/2
313/313 [==============================] - 97s 302ms/step - loss: 0.5112 - accuracy: 0.7510 - val_loss: 0.3607 - val_accuracy: 0.8628
Epoch 2/2
313/313 [==============================] - 94s 300ms/step - loss: 0.2090 - accuracy: 0.9236 - val_loss: 0.3078 - val_accuracy: 0.8790
以上就是Python机器学习NLP自然语言处理基本操作电影影评分析的详细内容,更多关于NLP自然语言处理资料请关注脚本之家其它相关文章!