门店经营分析(AB TEST)
数据分析实例测试
案例背景:MuscleHub 是一家新开业的健身房,为了更好地经营业务,店主向顾客提供一次免费的体能测试,但是体能测试会增加人力成本,是否真的有必要向所有顾客提供体能测试呢?请给出你的预判,看看最后的分析结果是否一致呢?
于是,进行AB Test 进行测试,经营模式如下图所示:

准备数据
1.案例数据有四个csv文件,分别是visits.csv(来客信息)、fitness_tests.csv(体能测试信息)、applications.csv(申请信息)、purchases.csv(付费信息)
数据来源于网络,导入三剑客模块加卡方检验:
from matplotlib import pyplot as plt
import numpy as np
import pandas as pd
from scipy.stats import chi2_contingency
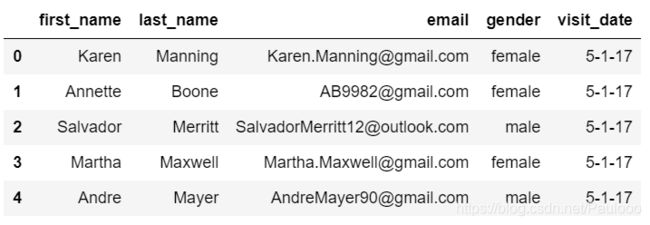
用read_csv()方法导入数据源,观察各表的数据结构:
visits = pd.read_csv('visits.csv')
visits.head()
fitness_tests = pd.read_csv('fitness_tests.csv')
fitness_tests.head()

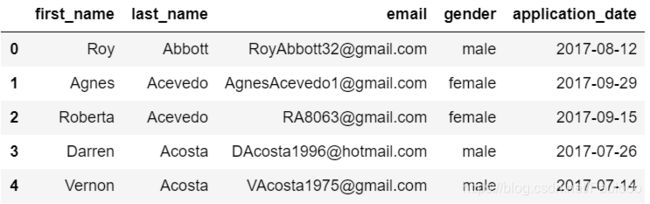
applications = pd.read_csv('applications.csv')
applications.head()
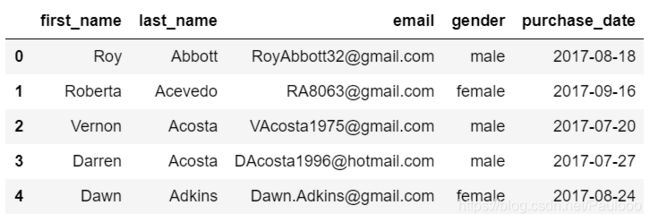
purchases = pd.read_csv('purchases.csv')
purchases.head()
可以看出,每个表之间有大量的重复客户信息,进行多表关联,把客户的行为(来访-测试-申请-付费)放在一张表中,由于业务需要,只选取近期在7-1-17之后的数据,并且认为Email是主键(即认为Email是不可重复的),这里直接在数据库中进行了操作:
SELECT visits.first_name,visits.last_name,visits.gender,visits.email,visits.visit_date,
fitness_tests.fitness_test_date,
applications.application_date,
purchases.purchase_date
FROM visits LEFT JOIN fitness_tests
ON visits.email = fitness_tests.email
LEFT JOIN applications
ON visits.email = applications.email
LEFT JOIN purchases
ON visits.email = purchases.email
WHERE visits.visit_date >= '7-1-17'
将查询结果导入python命名为df数据框,先查看df的大致信息:
df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 5006 entries, 0 to 5005
Data columns (total 8 columns):
first_name 5006 non-null object
last_name 5006 non-null object
gender 5006 non-null object
email 5006 non-null object
visit_date 5006 non-null object
fitness_test_date 2509 non-null object
application_date 575 non-null object
purchase_date 450 non-null object
dtypes: object(8)
memory usage: 313.0+ KB
总共有5006条数据,数据很干净,没有空值(店主值得表扬),通过info,知道了df的行数和具体的列,df数据框的逻辑就是,每个行为下都有日期,若日期为null则代表该客户没有参与该行为。
进行分析
因为数据干净,中间省略了清洗、重复值处理过程,接下来先把数据分为A,B两组:
df['ab_test_group'] = df.fitness_test_date.apply(lambda x:
'A' if pd.notnull(x) else 'B')
ab_counts = df.groupby('ab_test_group').email.count().reset_index()
plt.pie(ab_counts.email,labels=['A','B'],autopct='%0.2f%%')
plt.axis('equal')
plt.show()
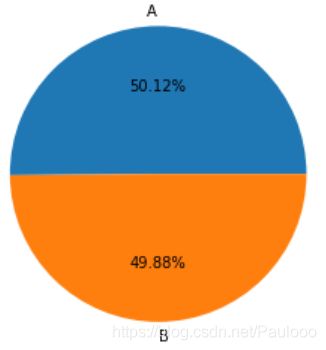
用匿名函数为df增加了一列分组信息,再对每个组别进行计数,用饼图查看A,B两组人数分布是否相当,可以看出两组人数基本一样。
再添加一列,来统计申请信息,并结合组别进行计数:
df['is_application'] = df.application_date.apply(lambda x:
'Application' if pd.notnull(x)
else 'No Application')
app_counts = df.groupby(['ab_test_group','is_application']).email.count().reset_index()
app_counts
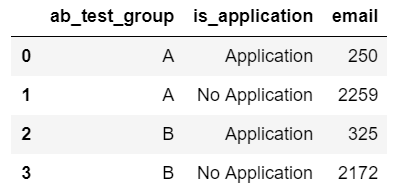
上图这种形式,不够直观,也不便于后续的分析,比如要求各组别的申请率,基于上表就不能进行整列操作,所以转化为pivot形式:
app_pivot = app_counts.pivot(columns = 'is_application',
index = 'ab_test_group',
values = 'email').reset_index()
app_pivot
```
然后就可以进行整列操作啦,添加Total 和 Percent 两列:
```python
app_pivot['Total'] = app_pivot['Application'] + app_pivot['No Application']
app_pivot['Percent with Application'] = app_pivot['Application']/app_pivot['Total']
app_pivot

可以看出B组的申请率高出A组四个点,数字背后是否有猫腻呢,熟悉的卡方检验上场了:
contingency = ([250,2259],
[325,2172])
chi2_contingency(contingency)
(11.163926105867061,
0.0008340323282603952,
1,
array([[ 288.18917299, 2220.81082701],
[ 286.81082701, 2210.18917299]]))
输出结果的第二个即为P值,远小于显著性水平α=5%,所以零假设为假,得出结论:没有参与体能测试得客户的申请率更高。从申请到付款这个行为也会流失掉一部分客户,所以针对这一过程再次分析:
df['is_member'] = df.purchase_date.apply(lambda x: 'Member' if pd.notnull(x)
else 'Not Member')
just_apps = df[df.is_application == 'Application']
member_count = just_apps.groupby(['ab_test_group','is_member']).email.count().reset_index()
member_pivot = member_count.pivot(columns = 'is_member',
index = 'ab_test_group',
values = 'email').reset_index()
member_pivot['Total'] = member_pivot['Member'] + member_pivot['Not Member']
member_pivot['Percent Purchase'] = member_pivot['Member']/member_pivot['Total']
member_pivot
contingency2 = [[200, 50], [250, 75]]
chi2_contingency(contingency2)

(0.615869230769231,
0.43258646051083327,
1,
array([[195.65217391, 54.34782609],
[254.34782609, 70.65217391]])
这里得出P值为43%,远大于显著性水平,所以体能测试对申请者的付费行为没有显著影响,换句话说一旦潜在客户完成了申请这个行为,体能测试这个活动将不对他后续的付费造成影响。
但健身房最终的目的是要客户完成最后付款获取收益,所以,再来查看每个组的最终付款率,故技重施:
final_member_count = df.groupby(['ab_test_group', 'is_member']).email.count().reset_index()
final_member_pivot = final_member_count.pivot(columns = 'is_member',
index = 'ab_test_group',
values = 'email').reset_index()
final_member_pivot['Total'] = final_member_pivot['Member']+final_member_pivot['Not Member']
final_member_pivot['Percent Purchase'] = final_member_pivot['Member']/final_member_pivot['Total']
final_member_pivot
contingency3 = [[200, 2309], [250, 2247]]
chi2_contingency(contingency3)
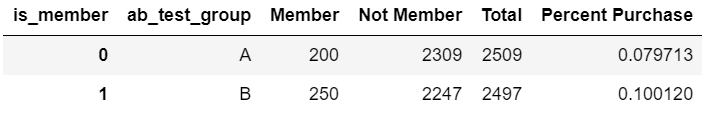
(6.123550458825774,
0.013339261893301502,
1,
array([[ 225.53935278, 2283.46064722],
[ 224.46064722, 2272.53935278]]))
到了这里,P值为1.3%又小于显著性水平,我们就有理由相信B组的客户从“来访-未参加体能测试-申请-付费”这一条路径下来留存高于A组,即健身房从B组潜在客户中赚到钱的概率确实高于A组。
不知道是否与你的猜想一致,反正与我的不一致。后来想了想,这背后的原因可能是很多参与免费体能测试的人的目的就只是冲着免费进行一次测试来的,测了就跑(毕竟自己也干过这种事情),也有可能是体能测试的过程没有给到客户好的体验,于是丢失了用户等等,数据背后的原因千千万万,只要脑洞够大就可以想到更多的潜在原因,具体的还是要结合业务去解释数据所呈现出来的现象。
可视化
这份数据简单,因此只是做了一副比较丑陋的漏斗图:
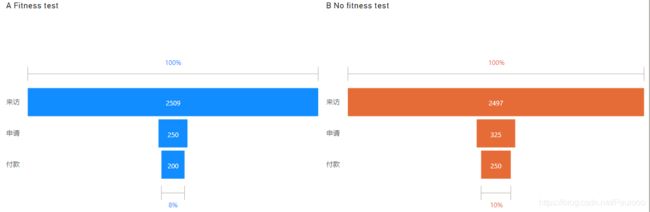
结论
1.从图中可以更直观地看出,“来访-申请”这个过程中,流失了绝大部分的客户,这背后的原因就可能是门店体验差、接待客户不到位、销售不积极等等,这一块的服务提升是很大的增加收益的空间,应该重点关注;
2.一旦用户完成了申请那么付款的转化率所受影响很小,对于完成申请但未付款的客户可以采取一系列唤回措施;
3.虽然B组最终的转化率只高出了A组2%,但通过假设验证,这个差值不是随机误差,A组提供了免费体验,增加了人力成本却没有带来更高的收益(吃力不讨好),应该从两方面去反思:(1)来参与体测的客户的消费意愿,是否强烈表现出只是来蹭个免费体测,应当尽可能剔除这部分(白嫖)客户,(2)体测的服务体验不够好,可能是私教的专业性,销售技巧等等原因造成。