AllenNLP2.2.0:入门篇
# 前言
AllenNLP 是艾伦人工智能研究院开发的开源 NLP 平台。它的设计初衷是为 NLP 研究和开发(尤其是语义和语言理解任务)的快速迭代提供支持。它提供了灵活的 API、对 NLP 很实用的抽象,以及模块化的实验框架,从而加速 NLP 的研究进展。
AllenNLP API 文档:https://docs.allennlp.org/v2.2.0/(根据版本号修改网址
AllenNLP Guide 指南:https://guide.allennlp.org/your-first-model
# 安装
1. 若有GPU查看CUDA版本
输入nvcc -V命令,即可查询到CUDA版本号

2.1 Windows版(无GPU的情况
torch安装教程:链接
 https://pytorch.org/get-started/locally/
https://pytorch.org/get-started/locally/
# 安装pytorch
pip install torch==1.8.1+cpu torchvision==0.9.1+cpu torchaudio===0.8.1 -f https://download.pytorch.org/whl/torch_stable.html
# 安装allennlp
pip install allennlp==2.2.02.2 Linux版(有GPU的情况
# 查看conda已有虚拟环境
conda info -e
# 激活/关闭虚拟环境
conda activate 环境名
conda deactivate
# 创建新环境
conda create -n allennlp python=3.7 # 发现最后创建的python -V 是3.7.10
# 安装pytorch #pytorch 1.8.1 torchvision 0.9.1 torchaudio 0.8.1 cudatoolkit 10.2.89
conda install pytorch torchvision torchaudio cudatoolkit=10.2 -c pytorch
# 安装allennlp 2.2.0
conda install allennlp然而在Linux上运行时一直报错:
[libprotobuf ERROR google/protobuf/descriptor_database.cc:641] File already exists in database: proto3
[libprotobuf FATAL google/protobuf/descriptor.cc:1371] CHECK failed: GeneratedDatabase()->Add(encoded_file_descriptor, size):
terminate called after throwing an instance of 'google::protobuf::FatalException'
what(): CHECK failed: GeneratedDatabase()->Add(encoded_file_descriptor, size):
Aborted
把allennlp、pytorch卸载后,直接安装allennlp就没有该错了...最终的版本号:
pytorch==1.7.0
torchvision==0.8.1
allennlp==2.2.0# 案例
在看了一堆教程后,决定按这篇博客 #AllenNLP 使用教程# 进行学习,它对官方提供的一个入门教程进行了翻译。然而实操途中遇到不少错误...后来发现这篇教程是基于allennlp 0.6.1
版本更新:# AllenNLP Changelog #
-
概要
Allennlp的基本使用流程是需要自定义两个文件:① datareader;② model;
数据、模型全部都定义完成了之后,需要写一个json文件用来完成对模型的基本配置。
-
介绍
对学术论文进行分类的模型:给出一篇论文的标题和摘要,我们想要判断它到底是在“自然语言处理领域ACL”,“机器学习领域ML” 还是 “人工智能领域AI”的论文
-
数据
{
"title": "Interferring Discourse Relations in Context",
"paperAbstract": "We investigate various contextual effects on text interpretation...",
"venue": "ACL"
}train数据:https://s3-us-west-2.amazonaws.com/allennlp/datasets/academic-papers-example/train.jsonl
dev数据:https://s3-us-west-2.amazonaws.com/allennlp/datasets/academic-papers-example/dev.jsonl
注:数据下载后需要进行处理,源数据中还含有一些论文其他信息,由于这里不会使用到,可以只提取出title、paperAbstract、venue,以及可能会有ASCII编码转换的问题需要处理
-
DataReader代码
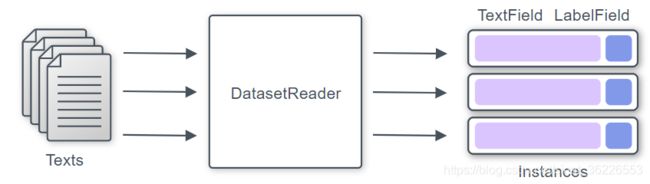
可以通过继承DatasetReader类来实现自己的DatasetReader。至少需要重写_read()方法,该方法读取输入数据集并生成实例。
Reader将获取输入文件中的每一行,使用tokenizer将文本拆分为单词,并使用allennlp自动构建的词汇表中的单词id将这些单词表示为张量
在 AllenNLP 当中需要指定一个 DatasetReader 用于提供解析数据的方法,自己实现的 DatasetReader 需要提供两个方法(# AllenNLP 数据加载 #
- _read 方法,输入是希望读取的文件的路径,不断的 yield Instance 类型的数据
- text_to_instance,在 _read 方法当中调用,目标是根据 _read 获取到的文本数据,制作 Instance 数据
@DatasetReader.register("s2_papers")
class SemanticScholarDatasetReader(DatasetReader):
def __init__(self,
tokenizer: Tokenizer = None,
token_indexers: Dict[str, TokenIndexer] = None) -> None:
super().__init__()
self._tokenizer = tokenizer or WhitespaceTokenizer()
self._token_indexers = token_indexers or {"tokens": SingleIdTokenIndexer()}
def _read(self, file_path):
with open(file_path, "r") as data_file:
logger.info("Reading instances from lines in file at: %s", file_path)
for line in data_file.readlines():
line = line.strip("\n")
if not line:
continue
paper_json = json.loads(line, strict=False)
title = paper_json['title']
abstract = paper_json['paperAbstract']
venue = paper_json['venue']
yield self.text_to_instance(title, abstract, venue)
def text_to_instance(self, title: str, abstract: str, venue: str = None) -> Instance:
tokenized_title = self._tokenizer.tokenize(title)
tokenized_abstract = self._tokenizer.tokenize(abstract)
title_field = TextField(tokenized_title, self._token_indexers)
abstract_field = TextField(tokenized_abstract, self._token_indexers)
fields = {'title': title_field, 'abstract': abstract_field}
if venue is not None:
fields['label'] = LabelField(venue)
return Instance(fields)-
Model代码
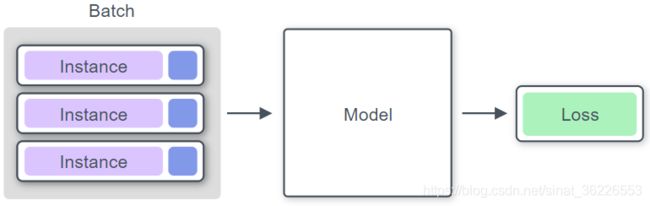
Model将获取一批Instance,预测输入的输出,并计算损失。
从概念上讲,文本分类的通用模型是这样做的:

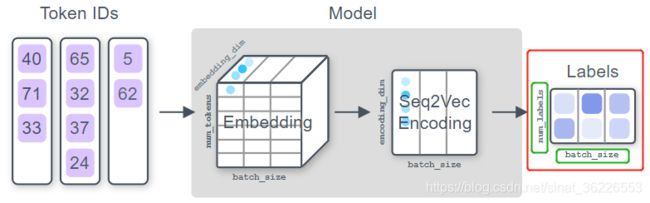
Step 1(Embedding tokens):
应用一个嵌入 (Embedding) 函数,将输入的每个token ID转换为向量
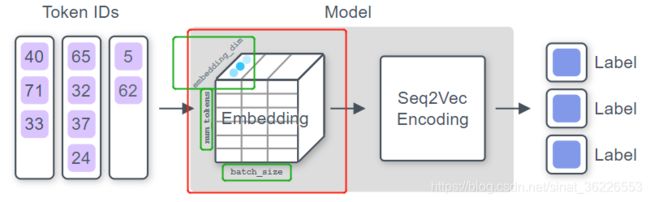
此处的token ID是allennlp为我们自动构建的词汇表中的单词ID,embedding_dim为设置的词向量维数,num_tokens为token的数目,batch_size为批量示例的数目

Step 2(Apply Seq2Vec encoder):
应用某个函数,将每个输入token的向量序列压缩为单个向量 [ [..], [..], [..] ... [..] ] → [ ....... ]

在像BERT这样的预训练语言模型出现之前,通常使用LSTM或CNN # 链接:seq2vec_encoders #
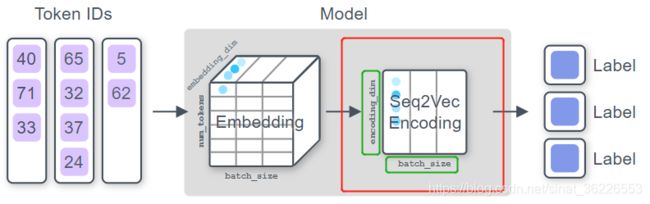
Step 3(Computing distribution over labels):
最后加一个分类层,它可以将encoder的输出转换为logits,每个标签可能分类到的值(可以理解为未归一化的概率 )。 这些值将在以后转换为概率分布,并用于计算损失。
@Model.register("paper_classifier")
class AcademicPaperClassifier(Model):
def __init__(self,
vocab: Vocabulary,
text_field_embedder: TextFieldEmbedder,
title_encoder: Seq2VecEncoder,
abstract_encoder: Seq2VecEncoder,
classifier_feedforward: FeedForward,
initializer: InitializerApplicator = InitializerApplicator(),
regularizer: Optional[RegularizerApplicator] = None) -> None:
super(AcademicPaperClassifier, self).__init__(vocab, regularizer)
self.text_field_embedder = text_field_embedder
self.num_classes = self.vocab.get_vocab_size("labels")
self.title_encoder = title_encoder
self.abstract_encoder = abstract_encoder
self.classifier_feedforward = classifier_feedforward
self.metrics = {
"accuracy": CategoricalAccuracy(),
"accuracy3": CategoricalAccuracy(top_k=3)
}
self.loss = torch.nn.CrossEntropyLoss()
initializer(self)
def forward(self,
title: Dict[str, torch.LongTensor],
abstract: Dict[str, torch.LongTensor],
label: torch.LongTensor = None) -> Dict[str, torch.Tensor]:
embedded_title = self.text_field_embedder(title)
title_mask = util.get_text_field_mask(title)
encoded_title = self.title_encoder(embedded_title, title_mask)
embedded_abstract = self.text_field_embedder(abstract)
abstract_mask = util.get_text_field_mask(abstract)
encoded_abstract = self.abstract_encoder(embedded_abstract, abstract_mask)
logits = self.classifier_feedforward(torch.cat([encoded_title, encoded_abstract], dim=-1))
class_probabilities = F.softmax(logits)
output_dict = {"class_probabilities": class_probabilities}
if label is not None:
loss = self.loss(logits, label.squeeze(-1))
for metric in self.metrics.values():
metric(logits, label.squeeze(-1))
output_dict["loss"] = loss
return output_dict
def get_metrics(self, reset: bool = False) -> Dict[str, float]:
return {metric_name: metric.get_metric(reset) for metric_name, metric in self.metrics.items()}
def decode(self, output_dict: Dict[str, torch.Tensor]) -> Dict[str, torch.Tensor]:
predictions = output_dict['class_probabilities'].cpu().data.numpy()
argmax_indices = numpy.argmax(predictions, axis=-1)
labels = [self.vocab.get_token_from_index(x, namespace="labels")
for x in argmax_indices]
output_dict['label'] = labels
return output_dict InitializerApplicator包含着所有参数的基本初始化方法。如果你想自定义初始化,就需要时候用RegularizerApplicator
注意我们需要利用一个叫masks的变量来标识哪些元素仅仅是用来标识边界的,而不需要模型考虑 # NLP 中消除padding对计算影响的技巧 #
decode函数包括两个功能 ①是接收forward函数的返回值,并且对这个返回值进行操作,比如说算出具体是那个词啊等等。②是将数字变成字符,方便阅读。
forward方法最后返回output,但它是一个词典类型,包含tag_logits标签得分和损失值。如果传入的labels不是None,需要计算损失值,将预测的tag_logits得分、正确标签和Mask矩阵传入accuracy即可自动完成计算。forward方法调用结束后将自动调用get_metrics方法,因此在get_metrics方法中定义的计算精度也将自动被调用。
-
配置文件
虽然我们已经写好datareader和model的代码,但我们不会去调用构造函数,而是通过config完成
[1] 为了能够在配置文件中找到我们定义的这个
model以及dataset_reader,我们需要给这两个类注册一个名字,如@DatasetReader.register("s2_papers")。有了这个注册,我们就能够在配置文件中使用这个类。[2] 在AllenNLP当中,所有的类都是可以动态加载的,最简单的理解就是,你在Json里存一个比如 dataset 的类名, 他会根据这个类名自动的去找到这个类的定义,然后创建一个实例 [AllenNLP 注册机制]
[3] 分批训练数据。 AllenNLP提供了一个名为BucketIterator的迭代器,通过对每批最大输入长度填充批量,使计算(填充)更高效。要做到这一点,它将按照每个文本中的符号数对实例进行排序。 我们在 'iterator' 键值中设置这些参数 [来源]
[4] AllenNLP之所以好用,主要是因为其支持解析JSON参数文件,将模型涉及的参数完全定义到JSON文件中,由AllenNLP动态解析绑定,可以轻而易举地完成模型的各种改动尝试,因为要改动模型更改JSON配置文件即可,而不需要非编写代码不可,改动JSON文件比改动代码更加灵活
使用AdaGrad作为优化器,执行40个epoch,如果10个epoch没有改进的话就提前结束训练
{
"dataset_reader": {
"type": "s2_papers",
"tokenizer": {
"type": "spacy",
},
"token_indexers": {
"tokens": {
"type": "single_id",
}
},
},
"train_data_path": "./Data/train-pre.json",
"validation_data_path": "./Data/dev-pre.json",
"trainer": {
"num_epochs": 40,
"patience": 10,
"cuda_device": 0,
"grad_clipping": 5.0,
"validation_metric": "+accuracy",
"optimizer": {
"type": "adagrad"
}
},
"data_loader": {
"batch_size": 8
},
"model": {
"type": "paper_classifier",
"text_field_embedder": {
"token_embedders": {
"tokens": {
"type": "embedding",
"embedding_dim": 100
}
}
},
"title_encoder": {
"type": "lstm",
"bidirectional": true,
"input_size": 100,
"hidden_size": 100,
"num_layers": 1,
"dropout": 0.2
},
"abstract_encoder": {
"type": "lstm",
"bidirectional": true,
"input_size": 100,
"hidden_size": 100,
"num_layers": 1,
"dropout": 0.2
},
"classifier_feedforward": {
"input_dim": 400,
"num_layers": 2,
"hidden_dims": [200, 3],
"activations": ["relu", "linear"],
"dropout": [0.2, 0.0]
}
}
}-
训练模型
最终文件结构:

train后面的参数指定了用哪个配置文件,-s:指定了训练日志、字典、模型等的存放位置,--include-package:指定了我们前面编写的python代码位置 # 链接:解析train过程 #
allennlp train config.json -s ./output --include-package code.paper_classification
在patience个epoch中看不到模型性能提升,模型停止运算。输出结果在./output中
Metrics: {
"best_epoch": 1,
"peak_worker_0_memory_MB": 3709.86328125,
"peak_gpu_0_memory_MB": 129.5810546875,
"training_duration": "0:14:08.685527",
"training_start_epoch": 0,
"training_epochs": 10,
"epoch": 10,
"training_accuracy": 0.9999333333333333,
"training_accuracy3": 1.0,
"training_loss": 0.0009722335907512084,
"training_worker_0_memory_MB": 3709.8515625,
"training_gpu_0_memory_MB": 129.5810546875,
"validation_accuracy": 0.819,
"validation_accuracy3": 1.0,
"validation_loss": 1.1913992423650634,
"best_validation_accuracy": 0.8395,
"best_validation_accuracy3": 1.0,
"best_validation_loss": 0.4236031983792782
}-
预测
Predictor ,从原始文本中生成预测结果,主要流程为获得Instance的json表示,转换为Instance,喂入模型,并以JSON可序列化格式返回预测结果。
# 参考
街道口扛把子(allennlp系列文章:中文分词等
AllenNLP 使用教程(一个官方入门教程的翻译
AllenNLP框架学习笔记(入门篇)(一个基于allennlp 1.2.2的二分类实验、该博主的allennlp系列文章 [链接]
⭐emiya:动手学AllenNLP(注册机制、数据加载、模型调用原理
⭐小猫:深入了解Allennlp细节(DataReader→Model→Train,介绍了很多细节
AllenNLP入门笔记(一)(allennlp常用API介绍、测试模型代码
⭐AllenNLP入门笔记(二)(本文的案例实现,细节介绍很具体;allennlp命令
AllenNLP学习之classifier_model(介绍基础分类器和Bert模型、该博主的allennlp系列文章 [链接]
Deep Learning for text made easy with AllenNLP(翻译稿,对参数进行入门级介绍
AllenNLP之入门解读代码(20 newsgroups分类器的案例(同github:demesquita),在init里面定义网络参数结构、在forward这里构建网络
自然语言处理N天-AllenNLP学习(设定文档解读)(源文件中已分词情况、TextFieldEmbedder的输出是这些嵌入的串联、input_size维度要一致;该博主的allennlp系列文章 [链接]
-
GitHub
justforyou16007/AllenNLP-Tutorials-Chinese(一个基于allennlp 0.8.4的系列教程
nutalk/allennlp_classification(AllenNLP 0.x 实现了基于LSTM、TEXTCNN、BERT的文本分类模型,对应的博客说明 [用AllenNlp写文本分类模型] [用AllenNlp写基于LSTM,TEXTCNN,BERT的文本分类模型]
dmesquita/easy-deep-learning-with-AllenNLP(一个基于allennlp 0.x 的20 newsgroups分类器
mhagiwara/realworldnlp(基于allennlp 1.0.0或以上的语义分析、命名实体识别、词性标注等
-
其他
深度学习 | 三个概念:Epoch, Batch, Iteration
NLP 装桶(Bucketing)和填充(padding)
Seq2seq模型(一)——初窥NLP