transformer详解---bert 详解
注释--------------------------------------------------------------------------------------------------------------------------
关于bert的一些使用问题具体看我这个博客:transformer bert使用教程_py机器学习深度学习的博客-CSDN博客
用自己的话来叙述 bert与transformer的不同:
1 bert只有transformer的encode 结构 ,是生成语言模型
2 bert 加入了输入句子的 mask机制,在输入的时候会随机mask
3 模型接收两个句子作为输入,并且预测其中第二个句子是否在原始文档中也是后续句子 可以做对话机制的应答。
4 在训练 BERT 模型时,Masked LM 和 Next Sentence Prediction 是一起训练的,目标就是要最小化两种策略的组合损失函数。
注释--------------------------------------------------------------------------------------------------------------------------
Transformer模型通俗理解 - BrianX - 博客园
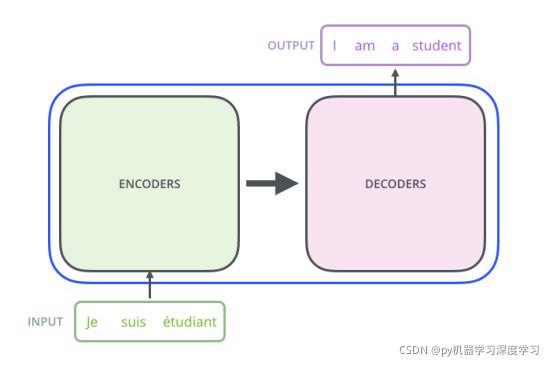
模型解析:上图
一个 encoder 一个 decoder
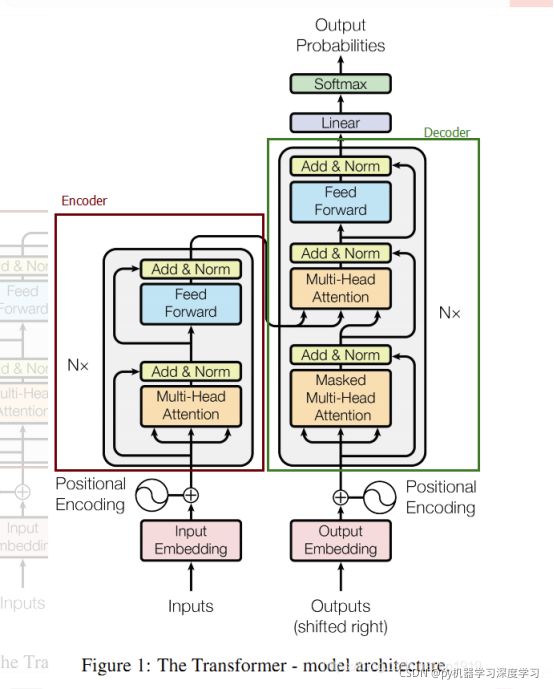
内部详解:
首先这是一个一个 encoder 一个 decoder 组成的结构 真正的transformer中,
encoder 和decoder 有6个块 如下图所示。
1.encoder
对于机器翻译来说,一个样本是由原始句子和翻译后的句子组成的。比如原始句子是: “我爱机器学习”,那么翻译后是 ’i love machine learning‘。 则该一个样本就是由“我爱机器学习”和 "i love machine learning" 组成。
这个样本的原始句子的单词长度是length=4,即‘我’ ‘爱’ ‘机器’ ‘学习’。经过embedding后每个词的embedding向量是512。那么“我爱机器学习”这个句子的embedding后的维度是[4,512 ] (若是批量输入,则embedding后的维度是[batch, 4, 512])。
padding
因为每个样本的原始句子的长度是不一样的,那么怎么能统一输入到encoder呢。此时padding操作登场了,假设样本中句子的最大长度是10,那么对于长度不足10的句子,需要补足到10个长度,shape就变为[10, 512], 补全的位置上的embedding数值自然就是0了
Padding Mask
对于输入序列一般我们都要进行padding补齐,也就是说设定一个统一长度N,在较短的序列后面填充0到长度为N。对于那些补零的数据来说,我们的attention机制不应该把注意力放在这些位置上,所以我们需要进行一些处理。具体的做法是,把这些位置的值加上一个非常大的负数(负无穷),这样经过softmax后,这些位置的权重就会接近0。Transformer的padding mask实际上是一个张量,每个值都是一个Boolean,值为false的地方就是要进行处理的地方。
Positional Embedding
得到补全后的句子embedding向量后,直接输入encoder的话,那么是没有考虑到句子中的位置顺序关系的。此时需要再加一个位置向量,位置向量在模型训练中有特定的方式,可以表示每个词的位置或者不同词之间的距离;总之,核心思想是在attention计算时提供有效的距离信息。
关于positional embedding ,文章提出两种方法:
1.Learned Positional Embedding ,这个是绝对位置编码,即直接对不同的位置随机初始化一个postion embedding,这个postion embedding作为参数进行训练。
2.Sinusoidal Position Embedding ,相对位置编码,即三角函数编码。
输入的句子是 我 爱 机器 学习 经过padding到长度为10 输入到encoder中 最后 encoder输出的是一个[10,512]矩阵p,这个矩阵p作为 value 和key 直接与decoder中query做 attention,也就是说
k v矩阵是来自于encoder的,q是来自于decoder的

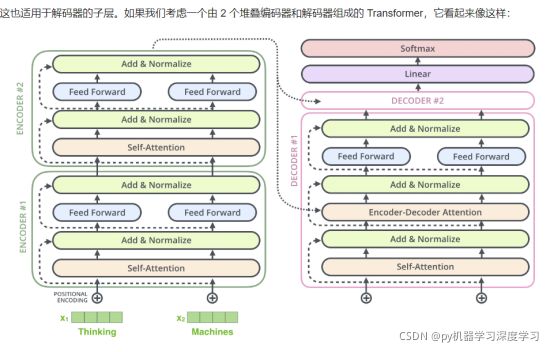
完整的transformer有6个 encoder decoder的

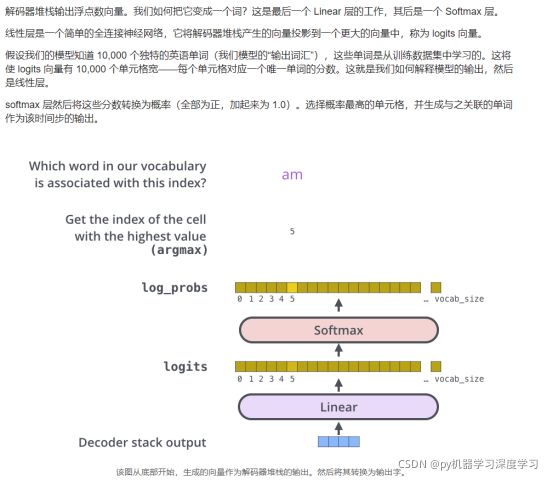
最终的预测是这样的:
总的来说训练时,decoder是并行的,在计算第i个输出的时候,只能看到i之前的输出,而不能看到它后面的,所以就用一个三角矩阵来进行mask,让它不能看到后面的内容。

插入一个训练动图:
bert 详解:
关于bert的一些使用问题具体看我这个博客:transformer bert使用教程_py机器学习深度学习的博客-CSDN博客
用自己的话来叙述 bert与transformer的不同:
1 bert只有transformer的encode 结构 ,是生成语言模型
2 bert 加入了输入句子的 mask机制,在输入的时候会随机mask
3 模型接收两个句子作为输入,并且预测其中第二个句子是否在原始文档中也是后续句子 可以做对话机制的应答。
4 在训练 BERT 模型时,Masked LM 和 Next Sentence Prediction 是一起训练的,目标就是要最小化两种策略的组合损失函数。

Transformer 是一种注意力机制,可以学习文本中单词之间的上下文关系的。
Transformer 的原型包括两个独立的机制,一个 encoder 负责接收文本作为输入,一个 decoder 负责预测任务的结果。
BERT 的目标是生成语言模型,所以只需要 encoder 机制。
Transformer 的 encoder 是一次性读取整个文本序列,而不是从左到右或从右到左地按顺序读取,
这个特征使得模型能够基于单词的两侧学习,相当于是一个双向的功能。
当我们在训练语言模型时,有一个挑战就是要定义一个预测目标,很多模型在一个序列中预测下一个单词,
“The child came home from ___”
双向的方法在这样的任务中是有限制的,为了克服这个问题,BERT 使用两个策略:
bert 改进一:1. Masked LM (MLM)-------------------------------------------------------------------
在将单词序列输入给 BERT 之前,每个序列中有 15% 的单词被 [MASK] token 替换。 然后模型尝试基于序列中其他未被 mask 的单词的上下文来预测被掩盖的原单词。
这样就需要:在 encoder 的输出上添加一个分类层
用嵌入矩阵乘以输出向量,将其转换为词汇的维度
用 softmax 计算词汇表中每个单词的概率
BERT 的损失函数只考虑了 mask 的预测值,忽略了没有掩蔽的字的预测。这样的话,模型要比单向模型收敛得慢,不过结果的情境意识增加了
bert改进二:Next Sentence Prediction (NSP)---------------------------------------------------
在 BERT 的训练过程中,模型接收成对的句子作为输入,并且预测其中第二个句子是否在原始文档中也是后续句子。
在训练期间,50% 的输入对在原始文档中是前后关系,另外 50% 中是从语料库中随机组成的,并且是与第一句断开的。
为了帮助模型区分开训练中的两个句子,输入在进入模型之前要按以下方式进行处理:
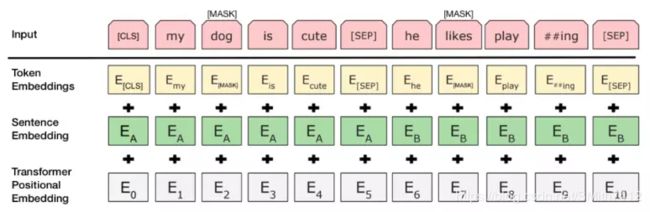
在第一个句子的开头插入 [CLS] 标记,在每个句子的末尾插入 [SEP] 标记。
将表示句子 A 或句子 B 的一个句子 embedding 添加到每个 token 上。
给每个 token 添加一个位置 embedding,来表示它在序列中的位置。
为了预测第二个句子是否是第一个句子的后续句子,用下面几个步骤来预测:
整个输入序列输入给 Transformer 模型
用一个简单的分类层将 [CLS] 标记的输出变换为 2×1 形状的向量
用 softmax 计算 IsNextSequence 的概率
bert分类代码:这里没有用softmax 可能要看实际的问题输出自己测试 ,应该也可以用的!
class BertClassificationModel(nn.Module):
def __init__(self):
super(BertClassificationModel, self).__init__()
model_class, tokenizer_class, pretrained_weights = (tfs.BertModel, tfs.BertTokenizer, 'bert-base-chinese')
self.tokenizer = tokenizer_class.from_pretrained(pretrained_weights)
self.bert = model_class.from_pretrained(pretrained_weights)
self.dense = nn.Linear(768,2) #bert默认的隐藏单元数是768, 输出单元是2,表示二分类
def forward(self, input_ids,attention_mask):
bert_output = self.bert(input_ids, attention_mask=attention_mask)
bert_cls_hidden_state = bert_output[0][:,0,:] #提取[CLS]对应的隐藏状态
linear_output = self.dense(bert_cls_hidden_state)
return linear_output在训练 BERT 模型时,Masked LM 和 Next Sentence Prediction 是一起训练的,目标就是要最小化两种策略的组合损失函数。
如何使用 BERT?-----------------------------------------------------------------------------------------------------------
BERT 可以用于各种NLP任务,只需在核心模型中添加一个层,例如:
在分类任务中,例如情感分析等,只需要在 Transformer 的输出之上加一个分类层
在问答任务(例如SQUAD v1.1)中,问答系统需要接收有关文本序列的 question,并且需要在序列中标记 answer。 可以使用 BERT 学习两个标记 answer 开始和结尾的向量来训练Q&A模型。
在命名实体识别(NER)中,系统需要接收文本序列,标记文本中的各种类型的实体(人员,组织,日期等)。 可以用 BERT 将每个 token 的输出向量送到预测 NER 标签的分类层。