快用爬虫,词云来欣赏长津湖的影评!!!超详细!!!
国庆热档的长津湖究竟怎么样
- 前景导入
- 项目实战
- 总结
前景导入
国庆定档的长津湖可谓激起多少年轻人的热血。经过朋友的推荐,我这个死宅也跃跃欲试出寝室去看电影了。思考再三,还是先准备获取这部电影的评论再下决定。于是做出了这个小小的脚本。
主要需要的技能:
1.非常简易的爬虫。甚至不需要selenium自动化爬虫,也不需要利用爬虫框架
2.python基础语法,熟悉对列表字典的处理,以及对python绘图功能的基础了解
3.学会查阅官方文档,比解析更为有用。
另:做此篇的目的也是为了使自己重新熟悉python爬虫功能,后期CV也会从网络爬取图片进行模型训练,这一方面后期再进行解释。
项目实战
1.网站源码分析
这里我所寻找的网站时豆瓣的评论网站:
link:点击进入.进入我们可以发现网站的域名为:
https://movie.douban.com/subject/25845392/comments?limit=20&status=P&sort=new_score
然后通过javascript跳转到下一页发现网站域名为:
https://movie.douban.com/subject/25845392/comments?start=20&limit=20&status=P&sort=new_score
到这里你应该看出规律了。
1.comment说明这是评论网址
2.start代表其最开始的评论序号-1
3.limit代表每页都是20条消息
4.sort代表按照时间先后来给评论排序
5.其他规律自行发现,不过多阐述
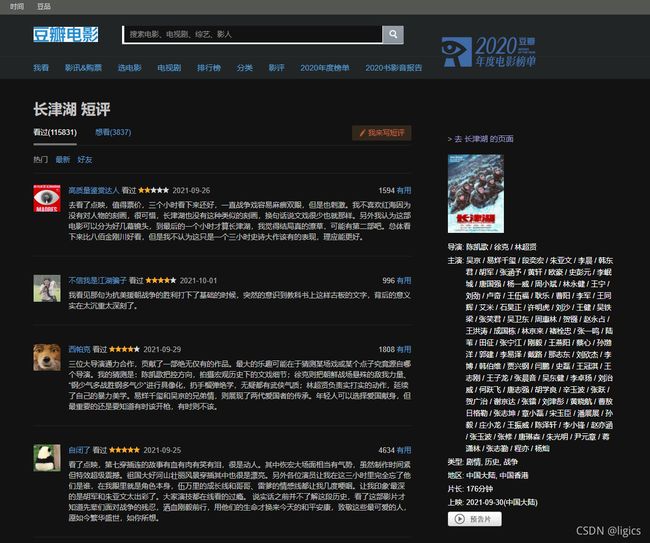
网站截图:
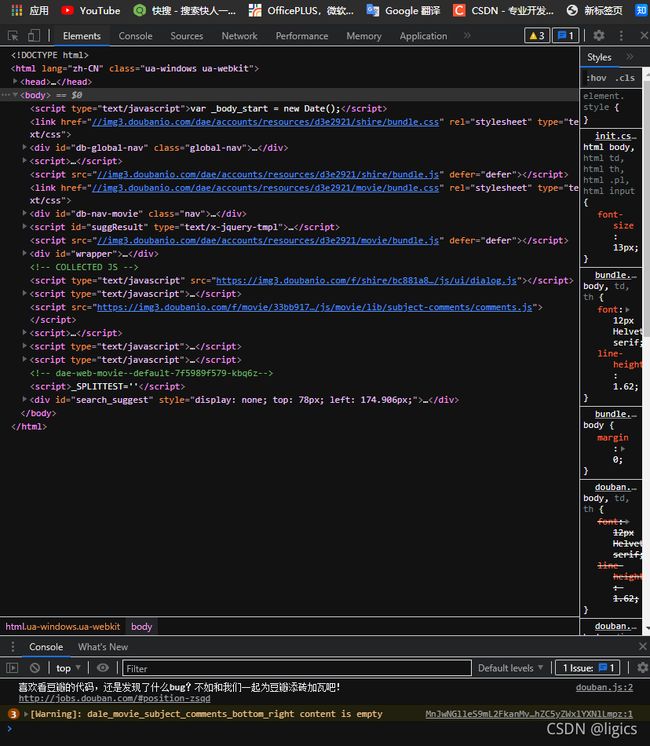
然后就得进入我们的F12的开发者界面进行html解析了。
左下角的豆瓣提示多可爱啊哈哈哈哈哈。据说豆瓣是个经常被爬虫侵犯的网站,在这说声对不起了。
废话不多说,如果大家有html基础可以直接通过点击拓展查询评论所在位置,但有种更为简便的方法:
点击左上角的select element选中界面的评论,然后就会定位到评论区了。
然后我们就能发现其html所在位置。
多次寻找就可以发现规律:可以发现每个评论都在class=“short”>(remark) 这绝对是最最最最简单的爬虫实例了,规律都直接摆在你手上了!

2.爬虫实战:
环境:
py-3.7
requests 负责post申请以及request返回数据,说白就是得到网站源码的
bs4 负责数据处理,进行网页文本解析
time 强大的时间库,这里能提供最简单的反爬虫操作,通过延时
re 提供强大的正则表达式来进行有效数据提取
os 判断是否存在文件
pd 格式化数据并且存入
**Tips:接下来就是代码区了,我们需要注意不是每次申请都能获得有效数据返回,这时就要查看状态码了。
另外,由于某些编码的原因,在编码中我们选择兼容中文的utf-8编码,这样才不会出现乱码的情况,你问我说明是乱码?上图:
这就是乱码。
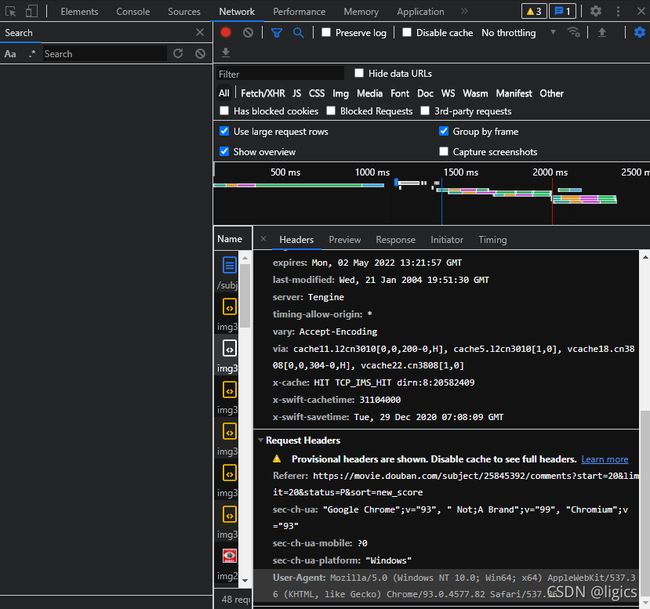
另外,我们需要网站的请求头(header),这个我们可以从F12开发者界面选择network栏,然后刷新界面内,随便选择其中一个element点击,随后会出现header的标识,滑到最底下就能看见了。如图:
至于正则化的话,限于篇幅,这里不做阐述,等有时间单独做一期,这东西还挺复杂了,我起码复习了十遍。
最后,上代码:

##encoding=utf-8
##function:to get the information of changjinghu
import requests #网页的申请
from bs4 import BeautifulSoup #网页解析,获取数据
import time #最简单的防反爬虫的操作
import pandas as pd #数据处理库
import re #规范数据,提取有效数据
import os #创建本地文件存入数据
def html_get(number,header):
#获取网站连接,并且获取网页的html源代码,有些网页需要用json解析,看具体网站
#number指网页后缀(一般开发者网页设置比较规律)
#header指用户代理,表示告诉豆瓣服务器,我们是什么类型的机器、浏览器(本质上是告诉浏览器,我们可以接收什么水平的文件内容)
if number==0:
url=r'https://movie.douban.com/subject/25845392/comments?limit=20&status=P&sort=new_score'
else:
url=r'https://movie.douban.com/subject/25845392/comments?start='+str(number)+r'&limit=20&status=P&sort=new_score'
html=requests.get(url,headers=header)
#发送请求,获取源码,状态码为200说明返回正常
if html.status_code==200:
html.encoding='UTF-8'
return html.text
else:
print('error!')
return None
def data_get():
header={
'User-Agent':
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.90 Safari/537.36'}
remarks=[]
for number in range(0,201,20):
data=BeautifulSoup(html_get(number,header),'html.parser')
remarks_com=re.compile('(.*?)')
remark=re.findall(remarks_com,str(data))
for m in remark:
remarks.append(m)
time.sleep(1)
print('第{0}页提取成功'.format(number/20+1))
return remarks
if __name__=="__main__":
remarks=data_get()
df=pd.DataFrame({
'remark':remarks})
path=r'D:\data\data.csv'
if not os.path.exists(path):
df.to_csv(path,encoding='utf_8_sig')
以上边将所有的数据进行了存储,但我们只完成了第一步,我们还要对数据进行预处理。
2.数据预处理及绘图
以上我们将220条评论存入了我们的data.csv文件中,接下来就是如何处理我们的数据呢?
环境:
py 3.7
matplotlib 绘图工具库,为了模仿matlab,从名字就能看出来
imageio 图片接口库,image+io,顾名思义
wordcloud 词云库,无可替代
jieba 中文分词库,编写这个库的绝对及其勤奋!!!
我在代码中做了及其多的注释,故不在此继续过多废话了
#function:to show the remark
import matplotlib.pyplot as plt #用于绘制图像
import pandas as pd #此处用于数据读取
import jieba #中文分词库,用来获取词频来进行特征提取
from wordcloud import WordCloud,STOPWORDS,ImageColorGenerator
from imageio import imread
#动态调整库
# 动态调整词典
jieba.suggest_freq('长津湖', True) #True表示该词不能被分割,False表示该词能被分割
str_=''
data=pd.read_csv(filepath_or_buffer=r'D:\data\data.csv',
usecols=['remark'])
data_list=data.values.flatten().tolist()
for remark in data_list:
str_=str_+'\n'+str(remark)#转换成字符串的形式,变为单可迭代变量
#接下来开始利用jieba进行分词,为精确模式
words_=jieba.lcut(str_)
#newtxt=' '.join(words_)
num={
}
for word in words_:
if len(word)==1:
#一个单词或者标点符号就选择性删除
continue
else:
num[word]=num.get(word,0)+1#遍历所有词语,没出现一次就加一
#将字典转换为列表,便于排序
items=list(num.items())
#根据词频进行排序
items.sort(key=lambda x:x[1],reverse=True)#使用匿名函数代表提取的是列表中第一列,这里指词频
#获取排序后的词语
words=[wd[0] for wd in items]
newtxt=' '.join(words)
#设置背景图片
bg_pic=imread(r'D:\data\cjh.png')
#生成词云
wordcloud = WordCloud(font_path='msyh.ttc',mask=bg_pic,background_color='white',scale=1.5).generate(newtxt)
#文件类型为字典
image_colors = ImageColorGenerator(bg_pic)
#显示词云图片
plt.imshow(wordcloud)
plt.axis('off')
plt.show()
于是,我们得到词频最多的词语绘制在我所选择的遮罩图片上,建议大家选择黑白分明的照片,这是算法所致,个人在CV方面的知识不算少,所以听我的准没错(问就是黑白的灰度值差大,边缘检测更为精确)
我所选用的原图:

代码生成云图:

是不是好看极了!我记得上次我们学校新生报告也是生成UESTC字样的云图!!!
总结
一切尽在不言中,这部电影我一定会去看!!!可惜卑微的只能和我的室友去看了。。。。