机器翻译
机器翻译
- 现成工具:沙拉查词
- 机器翻译原理
- 最佳翻译
- 会意会的机器翻译:你有算法,我有意会
现成工具:沙拉查词
网页:https://saladict.crimx.com/
大赞,Google 浏览器最好用的扩展之一!
机器翻译原理
如果一个事件的概率会因为某个条件而产生变化,那在这个条件发生的情况下,这个事件发生的概率就是条件概率。
比如,因为昨天晚睡了,所以今天大概率不会早起。
- P ( 早 起 ∣ 晚 睡 ) P(~早起~|~晚睡~) P( 早起 ∣ 晚睡 )
- P ( 事 件 ∣ 条 件 ) P(~事件~|~条件~) P( 事件 ∣ 条件 )
条件概率公式: P ( Y ∣ X ) = P ( X Y ) P ( X ) P( Y| X)=\frac{P(XY)}{P(X)} P(Y∣X)=P(X)P(XY)
- P ( Y ∣ X ) P(Y|X) P(Y∣X):条件概率,表示在 X 条件下 Y 发生的概率
- P ( X Y ) P(XY) P(XY):条件 X、事件 Y 同时发生的概率
- P ( X ) P(X) P(X):条件 X 发生的概率
在文本中的两个词 X 和 Y,前面的词就是后面的词的条件,比如 X 是中药,Y 是人参,反过来也成立,X 是人参,Y 是中药。
于是,就有一个想法:
- P ( Y ∣ X ) = P ( X Y ) P ( X ) P( Y| X)=\frac{P(XY)}{P(X)} P(Y∣X)=P(X)P(XY)
- P ( X ∣ Y ) = P ( X Y ) P ( Y ) P( X| Y)=\frac{P(XY)}{P(Y)} P(X∣Y)=P(Y)P(XY)
我们把俩个式子都变形:
- P ( X Y ) = P ( Y ∣ X ) ∗ P ( X ) P(XY) = P(Y|X)*P(X) P(XY)=P(Y∣X)∗P(X)
- P ( X Y ) = P ( X ∣ Y ) ∗ P ( Y ) P(XY) = P(X|Y)*P(Y) P(XY)=P(X∣Y)∗P(Y)
对比这个式子和前面的式子,我们发现它们都等于 P ( X , Y ) P(X,Y) P(X,Y),因此两个等式的左边也必然相等。
于是,我们就可以得到一个重要的公式:
- P ( Y ∣ X ) ∗ P ( X ) = P ( X ∣ Y ) ∗ P ( Y ) P(Y|X)*P(X)=P(X|Y)*P(Y) P(Y∣X)∗P(X)=P(X∣Y)∗P(Y)
在这个公式中,如果我们知道了其中三个因子,就能求出第四个。
通常来讲,两个条件概率 P ( X ) P(X) P(X) 和 P ( Y ) P(Y) P(Y) 是容易求的。
另外两个条件概率,一个是 X 条件下 Y 的概率,一个是 Y 条件下 X 的概率,常常一个比较容易得到,另一个比较难得到。
另外两个条件概率,一个是 X 条件下 Y 的概率,一个是 Y 条件下 X 的概率,常常一个比较容易得到,另一个比较难得到。
所以,我们常常从容易得到的条件概率,推导出难得到的概率,这就是著名的贝叶斯公式:
- P ( X ∣ Y ) = P ( Y ∣ X ) ∗ P ( X ) P ( Y ) P(X|Y)=P(Y|X)*\frac{P(X)}{P(Y)} P(X∣Y)=P(Y∣X)∗P(Y)P(X)
在这个公式中,我们假定 Y 条件下 X 的条件概率比较难得到,我们放在了等式的左边,而 X 条件下 Y 的条件概率容易得到,我们放在了等式的右边。
通过这种互换,可以把一个复杂的问题变成三个简单的问题。
这就是贝叶斯公式的本质。利用它,就解决了机器翻译的难题。
假定有一个英语句子 Y,想要翻译成中文句子 X,那怎么翻译呢?
很多人将它想象成语言学问题,其实这是一个数学问题,或者更准确地说,是一个概率的问题。
假定英语句子 Y 有很多种翻译方法 X1,X2,X3……XN,我们只要挑一种翻译 X,使得在已知英语句子 Y 的条件下,X 的概率 P ( X ∣ Y ) P(X|Y) P(X∣Y) 超过其它所有可能的句子的条件概率即可。
比如说,这句话有 10 种翻译方法,它们的条件概率分别是 0.1,0.5,0.01,0.02……你会发现第二种翻译方法 X2 的条件概率是 0.5,是最大的,因此就认为 Y 应该被翻译成X2,或者说 X = X2。
P ( X ∣ Y ) P(X|Y) P(X∣Y) 这个概率该怎么计算呢?
这个条件概率的计算,就要用到贝叶斯公式了。我们将它展开成:
- P ( X ∣ Y ) = P ( Y ∣ X ) ∗ P ( X ) P ( Y ) P(X|Y)=P(Y|X)*\frac{P(X)}{P(Y)} P(X∣Y)=P(Y∣X)∗P(Y)P(X)
P ( Y ∣ X ) P(Y|X) P(Y∣X) 是给定中文的句子,对应的英文句子的概率,它可以通过一个马尔可夫模型计算出来。
P ( X ) P(X) P(X) 是所谓的语言模型,它计算的是哪个句子在语法上更合理,这个也可以通过一个马尔可夫模型计算。
P ( Y ) P(Y) P(Y) 是一个常数,因为要翻译句子 Y,它是个确定的事情,我们把它的概率想象成 1 就可以了(其实不是1)。
于是原来的一个无法直接计算的条件概率,经过贝叶斯公式,变成了三个可以计算的概率。
这样,就能够判断给定一个句子,任何翻译出来的中文句子的可能性,而后我们找出最大的那个即可。
因为条件概率在数学上条件和结果可以互换,通过这种互换,把一个复杂的问题变成三个简单的问题,这就是贝叶斯公式的本质,利用它,就解决了机器翻译的难题。
具体来说,除了贝叶斯,机器翻译的方法还有许多,比如 集束搜索、维特比算法等,记录在《语音识别食用指南》。
最佳翻译
以下是 RNN结合集束搜索 实现的语言翻译,但 RNN 需要非常非常大的训练数据集和非常非常长的训练时间。
- 数据集:
本次我们只用它来实现日期格式的翻译。
- 1 March 2001
- 2001-03-01
自定义工具模块:
# nmt_utils.py
import numpy as np
from faker import Faker
import random
from tqdm import tqdm
from babel.dates import format_date
from tensorflow.keras.utils import to_categorical
import tensorflow.keras.backend as K
import matplotlib.pyplot as plt
fake = Faker()
Faker.seed(12345)
random.seed(12345)
FORMATS = ['short',
'medium',
'long',
'full',
'full',
'full',
'full',
'full',
'full',
'full',
'full',
'full',
'full',
'd MMM YYY',
'd MMMM YYY',
'dd MMM YYY',
'd MMM, YYY',
'd MMMM, YYY',
'dd, MMM YYY',
'd MM YY',
'd MMMM YYY',
'MMMM d YYY',
'MMMM d, YYY',
'dd.MM.YY']
LOCALES = ['en_US']
def load_date():
dt = fake.date_object()
try:
human_readable = format_date(dt, format=random.choice(FORMATS), locale='en_US')
human_readable = human_readable.lower()
human_readable = human_readable.replace(',','')
machine_readable = dt.isoformat()
except AttributeError as e:
return None, None, None
return human_readable, machine_readable, dt
def load_dataset(m):
human_vocab = set()
machine_vocab = set()
dataset = []
Tx = 30
for i in tqdm(range(m)):
h, m, _ = load_date()
if h is not None:
dataset.append((h, m))
human_vocab.update(tuple(h))
machine_vocab.update(tuple(m))
human = dict(zip(sorted(human_vocab) + ['' , '' ],
list(range(len(human_vocab) + 2))))
inv_machine = dict(enumerate(sorted(machine_vocab)))
machine = {
v:k for k,v in inv_machine.items()}
return dataset, human, machine, inv_machine
def preprocess_data(dataset, human_vocab, machine_vocab, Tx, Ty):
X, Y = zip(*dataset)
X = np.array([string_to_int(i, Tx, human_vocab) for i in X])
Y = [string_to_int(t, Ty, machine_vocab) for t in Y]
Xoh = np.array(list(map(lambda x: to_categorical(x, num_classes=len(human_vocab)), X)))
Yoh = np.array(list(map(lambda x: to_categorical(x, num_classes=len(machine_vocab)), Y)))
return X, np.array(Y), Xoh, Yoh
def string_to_int(string, length, vocab):
string = string.lower()
string = string.replace(',','')
if len(string) > length:
string = string[:length]
rep = list(map(lambda x: vocab.get(x, '' ), string))
if len(string) < length:
rep += [vocab['' ]] * (length - len(string))
return rep
def int_to_string(ints, inv_vocab):
l = [inv_vocab[i] for i in ints]
return l
EXAMPLES = ['3 May 1979', '5 Apr 09', '20th February 2016', 'Wed 10 Jul 2007']
def run_example(model, input_vocabulary, inv_output_vocabulary, text):
encoded = string_to_int(text, TIME_STEPS, input_vocabulary)
prediction = model.predict(np.array([encoded]))
prediction = np.argmax(prediction[0], axis=-1)
return int_to_string(prediction, inv_output_vocabulary)
def run_examples(model, input_vocabulary, inv_output_vocabulary, examples=EXAMPLES):
predicted = []
for example in examples:
predicted.append(''.join(run_example(model, input_vocabulary, inv_output_vocabulary, example)))
print('input:', example)
print('output:', predicted[-1])
return predicted
def softmax(x, axis=1):
ndim = K.ndim(x)
if ndim == 2:
return K.softmax(x)
elif ndim > 2:
e = K.exp(x - K.max(x, axis=axis, keepdims=True))
s = K.sum(e, axis=axis, keepdims=True)
return e / s
else:
raise ValueError('Cannot apply softmax to a tensor that is 1D')
def plot_attention_map(model, input_vocabulary, inv_output_vocabulary, text, n_s = 128, num = 6, Tx = 30, Ty = 10):
attention_map = np.zeros((10, 30))
Ty, Tx = attention_map.shape
s0 = np.zeros((1, n_s))
c0 = np.zeros((1, n_s))
layer = model.layers[num]
encoded = np.array(string_to_int(text, Tx, input_vocabulary)).reshape((1, 30))
encoded = np.array(list(map(lambda x: to_categorical(x, num_classes=len(input_vocabulary)), encoded)))
f = K.function(model.inputs, [layer.get_output_at(t) for t in range(Ty)])
r = f([encoded, s0, c0])
for t in range(Ty):
for t_prime in range(Tx):
attention_map[t][t_prime] = r[t][0,t_prime,0]
prediction = model.predict([encoded, s0, c0])
predicted_text = []
for i in range(len(prediction)):
predicted_text.append(int(np.argmax(prediction[i], axis=1)))
predicted_text = list(predicted_text)
predicted_text = int_to_string(predicted_text, inv_output_vocabulary)
text_ = list(text)
input_length = len(text)
output_length = Ty
plt.clf()
f = plt.figure(figsize=(8, 8.5))
ax = f.add_subplot(1, 1, 1)
i = ax.imshow(attention_map, interpolation='nearest', cmap='Blues')
cbaxes = f.add_axes([0.2, 0, 0.6, 0.03])
cbar = f.colorbar(i, cax=cbaxes, orientation='horizontal')
cbar.ax.set_xlabel('Alpha value (Probability output of the "softmax")', labelpad=2)
ax.set_yticks(range(output_length))
ax.set_yticklabels(predicted_text[:output_length])
ax.set_xticks(range(input_length))
ax.set_xticklabels(text_[:input_length], rotation=45)
ax.set_xlabel('Input Sequence')
ax.set_ylabel('Output Sequence')
ax.grid()
return attention_map
from tensorflow.keras.layers import Bidirectional, Concatenate, Permute, Dot, Input, LSTM, Multiply
from tensorflow.keras.layers import RepeatVector, Dense, Activation, Lambda
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.utils import to_categorical
from tensorflow.keras.models import load_model, Model
import tensorflow.keras.backend as K
import numpy as np
from faker import Faker
import random
from tqdm import tqdm
from babel.dates import format_date
from nmt_utils import *
import matplotlib.pyplot as plt
m = 10000
dataset, human_vocab, machine_vocab, inv_machine_vocab = load_dataset(m)
Tx = 30
Ty = 10
X, Y, Xoh, Yoh = preprocess_data(dataset, human_vocab, machine_vocab, Tx, Ty)
index = 0
repeator = RepeatVector(Tx)
concatenator = Concatenate(axis=-1)
densor = Dense(1, activation = "relu")
activator = Activation(softmax, name='attention_weights')
dotor = Dot(axes = 1)
def one_step_attention(a, s_prev):
s_prev = repeator(s_prev)
concat = concatenator([a, s_prev])
e = densor(concat)
alphas = activator(e)
context = dotor([alphas, a])
return context
n_a = 64
n_s = 128
post_activation_LSTM_cell = LSTM(n_s, return_state = True)
output_layer = Dense(len(machine_vocab), activation=softmax)
def model(Tx, Ty, n_a, n_s, human_vocab_size, machine_vocab_size):
X = Input(shape=(Tx, human_vocab_size))
s0 = Input(shape=(n_s,), name='s0')
c0 = Input(shape=(n_s,), name='c0')
s = s0
c = c0
outputs = []
a = Bidirectional(LSTM(n_a, return_sequences=True))(X)
for t in range(Ty):
context = one_step_attention(a, s)
s, _, c = post_activation_LSTM_cell(context, initial_state = [s, c])
out = output_layer(s)
outputs.append(out)
model = Model(inputs = [X, s0, c0], outputs = outputs)
return model
model = model(Tx, Ty, n_a, n_s, len(human_vocab), len(machine_vocab))
model.summary()
out = model.compile(optimizer=Adam(lr=0.005, beta_1=0.9, beta_2=0.999, decay=0.01), metrics=['accuracy'], loss='categorical_crossentropy')
s0 = np.zeros((m, n_s))
c0 = np.zeros((m, n_s))
outputs = list(Yoh.swapaxes(0,1))
model.fit([Xoh, s0, c0], outputs, epochs=10, batch_size=100)
s1 = np.zeros((1, n_s))
c1 = np.zeros((1, n_s))
EXAMPLES = ['March 3rd 2001', '1 March 2001']
for example in EXAMPLES:
source = string_to_int(example, Tx, human_vocab)
source = np.array(list(map(lambda x: to_categorical(x, num_classes=len(human_vocab)), source)))
source = np.expand_dims(source, axis=0)
prediction = model([source, s1, c1])
prediction = np.argmax(prediction, axis = -1)
output = [inv_machine_vocab[int(i)] for i in prediction]
print("source:", example)
print("output:", ''.join(output))
输出:
source: March 3rd 2001
output: 2001-03-03
source: 1 March 2001
output: 2001-03-01
会意会的机器翻译:你有算法,我有意会
其实机器翻译的水平已经不比英语四级水平的人差了,但也不够好。
机器翻译选择的是最有可能的句子,但这些句子可能并不地道,比如玩的开心,我们习惯说 Have a good day,但外国本地说的是 Have a good one,这样更加地道。
所以,我们能不能再机器翻译上再做一次改进,让机器翻译的句子更加地道!
这里就要介绍一个中英文回译法。
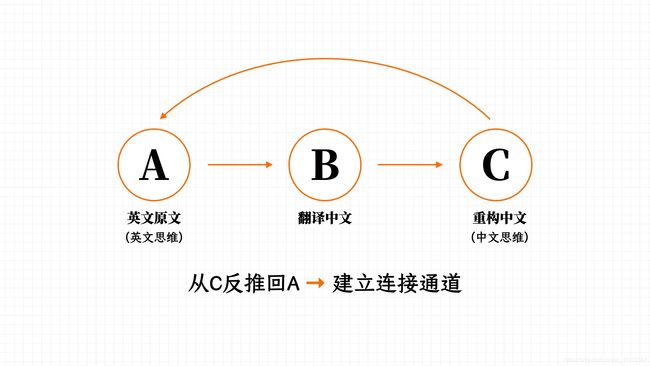
- A:用词典或者机器,翻译原文
- B:直译赶来的中文句子
- C:重构B,把直译改成意译,用中文习惯的说法
- C -> A:对比原文与意译,记录各种不同
- 扩展练习:把学到的知识迁移到其他场景中
- 五次复习法:巩固学习成果
e.g. 阅读的时候读到这么一段原文:
I 'm sorry about not getting back to you sooner.
I couldn’t access the internet from my laptop for some reason.
A:在微信里直译得到 B
-
很抱歉,没有早点回复你
-
因为某些原因,我无法从我的笔记本上上网
C:用中文习惯的说法,把直译改成意译
- 不好意思,这么晚才回复你
- 不知道怎么回事,我的笔记本连不上网
这一步假想同样的场景,你自己会如何表达即可。
此时,经过重构的C 与 原文翻译B,在表达顺序、结构上都有明显的区别。
C -> A:详细分析,得到这俩个句子之间的关联、替换
看着 C 的中文,而后想如果自己中文直译是什么样子?
你发现这些单词的用法也不是中文直译过来的:
- 这么晚:不是用 so late,而是 not…sooner
- 连上网:不是用 connect to,而是 access
- 不知道怎么回事:不是用 don’t konw why 或 for no reason,而是 for some reason
句子的主语也变了:
- 我的笔记本连不上网:主语不是笔记本,而是 I couldn’t access the internet from my laptop. 主语 I
迁移拓展:偷梁换柱
-
不好意思,这么晚才回复你。替换为 不好意思,拖了这么久才跟你说这件事。
-
I 'm sorry about not getting back to you sooner. 替换为 I 'm sorry about not telling you this sooner.
-
不知道怎么回事,我的笔记本连不上网。替换为 不知道怎么回事,我的手机上不了微信。
-
I couldn’t access the internet from my laptop for some reason. 替换为 I couldn’t access Wechat from my phone for some reason.