深度学习-常用损失函数详细介绍
个人微信公众号:AI研习图书馆,欢迎关注~
深度学习知识及资源分享,学习交流,共同进步~
1. 引言
损失函数是机器学习与深度学习里面的重要概念。从名字上就可以看出,损失函数(Loss Function)反应的是模型对数据的拟合程度。一般来说,损失函数越小,说明模型对数据的拟合也越好。同时我们还希望当损失函数比较大的时候,对应的梯度也会比较大,这样梯度下降的时候更新也会快一些。
损失函数是用来估量模型的预测值f(x)与真实值Y的不一致程度,它是一个非负值函数,通常用L(Y,f(x))来表示,损失函数越小,模型的鲁棒性越好。损失函数是经验风险函数的核心部分,也是结构风险函数的重要组成部分。模型的结构风险函数包括了经验风险项和正则项,通常可以表示成如下式子:
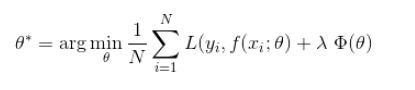
其中,前面的均值函数表示的是经验风险损失函数,L表示的是损失函数,后面的是正则化项。
本文主要收集和整理了深度学习常用的损失函数,给出函数表达形式,以及使用介绍和应用场景。
2. 常用损失函数
2.1 MSE损失函数
线性回归中,最常用的就是最小平方误差(MSE)了。MSE也相当简单:
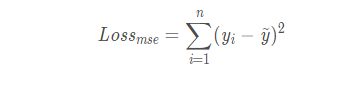
![]()
MSE的意义相当明确:如果预测值与真实值的欧式距离越大,损失函数越大。欧式距离越小,损失函数越小。同时,求导也是相当容易:
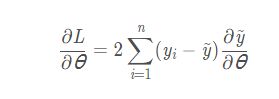
其中,θ是模型中待训练的参数。
一般来说,MSE是个很中庸的选择。用了MSE,一般不会有什么大毛病,但同时也不要指望他有特别优秀的表现。
注: Sigmoid一般不与MSE配合使用。在深度学习里,Sigmoid函数是常见的激活函数。特别注意的是,当使用Sigmoid做激活函数的时候,损失函数不能选择MSE。
因为Sigmoid的导数为f(x)(1−f(x))。假设当预测值为f(x)=1而真实值为0的时候,此时虽然(yi−y˜)很大,但是f(x)(1−f(x))太小接近0,收敛速度同样很慢。
2.2 CrossEntropy
交叉熵是从KL散度中引出,用于衡量两个分布之间差异的大小,其值总是大于等于0,两个分布越相似其值越接近于0。训练时的标签可以当成一种分布,实际输出堪称另一种分布,常与softmax层结合用于分类模型。
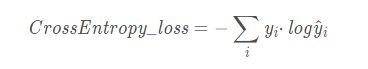
上面说到KL散度(KL divergence)用于衡量两个分布之间的大小的差异,这和MSE的度量方法是不一样的。下面讲到的log损失函数也是 divergence 的一种。
2.3 log损失函数
log损失通常用于逻辑回归,是二分类中常用的损失函数,若二分类中使用mse损失会造成最后优化函数为非凹函数,不利于训练。其中 x 表示输出该特征,y表示所属类别, p(1/x)表示输入特征 x 属于类别 1 的概率。
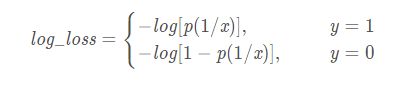
将上面分类书写的形式变换一下,便得到了BCE_loss,只不过是换了一个名字而已,效果与上式相同
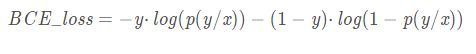
逻辑回归是分类网络中基础又重要的一个网络,GAN网络中的discriminator便是使用这种二分类网络。比较GAN网络的损失函数便会发现相似之处
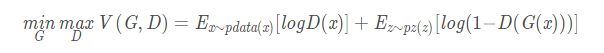
2.4 L1 Loss
l1loss即是L1范数下度量的距离,就是计算网络输出与标签之间对应元素绝对值然后求和。使用pytorch中的定义如下
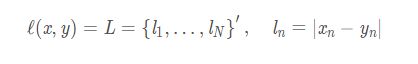
其中N表示batch的大小。
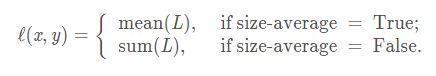
2.5 L2 Loss
2.6 Smooth L1
smooth L1是何凯明提出的优化的MSE损失,能有有效地优化梯度爆炸问题。这个例子表明我们可以根据我们网络的具体表现适当调节我们的损失函数从而解决特定的训练问题。
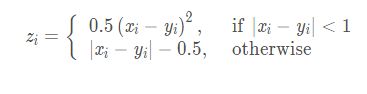
2.7 F-divergence
F-divergence是一个大的类,其中 F表示特定的函数,当函数 F不同便表示的不同的散度,上面提到的交叉熵便是 KL散度即 KL-divergence。其中KL使用的 F为 t⋅logtt·logtt⋅logt 。F-divergence损失函数如下:
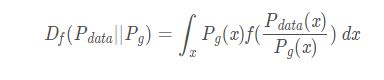
2.8 TV Loss
The total variation (TV) loss encourages spatial smoothness in the generated image.(总变差(TV)损失促进了生成的图像中的空间平滑性)
TV Loss Rubin等人在1990年左右观察到受噪声污染的图像的TV比无噪图像的总变分明显的大。 那么最小化TV理论上就可以最小化噪声。图片中相邻像素值的差异可以通过降低TV loss来一定程度上解决。比如降噪,对抗checkerboard等。
2.9 Softmax + Cross Entropy Loss(交叉熵)
加入交叉熵的原因是考虑到数值的稳定性。
损失函数:
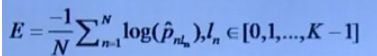
适应场景:单标签分类问题
该损失函数各个标签之间不独立
2.10 Sigmoid Cross Entropy Loss
损失函数: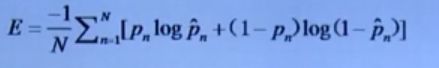
使用场景:预测目标概率分布,可用于多标签学习(如社会年龄估计)
注意:1.目标输出需要归一化到【0,1】;损失层的输出要有具体的意义;各个标签之间相互独立即每一维是独立的。
2.11 Center loss(softMax的一种改进)

2.12 Focal Loss
Basic Idea:用一个权重条件函数去降低易分样本对损失的贡献
解决方案:

适用场景:解决one-stage的目标检测中背景样本和前景样本的不平衡问题
2.13 Large-Margin Loss(softmax的改进)
Basic Idea:在SoftMax Loss中通过约束权重矩阵的夹角引入Margin正则
2.14 Contrastive Loss(Siamess Net)
损失函数: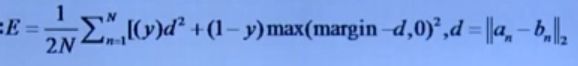
适用场景:人脸测度学习
2.15 Triplet Loss

适用场景:learning to rank ;人脸识别(FaceNet)
2.16 Moon Loss
Basic Idea:考虑多标签分类中训练和测试阶段样本分布的不平衡
对每个属性计算概率:
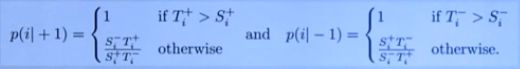
混合损失函数:
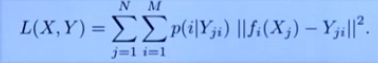
2.17 Euclidean Loss(欧氏损失)
损失函数;
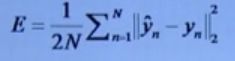
适用场景:实数值回归问题
注意:欧氏损失前可以增加Sigmoid操作进行归一化,相应的输出标签也归一化。
2.18 additive angular margin loss(Arcface)
损失函数:
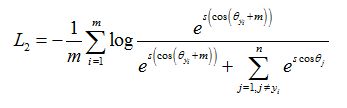
subject to:
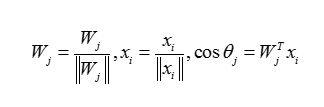
本文主要收集和整理了深度学习常用的损失函数,给出函数表达形式,以及使用介绍和应用场景,不足之处,还请见谅。
您的支持,是我不断创作的最大动力~
欢迎点赞,关注,留言交流~
深度学习,乐此不疲~