P2P应用
文章目录
- 前言
- 一、P2P原理
- 二、文件分发
-
- 1.客户机/服务器 vs P2P
- 2. BitTorrent协议
- 三、索引技术
-
- 1.集中式索引
- 2.洪泛式查询(Query flooding)
- 3.层次式覆盖网络
- 总结
前言
提示:以下是本篇文章正文内容
一、P2P原理
P2P技术属于覆盖层网络(Overlay Network)的范畴,是相对于客户机/服务器(C/S)模式来说的一种网络信息交换方式
P2P也叫「对等网络」(英语:peer-to-peer, 简称P2P),是一种在对等者(Peer)之间分配任务和工作负载的分布式应用架构,是对等计算模型在应用层形成的一种网络形式
在P2P网络环境中,彼此连接的多台计算机之间都处于对等的地位,各台计算机有相同的功能,无主从之分,每个节点既充当服务器,为其他节点提供服务,也能作为客户端,享用其他节点提供的服务
在C/S模式中,数据的分发采用专门的服务器,多个客户端都从此服务器获取数据
优点:数据的一致性容易控制,系统容易管理
缺点:因为服务器的个数只有一个(即便有多个也非常有限),系统容易出现单一失效点, 单一服务器面对众多的客户端,由于CPU能力、内存大小、网络带宽的限制,可同时服务的客户端非常有限,可扩展性差
P2P技术正是为了解决这些问题而提出来的一种对等网络结构, 在P2P网络中,每个节点既可以从其他节点得到服务,也可以向其他节点提供服务,庞大的终端资源被利用起来,解决了C/S模式中的弊端
特点:
1.没有服务器
2.任意端系统之间直接通信
3.节点阶段性接入Internet
4.节点可能更换IP地址

二、文件分发
P2P文件分发中,每个对等方能够向任何其他对等方重新分发他已经接收到的该文件的任何部分,从而从分发过程中协助该服务器,P2P文件分发协议BitTorrent
1.客户机/服务器 vs P2P
假设us: 服务器上传带宽,ui: 节点i的上传带宽,di: 节点i的下载带宽,文件大小:F
从一个服务器向N个节点分发一个文件需要多长时间?
C/S模式:

服务器串行地发送N个副本需要NF/us ,客户机i需要F/di时间下载
所以,分发N个F所需时间:

P2P模式

服务器必须发送一个副本,所需时间 F/us,客户机i需要F/di时间下载,总共需要下载NF比特,最快的可能上传速率: us + ui(i=1…n)
所以,分发N个F所需时间:

当客户端上传速率= u, F/u = 1小时, us = 10u, dmin ≥ us
两个模式下所化时间
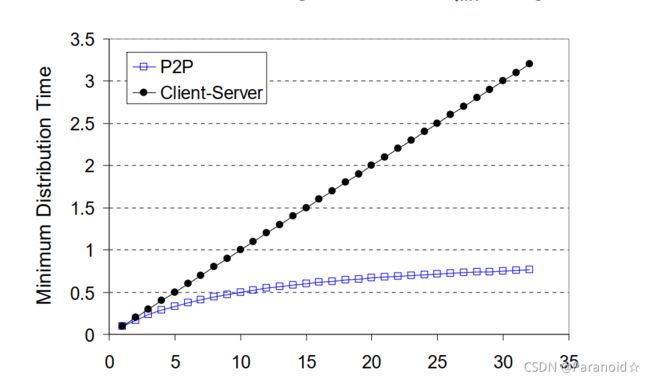
客户端-服务器体系下,分发时间随着对等方数量线性增加
P2P体系下,分发时间呈线性增长而趋向一个常数,若F表示分发的文件比特数量,u表示所有对等方具有的相同上传速率,则这个常数为F/u。
2. BitTorrent协议
BT(BitTorrent)是 P2P 的一种实现

当一个对等方加入某洪流时,它向追踪器注册自己,并获取节点列表,周期性地通知追踪器它仍在该洪流中
Tracker(追踪器):Tracker 是指运行于服务器上的一个服务程序,也称 Tracker服务器
tracker的作用: 跟踪参与torrent的节点,追踪到底有多少人同时在下载或上传同一个文件
客户端连上Tracker服务器,就会获得一个正在下载和上传的用户的信息列表(通常包括IP地址、端口、客户端ID等信息),根据这些信息,BT客户端会自动连上别的用户进行下载和上传
torrent(洪流): 交换同一个文件的文件块的节点组
chunk(文件块):一个洪流中的对等方下载等长度的文件块,典型长度256KB, 文件划分为256KB的chunk
邻近对等方:成功创建一个TCP连接的对等方
示例:

假设一个新的对等方Alice加入一个洪流,追踪器随机地从参与对等方的集合中选择对等方的一个子集并将对等方的IP地址发送给Alice,Alice拥有了一个IP地址的列表,Alice与列表上的所有对等方创建TCP连接,成为邻近对等方
给定任一时刻,不同的节点持有文件的不同chunk集合,节点(Alice)定期查询每个邻居所持有的chunk列表,对于节点缺失的chunk,,Alice(节点)发送请求获取(最稀缺的块,优先级最高请求)
节点同时也要 发送chunk: tit-for-tat,Alice向4个邻居发送chunk,正在向其发送Chunk要满足速率最快的4个,同时每10秒重新评估top 4
每30秒随机选择一个其他节点,Alie随机选择一名新的对换伴侣,向其发送chunk,新选择节点可能加入top 4
总之,大致过程:节点先加入torrent,若没有chunk,但是后面会逐渐积累,然后,向tracker注册以获得节点清单,与某些节点(“邻居”)建立连接,下载的同时,节点需要向其他节点上传chunk
注:节点可能加入或离开,一旦节点获得完整的文件,它可能(自私地)离开或(无私地)留下
三、索引技术
P2P系统的索引:信息到节点位置(IP地址+端口号)的映射
P2P应用中一个重要部分是信息索引,即信息到主机位置的映射,在这些应用程序中,对等方动态地更新和搜索索引
BitTorrent协议只是一个文件分发协议,并没有提供任何索引和搜索文件的功能为了能够在对等方区域中组织和搜索索引,所以需要搜索方法
1.集中式索引
提供了一个集中式索引,由一台大型服务器来提供索引服务,索引服务器从每个活动的对等方收集IP地址和可供共享的文件名称(内容),从而建立一个集中式的动态索引,将每个文件拷贝映射到一个IP地址集合

(1)节点加入时,通知中央服务器:IP地址和 内容
(2) Alice查找“Hey Jude”
(3) Alice从Bob处请求文件
内容和文件传输是分布式的,但是内容定位是高度集中式的,
这是一种P2P和CS混合体系结构,文件分发是P2P,搜索是C/S
缺点:
①、单点故障:索引服务器崩溃导致P2P应用崩溃
②、性能瓶颈和基础设施费用
③、侵犯版权,容易被关闭
2.洪泛式查询(Query flooding)
在查询洪泛中,索引全面地分布在对等方的区域中,每个对等方索引可供共享的文件而不索引其他文件
完全分布式架构,每个节点对它共享的文件进行索引,且只对它共享的文件进行索引
对等方形成了一个抽象的逻辑网络:覆盖网络,节点X与Y之间如果有TCP连接,
那么构成一个边,所有的活动节点和边构成覆盖网络
注:
1.边是虚拟链路,该链路可能有下面的许多物理链路组成
2.节点一般邻居数少于10个
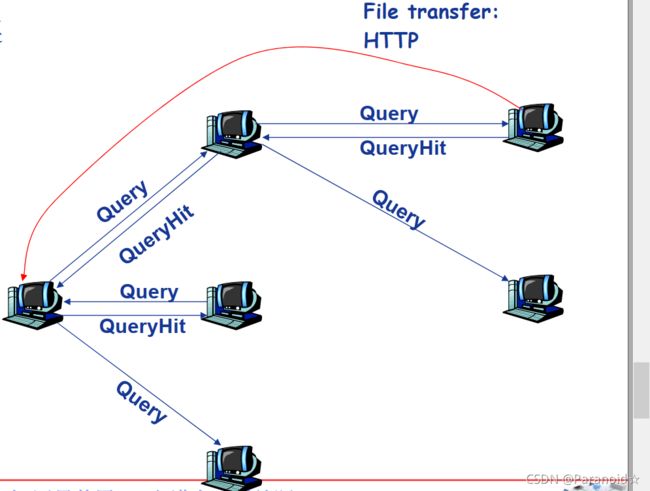
大致过程:
(1)查询消息通过已有的TCP连接发送
(2)节点转发查询消息
(3)如果查询命中,则利用反向路径发回查询节点
对等方通过已经存在的TCP连接,向覆盖网络中的相邻对等方发送查询报文,相邻对等方向他们的相邻对等方发送查询报文
当一个对等方接收到一条查询报文时,会检查该关键词是否与可供共享的任意文件相匹配,如果存在一个匹配,会回复一条“查询命中”报文,该报文包含了匹配文件名和文件长度。
该“查询命中”报文遵循“查询”报文的方向路径,因而使用预先存在的TCP连接。扩展性差,会产生大量流量,因此使用了范围受限查询洪泛
3.层次式覆盖网络
这是介于集中式索引和洪泛查询之间的方法

在层次覆盖设计中,不是所有对等方都是对等的,与因特网高速连接并具有高可用性的对等方被指派为超级节点
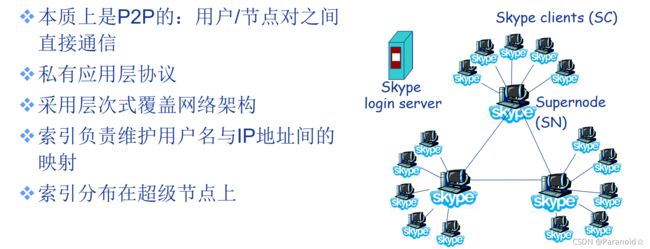
一个新的对等方与超级节点之一创建一个TCP连接,然后新对等方将其可供共享的文件告诉超级节点,而超级节点维护一个索引,包括其子对等方正在共享的所有文件的标识符、有关文件的元数据和保持这些文件的子对等方的IP地址,即每个超级节点成为一个小型的索引
超级节点之间相互建立TCP连接,从而形成一个覆盖网络,超级对等方可以向其相邻超级对等方转发查询,这里的查询是范围受限查询洪泛
超级节和踪子节之间采用集中式索引,超级节点之间采用洪泛式查询
Skype应用:
总结
提示:这里对文章进行总结: