OpenCV4机器学习算法原理与编程实战(附部分模型下载地址)
一直想找本书,能在机器学习复杂的算法原理和高效的编程实战之间达到合适的平衡:让感兴趣的同学拿到就有能用的代码,还有基本原理的介绍,因为了解原理才知道什么时候用什么算法最合适,以及如何调整参数。
一直没找到合适的,所以动手写了一本:p 拖拖拉拉花了三年多时间,幸运的是三年间技术一直在进步,也就有机会将最新的OpenCV4机器学习ML和深度学习DNN模块的精彩呈现在纸面,汇集了大量的算法原理与对应的示例程序,希望能对大家的学习有所帮助:)
最近有读者询问示例代码中某些文件的下载地址,为方便大家学习整理了一些模型和文件,在文末给出下载地址。
本文的思路是:
- 先介绍涉及的知识体系和主要特色,并给出这本书的目录结构;
- 再给出书中的三个案例,分别是DNN深度学习模型落地和SVM的在机器视觉中的应用;
- 最后是书中内容的截图展示。
目录
目录
内容介绍
全书目录
案例1:用C++ 和OpenCV 实现视频目标检测(YOLOv4)
1.实现思路
2.实现步骤
案例2:使用C++ 和OpenCV 实现场景文本检测识别(DB+CRNN)
1.实现思路
2.实现步骤
案例3:使用C++ 和OpenCV 实现手写数字识别(HOG+SVM)
应用提示
内容截图
书中部分模型与附件文件下载地址
分类算法模型
跟踪算法模型
分割算法的color.txt
检测算法的coco.names
本文分析算法的词典文件

内容介绍
机器学习关注的问题是:计算机程序如何随着经验积累自动提高性能。机器学习算法已成功应用于模式识别、通信、控制、金融、生物信息学、计算机视觉等众多领域。近年来,深度学习技术的进步,更是推动了计算机视觉领域的研究与行业应用的巨大变革。
目前介绍机器学习的书籍大致分为理论与实践两类,大多数应用类书籍使用Python或MATLAB语言编程实现。这本书的初衷是为读者拉近机器学习理论与算法C++编程实践之间的距离。OpenCV的机器学习与深度学习模块为我们在机器学习理论与编程实战之间架设了一座桥梁。读者通过阅读本书可在理解算法原理的基础上,通过大量应用与示例代码迅速提升基于C++语言的机器学习算法编程实践能力,书中的大量OpenCV函数用法、参数的介绍同样适用于Python接口调用。
本书以OpenCV4为工具,介绍的机器学习算法原理、代码实现与应用示例。第1章和第2章介绍了OpenCV4的安装配置、基本数据结构与图像处理操作;第3章讲解机器学习的基本概念;第4章从最简单的K均值和K近邻算法入手介绍聚类、分类与回归算法原理与应用;第5章至第7章介绍了最早的机器学习算法之一的决策树算法,及其改进算法——随机森林和Boosting集成学习算法;第8章介绍了应用广泛的支持向量机算法及应用,并涉及到一些基本的统计学习理论知识;第9章至第10章,重点介绍了人工神经网络与深度学习算法,并通过图像分类、对象检测、实例分割、目标跟踪与场景文本检测与识别等不同类型的大量应用介绍了GoogLeNet、YOLOv4、Mask R-CNN、GOTURN、DB、CRNN等深度学习算法模型的部署方法,其中不乏近年出现的高性能模型。
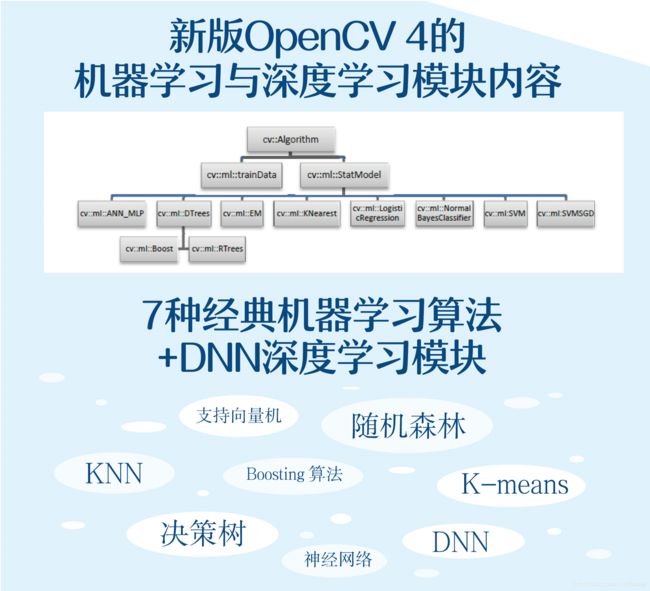

全书目录
第1章 概述
1.1 OpenCV简述
1.2 OpenCV的功能
1.3 OpenCV中的机器学习与深度神经网络模块
1.4 基本数据类型
1.4.1 数据类型概述
1.4.2 cv::Vec类
1.4.3 cv::Point类
1.4.4 cv::Scalar类
1.4.5 cv::Size类
1.4.6 cv::Rect类
1.4.7 cv::RotatedRect类
1.4.8 cv::Mat类
1.4.9 基本矩阵运算
参考文献
第2章 OpenCV在机器学习任务中的基本图像操作
2.1 基本图像操作
2.1.1 读取、显示和存储图像
2.1.2 颜色空间转换
2.1.3 图像的几何变换
2.1.4 直方图均衡化
2.1.5 标注文字和矩形框
2.2 基本视频操作
2.2.1 读取和播放视频文件
2.2.2 处理视频文件
2.2.3 存储视频文件
参考文献
第3章 机器学习的基本原理与OpenCV机器学习模块
3.1 机器学习的基本概念
3.1.1 机器学习的定义
3.1.2 机器学习的分类
3.2 机器学习的一般流程
3.2.1 机器学习流程
3.2.2 数据集
3.2.3 偏差与方差
3.2.4 评估分类器性能的方法
3.3 逻辑回归分类示例
3.3.1 图像数据与数据表示
3.3.2 逻辑回归模型
3.3.3 逻辑回归的损失函数
3.4 OpenCV支持的机器学习算法
3.4.1 机器学习模块的结构
3.4.2 机器学习模块中的算法
3.4.3 数据集准备
3.4.4 特征选择
参考文献
第4章 K-means和KNN
4.1 算法原理
4.1.1 K-means原理
4.1.2 KNN原理
4.2 OpenCV实现
4.2.1 K-means的实现
4.2.2 KNN的实现
4.3 应用示例
4.3.1 K-means聚类示例
4.3.2 KNN手写数字识别示例
4.3.3 应用提示
参考文献
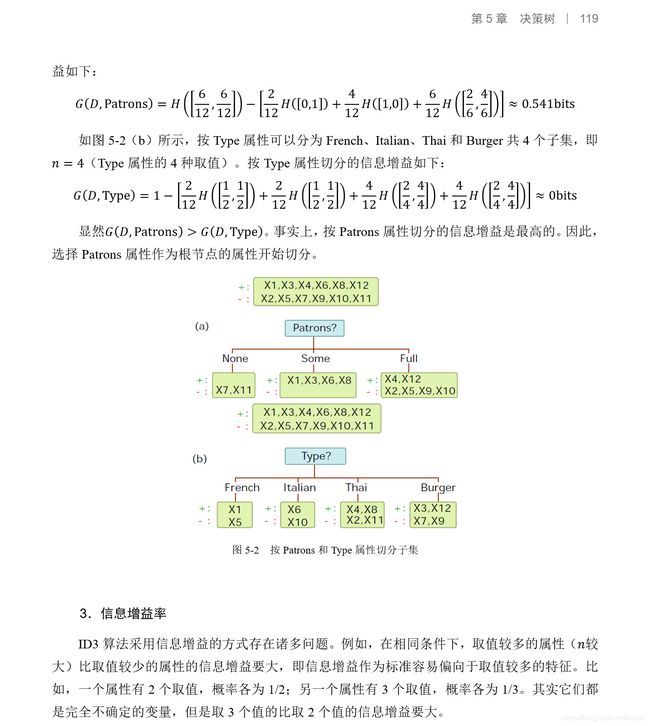
第5章 决策树
5.1 决策树原理
5.1.1 决策树的基本思想
5.1.2 决策树的表示方法
5.1.3 最佳切分属性的选择
5.1.4 停止标准
5.1.5 剪枝
5.2 OpenCV实现
5.2.1 创建决策树
5.2.2 训练决策树
5.2.3 使用决策树预测
5.3 应用示例
5.3.1 蘑菇可食性分类
5.3.2 预测波士顿房价
5.3.3 应用提示
参考文献
第6章 随机森林
6.1 随机森林原理
6.1.1 随机森林的基本思想
6.1.2 Bagging算法
6.2 OpenCV实现
6.2.1 OpenCV中的随机森林
6.2.2 创建随机森林
6.2.3 训练随机森林
6.2.4 使用随机森林预测
6.3 应用示例
6.3.1 蘑菇可食性分类
6.3.2 预测波士顿房价
6.3.3 应用提示
参考文献
第7章 Boosting算法
7.1 Boosting算法原理
7.1.1 Boosting算法的基本思想
7.1.2 Boosting算法
7.1.3 AdaBoost算法
7.2 OpenCV实现
7.2.1 创建AdaBoost模型
7.2.2 训练AdaBoost模型
7.2.3 使用AdaBoost模型预测
7.3 应用示例
7.3.1 蘑菇可食性分类
7.3.2 英文字母分类问题
7.3.3 应用提示
参考文献
第8章 支持向量机
8.1 支持向量机原理
8.1.1 统计学习理论概述
8.1.2 线性SVM算法基本原理
8.1.3 非线性SVM算法的基本原理
8.1.4 SVM回归算法的基本原理
8.1.5 SVM算法执行SRM准则的解释
8.2 OpenCV实现
8.2.1 OpenCV中的SVM算法
8.2.2 创建SVM模型
8.2.3 训练SVM模型
8.2.4 使用SVM模型预测
8.3 应用示例
8.3.1 使用HOG特征与SVM算法识别手写数字
8.3.2 应用提示
参考文献
第9章 神经网络
9.1 神经网络算法原理
9.1.1 神经网络的结构与表示
9.1.2 单隐层前馈神经网络
9.1.3 多隐层前馈神经网络
9.1.4 梯度下降法
9.1.5 反向传播算法
9.2 OpenCV实现
9.2.1 OpenCV中的MLP算法
9.2.2 创建MLP模型
9.2.3 训练MLP模型
9.2.4 使用MLP模型预测
9.3 应用示例
9.3.1 使用神经网络识别手写数字
9.3.2 应用提示
参考文献
第10章 深度神经网络
10.1 卷积神经网络的基本原理
10.1.1 卷积神经网络的结构
10.1.2 卷积层
10.1.3 池化
10.1.4 Softmax层
10.1.5 CNN特征学习的过程
10.1.6 CNN特征学习的原理
10.2 OpenCV的DNN模块
10.2.1 OpenCV支持的深度学习框架
10.2.2 支持的层类型
10.2.3 编译支持GPU加速的OpenCV
10.2.4 DNN模块的使用
10.3 应用示例
10.3.1 典型计算机视觉任务
10.3.2 使用GoogLeNet实现图像分类
10.3.3 使用YOLOv4实现目标检测
10.3.4 使用Mask R-CNN实现实例分割
10.3.5 使用GOTURN模型实现目标跟踪
10.3.6 使用DB算法实现场景文本检测
10.3.7 使用CRNN实现场景文本识别
10.3.8 应用提示
参考文献
案例1:用C++ 和OpenCV 实现视频目标检测(YOLOv4)
1.实现思路
读取视频流,载入模型,执行推理,找出所有目标及其位置,最后绘制检测结果。
2.实现步骤
读取摄像头视频流或本地视频文件:
cv::VideoCapture cap;
cap.open(0); //打开摄像头
//cap.open("TH1.mp4"); //读取视频文件
载入模型:
cv::dnn::Net net = cv::dnn::readNet(config, model, framework);
net.setPreferableTarget(cv::dnn::DNN_TARGET_CUDA);
执行推理:
net.forward(outs, outNames); //前向传播找出所有目标及其位置(部分):
for (size_t i = 0; i < outs.size(); ++i) {
data = (float*)outs[i].data;
for (int j = 0; j < outs[i].rows; ++j, data += outs[i].cols)
{
scores = outs[i].row(j).colRange(5, outs[i].cols);
cv::minMaxLoc(scores, 0, &confidence, 0, &classIdPoint);
绘制检测结果(部分):
void drawPred(
cv::Mat &frame,
vector &boxes,
vector &classIds,
vector &indices,
vector &classNamesVec)
案例2:使用C++ 和OpenCV 实现场景文本检测识别(DB+CRNN)
将检测模型的文本区域检测结果输入识别模型后,便可以对场景图像中的文字进行检测识别了。示例代码10-7是在OpenCV官方场景文字检测识别示例代码基础上修改而来的。
1.实现思路
读取图像,初始化参数,载入模型,载入词典,场景文本提取,提取后文本识别,检测结果后处理。
2.实现步骤
初始化参数(部分):
//[1]初始化参数
//DB文本检测模型
cv::String detModelPath =
"D:/models/TextRecognitionModel_google/DB_TD500_resnet50.onnx";
float binThresh = 0.3;
float polyThresh = 0.5;
double unclipRatio = 2.0;
uint maxCandidates = 200;
int height = 736;
int width = 736;
//CRNN文本识别模型
cv::String recModelPath =
"D:/models/TextRecognitionModel_google/crnn_cs_CN.onnx";
cv::String vocPath =
"D:/models/TextRecognitionModel_google/alphabet_3944.txt";
int imreadRGB = 1;
载入模型:
//[2]载入模型
cv::dnn::TextDetectionModel_DB detector(detModelPath);
detector.setBinaryThreshold(binThresh)
.setPolygonThreshold(polyThresh)
.setUnclipRatio(unclipRatio)
.setMaxCandidates(maxCandidates);
载入词典(部分):
//[3]载入词典
CV_Assert(!vocPath.empty());
std::ifstream vocFile;
vocFile.open(samples::findFile(vocPath));
CV_Assert(vocFile.is_open());
cv::String vocLine;
std::vector vocabulary;
while (std::getline(vocFile, vocLine)) {
vocabulary.push_back(vocLine);
}
模型推理(部分):
//[4]推理
cv::Mat frame = imread(samples::findFile(imgPath), imreadRGB);
CV_Assert(!frame.empty());
std::string recognitionResult = recognizer.recognize(frame);
cv::imshow("evaluate image", frame);
载入图像:
//[5]载入图像
cv::Mat frame = cv::imread("acmilan.jpg");
std::cout << frame.size << std::endl;
模型推理:
//[6]推理
std::vector< std::vector > detResults;
detector.detect(frame, detResults);
检测结果后处理(部分):
std::vector< std::vector > contours;
for (uint i = 0; i < detResults.size(); i++)
{
const auto& quadrangle = detResults[i];
CV_CheckEQ(quadrangle.size(), (size_t)4, "");
contours.emplace_back(quadrangle);
std::vector quadrangle_2f;
for (int j = 0; j < 4; j++)
quadrangle_2f.emplace_back(quadrangle[j]);
图10-59是示例代码10-7综合了DB文本检测与CRNN文本识别模型后的识别结果。图10-59中左上角的小图为文本区域仿射变换后的切片图像,将其作为CRNN识别模型的输入,识别结果自动显示在大图中文本区域的右侧。

案例3:使用C++ 和OpenCV 实现手写数字识别(HOG+SVM)
特征描述子是图像或图像块的某种表示,通过提取有用的信息并丢弃多余的信息来简化图像。在识别任务中,我们会使用某种特征描述子,先从原始图像中提取出特征,构成描述该图像的特征向量x^((i)),再使用分类算法对图像进行分类。在本例中,我们使用梯度直方图(Histogram of Oriented Gradients,HOG)特征描述子将灰度图像转换为特征向量。
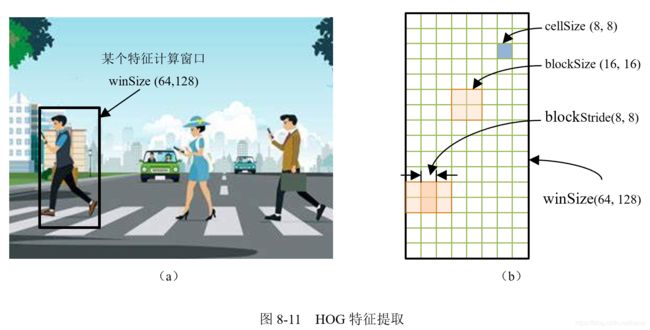
在了解了类的关键构造参数后,首先,创建HOGDescriptor类的一个实例hog,根据手写数字图像大小来初始化实例hog的参数:
HOGDescriptor hog(
Size(20, 20), //winSize
Size(10, 10), //blocksize
Size(5, 5), //blockStride
Size(10, 10), //cellSize
9, //nBins
1, //derivAper
-1, //winSigma
0, //histogramNormType
0.2, //L2HysThresh
1,//gammal correction
64,//nlevels=64
1);//Use signed gradients
然后,调用HOGDescriptor类的compute方法计算HOG特征,得到特征描述子descriptors:
vector descriptors;
hog.compute(img, descriptors);
接着,将特征描述子descriptors转换成OpenCV的Mat数据类型,并存入训练样本集:
vector trainDataVec
trainDataVec.push_back(Mat(descriptors).clone());
最后,使用convert_to_ml函数将vector
void convert_to_ml(const vector & train_samples, Mat& trainData)
{
//--Convert data
const int rows = (int)train_samples.size();
const int cols = (int)std::max(train_samples[0].cols,
train_samples[0].rows);
Mat tmp(1, cols, CV_32FC1);
trainData = Mat(rows, cols, CV_32FC1);
for (size_t i = 0; i < train_samples.size(); ++i)
{
CV_Assert(train_samples[i].cols == 1 || train_samples[i].rows == 1);
if (train_samples[i].cols == 1)
{
transpose(train_samples[i], tmp);
tmp.copyTo(trainData.row((int)i));
}
else if (train_samples[i].rows == 1)
{
train_samples[i].copyTo(trainData.row((int)i));
}
}
}
前文介绍了如何计算每幅图像的HOG特征,并将其组成训练样本。下面编写函数generateDataSet,完成整个数据集的制作:
/** @生成模型的训练集与测试集
参数1:img,输入,灰度图像,由固定尺寸的小图像拼接成的大图,不同类别的小图像依次排列
参数2:trainDataVec,输出,训练集维度为训练样本数×单个样本特征数,CV_32F类型
参数3:testDataVec,输出,测试集维度为测试样本数×单个样本特征数,CV_32F类型
参数4:trainLabel,输出,训练集标签维度为训练样本数×1,int型向量
参数4:testLabel ,输出,测试集标签维度为测试样本数×1,int型向量
参数5:train_rows,输入,用于训练的样本所占的行数,默认4行用于训练,1行用于测试
参数6:HOG_flag,输入。true:提取HOG特征描述子作为特征向量。false:直接使用图像原始像素
*/
void generateDataSet(Mat &img, vector &trainDataVec, vector &testDataVec, vector &trainLabel, vector &testLabel, int train_rows, bool HOG_flag)
{
//初始化图像中切片图像与其他参数
int width_slice = 20; //单个数字切片图像的宽度
int height_slice = 20; //单个数字切片图像的高度
int row_sample = 100; //每行样本数
int col_sample = 50; //每列样本数
int row_single_number = 5; //单个数字占5行
int test_rows = row_single_number - train_rows; //测试样本所占行数
Mat trainMat(train_rows * 20 * 10, img.cols, CV_8UC1);
//存放所有训练图片
trainMat = Scalar::all(0);
Mat testMat(test_rows * 20 * 10, img.cols, CV_8UC1);
//存放所有测试图片
testMat = Scalar::all(0);
//生成测试大图和训练大图
for (int i = 1; i <= 10; i++)
{
Mat tempTrainMat = img.rowRange((i - 1) * row_single_number * 20, (i *
row_single_number - 1) * 20).clone();
Mat tempTestMat = img.rowRange((i * row_single_number - 1) * 20, (i *
row_single_number) * 20).clone();
//train
cv::Mat roi_train = trainMat(Rect(0, (i - 1) * train_rows * 20,
tempTrainMat.cols, tempTrainMat.rows));
Mat mask_train(roi_train.rows, roi_train.cols, roi_train.depth(),
Scalar(1));
//test
cv::Mat roi_test = testMat(Rect(0, (i - 1) * test_rows * 20,
tempTestMat.cols, tempTestMat.rows));
Mat mask_test(roi_test.rows, roi_test.cols, roi_test.depth(),
Scalar(1));
//把提取的训练测试行分别复制到训练图片与测试图片中
tempTrainMat.copyTo(roi_train, mask_train);
tempTestMat.copyTo(roi_test, mask_test);
}
表8-3为不同的特征与SVM核函数在手写数字数据集上的测试结果。表中“特征”栏“原图”指的是将20像素×20像素的原始图像直接拉成400×1的向量作为特征向量;“HOG”为算法从每幅图中抽取的81×1维的HOG特征向量。从测试结果可以看出,使用偏斜校正后的图像训练的分类器,准确率要好于使用原始图像的分类器。当然,如果使用偏斜校正后的图像来训练分类器,那么测试样本也需要经偏斜校正后再送入分类器进行分类。

应用提示
SVM的类型非常多。针对线性可分数据,可以使用软间隔SVM;针对非线性可分数据,可以使用引入核技巧的非线性SVM;针对回归任务可以使用SVR。在具体使用时有两个重要的问题,一是模型选择问题(即参数搜索),二是特征提取问题。
例如,当使用高斯核函数的C-SVM时,主要参数为C和γ,那么如何选择呢?最好的方法是使用“网格搜索”寻找不同的参数组合,之后进行交叉验证,找出使交叉验证精度最高的参数组合(C,γ)。OpenCV提供的trainAuto函数可以测试不同的参数网格,通过k折叠交叉验证自动完成参数寻优。
此外,可以通过控制SV的数量对模型进行选择。下面用留一交叉验证(Leave-One-Out Cross Validation,LOOCV)的方法进行简要说明。LOOCV是指每次只留1个样本作为交叉验证集,剩下的m-1个样本作为训练集。由此可见,LOOCV本质是m折交叉验证(样本集被平分为m份,每份1个样本)。用E_loocv表示留一交叉验证误差,它比k折叠(k ----------------------------------------------------------------------------------------------------------- 更多内容后续逐步更新,大家也可使用原书(含全套源码)学习参考。 决策树算法的原理(部分) 决策树算法的原理(部分) 决策树算法的原理(部分) OpenCV对算法的实现 应用示例 示例源码及分析 应用提示 链接:https://pan.baidu.com/s/1rlapvOnKBCR9CruaGW0K0Q 链接:https://pan.baidu.com/s/1Os5a_ZiZ_RLnMvpbjEeIlA 链接:https://pan.baidu.com/s/1wP0X67BFn68M46gJeUFlGw 链接:https://pan.baidu.com/s/1MU6Rje8oeFbLeTfdpf82Ng 链接:https://pan.baidu.com/s/1UTtuGKIQu3n0Kjzb7CR7Ww PS.其他模型和代码在出版社提供的资料中可全套下载。 本文更新链接:https://blog.csdn.net/iracer/article/details/116051674 转载请注明出处。内容截图






书中部分模型与附件文件下载地址
分类算法模型
提取码:5etb
跟踪算法模型
提取码:vqnx
分割算法的color.txt
提取码:b05v
检测算法的coco.names
提取码:ued4
本文分析算法的词典文件
提取码:kqbf