机器学习——多元线性回归分析(multiple regression)及应用
1、多元回归分析与简单线性回归区别
多个自变量x
2、多元回归模型
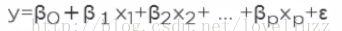 ,其中,
,其中, 是参数,
是参数,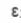 是误差值
是误差值
3、多元回归方程

4、估计多元回归方程
 ,一个样本被用来计算的点估计
,一个样本被用来计算的点估计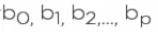
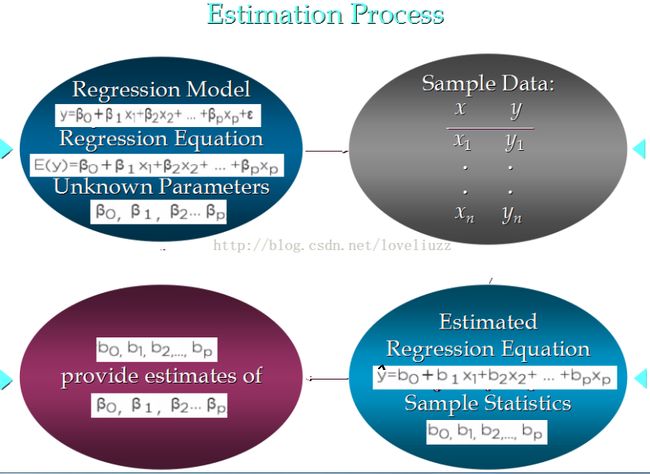
5、估计流程(与简单线性回归类似)
6、估计方法
使sum of squares最小,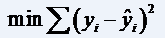 ,运算与简单线性回归类似,涉及线性代数和矩阵代数的运算
,运算与简单线性回归类似,涉及线性代数和矩阵代数的运算
7、举例
一家快递公司送货,X1:运输里程;X2:运输次数;Y:总运输时间
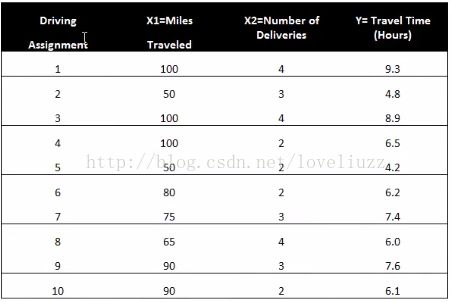


8、描述参数含义
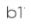 :平均每多送1英里,运输时间延长0.0611小时
:平均每多送1英里,运输时间延长0.0611小时
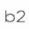 :平均每多一次运输,运输时间延长0.923小时
:平均每多一次运输,运输时间延长0.923小时
9、预测
问题:如果一个运输任务是跑102英里,运输6次,预计时间是多长?
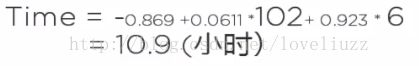
10、如果自变量里面有分类型变量(categorical data),如何处理?

11、关于误差的分布

12、对第一个表格的数据,快递公司运输问题用Python进行代码实现
将运输里程、运输次数、总运输时间按列的形式保存到文件TransportData.csv文件中,如下图:

Python3.5实现代码为:
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# Author:ZhengzhengLiu
from numpy import genfromtxt #genfromtxt函数创建数组表格数据
import numpy as np
from sklearn import datasets,linear_model
#读取数据,r后边内容当做完整的字符串,忽略里面的特殊字符
dataPath = r'F:\PythonCode\Regresssion\TransportData.csv'
transportData = genfromtxt(dataPath,delimiter=',') #将路径下的文本文件导入并转化成numpy数组格式
print("transportData:",transportData)
X = transportData[:,:-1] #取所有行和除了最后一列的所有列作为特征向量
Y = transportData[:,-1] #取所有行和最后一列作为回归的值
print("X:",X)
print("Y:",Y)
#建立回归模型
regr = linear_model.LinearRegression()
regr.fit(X,Y)
print("coefficients:",regr.coef_) #b1,...,bp(与x相结合的各个参数)
print("intercept:",regr.intercept_) #b0(截面)
x_pred = [102,6]
y_pred = regr.predict(x_pred) #预测
print("y_pred:",y_pred)
transportData: [[ 100. 4. 9.3]
[ 50. 3. 4.8]
[ 100. 4. 8.9]
[ 100. 2. 6.5]
[ 50. 2. 4.2]
[ 80. 2. 6.2]
[ 75. 3. 7.4]
[ 65. 4. 6. ]
[ 90. 3. 7.6]
[ 90. 2. 6.4]]
X: [[ 100. 4.]
[ 50. 3.]
[ 100. 4.]
[ 100. 2.]
[ 50. 2.]
[ 80. 2.]
[ 75. 3.]
[ 65. 4.]
[ 90. 3.]
[ 90. 2.]]
Y: [ 9.3 4.8 8.9 6.5 4.2 6.2 7.4 6. 7.6 6.4]
coefficients: [ 0.06231881 0.88000431]
intercept: -0.807517256255
y_pred: [ 10.82902718]将分类变量转化成0,1,2等数字来表示。0:小车,1:SUV,2:卡车,转码格式为:用一个3维数表示,所用车辆类型为1,其余车型为0.
将运输里程、运输次数、运输车型、总运输时间按列的形式保存到文件TransportData2.csv文件中,转码格式如下图:
转码格式:(转化过程,不是最终存储内容)
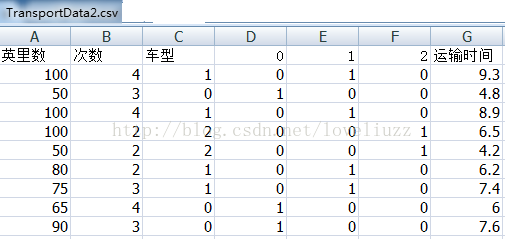
将转码后的数据保存在TransportData2.csv文件中:

对前面的代码稍作修改即可:
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# Author:ZhengzhengLiu
#多元线性回归处理自变量中有分类变量
from numpy import genfromtxt #genfromtxt函数创建数组表格数据
import numpy as np
from sklearn import datasets,linear_model
#读取数据,r后边内容当做完整的字符串,忽略里面的特殊字符
dataPath = r'F:\PythonCode\Regresssion\TransportData2.csv'
transportData = genfromtxt(dataPath,delimiter=',') #将路径下的文本文件导入并转化成numpy数组格式
print("transportData:",transportData)
X = transportData[:,:-1] #取所有行和除了最后一列的所有列作为特征向量
Y = transportData[:,-1] #取所有行和最后一列作为回归的值
print("X:",X)
print("Y:",Y)
#建立回归模型
regr = linear_model.LinearRegression()
regr.fit(X,Y)
print("coefficients:",regr.coef_) #b1,...,b5(与x相结合的各个参数)
print("intercept:",regr.intercept_) #b0(截面)
x_pred = [102,6,0,0,1]
y_pred = regr.predict(x_pred) #预测
print("y_pred:",y_pred)
transportData: [[ 100. 4. 0. 1. 0. 9.3]
[ 50. 3. 1. 0. 0. 4.8]
[ 100. 4. 0. 1. 0. 8.9]
[ 100. 2. 0. 0. 1. 6.5]
[ 50. 2. 0. 0. 1. 4.2]
[ 80. 2. 0. 1. 0. 6.2]
[ 75. 3. 0. 1. 0. 7.4]
[ 65. 4. 1. 0. 0. 6. ]
[ 90. 3. 1. 0. 0. 7.6]
[ 90. 2. 1. 0. 0. 6.4]]
X: [[ 100. 4. 0. 1. 0.]
[ 50. 3. 1. 0. 0.]
[ 100. 4. 0. 1. 0.]
[ 100. 2. 0. 0. 1.]
[ 50. 2. 0. 0. 1.]
[ 80. 2. 0. 1. 0.]
[ 75. 3. 0. 1. 0.]
[ 65. 4. 1. 0. 0.]
[ 90. 3. 1. 0. 0.]
[ 90. 2. 1. 0. 0.]]
Y: [ 9.3 4.8 8.9 6.5 4.2 6.2 7.4 6. 7.6 6.4]
coefficients: [ 0.05545649 0.69545199 -0.1734737 0.57081602 -0.39734232]
intercept: 0.197201946472
y_pred: [ 9.62913307]