Ubuntu18.04下YOLOv3详解——搭建、训练、测试、评估
Ubuntu18.04下YOLOv3详解——搭建、训练、测试、评估
-
- 基本配置
- 环境搭建
- 模型训练
- 模型测试
- 模型评估
- 问题总结
- Reference
YOLOv3是目标检测任务中最常用的算法之一,本文具体讲述了YOLOv3搭建——训练——测试——评估的几个步骤,顺便记录了遇到的几个坑。我用的是Ubuntu版本Darknet框架的YOLOv3,参考作者的步骤( https://pjreddie.com/darknet/yolo/)来一步步完成的,后面为了项目部署会继续学Tensorflow框架的。

基本配置
Ubuntu18.04
cuda9.0
cudnn7.3.1
opencv3.2.0
环境搭建
cuda和cudnn的配置相关具体的博文有很多,不需要过多赘述,推荐这篇博客写的比较详细(https://blog.csdn.net/weixin_41851439/article/details/88712465),一定注意Ubuntu系统与cuda、cudnn三者之间的对应关系,装cuda和cudnn是因为下面调用GPU进行训练和测试,用CPU和GPU的速度天差地别,如果显存太差建议用CPU慢慢跑。
主目录下
git clone https://github.com/pjreddie/darknet
cd darknet
make
下载预训练权重,若下载太慢则复制链接(https://pjreddie.com/media/files/yolov3.weights)到浏览器下载。
wget https://pjreddie.com/media/files/yolov3.weights
下面测试一下!
./darknet detect cfg/yolov3.cfg yolov3.weights data/dog.jpg
将会见到以下输出
layer filters size input output
0 conv 32 3 x 3 / 1 416 x 416 x 3 -> 416 x 416 x 32 0.299 BFLOPs
1 conv 64 3 x 3 / 2 416 x 416 x 32 -> 208 x 208 x 64 1.595 BFLOPs
.......
105 conv 255 1 x 1 / 1 52 x 52 x 256 -> 52 x 52 x 255 0.353 BFLOPs
106 detection
truth_thresh: Using default '1.000000'
Loading weights from yolov3.weights...Done!
data/dog.jpg: Predicted in 0.029329 seconds.
dog: 99%
truck: 93%
bicycle: 99%
因为还没有调用GPU,用CPU进行测试的时候会几秒到十几秒的时间,下面调用一下GPU,减少训练测试时间,修改Makefile文件
终端输入命令
gedit Makefile
修改如下
GPU=1
CUDNN=1
OPENCV=1 # 如果安装了opencv则改为1
OPENMP=0
DEBUG=0
...
NVCC=/usr/local/cuda-9.0/bin/nvcc # 原为 NVCC = nvcc,cuda后面的紧跟自己的cuda版本,如cuda-9.0,cuda-10.0等
修改完后终端重新make后重新测试
如果见到下面的情况,不要慌,有两种可能:
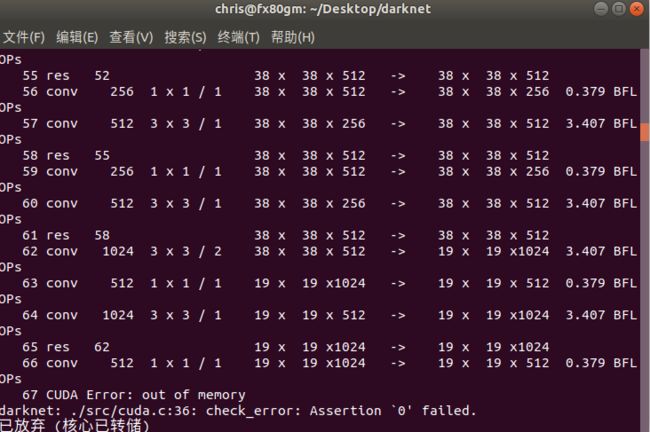 1.显存不够,深度学习对显卡的显存要求较高,一般至少需要4G的显存,检查一下自己显卡对应的显存,如果显存不够建议换个好一点的显卡或者租服务器,深度学习最不能省钱的就是显卡了!!!
1.显存不够,深度学习对显卡的显存要求较高,一般至少需要4G的显存,检查一下自己显卡对应的显存,如果显存不够建议换个好一点的显卡或者租服务器,深度学习最不能省钱的就是显卡了!!!
2.cfg文件没有修改,cfg文件夹下的yolov3.cfg文件做以下修改,如果是训练状态,取消Training下面batch和subdivisions的注释,把Testing的batch和subdivisions注释掉
# Testing
batch=1
subdivisions=1
# Training
# batch=64
# subdivisions=16
...
模型训练
接下来将会以自己的数据集作为例子进行训练,文件目录如下所示,图片存储于JPEGImages文件夹下,标注的xml文件存储与
VOCdevkit
——VOC2008
————Annotations
————ImageSets
——————Main
————JPEGImages
在voc2008文件夹下建立voc_2008.py文件并运行,voc_2008.py的作用是在ImageSets 下的main文件夹产生随机分割后的训练集测试集路径文件,代码如下:
import os
import random
trainval_percent = 0.1
train_percent = 0.9
xmlfilepath = 'Annotations'
txtsavepath = 'ImageSets/Main'
total_xml = os.listdir(xmlfilepath)
num = len(total_xml)
list = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
trainval = random.sample(list, tv)
train = random.sample(trainval, tr)
ftrainval = open('ImageSets/Main/trainval.txt', 'w')
ftest = open('ImageSets/Main/test.txt', 'w')
ftrain = open('ImageSets/Main/train.txt', 'w')
fval = open('ImageSets/Main/val.txt', 'w')
for i in list:
name = total_xml[i][:-4] + '\n'
if i in trainval:
ftrainval.write(name)
if i in train:
ftest.write(name)
else:
fval.write(name)
else:
ftrain.write(name)
ftrainval.close()
ftrain.close()
fval.close()
ftest.close()
随后在darknet主目录下建立voc_label.py文件并运行,voc_label.py的作用是将所有标注的xml文件转化成txt文件,因为YOLO支持读取的数据只是txt格式,代码如下:
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
sets=[('2008', 'train'), ('2008', 'val'), ('2008', 'test')]
classes = ["knife"]
def convert(size, box):
dw = 1./(size[0])
dh = 1./(size[1])
x = (box[0] + box[1])/2.0 - 1
y = (box[2] + box[3])/2.0 - 1
w = box[1] - box[0]
h = box[3] - box[2]
x = x*dw
w = w*dw
y = y*dh
h = h*dh
return (x,y,w,h)
def convert_annotation(year, image_id):
in_file = open('VOCdevkit/VOC%s/Annotations/%s.xml'%(year, image_id))
out_file = open('VOCdevkit/VOC%s/labels/%s.txt'%(year, image_id), 'w')
tree=ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult)==1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text), float(xmlbox.find('ymax').text))
bb = convert((w,h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
wd = getcwd()
for year, image_set in sets:
if not os.path.exists('VOCdevkit/VOC%s/labels/'%(year)):
os.makedirs('VOCdevkit/VOC%s/labels/'%(year))
image_ids = open('VOCdevkit/VOC%s/ImageSets/Main/%s.txt'%(year, image_set)).read().strip().split()
list_file = open('%s_%s.txt'%(year, image_set), 'w')
for image_id in image_ids:
list_file.write('%s/VOCdevkit/VOC%s/JPEGImages/%s.jpg\n'%(wd, year, image_id))
convert_annotation(year, image_id)
list_file.close()
这样训练集便准备好了!现在的目录如下所示:
VOCdevkit
——VOC2008
————Annotations
————ImageSets
——————Main
————————train.txt
————————trainval.txt
————————test.txt
————————val.txt
————JPEGImages
————labels
————voc_2008.py
训练文件是train.txt,测试文件是test.txt,直接生成的train.txt文件中只有图片的名称,而读取的train.txt中应该包含图片的路径信息,这里我采用了绝对路径,绝对路径的批量处理可以采用Excel或者Python脚本来完成,我用的是Excel批量添加路径信息。
还有需要修改的是voc.data和voc.names文件,我的这两个文件是放在Darknet主目录下面的,voc.data中包含数据集的类别数量、训练文件和测试文件、种类的名称路径和保存权重的路径,由于我就一种刀的种类,所以classes= 1,names为knife
classes= 1
train = VOCdevkit/VOC2008/ImageSets/Main/train.txt
valid = VOCdevkit/VOC2008/ImageSets/Main/test.txt
names = voc.names
backup = backup
knife
最后需要修改的就是修改cfg/yolov3.cfg,这个是最重要的配置文件,前面已经提到过,batch看显存具体调节,但是需16倍数,每batch个样本更新一次参数,subdivisions是8的倍数,需要改的地方我都进行了注释,filters和classes在cfg中有三处需要修改,random看显存调节。
# Testing
# batch=1
# subdivisions=1
# Training
batch=64
subdivisions=16
width=416 #原本为608,看情况具体调节
height=416
...
...
[convolutional]
size=1
stride=1
pad=1
filters=18 #计算公式为3*(classes+5),比如我只有一类,那filters算出来为18
activation=linear
[yolo]
mask = 6,7,8
anchors = 10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
classes=1 #数据集的类别数量
num=9
jitter=.3
ignore_thresh = .5
truth_thresh = 1
random=1 #随机使用不同尺寸的图片进行训练,具体看自己设备配置调节,显存不够就关闭多尺度,把1改成0
其他具体的cfg文件中的参数讲解可参考(https://blog.csdn.net/sinat_37196107/article/details/78759086)和(https://blog.csdn.net/la_fe_/article/details/81623869)
最后开始训练了!
首先下载预训练模型
wget https://pjreddie.com/media/files/darknet53.conv.74
终端运行命令,以下是训练模型的几条命令
./darknet detector train voc.data cfg/yolov3.cfg darknet53.conv.74
如果想使用多块GPU
./darknet detector train voc.data cfg/yolov3.cfg darknet53.conv.74 -gpus 0,1,2,3
保存log日志文件,log文件用来绘画loss、iou等曲线
./darknet detector train voc.data cfg/yolov3.cfg darknet53.conv.74 2>&1 | tee log/train_yolov3.log
如果训练过程中nan出现的比较多,需要可能是因为训练集中小目标比较多,这种情况不需要担心,只要不全是nan就可以,主要评价标准还是要看模型的测试结果,先训练一万batches再拿出来检测一下效果。
如果想继续之前的训练,我们的权重保存在backup文件下下面,终端运行命令
./darknet detector train voc.data cfg/yolov3.cfg backup/yolov3.backup
训练效果图

模型测试
将cfg文件中的# batch和subdivisions修改掉
测试命令,
./darknet detector test voc.data cfg/yolov3.cfg backup/yolov3.backup <JPEGImage_path>
多测试几张,来看看测试效果



 这是随机预测的几张图片,但是在实际当中需要批量的预测,一张一张的测试很累,成百上千数量图片的输出才是有效的选择。
这是随机预测的几张图片,但是在实际当中需要批量的预测,一张一张的测试很累,成百上千数量图片的输出才是有效的选择。
Step1:用下面代码替换detector.c文件(example文件夹下)的void test_detector函数(注意有3处要改成自己的路径)
void test_detector(char *datacfg, char *cfgfile, char *weightfile, char *filename, float thresh, float hier_thresh, char *outfile, int fullscreen)
{
list *options = read_data_cfg(datacfg);
char *name_list = option_find_str(options, "names", "data/names.list");
char **names = get_labels(name_list);
image **alphabet = load_alphabet();
network *net = load_network(cfgfile, weightfile, 0);
set_batch_network(net, 1);
srand(2222222);
double time;
char buff[256];
char *input = buff;
float nms=.45;
int i=0;
while(1){
if(filename){
strncpy(input, filename, 256);
image im = load_image_color(input,0,0);
image sized = letterbox_image(im, net->w, net->h);
//image sized = resize_image(im, net->w, net->h);
//image sized2 = resize_max(im, net->w);
//image sized = crop_image(sized2, -((net->w - sized2.w)/2), -((net->h - sized2.h)/2), net->w, net->h);
//resize_network(net, sized.w, sized.h);
layer l = net->layers[net->n-1];
float *X = sized.data;
time=what_time_is_it_now();
network_predict(net, X);
printf("%s: Predicted in %f seconds.\n", input, what_time_is_it_now()-time);
int nboxes = 0;
detection *dets = get_network_boxes(net, im.w, im.h, thresh, hier_thresh, 0, 1, &nboxes);
//printf("%d\n", nboxes);
//if (nms) do_nms_obj(boxes, probs, l.w*l.h*l.n, l.classes, nms);
if (nms) do_nms_sort(dets, nboxes, l.classes, nms);
draw_detections(im, dets, nboxes, thresh, names, alphabet, l.classes);
free_detections(dets, nboxes);
if(outfile)
{
save_image(im, outfile);
}
else{
save_image(im, "predictions");
#ifdef OPENCV
cvNamedWindow("predictions", CV_WINDOW_NORMAL);
if(fullscreen){
cvSetWindowProperty("predictions", CV_WND_PROP_FULLSCREEN, CV_WINDOW_FULLSCREEN);
}
show_image(im, "predictions");
cvWaitKey(0);
cvDestroyAllWindows();
#endif
}
free_image(im);
free_image(sized);
if (filename) break;
}
else {
printf("Enter Image Path: ");
fflush(stdout);
input = fgets(input, 256, stdin);
if(!input) return;
strtok(input, "\n");
list *plist = get_paths(input);
char **paths = (char **)list_to_array(plist);
printf("Start Testing!\n");
int m = plist->size;
if(access("/home/FENGsl/darknet/data/out",0)==-1)//"/home/FENGsl/darknet/data"修改成自己的路径
{
if (mkdir("/home/FENGsl/darknet/data/out",0777))//"/home/FENGsl/darknet/data"修改成自己的路径
{
printf("creat file bag failed!!!");
}
}
for(i = 0; i < m; ++i){
char *path = paths[i];
image im = load_image_color(path,0,0);
image sized = letterbox_image(im, net->w, net->h);
//image sized = resize_image(im, net->w, net->h);
//image sized2 = resize_max(im, net->w);
//image sized = crop_image(sized2, -((net->w - sized2.w)/2), -((net->h - sized2.h)/2), net->w, net->h);
//resize_network(net, sized.w, sized.h);
layer l = net->layers[net->n-1];
float *X = sized.data;
time=what_time_is_it_now();
network_predict(net, X);
printf("Try Very Hard:");
printf("%s: Predicted in %f seconds.\n", path, what_time_is_it_now()-time);
int nboxes = 0;
detection *dets = get_network_boxes(net, im.w, im.h, thresh, hier_thresh, 0, 1, &nboxes);
//printf("%d\n", nboxes);
//if (nms) do_nms_obj(boxes, probs, l.w*l.h*l.n, l.classes, nms);
if (nms) do_nms_sort(dets, nboxes, l.classes, nms);
draw_detections(im, dets, nboxes, thresh, names, alphabet, l.classes);
free_detections(dets, nboxes);
if(outfile){
save_image(im, outfile);
}
else{
char b[2048];
sprintf(b,"/home/FENGsl/darknet/data/out/%s",GetFilename(path));//"/home/FENGsl/darknet/data"修改成自己的路径
save_image(im, b);
printf("save %s successfully!\n",GetFilename(path));
#ifdef OPENCV
cvNamedWindow("predictions", CV_WINDOW_NORMAL);
if(fullscreen){
cvSetWindowProperty("predictions", CV_WND_PROP_FULLSCREEN, CV_WINDOW_FULLSCREEN);
}
show_image(im, "predictions");
cvWaitKey(0);
cvDestroyAllWindows();
#endif
}
free_image(im);
free_image(sized);
if (filename) break;
}
}
}
}
Step2:在前面添加*GetFilename(char *p)函数(注意后面的注释)
#include "darknet.h"
#include Step3:在Darknet主目录下重新make
Step4:批量预测命令
./darknet detector test voc.data cfg/yolov3.cfg backup/yolov3.backup
 Step5:在此输入预测图片的txt文件路径,我的测试集路径文件保存在data下面了,所以输入data/test.txt
Step5:在此输入预测图片的txt文件路径,我的测试集路径文件保存在data下面了,所以输入data/test.txt
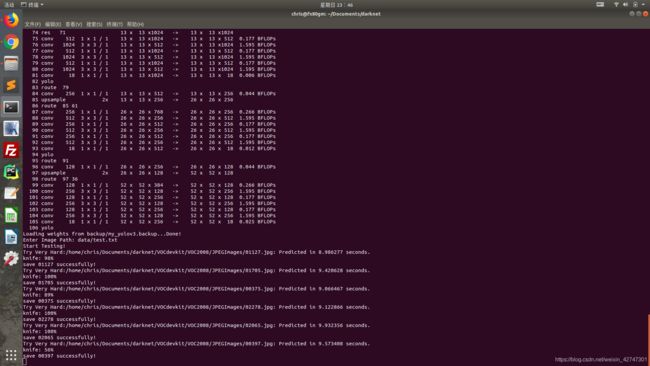 输出的预测图像都保存在data的out文件夹下
输出的预测图像都保存在data的out文件夹下
模型评估
本章节主要写mAP的计算和recall的计算
(1)mAP计算
Step1:终端输入命令
./darknet detector valid cfg/voc.data cfg/yolov3.cfg backup/yolov3_final.weights

Step2:输出预测坐标的result文件如下图所示,把文件名修改为knife.txt
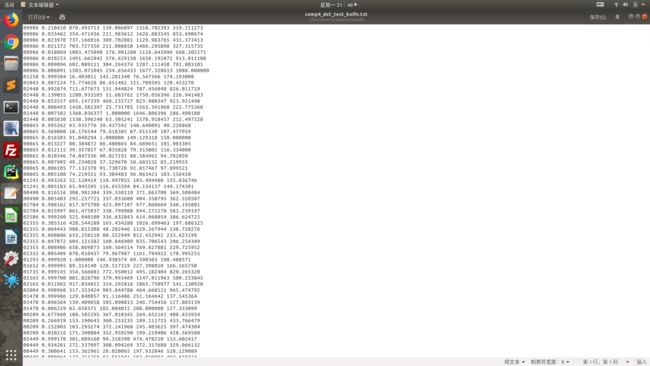 Step3:下载voc_eval.py
Step3:下载voc_eval.py
https://github.com/rbgirshick/py-faster-rcnn/tree/master/lib/datasets
Step4:新建compute_mAP,py,需要注意的是voc_eval.py是基于python2编写的,如果系统版本是python3的需要切换一下环境
from voc_eval import voc_eval
print voc_eval('/home/cxx/Amusi/Object_Detection/YOLO/darknet/results/{}.txt', '/home/cxx/Amusi/Object_Detection/YOLO/darknet/datasets/pjreddie-VOC/VOCdevkit/VOC2007/Annotations/{}.xml', '/home/cxx/Amusi/Object_Detection/YOLO/darknet/datasets/pjreddie-VOC/VOCdevkit/VOC2007/ImageSets/Main/test.txt', 'person', '.')
切换环境方法如下,运行以下两条命令
echo alias python=python3 >> ~/.bashrc
source ~/.bashrc
Step5:计算得出mAP结果
 我只有一类物体,计算得出的结果为0.797629
我只有一类物体,计算得出的结果为0.797629
(2)计算recall值
Step1:修改detector.c下的validate_detector_recall函数
替换list *plist = get_paths(“data/coco_val_5k.list”);为list *plist=get_paths(“scripts/train.txt”);自己的训练集文本
Step2:重新make
Step3:运行命令
./darknet detector recall cfg/voc.data cfg/yolov3.cfg backup/yolov3_final.weights
最后一列为recall值
计算IOU为NAN的问题,替换for(k = 0; k < l.wl.hl.n; ++k)为for(k = 0; k < nboxes; ++k),重编译执行
问题总结
可以参考(https://blog.csdn.net/lumingha/article/details/89038863#_373),总结的非常全面
Reference
https://blog.csdn.net/mieleizhi0522/article/details/79989754