C# 学习笔记(18)操作SQL Server 中
C# 学习笔记(18)操作SQL Server 中
数据库基础操作
SQL语法可以参考 菜鸟教程 或者微软官方的SQL示例
注意SQL不区分大小写
查
1.基础查询
--最基础的查询语句, select * from table_name
select * from studentTable

2.条件查询
--条件查询 select * from table_name where 条件
select * from studentTable where studentTable.gradeID = 5

3.条件查询 between and
--条件查询 select * from table_name where 条件
select * from studentTable where studentTable.cityID between 1 and 7 --查找 studentTable.cityID 在 1-7 范围内的行
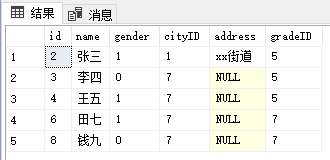
4.多条件查询 and
--多条件查询 select * from table_name where 条件 and 条件
select * from studentTable where studentTable.cityID between 1 and 7 and studentTable.gradeID = 7

5.字符匹配 like
--多条件查询 select * from table_name where 条件 and 条件 studentTable.name like '%七%' studentTable.name中含有字符 七 的行 %为通配符 匹配0 - 多个字符
select * from studentTable where studentTable.cityID between 1 and 7 and studentTable.name like '%七%'

6.按需求提取列
--条件查询 + 提取需要列 select table_name.列名1, table_name.列名2 from table_name where 条件
select studentTable.name as 姓名, gender as 性别, address as 地址 from studentTable where studentTable.gradeID = 5

7.联合查询
--联合查询 两个表的数据组合
select * from studentTable
inner join cityTable on cityTable.id = studentTable.cityID --将cityTable.id 等于 studentTable.cityID的两个表的行合并成一行

8.多表联合查询
--联合查询 多个表的数据组合
select studentTable.id as 学生编号, studentTable.name as 姓名, genderTable.name as 性别,
gradeTable.name as 班级, (provinceTable.province + cityTable.cityName + isNull(studentTable.address, '')) as 家庭地址
from studentTable
inner join cityTable on cityTable.id = studentTable.cityID
inner join provinceTable on cityTable.provinceID = provinceTable.id
inner join genderTable on genderTable.id = studentTable.gender
inner join gradeTable on gradeTable.id = studentTable.gradeID

9.嵌套查询
--嵌套查询 可以在查询语句结果的基础上多次进行筛选嵌套
select * from
(select studentTable.id as 学生编号, studentTable.name as 姓名, genderTable.name as 性别,
gradeTable.name as 班级, (provinceTable.province + cityTable.cityName + isNull(studentTable.address, '')) as 家庭地址
from studentTable
inner join cityTable on cityTable.id = studentTable.cityID
inner join provinceTable on cityTable.provinceID = provinceTable.id
inner join genderTable on genderTable.id = studentTable.gender
inner join gradeTable on gradeTable.id = studentTable.gradeID) as t1
where 性别 = '男'

10.排序
--对查询结果排序 order by 列名
select * from studentTable where cityID = 7
order by studentTable.id desc --desc 递减排序

11.分组
--对查询结果分组, 然后使用count(*) 统计各个分组的行数
select cityID, count(*) as 数量 from studentTable
group by cityID
group by cityID 会对相同的cityID值的行划分成一组,如下图cityID为7的共有4行,这四行划分成了一组,也就是只能显示一行,因此这个表中只能显示cityID列 和 聚合函数生成的列,不能显示姓名这样的列(四个姓名显示谁的?)

--对查询结果分组, 然后使用count(*) 统计各个分组的行数
select cityID, count(*) as 数量 from studentTable
group by cityID having cityID > 7 --having 限定cityID范围 只对范围内的cityID进行分组

索引
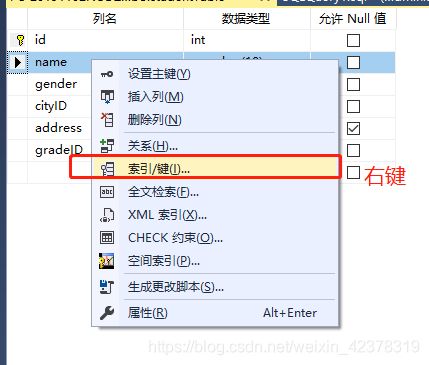
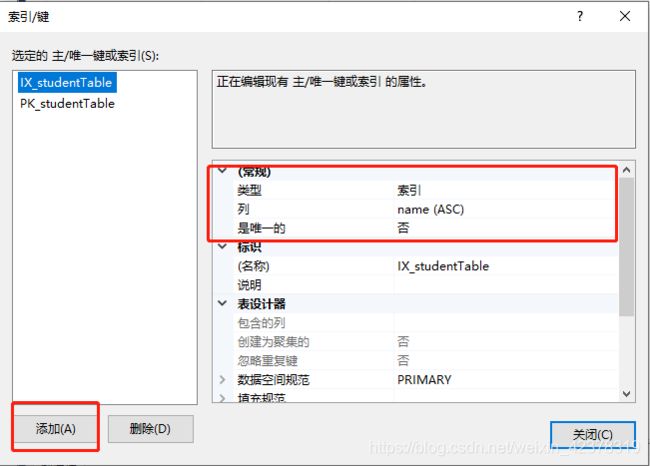
查询时,where后面经常使用的列(非主键列)可以将其设置为索引,用空间来换取时间,当数据量大时可以显著加快查询时间

聚合函数
微软文档
| 聚合函数 | 功能 |
|---|---|
| avg(列名) | 求列中各项的平均值 |
| count(列名) | 获取列的行数 |
| max(列名) | 获取列中的最大值 |
| min(列名) | 获取列中最小值 |
| sum(列名) | 获取列中各项之和 ,SUM 只能用于数字列。 Null 值会被忽略。 |
| stdev(列名) | 返回指定列中所有值的标准偏差 |
| stdevp(列名) | 返回指定列中所有值的总体标准偏差 |
| var(列名) | 返回指定列中所有值的方差 |
| varp(列名) | 返回指定列中所有值的总体统计方差 |
其他聚合函数操作类似
--查询学生信息表
select * from studentTable
--查询学生信息表行数
select count(cityID) from studentTable
--聚合函数参数前加 distinct 关键字后,重复的列只统计一次
select count(distinct cityID) from studentTable

开窗函数
上面的聚合函数查询出来是一个值,当想要将这个值添加到表中,就需要将这个值变成一列然后添加到表中(不然只有一个值,放到表中的哪一列?),over()函数也就是开窗函数就是干这个的,将聚合函数查出来的结果变成一列
--开窗
select *, count(*) over() as 总行数 from studentTable

over()函数也可以填入以下三种关键字(可以全部用上,也可以只用其中一种)
- PARTITION BY:将查询结果集分为多个分区。
--开窗
select *, count(*) over(partition by cityID) as 总行数 from studentTable
先获取 select * from studentTable 的查询结果,然后根据cityID对查询结果分组,最后对每组的行数进行count(*)统计并将数据变成一列添加到查询结果中

- ORDER BY:定义结果集的每个分区中行的逻辑顺序。
--开窗
select *, count(*) over(order by cityID) from studentTable
先获取 select * from studentTable 的查询结果,然后根据 cityID 列的值进行排序分组(order by 有起始行和结束行参数,这里没有填默认为第一行到当前行),最后对每组的行数进行count(*)统计并将数据变成一列添加到查询结果中
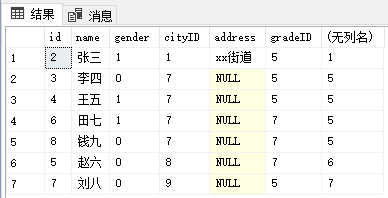
最常用的就是给结果集加上序号,查询结果最左侧的序号是数据库管理工具提供的,并不是查询结果集的内容。id是主键,不可以当作行序号(例如身份证号,前面的人去了,排在后面的人身份证号并不会改变,主键也是如此,前面数据删除后,主键号也不会改变,因此主键并不一定连续。)
--开窗
select *, ROW_NUMBER() over(order by id) as 行序号 from studentTable

- ROWS/RANGE:通过指定分区中的起点和终点来限制分区中的行数。 它需要 ORDER BY 参数,如果指定了ORDER BY 参数,则默认值是从分区起点到当前元素
没用过
增
添加信息时注意外键,例如cityID就是一个外键,添加时一定要确保城市信息表中存在该序号的主键,否则会添加失败。
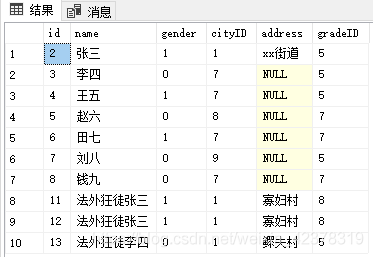
--向表 studentTable 中插入数据 数据顺序 (gradeID, name, gender, cityID, address)
insert into studentTable(gradeID, name, gender, cityID, address)
Values(8,'法外狂徒张三', 1, 1, '寡妇村')

--向表 studentTable 中插入多条数据 数据顺序 (gradeID, name, gender, cityID, address)
insert into studentTable(gradeID, name, gender, cityID, address)
Values(8,'法外狂徒张三', 1, 1, '寡妇村'),
(5,'法外狂徒李四', 0, 1, '鳏夫村')
删
删除时需要注意外键问题,比如要删除cityTable中的一个城市信息,则需要保证外键(学生信息表中cityID没有使用对应的城市),否则不能删除,需要先删除学生信息表使用该城市的学生信息,然后才能删除cityTable中的城市信息。其实还是为了确保学生信息表中cityID列中所有城市都可以在cityTable中查询到。
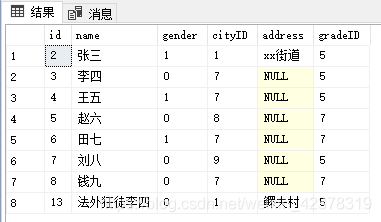
--删除 studentTable 表中 名字是 法外狂徒张三的列
delete from studentTable where studentTable.name = '法外狂徒张三'
改
--将studentTable 表中 studentTable.name = '法外狂徒李四' 的行的 gender更新为1
update studentTable set studentTable.gender = 1 where studentTable.name = '法外狂徒李四'

添加视图
在将列和表设计为最小状态后,查询需要的数据时不可避免的需要多个表联合查询,每次都要联合查询很是麻烦,SQL提供了视图来解决这个问题
--联合查询 多个表的数据组合
select studentTable.id as 学生编号, studentTable.name as 姓名, genderTable.name as 性别,
gradeTable.name as 班级, (provinceTable.province + cityTable.cityName + isNull(studentTable.address, '')) as 家庭地址
from studentTable
inner join cityTable on cityTable.id = studentTable.cityID
inner join provinceTable on cityTable.provinceID = provinceTable.id
inner join genderTable on genderTable.id = studentTable.gender
inner join gradeTable on gradeTable.id = studentTable.gradeID
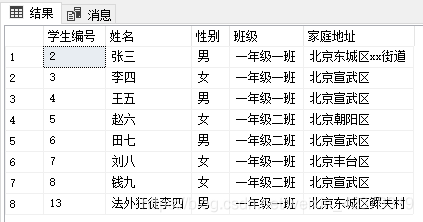
这种经常使用但是又臭又长查询就可以做出视图
--创建视图 studentInfoTable
create view studentInfoTable
as
select studentTable.id as 学生编号, studentTable.name as 姓名, genderTable.name as 性别,
gradeTable.name as 班级, (provinceTable.province + cityTable.cityName + isNull(studentTable.address, '')) as 家庭地址
from studentTable
inner join cityTable on cityTable.id = studentTable.cityID
inner join provinceTable on cityTable.provinceID = provinceTable.id
inner join genderTable on genderTable.id = studentTable.gender
inner join gradeTable on gradeTable.id = studentTable.gradeID
创建视图后,就可以对视图像表一样操作,但是视图并不是重新创建了一张表,只是把上面那一坨语句的查询结果当作了表。

如果想要修改视图,将创建视图的关键字 create 改为 alter 即可
添加存储过程
存储过程和函数类似,可以像调用函数一样调用存储过程
--创建存储过程 该存储过程有一个参数 @gradeName 类型为 nvarchar(20)
create proc GetStudentsInfoFromGrade
@gradeName nvarchar(20) --参数 班级名称
as
begin
--查询指定班级的学生信息
select * from studentInfoTable where 班级 = @gradeName
end

--调用存储过程
exec GetStudentsInfoFromGrade '一年级一班'

如果想要修改存储过程,将创建存储过程的关键字 create 改为 alter 即可
数据透视
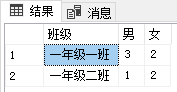
数据透视,起始就是行列转换,例如想要看每个班级中男女个数,可以将性别 男 女作为列名,班级作为行名。

--数据透视
select 班级, count(case when 性别 = '男' then 学生编号 end) as 男,
count(case when 性别 = '女' then 学生编号 end) as 女 from studentInfoTable
group by 班级 --分组
order by 班级 desc --排序
数据分页
当数据量比较大时,由于内存大小有限,就需要对查询结果进行分页处理
进行分页前,首先要对数据进行排序添加序号
--排序并添加序号
select *, ROW_NUMBER() over(order by id) as 行序号 from studentTable
查询结果最左侧的序号是数据库管理工具提供的,并不是查询结果集的内容。id是主键,不可以当作行序号(例如身份证号,前面的人去了,排在后面的人身份证号并不会改变,主键也是如此,前面数据删除后,主键号也不会改变,因此主键并不一定连续。)

创建一个存储过程
--获取一页学生信息
create proc GetStudentInfoPage
@pageIndex int, --要查询的页序号
@pageSize int --页大小
as
begin
select * from (select *, ROW_NUMBER() over(order by id) as 行序号 from studentTable) as t1 --嵌套查询
where 行序号 between (@pageIndex-1)*@pageSize+1 and @pageIndex*@pageSize --根据页序号和页大小确定筛选条件
end
--查询第二页 一页两个数据
exec GetStudentInfoPage 2, 2
