Map接口实现:HashMap
Map接口
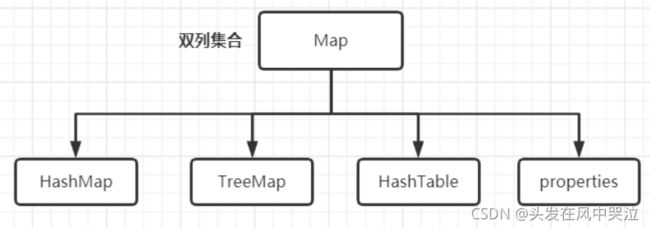
1.Map用于存放具有映射关系的双列数据:key-value
2.Map中的key和value可以是任何引用类型的数据,会封装到HashMap$Node对象中
3.Map中的key值不允许重复,value值可以重复,(key为null,只能有一个)
4.常用String类作为Map的key
5.key和vaule存在单向一对一关系,即通过指定的key总能找到对应的value
Map常用方法
remove(Object key) 删除
size() 返回元素个数
isEmpty() 判断是否为空
clear() 清空
get(Object key) 获取val
containsKey 查找键是否存在
keySet 获取键集合
entrySet 获取所有的关系 k-v
values 获取值集合
Map遍历方式:
1. keySet() 获取key的Set集合
2. EntrySet() 获取key-value的Set集合,再向下转型为Entry,使用Entry接口中 getKey() 和 getValue()方法获取 k-v
3. values() 获取value的Collection集合
public class Map六大遍历方式 {
public static void main(String[] args) {
HashMap map = new HashMap();
map.put("邓超","孙俪");
map.put("张三","李四");
map.put("黄晓明","李颖");
map.put("胡歌",null);
map.put(null,"护士");
// keySet获取key集合
Set set = map.keySet();
// 1 增强for
for (Object obj : set) {
System.out.println(obj);
}
// 2 迭代器 迭代key
Iterator iterator = set.iterator();
while (iterator.hasNext()) {
Object next = iterator.next();
System.out.println(next);
}
//values获取value集合
Collection values = map.values();
// 3 values()取出值集合
for (Object value : values) {
System.out.println(value);
}
// 4 迭代器 迭代值
Iterator iterator1 = values.iterator();
while (iterator1.hasNext()) {
Object next = iterator1.next();
System.out.println(next);
}
// 5 EntrySet
Set set1 = map.entrySet();
for (Object o : set1) {
//向下转型 Object 转 Entry
Map.Entry o1 = (Map.Entry) o;
Object key = o1.getKey();
Object value = o1.getValue();
System.out.println(key +"-" +value);
}
// 6 迭代器
Iterator iterator2 = set1.iterator();
while (iterator2.hasNext()) {
}
}
}
HashMap
HashMap源码解析
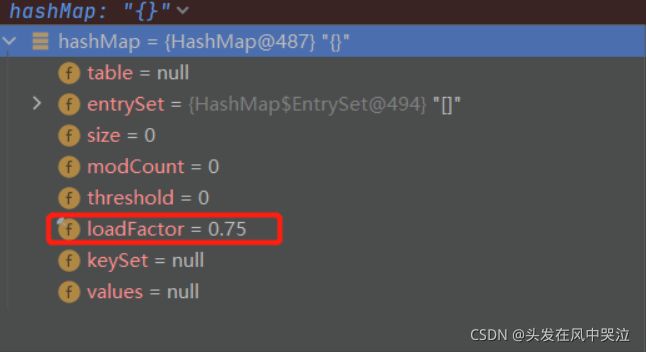
1.执行无参构造器,初始化 (负载系数)loadFactor = 0.75
static final float DEFAULT_LOAD_FACTOR = 0.75f;
public HashMap() {
this.loadFactor = DEFAULT_LOAD_FACTOR;
}
2.走putVal()方法,传递key、value、key的hash值
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
3.整个集合最重要的一个方法putVal()
情况一:HashMap刚初始化,如果table容量为空,进行第一次resize()扩容操作;
通过hash值计算出索引位置,如果该索引处为null,直接将node节点存入
情况二:如果tabel容量不为空,计算出的索引位置为null,直接存入
情况三:如果tabel容量不为空,计算出的索引位置不为null;
如果该索引处 key的hash值 和 equlas() 和存入相同,则旧的value值被替换
情况四:如果tabel容量不为空,计算出的索引位置不为null;如果该索引处 key的hash值 和 equlas() 和存入的不相同,
则遍历该索引处的链表继续比较,有相同则替换value,无相同则添加到最后
扩容机制:当table容量为0时,第一次扩容到16,阈值为12,每次添加节点后都要判断 需要的最小容量是否超过阈值,超过则执行resize()方法进行扩容
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)//如果链表已经红黑树化,用红黑树方式存入
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
//挂载到最后
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1)
treeifyBin(tab, hash);// 如果数组容量不到64,单条链表到达8也不会树化,此时只会进行扩容
break;
}
//找到相同的key,返回替换value
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) {
// existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
HashMap初始化后
HashTable
源码简单介绍
HashTable 键和值都不能为null
HashTable 线程安全,HashMap 线程不安全,但效率高
底层有数组 Hashtable$Entry[] 初始化为11,阈值threshold=11*0.75=8
扩容条件:count >= threshold
扩容方法:rehash()
扩容倍数(2倍+1):int newCapacity = (oldCapacity << 1) + 1;
Properties
介绍
Properties类继承自HashTable类并且实现Map接口
还可以用于从 ***.properties文件中,加载数据到Propertiesa类对象,进行读取和修改