《信息检索》课程大作业 实现一个本地搜索引擎
《先锋检索》——开发文档
也是本人的第一篇博客
这篇博客是本人《信息检索》课程大作业的开发文档,使用了larbin(网络爬虫)+xunsearch(搜索引擎解决方案)的解决方案。事实上,或许有更多更简单/更高超的方案,但是我使用的这个方案,一方面,相比一些需要较高技术的方案节省了大量的时间;另一方面,相对于一些现成的代码实际上仍然需要一些简单的操作,有利于进一步加强对“信息检索”实现过程的理解。
注意:本系统需要在Linux下部署运行,本人曾尝试使用Ubuntu18.0 /Centos 7.0部署,均获得成功。可能需要使用虚拟机,有关教程请自行搜索,相信你一定行。
第一部分主要介绍一些理论上的内容;实操性的内容从第二部分设计文档开始。
文末附有本项目的仓库链接。
一些细节,如文件应该放在那个文件夹下、命令行应该在哪个文件夹中运行,可能没有显式地指出,希望读者可以从附图中得到有关信息,或自行尝试。
项目地址:https://gitee.com/CHH12/IR-project-pioneer-search
仓库中含有完整设计文档。
(由于选题原因,一些图片不能展示,敬请移步仓库下载PDF原版)
目录
(一)系统说明
一、系统架构
二、模块介绍
1.网络爬虫——Larbin
2.前端+搜索引擎:Xunsearch(迅搜)& Xapian
3.网页解析与数据存储:Parser.py(BeautifulSoup4)
(二)设计文档
一、运行环境
二、总体设计流程
三、各模块设计细节
1.网络爬虫模块
2.解析器模块
3.搜索引擎模块
四、网站页面一览
-
(一)系统说明
本搜索引擎主要收录与 红色 有关的网页文档,基于这一描述,我决定将本搜索引擎命名为“先锋检索”。
-
一、系统架构
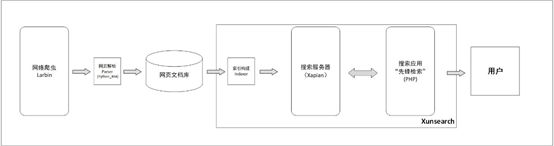
本搜索引擎系统主要架构如上图所示。
检索的源文档由网络爬虫从给定的种子网页开始爬取,爬取到本地后利用Python中的BeautifulSoup4模块进行网页的解析,并写入数据库中,完成网页文档数据的获取。
之后利用搜索引擎解决方案Xunsearch(迅搜)构建搜索引擎,利用索引器Indexer对文档数据进行索引,并构建基于Xapian的后端搜索服务器与前端的搜索应用,向用户展示出搜索功能。
-
二、模块介绍
-
1.网络爬虫——Larbin
Larbin是一种开源的网络爬虫,由法国人Sébastien Ailleret独立开发,用c++语言实现。
Larbin设计简单,具有高度的可配置性,能够配置抓取深度、间隔、并发度、代理,并支持通过后缀名对抓取网页进行过滤。
Larbin具有非常高的效率,一个简单的larbin的爬虫可以每天获取500万的网页,可以轻易的获取/确定单个网站的所有联结,还可以镜像一个网站。Larbin能够跟踪从给定的种子页面出发,进行自动扩展url的页面抓取与保存,从而为搜索引擎提供广泛的数据来源。
美中不足的是,Larbin只是一个爬虫,只抓取网页,并不负责网页的解析、数据库的存储以及索引的建立,也不支持分布式系统。另外,Larbin已经较长时间不再更新,因而不支持https协议,这在今天很大程度上造成了网页页面的局限性。
这里采用由国人在基于原版Larbin2.6.3版本上继续开发并发布于GitHub的Larbin2.6.5版本进行搜索引擎系统的构建。
项目网址:https://github.com/ictxiangxin/larbin
2.前端+搜索引擎:Xunsearch(迅搜)& Xapian
(1)Xunsearch
Xunsearch(迅搜)是一以 GPL 协议开源发布的高性能、全功能的全文检索解决方案,并针对中文深度优化和处理,用于帮助开发者针对海量数据快速建立搜索引擎。
Xunsearch 采用结构化分层设计,包含后端服务器和前端开发包两大部分。后端是用 C/C++ 基于 Xapian搜索库、SCWS 中文分词、libevent 等开源库开发,借鉴了 nginx 的多进程多线程混合工作方式,是一个可承载高并发的高性能服务端。前端则是使用流行的脚本语言编写了开发工具包(SDK)。
Xunsearch具有以下特点:
- 海量数据下高速搜索响应。单库最多支持 40 亿条数据,在 500 万张网页1.5TB 数据中,非缓存检索时间约 0.5 秒。
- 为搜索而自主开发 scws 中文分词库,支持复合分词、自定义补充词库,保障查全率、准确率。
- 拥有健壮稳定的后端守护程序、内置缓存池与线程池用于保障性能。
- 索引接口齐全,索引添加简便,支持实时搜索,支持多种数据源 ( SQL, JSON, CSV等)。
- 开发难度较低,具备规范的中文文档、示范代码,以及非常实用的辅助工具。
- 除通用搜索引擎功能外,还内置支持拼音检索、分面搜索、相关搜索、同义词搜索、搜索纠错建议等专业功能。
- 与 Lucene/Sphinx 等相比,xunsearch 提供了更丰富且必需的功能。
在开发的过程中,正是得益于xunsearch所提供的多种方便的工具,才能够让我在短时间内得以顺利地开发完成本项目。
特别注意到,Xunsearch中的索引有如下特点:
- Xunsearch 每个搜索项目的索引数据是分开单独存放的,索引本质上是一系列预设计文件, 内部都是特别设计的 Tree 结构。
- 包含 2 个主要索引数据库,分别是db 默认的主索引数据库,存放各种检索数据;log_db 搜索日志数据库,用于存放搜索日志相关,用于实现相关搜索、搜索建议、拼音搜索等。
- 索引操作(包含添加、删除、修改文档)均是异步的行为,以达到性能优化设计。
- 官方地址:http://www.xunsearch.com/
(2)Xapian
Xunsearch基于Xapian搜索引擎库开发,也正是在Xapian的支持下xunsearch才能有前文所述的高速搜索响应。
在Xapian的文档中,官方称 Xapian是一个“允许开发人员轻易地添加高级索引和搜索功能到他们的应用系统的高度可修改的工具,它在支持概率论检索模型的同时也支持布尔型操作查询集”。
实际上Xapian与Lucene有许多相似之处,如二者都有Term、Value、Posting、Position和Document这些概念。
当然,而二者也有许多不同:Xapian基于C++进行开发,可以绑定到多种语言,可移植性高;Xapian采用BM-25模型,具有较好的检索效果;Xapian的检索性能远远高于Lucene。
Xapian提供了多种查询机制,包括:概率性搜索排名、相关度反馈、邻近搜索、布尔搜索、词干提取、通配符查询、别名查询、拼写纠正等,为开发者提供了丰富的功能。
Xpian的主要功能点总结如下:
- 开源,基于GPL协议
- 支持Unicode,存储索引数据也是用UTF-8
- 可移植性,可以运行在Linux, Mac OS X, Windows系统上
- 支持多种语言的绑定,现在有Perl, python, java, PHP, C#等
- 以概念模型为查询分数计算基础,利用BM25算法进行加权
- 可以实现相关度的反馈,Xapian能够基于用户的查询条件来返回与其相关的词组,并基于此进行检索,返回一类相关的文档
- 词组与近似词查询,用户的查询条件可以指定词组中词的出现顺序,出现次数等条件
- 支持Boolean查询,如"A NOT B",Boolean查询结果的排序是基于概率模型,
- 支持词干的查询
- 支持前缀查询,如Xap*
- 支持同义词查询,
- 支持基于用户查询条件的拼写检测
- 支持分面搜索。
- 支持大于2GB的数据文件
- 与平台(操作系统)独立的索引格式,linux和windows平台可以使用相同的索引
Xapian的主要设计如下:
- 布尔型检索和概率性检索有两种组合的方式:先用布尔型检索得到所有documents中的某个子集,然后在这个子集中再使用概率性检索。 先进行概率性检索,然后使用布尔型检索过滤查询结果。
- 布尔型风格的查询都可以在检索得出documents集合结果后,然后使用概率性检索的排序(BM25)。
- 使用flint作为存储系统,以块的形式来存储,默认每块是8K,理论上每一个文件最大可以达到2048GB。Terms和Documents使用B-树来存储的,增删改查比较方便迅速
- Xapian的database是所有用于检索的信息表的集合,必须包含:
- posting_list_table:保存了被每一个term索引的document,实际上保存的应该是document的唯一识别Id。
- record_table:保存了每一个document所关联的data,data不能通过query检索,只能通过document来获取。
- term_list_table:保存了索引每个document的所有的term。
3.网页解析与数据存储:Parser.py(BeautifulSoup4)
对于网页文档内容进行解析和格式化。可以利用python的BeautifulSoup4模块编写一个简易的脚本程序实现这一功能。
BeautifulSoup4是一个可以从HTML或XML中提取数据的python库,利用它可以很快的实现网页解析的功能。
模块文档:https://beautifulsoup.readthedocs.io/zh_CN/v4.4.0/#
-
(二)设计文档
-
一、运行环境
主机:
系统:Windows 10
带宽:40Mbps
虚拟机(搜索引擎运行环境):
软件:VMware Workstation Pro 14
配置设置:
内存:2GB
处理器:Intel(R) Core(TM) i7-8550U CPU @ 1.80GHz(核心数:1)
系统:Linux Ubuntu 18.04
依赖环境:
Apache 2.0
PHP 5.3.29
python 3
-
二、总体设计流程
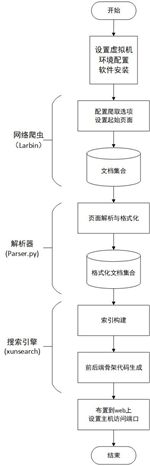
-
三、各模块设计细节
-
1.网络爬虫模块
(1)概述:
网络爬虫模块使用Larbin2.6.5进行网页文档的爬取。在按照配置进行爬取30分钟后,最终获得41612个文档(约1.25GB)。由于爬虫自身的限制,这些文档均来自http站点。
(2)配置:
- 输出模式:简单保存
- 是否锁定种子站点:否
- 并行连接访问的数目:50
- 并行DNS请求的数目:5
- 爬取站点的最大深度:无限制
- 同一个服务器的两次请求的间隔时间:10秒
- 带宽限制:无限制
- 运行时间:30分钟
- 提取的页面数:无限制
- 是否哈希页面以去重:是
- 种子网页地址:
- http://www.12371.cn(共产党员网)
- http://www.uucps.edu.cn/(大学生网络党校)
(3)爬取记录与分析:
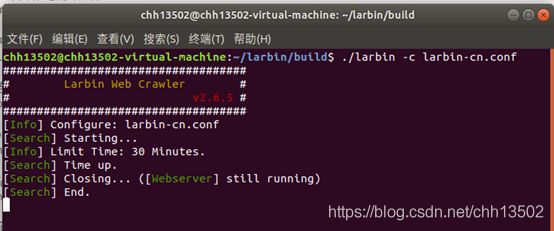
从统计结果可以看出,共收到56894个URL,访问了55685个页面,最终成功爬取41612个页面。平均每分钟爬取1387个页面,其效率之高可见一斑。

从上图可以具体地得出爬虫的爬取效率,可见爬虫爬取的速度随着时间的推移也会发生较大的变化。
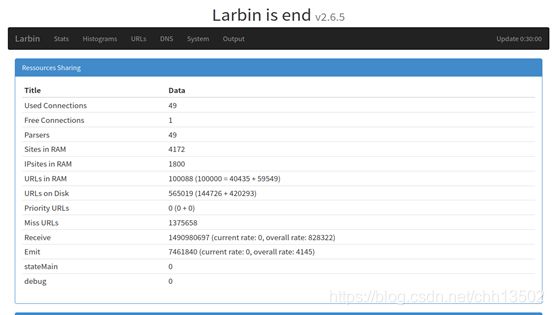
上图反映了爬虫爬取结束时的资源使用情况。
2.解析器模块
- 概述:
解析器模块由我直接利用Python的BeautifulSoup4, Pandas模块编写,前者可以对网页文档进行解析,后者便于将数据以csv文件形式保存,便于后续搜索引擎使用。
2.核心代码:
id = []
title = []
body = []
urls = []
#确定id,保存url
id.append(k)
url = lines[k % 2000]
url = url[url.find('h'):].replace('\n', '')
urls.append(url)
#解析网页
with open(path + file, 'rb') as f:
soup = BeautifulSoup(f.read(), 'html.parser')
if soup.title == None or soup.title.string == None:
title.append('')
else:
title.append(soup.title.string.replace('\n', '').replace('\r', ''))
body.append(soup.get_text().replace('\n', '').replace('\r', ''))
print(k)
#生成记录
data = {'id': id, 'title': title, 'body': body, 'urls': urls}
frame = pd.DataFrame(data)
#写入数据文件
if k == 0:
frame.to_csv('data_u.csv', encoding='utf-8', index=False)
else:
frame.to_csv('data_u.csv',
mode='a+',
header=False,
encoding='utf-8',
index=False)
k = k + 1(3)处理结果:

每个文档被分出id,title,body, urls四个字段,存储在一个csv文件中。
3.搜索引擎模块
(1)概述:
搜索引擎模块利用xunsearch提供的开发工具即可实现。首先确定运行环境正常,然后对格式化的csv文件进行索引,并生成搜索骨架代码,即可实现基本检索功能。
(2)构造流程:
#环境检查:
工具包中配备了运行检测工具RequiredCheck ,检查当前环境是否满足Xunsearch的运行条件。
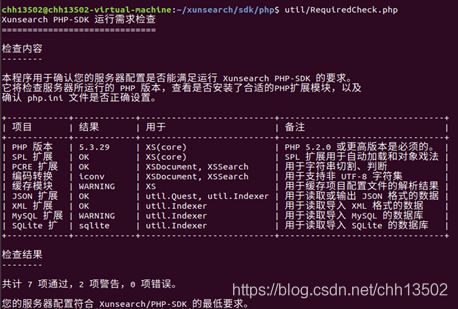
这里可以看出系统环境能够运行Xunsearch。
#编写项目配置文件:
Xunsearch工具包中配备了配置文件生成工具IniWizzard(http://xunsearch.com/tools/iniconfig),仅需指定项目的名称,服务器的端口,以及数据中各个字段在索引中的类型、索引方式、检索权重,摘要长度等属性,就可以自动生成配置文件。
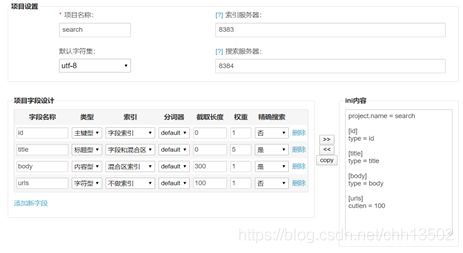
回顾网页解析的部分,在生成的csv文件中,每条文档记录有四个字段:id,title,body,urls。在搜索引擎中,对这三个字段进行如下定义与说明:id为主键,作为每个文档的标识符;title为每个文档的标题,可以指定字段搜索,也可从“全文”搜索中得到结果,且赋予较高权重;body为每个文档的内容,可以从“全文”搜索中得到结果,并截取300个字符作为搜索结果的摘要显示;urls 作为每个文档在展示时的附属信息,不进行索引;这里截取完整url进行展示,故取较大长度100。利用该工具可以生成配置文件。由于大多配置与默认相同,因此没有显式地在配置文件中指出。
#建立索引:
工具包中配备了索引管理器Indexer,可以批量导入索引、清空索引、刷新索引队列等。可以方便地为格式化的csv文件建立索引。

在db文件夹下,可以看到建立的索引文件。
#搜索测试:
工具包中配备了搜索测试工具Quest,可以在当前索引中进行测试搜索,测试给定查询词的返回的数据。

#骨架代码生成:
工具包中配备了骨架代码生成工具SearchSkel,可以生成按照配置文件生成前端代码,大大加快了开发速度,避免了“反复造轮子”的困扰。
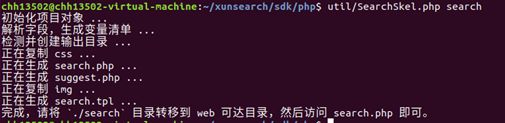
如图所示,已经在./search中生成了骨架代码,访问php文件即可使用搜索功能。
#部署到web可达目录:
运行Apache2.0,PHP5.4,将骨架代码放入/var/www/html中,即可在本地服务器localhost访问搜索页面,实现搜索引擎的功能。
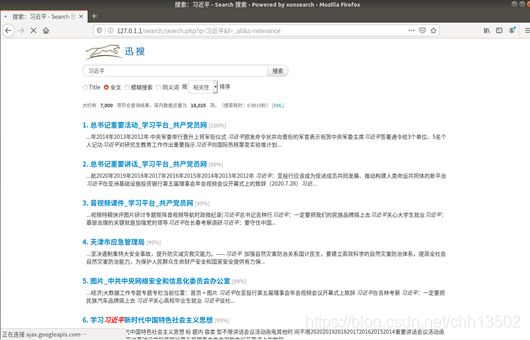
输入查询词,生成url,并输出对应检索页面。

点击文档标题,会返回对应的文档主键(id)
#l利用给定代码进行再开发:(修改php文件等,请自行摸索)
- 重新设计页面logo,更加符合本搜索引擎主题
- 对骨架代码中的国外cdn进行修改,加快访问速度
- 对页面中的不合理的内容、样式进行优化,增加美观性
- 对搜索反馈的结果进行优化,加入指向源网页的超链接,优化用户体验
#部署到服务器:
本项目已经部署到公网服务器(出于安全缘故这里不进行开放)。
-
四、网站页面一览
(图片无法上传,请进入仓库下载原文)
在部署到web可访问的目录后,通过虚拟机的端口转发设置,即可实现在主机访问搜索引擎。若将本项目布置在服务器上,即可通过互联网进行访问。
- 首页:
可以从本地浏览器访问到检索页面。在使用了搜索功能后,搜索引擎将分析搜索日志,从而提供了热门搜索词。
页脚标明了作者的信息。
搜索时,可以选择按照标题字段检索或全文检索,可以开启同义词搜索、模糊搜索等功能,也可以选择排序规则。
2.查询词联想:
可以看到在输入查询词的同时系统会自动进行联想。
3.搜索纠错:
出现查询词可能出现错误时,系统会给出替换用词;当没有搜索到结果时,系统会给出纠错提示与修改建议
4.结果反馈:
在反馈搜索时,会反馈查询结果的标题、文档摘要以及文档对应的原网址,并进行对查询词进行高亮表示(红字斜体),并会返回检索条目,检索时间,检索相似度等信息。在页脚还提供了与查询词相关的搜索内容。
5.结果交互:
为每个搜索结果的标题进行特殊设置:一是在选中条目时,条目样式会发生改变,增强交互感;二是设置超链接,方便从搜索结果直接跳转至原页面进行内容查看。
项目地址:https://gitee.com/CHH12/IR-project-pioneer-search
链接中含完整设计文档