Nebula Graph图数据的安装部署
随着社交、电商、金融、零售、物联网等行业的快速发展,现实社会织起了了一张庞大而复杂的关系网,亟需一种支持海量复杂数据关系运算的数据库即图数据库。本系列文章是学习知识图谱以及图数据库相关的知识梳理与总结
本文会包含如下内容:
- nebula的介绍
- nebula server的安装
- nebula console安装
- nebula studio安装
- nebula importer的安装
本篇文章适合人群:架构师、技术专家、对知识图谱与图数据库感兴趣的高级工程师
1. nebula的介绍
官网介绍: nebula是一个可靠的分布式、线性扩容、性能高效的图数据库世界上唯一能够容纳千亿个顶点和万亿条边,并提供毫秒级查询延时的图数据库解决方案
目前互联网大厂如腾讯、京东、美团、快手的图数据库基本都使用这个。
目前nebula有2个版本,nebula 1.x 及 刚刚发布的 nebula 2.0.0版本,2.0.0版本增强了 nGQL 表达能力,提高了带索引数据插入性能,逐步兼容 openCypher
nebula 2.0.0的release notes详见:https://discuss.nebula-graph.com.cn/t/topic/3235
本文基于nebula 2.0.0进行安装部署
一个典型的Nebula Graph集群架构如下:
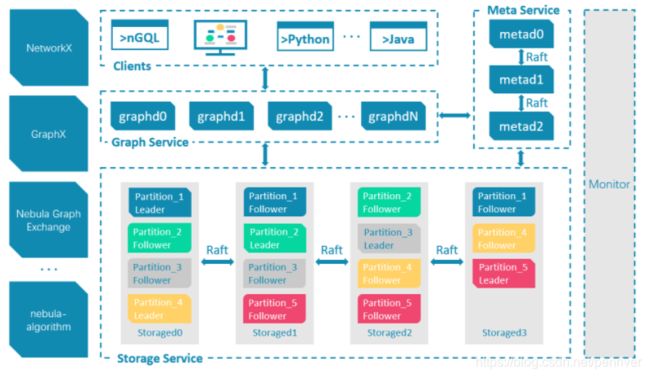
2. nebula server的安装
安装步骤如下:
nohup wget https://github.com/vesoft-inc/nebula-graph/releases/download/v2.0.0/nebula-graph-2.0.0.el7.x86_64.rpm &
rpm -ivh --prefix=/data1/graphdb/nebula nebula-graph-2.0.0.el7.x86_64.rpm
cd /data1/graphdb/nebula/etc
mv nebula-metad.conf.production nebula-metad.conf
mv nebula-graphd.conf.production nebula-graphd.conf
mv nebula-storaged.conf.production nebula-graphd.conf
cd ../
./scripts/nebula.service start all
./scripts/nebula.service status all
./scripts/nebula.service stop all配置文件有三个,在etc目录下:nebula-metad.conf、nebula-graphd.conf、nebula-storaged.conf,分别是针对元数据服务、图服务、存储服务的配置
三个配置文件都需要配置元数据服务地址,如: --meta_server_addrs=172.25.21.22:9559,172.25.21.17:9559,172.25.21.19:9559,同时需要将--local_ip修改为本机的IP
针对nebula-metad.conf除上面的配置外,其它不用修改
针对nebula-graphd.conf除上面的配置外,增加--default_charset=utf8 --default_collate=utf8_bin两个参数
针对nebula-storaged.conf,调整如下参数:
另外关于 minor compact 和 major compact 调优,生产环境的建议是:开启 minor compact 关闭 major compact。
关闭 major compact 主要是因为这个操作很占磁盘 IO,并且很难通过线程数(--rocksdb_db_options={"max_subcompactions":"4","max_background_jobs":"4"})控制
max_edge_returned_per_vertex 这个参数,数据在最底层存储层直接针对超级节点进行了过滤,在使用中就不会受到超级节点的困扰
#rocksdb DBOptions in json, each name and value of option is a string, given as "option_name":"option_value" separated by comma
--rocksdb_db_options={"max_subcompactions":"4","max_background_jobs":"4"}
# rocksdb ColumnFamilyOptions in json, each name and value of option is string, given as "option_name":"option_value" separated by comma
--rocksdb_column_family_options={"disable_auto_compactions":"false","write_buffer_size":"67108864","max_write_buffer_number":"4","max_bytes_for_level_base":"268435456"}
# rocksdb BlockBasedTableOptions in json, each name and value of option is string, given as "option_name":"option_value" separated by comma
--rocksdb_block_based_table_options={"block_size":"8192"}
# Raft election timeout
--raft_heartbeat_interval_secs=10
# RPC timeout for raft client (ms)
--raft_rpc_timeout_ms=5000
--max_batch_size=512
# recommend: 1/3 of all memory 256/3 == 80GB
--rocksdb_block_cache=81920
# The type of storage engine, `rocksdb', `memory', etc.
--engine_type=rocksdb
--max_handlers_per_req=10
# 参数配置减小内存使用
--enable_partitioned_index_filter=true
--max_edge_returned_per_vertex=100003. nebula console安装
cd /data1/graphdb/
wget https://hub.fastgit.org/vesoft-inc/nebula-console/releases/download/v2.0.0-ga/nebula-console-linux-amd64-v2.0.0-ga
chmod 111 nebula-console-linux-amd64-v2.0.0-ga
mv nebula-console-linux-amd64-v2.0.0-ga nebula-console
#使用语法: nebula-console -addr -port -u -p [-t 120] [-e "nGQL_statement" | -f filename.nGQL]
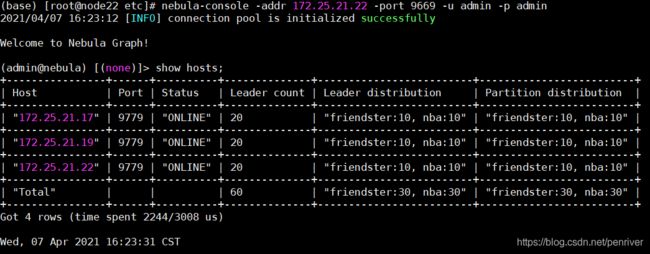
nebula-console -addr 172.25.21.22 -port 9669 -u admin -p admin 使用console查看集群信息,可以看到集群有三个节点
4. nebula studio安装
需要提前安装好docker及docker-compose,并配置好aliyun作为镜像【docker的版本是18.09.6,如果docker版本较新,如20.10.5时,网络映射有问题,导致7001端口通过http://ip:7001 不能访问】
wget https://hub.fastgit.org/vesoft-inc/nebula-web-docker/archive/refs/heads/master.zip
unzip nebula-web-docker-master.zip
cd /data1/graphdb/nebula-web-docker-master/v2/
#拉取镜像
docker-compose pull
#创建并启动镜像
docker-compose up -d
#停止并删除镜像
docker-compose down
#启动服务
docker-compose start
#停止服务
docker-compose stopstudio的界面如下:
5. nebula importer的安装
importer未提供部署包,需要先编译。因为importer是go语言开发,所以需要先安装go的运行环境
5.1 安装go运行环境
wget https://studygolang.com/dl/golang/go1.13.8.linux-amd64.tar.gz
tar -zxvf go1.13.8.linux-amd64.tar.gz
mv go /usr/local/go
#配置环境变量
#将下述配置加到 `~/.bashrc` 文件中,并通过 `source ~/.bashrc` 使其生效。
export GOROOT=/usr/local/go
export GOPATH=$HOME/go
export GO111MODULE=on
export GOPROXY=https://goproxy.cn
export PATH=$PATH:$GOROOT/bin:$GOPATH/bin:/data1/graphdb/nebula/bin
检查是否安装成功:go version
如果能成功显示:go version go1.13.8 linux/amd64,则表示安装成功
5.2 编译importer
#使用git clone或手工下载zip包
git clone https://github.com/vesoft-inc/nebula-importer.git
cd nebula-importer
make build5.3 导入命令示例
nebula-importer --config=nba-data-importer.yaml
6. 配置环境变量
为了执行命令时不需要进入到nebula的安装目录,做如下操作
1. 将所有nebula-console、nebula-importer 迁动到nebula/bin目录下
2. 配置环境变量,修改 `~/.bashrc` 文件的path配置项,并通过 `source ~/.bashrc` 使其生效
export PATH=$PATH:$GOROOT/bin:$GOPATH/bin:/data1/graphdb/nebula/bin:/data1/graphdb/nebula/scripts
这样,就可以愉快的执行命令了,如:
nebula.service status all
