利用Google的CoLab来跑Faster-Rcnn pytorch版
一、 前言
实验平台:CoLab
实验环境:python 3.7+pytorch 1.15
官方教程
新手指引:https://medium.com/deep-learning-turkey/google-colab-free-gpu-tutorial-e113627b9f5d
常见问题:https://research.google.com/colaboratory/faq.html
官方给出的新手指引当中已经给出了前期配置、常见软件和库的安装等方法。大家凭借官方教程可以基本入门Colab,但如果想更加自如地在Colab上跑通自己的代码,可能还需要更多的学习。
二、前期准备
按照我的第一篇文章来准备好实验环境,文章链接https://blog.csdn.net/w1520039381/article/details/117515712
三、配置实验环境
1、.安装必要的包和软件
输入以下代码
!apt-get install -y -qq software-properties-common python-software-properties module-init-tools
!add-apt-repository -y ppa:alessandro-strada/ppa 2>&1 > /dev/null
!apt-get update -qq 2>&1 > /dev/null
!apt-get -y install -qq google-drive-ocamlfuse fuse
from google.colab import auth
auth.authenticate_user()
from oauth2client.client import GoogleCredentials
creds = GoogleCredentials.get_application_default()
import getpass
!google-drive-ocamlfuse -headless -id={
creds.client_id} -secret={
creds.client_secret} < /dev/null 2>&1 | grep URL
vcode = getpass.getpass()
!echo {
vcode} | google-drive-ocamlfuse -headless -id={
creds.client_id} -secret={
creds.client_secret}
运行后,会出现提示框框需要输入验证码,点击蓝色的链接复制验证码,然后粘贴到框框中按enter就搞定了
2、挂载云盘端
其实完成前面的操作我们就可以在Colab中敲写代码或者输入一些系统命令了,但是我们现在连接的虚拟机是和Google Drive脱离的,也就是说我们跑的程序无法使用谷歌云盘里的文件,这就非常受限制了。所以我们一般需要将谷歌云盘看作是虚拟机中的一个硬盘挂载,这样我们就可以使用虚拟机轻松访问谷歌云盘。
挂载Google Drive代码:
方法一.
# 指定Google Drive云端硬盘的根目录,名为drive
!mkdir -p drive
!google-drive-ocamlfuse drive
上面的方法实际是在虚拟机上安装谷歌云盘!如果不行可以尝试方法二
方法二.
# Load the Drive helper and mount
from google.colab import drive
# This will prompt for authorization.
drive.mount('/content/drive')
输入授权码即可。挂载完成后在虚拟机中会多出一个文件夹"drive",用!ls命令查看。
3.配置深度学习平台
其实在colab里面已经默认安装有最新版的pytorch了,如果不放心可以自己手动安装一下,安装方式为:
!pip3 install https://download.pytorch.org/whl/cu80/torch-1.0.1.post2-cp36-cp36m-linux_x86_64.whl
!pip3 install torchvision
除了pytorch外,colab还自带了tensorflow最新版和其他大量的第三方库,如果没有版本要求基本上不用自己手动去安装。下面直接进入主题,用colab训练faster-rcnn。
四、用colab训练faster-rcnn
项目地址:https://github.com/jwyang/faster-rcnn.pytorch/tree/pytorch-1.0
注意:进入项目之后会发现有4个branchs,选择pytorch-1.0这个branch,选错branch会导致编译错误。
然后git clone这个仓库到你的colab中,为了保险起见,clone的时候加上分支控制-b pytorch-1.0即:
!git clone -b pytorch-1.0 https://github.com/jwyang/faster-rcnn.pytorch.git
这里有一点要注意,不能直接使用cd改变路径,需要使用python的方法,如下
import os
os.chdir('faster-rcnn.pytorch')
!ls

创建新文件夹data并下载预训练模型
!mkdir data
os.chdir('data')
!mkdir pretrained_model
os.chdir('pretrained_model')
# 下载预训练模型res101
!wget https://filebox.ece.vt.edu/~jw2yang/faster-rcnn/pretrained-base-models/resnet101_caffe.pth
# 下载预训练模型vgg16
!wget https://filebox.ece.vt.edu/~jw2yang/faster-rcnn/pretrained-base-models/vgg16_caffe.pth
预训练模型下载好以后,返回上一级路径data,然后下载训练集voc2007
os.chdir('../') #返回上一级目录即data/下
# 下载数据集
!wget http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCtrainval_06-Nov-2007.tar
!wget http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCtest_06-Nov-2007.tar
!wget http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCdevkit_08-Jun-2007.tar
# 解压缩
!tar xvf VOCtrainval_06-Nov-2007.tar
!tar xvf VOCtest_06-Nov-2007.tar
!tar xvf VOCdevkit_08-Jun-2007.tar
# 建立软连接
!ln -s $VOCdevkit VOCdevkit2007 #注意!如果上面解压缩得到的文件夹名字为"VOCdevdit",要将其改为“VOCdevdit2007",否则后面会报错。
我在删除的时候出现了无法删除的错误,只能用命令行删除,如下:
首先进入到VOCdevkit2007文件下
import os
os.chdir('data')
然后输入
!rm -rf VOCdevkit2007
将VOCdevkit2007删除,接着就可以将VOCdevkit改为VOCdevkit2007了。
回到上一级路径,然后进入lib中进行编译(在这一步经常会出错,博主本人在这里遇到各种错误并解决了,如果你也遇到错误了欢迎与我交流)
os.chdir('../lib')
!python setup.py build develop
完成后如下图所示
编译成功后,就可以开始训练了。
训练参数可以参考下表配置
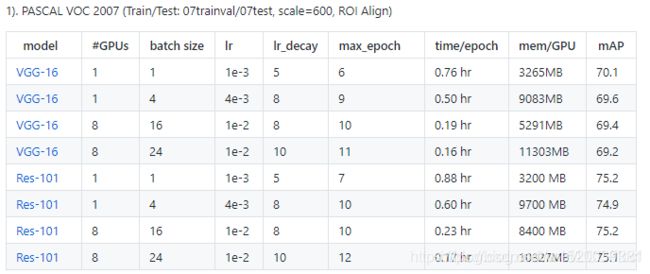
我这里的训练参数使用了表格的倒数三行的参数。
训练代码(参考):
!CUDA_VISIBLE_DEVICES=0 python trainval_net.py \
--dataset pascal_voc \
--net res101 \
--bs 4 \
--nw 0 \
--lr 0.004 \
--lr_decay_step 8 \
--epochs 10 \
--cuda
其中“CUDA_VISIBLE_DEVICES”指代了gpu的id,这得看你实验室服务器哪块gpu是闲置的。
“–dataset”指代你跑得数据集名称,我们就以pascal-voc为例。
“–net”指代你的backbone网络是啥,我们以res101为例。
"–bs"指的batch size。
“–nw”指的是worker number,取决于你的Gpu能力,我用的是Titan Xp 12G,所以选择4。稍微差一些的gpu可以选小一点的值。
“–cuda”指的是使用gpu。
在输入这个代码前,要先到这个文件的目录底下,命令如下
import os
os.chdir('../')
完成输入!pwd查看所在目录级别

然后进入训练阶段,没报错就会输出以下内容(如报错cannot import name ‘imread’ from 'scipy.misc’往下翻)
Called with args:
Namespace(batch_size=4, checkepoch=1, checkpoint=0, checkpoint_interval=10000, checksession=1, class_agnostic=False, cuda=True, dataset='pascal_voc', disp_interval=100, large_scale=False, lr=0.004, lr_decay_gamma=0.1, lr_decay_step=8, mGPUs=False, max_epochs=10, net='res101', num_workers=0, optimizer='sgd', resume=False, save_dir='models', session=1, start_epoch=1, use_tfboard=False)
Using config:
{
'ANCHOR_RATIOS': [0.5, 1, 2],
'ANCHOR_SCALES': [8, 16, 32],
'CROP_RESIZE_WITH_MAX_POOL': False,
'CUDA': False,
'DATA_DIR': '/content/drive/My Drive/faster-rcnn.pytorch/data',
'DEDUP_BOXES': 0.0625,
'EPS': 1e-14,
'EXP_DIR': 'res101',
'FEAT_STRIDE': [16],
'GPU_ID': 0,
'MATLAB': 'matlab',
'MAX_NUM_GT_BOXES': 20,
'MOBILENET': {
'DEPTH_MULTIPLIER': 1.0,
'FIXED_LAYERS': 5,
'REGU_DEPTH': False,
'WEIGHT_DECAY': 4e-05},
'PIXEL_MEANS': array([[[102.9801, 115.9465, 122.7717]]]),
'POOLING_MODE': 'align',
'POOLING_SIZE': 7,
'RESNET': {
'FIXED_BLOCKS': 1, 'MAX_POOL': False},
'RNG_SEED': 3,
'ROOT_DIR': '/content/drive/My Drive/faster-rcnn.pytorch',
'TEST': {
'BBOX_REG': True,
'HAS_RPN': True,
'MAX_SIZE': 1000,
'MODE': 'nms',
'NMS': 0.3,
'PROPOSAL_METHOD': 'gt',
'RPN_MIN_SIZE': 16,
'RPN_NMS_THRESH': 0.7,
'RPN_POST_NMS_TOP_N': 300,
'RPN_PRE_NMS_TOP_N': 6000,
'RPN_TOP_N': 5000,
'SCALES': [600],
'SVM': False},
'TRAIN': {
'ASPECT_GROUPING': False,
'BATCH_SIZE': 128,
'BBOX_INSIDE_WEIGHTS': [1.0, 1.0, 1.0, 1.0],
'BBOX_NORMALIZE_MEANS': [0.0, 0.0, 0.0, 0.0],
'BBOX_NORMALIZE_STDS': [0.1, 0.1, 0.2, 0.2],
'BBOX_NORMALIZE_TARGETS': True,
'BBOX_NORMALIZE_TARGETS_PRECOMPUTED': True,
'BBOX_REG': True,
'BBOX_THRESH': 0.5,
'BG_THRESH_HI': 0.5,
'BG_THRESH_LO': 0.0,
'BIAS_DECAY': False,
'BN_TRAIN': False,
'DISPLAY': 20,
'DOUBLE_BIAS': False,
'FG_FRACTION': 0.25,
'FG_THRESH': 0.5,
'GAMMA': 0.1,
'HAS_RPN': True,
'IMS_PER_BATCH': 1,
'LEARNING_RATE': 0.001,
'MAX_SIZE': 1000,
'MOMENTUM': 0.9,
'PROPOSAL_METHOD': 'gt',
'RPN_BATCHSIZE': 256,
'RPN_BBOX_INSIDE_WEIGHTS': [1.0, 1.0, 1.0, 1.0],
'RPN_CLOBBER_POSITIVES': False,
'RPN_FG_FRACTION': 0.5,
'RPN_MIN_SIZE': 8,
'RPN_NEGATIVE_OVERLAP': 0.3,
'RPN_NMS_THRESH': 0.7,
'RPN_POSITIVE_OVERLAP': 0.7,
'RPN_POSITIVE_WEIGHT': -1.0,
'RPN_POST_NMS_TOP_N': 2000,
'RPN_PRE_NMS_TOP_N': 12000,
'SCALES': [600],
'SNAPSHOT_ITERS': 5000,
'SNAPSHOT_KEPT': 3,
'SNAPSHOT_PREFIX': 'res101_faster_rcnn',
'STEPSIZE': [30000],
'SUMMARY_INTERVAL': 180,
'TRIM_HEIGHT': 600,
'TRIM_WIDTH': 600,
'TRUNCATED': False,
'USE_ALL_GT': True,
'USE_FLIPPED': True,
'USE_GT': False,
'WEIGHT_DECAY': 0.0001},
'USE_GPU_NMS': True}
Loaded dataset `voc_2007_trainval` for training
Set proposal method: gt
Appending horizontally-flipped training examples...
wrote gt roidb to /content/drive/My Drive/faster-rcnn.pytorch/data/cache/voc_2007_trainval_gt_roidb.pkl
done
Preparing training data...
done
before filtering, there are 10022 images...
after filtering, there are 10022 images...
10022 roidb entries
Loading pretrained weights from data/pretrained_model/resnet101_caffe.pth
[session 1][epoch 1][iter 0/2505] loss: 4.4889, lr: 4.00e-03
fg/bg=(86/426), time cost: 0.631022
rpn_cls: 0.7647, rpn_box: 0.1163, rcnn_cls: 3.2056, rcnn_box 0.4022
[session 1][epoch 1][iter 100/2505] loss: 1.6482, lr: 4.00e-03
fg/bg=(76/436), time cost: 48.210583
rpn_cls: 0.1818, rpn_box: 0.0935, rcnn_cls: 0.5636, rcnn_box 0.3963
[session 1][epoch 1][iter 200/2505] loss: 1.3492, lr: 4.00e-03
fg/bg=(96/416), time cost: 48.308645
rpn_cls: 0.1621, rpn_box: 0.0816, rcnn_cls: 0.5371, rcnn_box 0.4290
[session 1][epoch 1][iter 300/2505] loss: 1.2802, lr: 4.00e-03
fg/bg=(78/434), time cost: 48.690686
rpn_cls: 0.1772, rpn_box: 0.0466, rcnn_cls: 0.4028, rcnn_box 0.3361
[session 1][epoch 1][iter 400/2505] loss: 1.1955, lr: 4.00e-03
fg/bg=(85/427), time cost: 47.541170
rpn_cls: 0.1286, rpn_box: 0.0465, rcnn_cls: 0.5260, rcnn_box 0.3859
[session 1][epoch 1][iter 500/2505] loss: 1.0540, lr: 4.00e-03
fg/bg=(115/397), time cost: 48.236158
rpn_cls: 0.1394, rpn_box: 0.0556, rcnn_cls: 0.2973, rcnn_box 0.4523
[session 1][epoch 1][iter 600/2505] loss: 1.0687, lr: 4.00e-03
fg/bg=(107/405), time cost: 48.574353
rpn_cls: 0.1539, rpn_box: 0.1052, rcnn_cls: 0.5257, rcnn_box 0.4881
[session 1][epoch 1][iter 700/2505] loss: 1.0978, lr: 4.00e-03
fg/bg=(109/403), time cost: 48.813421
rpn_cls: 0.2389, rpn_box: 0.0672, rcnn_cls: 0.4576, rcnn_box 0.4189
[session 1][epoch 1][iter 800/2505] loss: 1.0128, lr: 4.00e-03
fg/bg=(106/406), time cost: 48.740548
rpn_cls: 0.1770, rpn_box: 0.0782, rcnn_cls: 0.2983, rcnn_box 0.4205
[session 1][epoch 1][iter 900/2505] loss: 0.9556, lr: 4.00e-03
fg/bg=(111/401), time cost: 48.509384
rpn_cls: 0.2041, rpn_box: 0.0592, rcnn_cls: 0.7014, rcnn_box 0.4860
[session 1][epoch 1][iter 1000/2505] loss: 0.9686, lr: 4.00e-03
fg/bg=(85/427), time cost: 47.961507
rpn_cls: 0.2358, rpn_box: 0.2542, rcnn_cls: 0.3569, rcnn_box 0.3245
[session 1][epoch 1][iter 1100/2505] loss: 0.9632, lr: 4.00e-03
fg/bg=(104/408), time cost: 48.437697
rpn_cls: 0.1242, rpn_box: 0.0423, rcnn_cls: 0.3338, rcnn_box 0.4645
[session 1][epoch 1][iter 1200/2505] loss: 0.9806, lr: 4.00e-03
fg/bg=(91/421), time cost: 48.610538
rpn_cls: 0.1442, rpn_box: 0.0555, rcnn_cls: 0.4080, rcnn_box 0.3023
[session 1][epoch 1][iter 1300/2505] loss: 0.9174, lr: 4.00e-03
fg/bg=(103/409), time cost: 48.365453
rpn_cls: 0.0811, rpn_box: 0.0445, rcnn_cls: 0.2094, rcnn_box 0.3271
[session 1][epoch 1][iter 1400/2505] loss: 0.9440, lr: 4.00e-03
fg/bg=(108/404), time cost: 48.756201
rpn_cls: 0.1123, rpn_box: 0.0629, rcnn_cls: 0.3999, rcnn_box 0.3369
[session 1][epoch 1][iter 1500/2505] loss: 0.9464, lr: 4.00e-03
fg/bg=(89/423), time cost: 48.500985
rpn_cls: 0.1723, rpn_box: 0.0166, rcnn_cls: 0.2288, rcnn_box 0.2641
[session 1][epoch 1][iter 1600/2505] loss: 0.8660, lr: 4.00e-03
fg/bg=(101/411), time cost: 48.771032
rpn_cls: 0.1530, rpn_box: 0.0996, rcnn_cls: 0.2945, rcnn_box 0.3139
[session 1][epoch 1][iter 1700/2505] loss: 0.8878, lr: 4.00e-03
fg/bg=(109/403), time cost: 48.641863
rpn_cls: 0.1419, rpn_box: 0.0537, rcnn_cls: 0.3297, rcnn_box 0.4069
[session 1][epoch 1][iter 1800/2505] loss: 0.8100, lr: 4.00e-03
fg/bg=(88/424), time cost: 48.417810
rpn_cls: 0.0559, rpn_box: 0.1918, rcnn_cls: 0.3625, rcnn_box 0.2613
[session 1][epoch 1][iter 1900/2505] loss: 0.8600, lr: 4.00e-03
fg/bg=(113/399), time cost: 48.563857
rpn_cls: 0.0154, rpn_box: 0.0383, rcnn_cls: 0.2815, rcnn_box 0.2234
[session 1][epoch 1][iter 2000/2505] loss: 0.8559, lr: 4.00e-03
fg/bg=(122/390), time cost: 48.363470
rpn_cls: 0.1922, rpn_box: 0.4808, rcnn_cls: 0.2923, rcnn_box 0.3362
[session 1][epoch 1][iter 2100/2505] loss: 0.8183, lr: 4.00e-03
fg/bg=(107/405), time cost: 48.086220
rpn_cls: 0.0638, rpn_box: 0.1064, rcnn_cls: 0.3839, rcnn_box 0.2680
[session 1][epoch 1][iter 2200/2505] loss: 0.8315, lr: 4.00e-03
fg/bg=(128/384), time cost: 48.608972
rpn_cls: 0.1844, rpn_box: 0.1249, rcnn_cls: 0.6824, rcnn_box 0.4886
[session 1][epoch 1][iter 2300/2505] loss: 0.8104, lr: 4.00e-03
fg/bg=(128/384), time cost: 49.013214
rpn_cls: 0.2232, rpn_box: 0.0397, rcnn_cls: 0.5556, rcnn_box 0.5165
[session 1][epoch 1][iter 2400/2505] loss: 0.8279, lr: 4.00e-03
fg/bg=(115/397), time cost: 48.389256
rpn_cls: 0.2307, rpn_box: 0.3071, rcnn_cls: 0.2680, rcnn_box 0.3603
[session 1][epoch 1][iter 2500/2505] loss: 0.7977, lr: 4.00e-03
fg/bg=(103/409), time cost: 48.490996
rpn_cls: 0.1070, rpn_box: 0.0859, rcnn_cls: 0.1753, rcnn_box 0.3318
save model: models/res101/pascal_voc/faster_rcnn_1_1_2504.pth
[session 1][epoch 2][iter 0/2505] loss: 0.6844, lr: 4.00e-03
fg/bg=(128/384), time cost: 0.499750
rpn_cls: 0.0505, rpn_box: 0.0330, rcnn_cls: 0.2169, rcnn_box 0.3840
[session 1][epoch 2][iter 100/2505] loss: 0.7295, lr: 4.00e-03
fg/bg=(81/431), time cost: 49.123291
rpn_cls: 0.1039, rpn_box: 0.0405, rcnn_cls: 0.1429, rcnn_box 0.2362
[session 1][epoch 2][iter 200/2505] loss: 0.7193, lr: 4.00e-03
fg/bg=(103/409), time cost: 48.159855
rpn_cls: 0.1081, rpn_box: 0.0726, rcnn_cls: 0.2107, rcnn_box 0.2215
[session 1][epoch 2][iter 300/2505] loss: 0.6917, lr: 4.00e-03
fg/bg=(122/390), time cost: 48.052244
rpn_cls: 0.1752, rpn_box: 0.0425, rcnn_cls: 0.2849, rcnn_box 0.3116
[session 1][epoch 2][iter 400/2505] loss: 0.7373, lr: 4.00e-03
fg/bg=(82/430), time cost: 49.114329
rpn_cls: 0.0330, rpn_box: 0.0310, rcnn_cls: 0.1921, rcnn_box 0.1565
[session 1][epoch 2][iter 500/2505] loss: 0.6723, lr: 4.00e-03
fg/bg=(106/406), time cost: 48.423283
rpn_cls: 0.1797, rpn_box: 0.0617, rcnn_cls: 0.2663, rcnn_box 0.2916
[session 1][epoch 2][iter 600/2505] loss: 0.6936, lr: 4.00e-03
fg/bg=(90/422), time cost: 48.457257
rpn_cls: 0.0250, rpn_box: 0.0115, rcnn_cls: 0.0861, rcnn_box 0.1890
[session 1][epoch 2][iter 700/2505] loss: 0.6561, lr: 4.00e-03
fg/bg=(89/423), time cost: 48.276662
rpn_cls: 0.0705, rpn_box: 0.0531, rcnn_cls: 0.1684, rcnn_box 0.1714
[session 1][epoch 2][iter 800/2505] loss: 0.6618, lr: 4.00e-03
fg/bg=(128/384), time cost: 48.745029
rpn_cls: 0.1439, rpn_box: 0.0519, rcnn_cls: 0.2942, rcnn_box 0.2803
[session 1][epoch 2][iter 900/2505] loss: 0.6984, lr: 4.00e-03
fg/bg=(110/402), time cost: 49.094426
rpn_cls: 0.2028, rpn_box: 0.1617, rcnn_cls: 0.2852, rcnn_box 0.2869
[session 1][epoch 2][iter 1000/2505] loss: 0.6669, lr: 4.00e-03
fg/bg=(75/437), time cost: 47.975516
rpn_cls: 0.0783, rpn_box: 0.0166, rcnn_cls: 0.1740, rcnn_box 0.1564
[session 1][epoch 2][iter 1100/2505] loss: 0.7015, lr: 4.00e-03
fg/bg=(123/389), time cost: 47.807172
rpn_cls: 0.0908, rpn_box: 0.0418, rcnn_cls: 0.2975, rcnn_box 0.2434
[session 1][epoch 2][iter 1200/2505] loss: 0.6982, lr: 4.00e-03
fg/bg=(66/446), time cost: 48.006961
rpn_cls: 0.0431, rpn_box: 0.0348, rcnn_cls: 0.2830, rcnn_box 0.1955
[session 1][epoch 2][iter 1300/2505] loss: 0.6325, lr: 4.00e-03
fg/bg=(85/427), time cost: 50.348251
rpn_cls: 0.0769, rpn_box: 0.0946, rcnn_cls: 0.3239, rcnn_box 0.2578
[session 1][epoch 2][iter 1400/2505] loss: 0.6572, lr: 4.00e-03
fg/bg=(128/384), time cost: 48.929197
rpn_cls: 0.1393, rpn_box: 0.1332, rcnn_cls: 0.2521, rcnn_box 0.3753
[session 1][epoch 2][iter 1500/2505] loss: 0.6702, lr: 4.00e-03
fg/bg=(83/429), time cost: 47.852913
rpn_cls: 0.0518, rpn_box: 0.0096, rcnn_cls: 0.1449, rcnn_box 0.0970
[session 1][epoch 2][iter 1600/2505] loss: 0.6550, lr: 4.00e-03
fg/bg=(84/428), time cost: 48.381806
rpn_cls: 0.1668, rpn_box: 0.1389, rcnn_cls: 0.2901, rcnn_box 0.2763
[session 1][epoch 2][iter 1700/2505] loss: 0.6845, lr: 4.00e-03
fg/bg=(111/401), time cost: 48.081511
rpn_cls: 0.1094, rpn_box: 0.0284, rcnn_cls: 0.3238, rcnn_box 0.2787
[session 1][epoch 2][iter 1800/2505] loss: 0.6928, lr: 4.00e-03
fg/bg=(120/392), time cost: 48.595775
rpn_cls: 0.0785, rpn_box: 0.0484, rcnn_cls: 0.2455, rcnn_box 0.2640
[session 1][epoch 2][iter 1900/2505] loss: 0.6299, lr: 4.00e-03
fg/bg=(83/429), time cost: 48.641484
rpn_cls: 0.0471, rpn_box: 0.0094, rcnn_cls: 0.1121, rcnn_box 0.2505
[session 1][epoch 2][iter 2000/2505] loss: 0.6384, lr: 4.00e-03
fg/bg=(128/384), time cost: 49.008403
rpn_cls: 0.1931, rpn_box: 0.0428, rcnn_cls: 0.5773, rcnn_box 0.2935
[session 1][epoch 2][iter 2100/2505] loss: 0.6534, lr: 4.00e-03
fg/bg=(128/384), time cost: 48.640137
rpn_cls: 0.0835, rpn_box: 0.0698, rcnn_cls: 0.4252, rcnn_box 0.2530
[session 1][epoch 2][iter 2200/2505] loss: 0.6461, lr: 4.00e-03
fg/bg=(96/416), time cost: 48.904739
rpn_cls: 0.0456, rpn_box: 0.0212, rcnn_cls: 0.2345, rcnn_box 0.4018
[session 1][epoch 2][iter 2300/2505] loss: 0.6130, lr: 4.00e-03
fg/bg=(128/384), time cost: 48.537663
rpn_cls: 0.1542, rpn_box: 0.1570, rcnn_cls: 0.2312, rcnn_box 0.2815
[session 1][epoch 2][iter 2400/2505] loss: 0.6240, lr: 4.00e-03
fg/bg=(95/417), time cost: 49.230861
rpn_cls: 0.0618, rpn_box: 0.0613, rcnn_cls: 0.1909, rcnn_box 0.1798
[session 1][epoch 2][iter 2500/2505] loss: 0.6309, lr: 4.00e-03
fg/bg=(111/401), time cost: 49.703421
rpn_cls: 0.0674, rpn_box: 0.0976, rcnn_cls: 0.2992, rcnn_box 0.1979
save model: models/res101/pascal_voc/faster_rcnn_1_2_2504.pth
[session 1][epoch 3][iter 0/2505] loss: 0.8766, lr: 4.00e-03
fg/bg=(110/402), time cost: 0.490823
rpn_cls: 0.1830, rpn_box: 0.1403, rcnn_cls: 0.2586, rcnn_box 0.2947
如果出错,出现以下情况

这是scipy的库版本太高,改成1.2.1,输入以下命令
!pip install scipy==1.2.1
安装好后,就可以运行,如果还有其他错误,可以自行百度,或者去到这个项目的github的issue去查看相关错误,基本上按着我的文章来错误无非就是位置不对、库的版本太高!
注意:colab好像一次只能用12个小时,12个小时还没训练完的话会自动停止训练,并且资源会被谷歌回收,也就是说所有结果都会被清空,因此,请注意你的训练时长!
五、总结
1、可以把Colab看成是一台带有GPU的Ubuntu虚拟机,只不过我们只能用命令行的方式操作它。你可以选择执行系统命令,亦或是直接编写运行python代码。
2、挂载完Google Drive,会在虚拟机里生成一个drive文件夹,直接将Google Drive当成是一块硬盘即可。访问drive文件夹里的文件,就是在访问你的Google Drive里的文件。
3、Colab最多连续使用12小时,超过时间系统会强制掐断正在运行的程序并收回占用的虚拟机。(好像再次连接到虚拟机后,虚拟机是被清空的状态,需要重新配置和安装库等等)
4、请使用科学上网
本文章有一部分转载自https://blog.csdn.net/LCCFlccf/article/details/89302730,然后我在它的基础上跑了一遍,加上了我遇到的问题!有什么问题,可以私信交流!
接下来,会用自己的数据来训练!