Openpose+Tensorflow 这样实现人体姿态估计 | 代码干货


作者 | 李秋键
出品 | AI科技大本营(ID:rgznai100)
人体姿态估计指从单个 RGB 图像中精确地估计出人体的位置以及检测骨骼关键点的位置。人体姿态估计是计算机视觉领域的研究热点,是诸多计算机视觉任务的基础,如动作分类、异常行为检测、自动驾驶等。
Openpose 项目库运用流行的深度学习算法,能快速地识别图像中单人及多人的二维姿态,通过学习检测图像中人物的关键点位置,从而不依赖于图像中的局部特征完成人物目标检测,即使在图像噪声较大下,可准确提取人物的关键点,然后使用建模重构的方式对学习检测到的像中人物关键点位置进行姿态特征的提取,能更有效地保证精度及连续性。
本项目通过使用 Tensorflow 搭建 Openpose 环境实现对人体18个骨骼点的实时监测。其最终实现的效果如下图可见:


基本介绍
姿态估计分为单人姿态估计和多人姿态估计两大类,前者根据给定边界框的裁剪图像预测一个目标的所有人体关键点,后者需要进一步估计一幅图像中所有人的姿态。其中姿态识别的发展历程如下图可见:
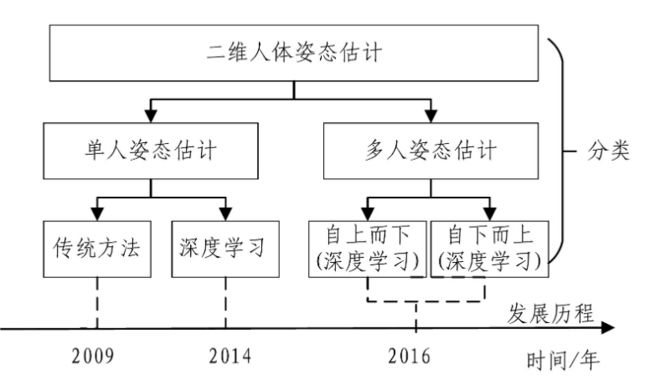
Openpose 作为多人姿态估计算法比单人姿态估计更加复杂,不仅要扫描整个图像以寻找可能的人体关节候选区域,还要生成关节热图来进一步预测对应关键点的真实位置。同时还要根据当前身体关节和相邻层中每个身体部位之间的置信度,来确定哪些关节与当前关节属于同一个人。
1.1 环境要求
平台:Python3.6.5+Windows
主要用的库:opencv-python模块、Numpy模块、TensorFlow模块。
1.2 应用领域
人体姿态估计在人机交互、智能监控、虚拟现实以及运动分析等领域有着广阔的应用前景。
人机交互:基于姿态估计的人机交互可应用于日常生活中,例如,在我们日常使用的快手、抖音和微视等视频软件中,一些动作特效就是由姿态估计技术完成的,体感游戏也依赖于姿态估计技术。
智能监控:人体姿态估计目前最为广泛的应用是在智能监控中。随着人们安防意识的提升以及监控技术的日益成熟,智能监控系统的应用领域在不断扩大。智能监控与普通监控的区别主要在于其将人体姿态估计技术嵌入视频服务器中,运用算法估计、判断监控画面场景中的人体姿态,提取其中的关键信息,当出现异常行为时及时向用户发出警报。
其他应用:除了人机交互和智能监控,姿态估计还可应用于体育项目、队列评分、智能驾驶、零售等。例如在体育领域,人工智能教练系统来帮助运动员调整专业动作,为运动员提供个性化的运动训练体验

算法流程
Openpose算法姿态提取算法的流程如下图所示,可概括为以下几步:
(a)输入一个w×h的彩色人物图像;
(b)前馈网络对检测目标的关键点位置进行预测,并得到其二维置信度映射S以及一组2D矢量向量场L;
(c)用S和L来编码检测目标各部间的关联向量场;
(d)通过置信度分析检测目标的亲和向量场,最终标示出所有检测目标的2D关键点。

2.1 Openpose网络
Openpose的整体网络结构采用VGG网络作为骨架进行预训练处理。该网络分为两个部分,两部分能同时对提取到的关键点进行预测置信图、编码相邻关键点间的关联向量场并分别回归S和L。
图中上半部分即第一分支用以预测置信图,下半部分即第二分支用以预测关联向量场。每回归一次S和L即为完成一轮迭代预测,通过连续的t∈(1,⋯,T)轮迭代,就能形成整个预测网络体系结构。
每一阶段统计一次反馈损失函数,并把S、L及F即原始输入连接起来,进而得到下一阶段预测训练的输入。在进行了n轮迭代之后,S能起到一定程度的区分预测网络体系左右结构的作用,迭代次数越多其区分程度越显著。
其中网络模型代码如下:
def setup(self):
min_depth = 8
depth = lambda d: max(int(d *self.conv_width), min_depth)
depth2 = lambda d: max(int(d *self.conv_width2), min_depth)
with tf.variable_scope(None,'MobilenetV1'):
(self.feed('image')
.convb(3, 3, depth(32), 2,name='Conv2d_0')
.separable_conv(3, 3, depth(64),1, name='Conv2d_1')
.separable_conv(3, 3, depth(128),2, name='Conv2d_2')
.separable_conv(3, 3, depth(128),1, name='Conv2d_3')
.separable_conv(3, 3, depth(256),2, name='Conv2d_4')
.separable_conv(3, 3, depth(256),1, name='Conv2d_5')
.separable_conv(3, 3, depth(512),1, name='Conv2d_6')
.separable_conv(3, 3, depth(512),1, name='Conv2d_7')
.separable_conv(3, 3, depth(512),1, name='Conv2d_8')
# .separable_conv(3, 3, depth(512),1, name='Conv2d_9')
# .separable_conv(3, 3,depth(512), 1, name='Conv2d_10')
# .separable_conv(3, 3,depth(512), 1, name='Conv2d_11')
# .separable_conv(3, 3,depth(1024), 2, name='Conv2d_12')
# .separable_conv(3, 3,depth(1024), 1, name='Conv2d_13')
)
(self.feed('Conv2d_1').max_pool(2, 2,2, 2, name='Conv2d_1_pool'))
(self.feed('Conv2d_7').upsample(2,name='Conv2d_7_upsample'))
(self.feed('Conv2d_1_pool', 'Conv2d_3','Conv2d_7_upsample')
.concat(3, name='feat_concat'))
feature_lv = 'feat_concat'
with tf.variable_scope(None,'Openpose'):
prefix = 'MConv_Stage1'
(self.feed(feature_lv)
.separable_conv(3, 3, depth2(128),1, name=prefix + '_L1_1')
.separable_conv(3, 3, depth2(128),1, name=prefix + '_L1_2')
.separable_conv(3, 3, depth2(128),1, name=prefix + '_L1_3')
.separable_conv(1, 1, depth2(512),1, name=prefix + '_L1_4')
.separable_conv(1, 1, 38, 1,relu=False, name=prefix + '_L1_5'))
(self.feed(feature_lv)
.separable_conv(3, 3, depth2(128),1, name=prefix + '_L2_1')
.separable_conv(3, 3, depth2(128),1, name=prefix + '_L2_2')
.separable_conv(3, 3, depth2(128),1, name=prefix + '_L2_3')
.separable_conv(1, 1, depth2(512),1, name=prefix + '_L2_4')
.separable_conv(1, 1, 19, 1,relu=False, name=prefix + '_L2_5'))
for stage_id inrange(self.num_refine):
prefix_prev = 'MConv_Stage%d' %(stage_id + 1)
prefix = 'MConv_Stage%d' %(stage_id + 2)
(self.feed(prefix_prev +'_L1_5',
prefix_prev +'_L2_5',
feature_lv)
.concat(3, name=prefix +'_concat')
.separable_conv(7, 7,depth2(128), 1, name=prefix + '_L1_1')
.separable_conv(7, 7,depth2(128), 1, name=prefix + '_L1_2')
.separable_conv(7, 7,depth2(128), 1, name=prefix + '_L1_3')
.separable_conv(1, 1,depth2(128), 1, name=prefix + '_L1_4')
.separable_conv(1, 1, 38, 1, relu=False,name=prefix + '_L1_5'))
(self.feed(prefix + '_concat')
.separable_conv(7, 7,depth2(128), 1, name=prefix + '_L2_1')
.separable_conv(7, 7,depth2(128), 1, name=prefix + '_L2_2')
.separable_conv(7, 7,depth2(128), 1, name=prefix + '_L2_3')
.separable_conv(1, 1,depth2(128), 1, name=prefix + '_L2_4')
.separable_conv(1, 1, 19, 1,relu=False, name=prefix + '_L2_5'))
# final result
(self.feed('MConv_Stage%d_L2_5' %self.get_refine_num(),
'MConv_Stage%d_L1_5' %self.get_refine_num())
.concat(3, name='concat_stage7'))

2.2 模型训练
通过 TensorFlow 对姿态训练,官方提供了三个模型,分别为:
Cmu:基于模型的VGG预训练网络。其中使用TensorFlow将Caffe格式的Weights转换为tensorflow格式。
Dsconv:与cmu版本相同的架构,除了移动网络的深度可分离卷积。使用“迁移学习”来训练它,但它提供的速度和准确性都相对较差。
Mobilenet:在mobilenet模型的基础上,使用12个卷积层作为特征提取层。为了对小人物进行改进,对体系结构进行了微小的修改。根据网络规模参数学习三种模型。


算法测试
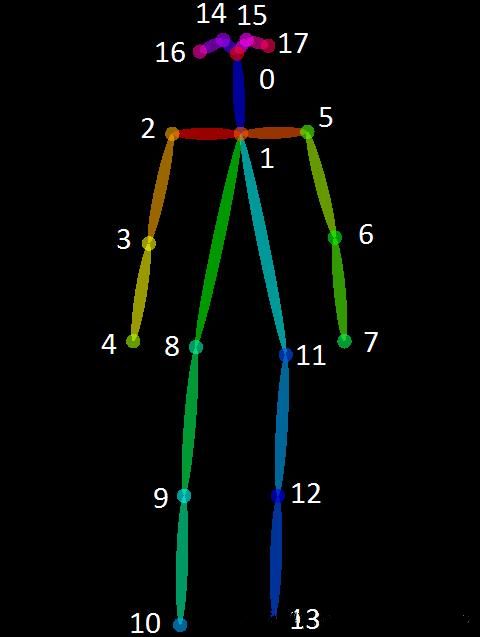
3.1 人体关键点:
Openpose算法针对已有"bottom-up"方法缺点:
(1)未利用全局上下文先验信息,也即图片中其他人的身体关键点信息;(2)将关键点对应到不同的人物个体,算法复杂度太高。提出了“Part Affinity Fields (PAFs)”方法,即每个像素是2D的向量,用于表征位置和方向信息。基于检测出的关节点和关节联通区域,使用greedy inference算法,可以将这些关节点快速对应到不同人物个体。
其中18个关键点对应位置分别如下:
3.2 算法测试:
其中image参数为所需要测试的图片路径;model为使用的测试模型,默认为cmu模型;通过直接运行提供的源码中的test.py即可得到运行效果。
parser =argparse.ArgumentParser(description='tf-pose-estimation run')
parser.add_argument('--image', type=str, default='./images/p2.jpg')
parser.add_argument('--model', type=str, default='cmu',
help='cmu / mobilenet_thin/ mobilenet_v2_large / mobilenet_v2_small')
parser.add_argument('--resize', type=str, default='0x0',
help='if provided, resizeimages before they are processed. '
'default=0x0,Recommends : 432x368 or 656x368 or 1312x736 ')
parser.add_argument('--resize-out-ratio', type=float, default=4.0,
help='if provided, resizeheatmaps before they are post-processed. default=1.0')
args = parser.parse_args()
w, h = model_wh(args.resize)
if w == 0 or h == 0:
e =TfPoseEstimator(get_graph_path(args.model), target_size=(432, 368))
else:
e =TfPoseEstimator(get_graph_path(args.model), target_size=(w, h))
# estimate human posesfrom a single image !
image =common.read_imgfile(args.image, None, None)
image=cv2.resize(image,(600,400))
cv2.imshow("2",image)
if image is None:
logger.error('Image can not beread, path=%s' % args.image)
sys.exit(-1)
t = time.time()
humans = e.inference(image, resize_to_default=(w > 0 and h > 0), upsample_size=args.resize_out_ratio)
elapsed = time.time() - t
logger.info('inference image: %sin %.4f seconds.' % (args.image, elapsed))
image = TfPoseEstimator.draw_humans(image, humans, imgcopy=False)
cv2.imshow("1",image)
cv2.waitKey(0)

代码:https://pan.baidu.com/s/1vkc1EQuaAUMqoaegkdZ_pA
提取码:i46w
作者简介:李秋键,CSDN博客专家,CSDN达人课作者。硕士在读于中国矿业大学,开发有taptap竞赛获奖等。
在评论区留言你对Openpose、Tensorflow的学习心得
AI科技大本营将选出三名优质留言
携手【北京大学出版社】送出
《TensorFlow深度学习实战大全》一本
截至7月13日14:00点



更多精彩推荐
Windows 11 上手机!小米 8、一加 6T、微软 Lumia 950 XL 都可以运行
深度学习教你重建赵丽颖的三维人脸
Arm收购进展、元宇宙、GPU涨价……听听黄仁勋怎么说
点分享点收藏点点赞点在看