神经网络结构搜索NAS简述
导读:自动化机器学习(AutoML)变得越来越火,是机器学习下个发展方向之一。其中的神经网络结构搜索(NAS)是其中重要的技术之一。
这是小编的其他文章,希望对大家有所帮助,点击即可阅读
人工智能常用的十大算法 人工智能数学基础(二)十大经典算法(图像处理)
为了方便大家学习交流,我建了一个扣裙:966367816
另外我还整理了整整python人工智能学习笔记、课程视频、面试宝典一并可以免费分享给大家!扫描文末二维码加V免费咨询学习问题领取资料
1、基于强化学习的NAS
这里介绍的论文是Zoph, Barret, and Quoc V. Le. “Neural Architecture Search with Reinforcement Learning.” ICLR, 2016. 这篇论文的大体框架和思路如下图所示。在这篇论文中作者使用一个RNN作为智能体。作者考虑到神经网络的结构和连接可以用一个可变长度的字符串表示,这样可以用RNN生成这样的字符串。RNN采样生成了这样的字符串,一个网络,即子网络(child network)就被确定了。训练这个子网络,得到验证集在这个网络上的准确率,作为奖励信号。然后根据奖励计算策略梯度,更新RNN。在下一轮迭代,RNN会给出可能在验证集上准确率高的一个网络结构。也就是说,RNN会随着时间提升它的搜索质量。

首先作者假设要生成一个前向的只包含卷积的网络(没有跨连接)。使用RNN可以生成卷积层的超参数,超参数表示为一个标记序列:

RNN会预测每一层的滤波器的高度、宽度,步长的高度、宽度,和滤波器个数,一个5个参数。每一个预测是通过softmax分类器实现的,这个时间步的预测会作为下个时间步的输入。当层数达到一个特定的值,这个生成的过程就会停止。这个值会随着训练过程增加。一旦RNN生成了一个结构,即子网络,这个子网络就会被训练,验证集的准确率被记录下来被作为奖励。然后控制器RNN的参数
![]()
被更新以生成期望验证集准确率最大的结构。
RNN生成一个子网络后,其生成的标记序列可以被看作一系列动作

。验证集在其上取得的准确率作为奖励R RR,然后训练RNN。为了找到最优的结构,我们网RNN取最大化期望奖励

:
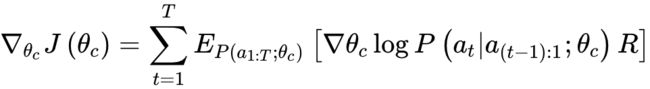
上式的经验估计如下:

这里m是控制器在训练过程中一个batch生成的子网络数量,T是生成的每个子网络的超参数数量,
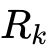
是第k个子网络在验证集上的准确率。上述的估计是无偏的,还会有很高的方差,为了降低方差,作者使用了baseline function:
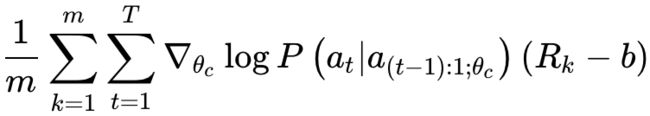
这里b是之前子网络准确率的指数移动平均值。
上面介绍的就是基于强化学习NAS的基本原理,不过原论文中还有带跨连接(skip)网络的搜索和RNN的搜索,感兴趣的读者可以继续阅读原论文。基于强化学习的方法是NAS的开创之作,但缺点也很明显:每次生成新的网络结构需要重新训练,非常耗时,且策略梯度不一定能达到很好的结果。
2、基于遗传算法的NAS
这节介绍的论文是Real, Esteban, et al. “Large-Scale Evolution of Image Classifiers.” ICML’17 Proceedings of the 34th International Conference on Machine Learning - Volume 70, 2017, pp. 2902–2911. 本文采用遗传算法进行网络的搜索。首先,作者进化出一个神经网络模型的种群,这个种群会包含很多不同的网络模型,其中每个模型即为一个个体。这个模型被训练后在验证集上的准确率为此个体的适应度评估。在每一个进化步中,worker(即计算机)从种群中随机选择两个个体,然后计算并比较其适应度。适应度较差的个体从种群中被移除,较好的个体留下来作为亲本进行下一步的繁殖。繁殖过程中,worker复制这个亲本,然后对其进行变异,即对其进行结构上的修改,修改后的模型称为后代。这个后代被训练然后得到在验证集上的准确率,最后被放回到种群里。
用这样的策略在巨大的搜索空间里寻找最优的分类模型需要巨大的计算量,为此作者提出了一个大规模并行的方法。很多worker在不同的计算机上异步地操作,他们彼此之间不直接通信。他们使用一个共享的文件系统,这里用字典存储了种群的信息,每个字典代表一个个体。相应的操作可以通过修改字典完成,例如,移除一个个体即为字典的重命名。有时会出现这种情况,对于同一个个体,一个worker尝试对其进行修改,但另一个worker可能正在对其进行操作,此时这个worker放弃修改并重新尝试。在这篇论文里,种群的大小是1000个个体,worker的个数总是为种群大小的四分之一。为了在有限的空间内实现长时间的运行,会经常对被移除的个体的字典进行垃圾收集。
对于个体来说,其结构被编码为一个图,我们称之为DNA。在图中,顶点表示3阶张量或激活函数。3阶张量表示图片的长宽和通道数。激活函数可以是带ReLu的批标准化,也可以是简单的线性单元。图的边表示恒等映射或卷积,并包含定义卷积特性的变异了的数值参数。当一个顶点有多个边时,他们的长宽和通道数目可能不一致。为了解决这个问题,选择这些边中的一个作为主要边,这个主要边是非跨连接的。非主要边的激活值以主要边为基准,在长宽这个维度上进行zerothorder插值,在通道这个维度上进行填充或截断。除了图,学习率也被存在DNA里。后代是通过对亲本的复制和变异产生的,这些变异是从预先定义的集合里随机选择的。预先定义的变异集合包括改变学习率、插入卷积、移除卷积、改变步长、改变通道数目等等。上述所有随时选取都是均匀分布的。对于数值型的变异,新的值在现有值附近选取。例如,一个变异作用于一个有10个输出通道的卷积,将会导致一个有5到20个输出通道的卷积(即是原始值的一半到两倍),在此范围内的值都是允许的。对于其他参数也是如此,从而产生一个密集的搜索空间。对于步长,都使用以2为底的log值,以便激活值的形状更容易匹配。原则上,参数没有上限,例如,模型的深度没有限制。参数的密集性和无界性会导致大量可能的网络结构。下图展示了一次搜索的过程,横轴是搜索时间,纵轴是测试集准确率,并且图中列举了四个时刻所搜索到的模型结构的例子。
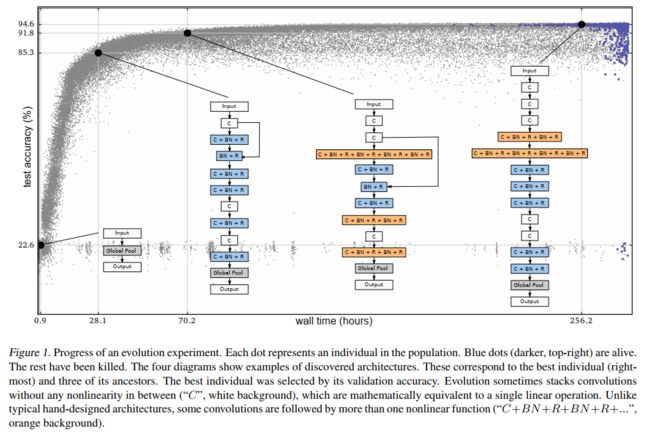
上面介绍的就是基于遗传算法的NAS,但其缺点也是搜索较慢,每次都要重新训网络。
3、One-shot NAS
本节介绍的论文是Bender, Gabriel M., et al. “Understanding and Simplifying One-Shot Architecture Search.” International Conference on Machine Learning, 2018, pp. 550–559. 为了缩短训练时间,one-shot NAS的思路是使用超网络,这个超网络涵盖了搜索空间中所有可能的网络结构,每个子结构都是权值共享的。一个简单的例子如下图所示:
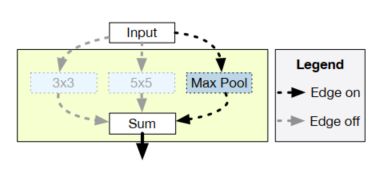
上图中,在网络的某个位置,有3x3卷积、5x5卷积或者最大池化三个操作可以选择,不同于分别训练三个模型,我们训练一个包括了这三个操作的模型(one-shot model),然后在验证阶段,我们选择性地剔除其中两个操作的输出,保留使预测准确率最高的操作。一个更复杂的例子,在一个网络中可能在很多位置上包含了很多不同的操作选择,搜索空间是随着选择数目指数地增长,而one-shot模型的大小只随选择数目线性增长。相同的权重可以用来评估很多不同的结构,极大地降低了计算量。
为one-shot设计搜索空间需要满足以下几个要求:(1)搜索空间需要足够大来捕捉到多样的候选结构;(2)one-shot模型产生的验证集准确率必须能预测独立模型训练产生的精度;(3)在有限的计算资源下,one-shot模型需要足够小。下图给出了一个搜索空间的例子:
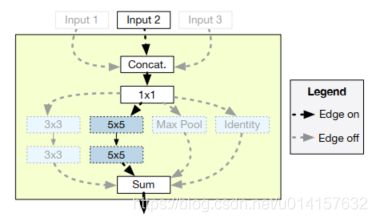
它合并了关于网络结构和应用在网络中不同位置的操作的重要决策。在训练过程中,one-shot模型包括了三个不同的输入,这些输入被连接在一起。在评估阶段,它可以通过剔除Input 1和Input 3来模拟一个一个仅包含Input 2的网络。更一般地说,我们可以使能或禁止任何输入连接的组合。这样,搜索空间可以随着传入的跨连接数目指数级地增长,而one-shot模型大小只线性地增长。连接操作后面总是连着一个1x1卷积,使得无论有多少传入的跨连接,输出的滤波器数目都是常量。然后one-shot模型在1x1卷积的输出上应用不同的操作,将结果相加。在评估阶段,则会移除一些操作。上图中有4种操作:3x3卷积、5x5卷积、最大池化和Identity,但只有5x5卷积操作留了下来。one-shot模型是个大型的网络,用带动量的SGD训练,为了保证特定架构的one-shot模型精度与独立模型精度之间的良好关系,作者考虑了以下几个方面:
- 互相适应的鲁棒性。如果直接训练整个one-shot模型,模型里的各部分会相互耦合。即使移除不重要的操作,也会造成模型预测精度的急剧下降,one-shot模型和独立模型之间的准确率的关系也会退化。为了解决这个问题,作者在训练one-shot模型时也包含了path dropout(我理解的是类似于dropout,起到了正则化的作用),对于每个batch,也随机地剔除一些操作。通过实验发现,一开始的时候不用path dropout,然后随着时间逐渐地增加dropout的几率,可以达到很好的效果。dropout的几率是
,0
- 训练模型的稳定性。作者一开尝试实验的时候发现one-shot的训练很不稳定,但是仔细地应用BN可以增加稳定性,作者使用了BN-ReLU-Conv这样的卷积顺序。在评估阶段要剔除某些操作,这会使每层batch的统计量改变,因为对于候选结构无法提前得知其batch统计量。因此批BN在评估时的应用方式与在训练时完全相同——动态计算batch的统计信息。作者还发现,训练one-shot模型时,如果在一个batch里对每个样本都dropout同样的操作,训练也会不稳定。因此对于不同的样本子集,作者dropout不同的操作:作者将一个batch的样本分成多个小batch(文中称为ghost batch),一个batch有1024个样本,分成32个ghost batch,每个有32个样本,每个ghost batch剔除不同的操作。
- 防止过度正则化。在训练期间,L2正则化只应用于当前结构在one-shot模型里所用到的那部分。如果不这样,那些经常被删除的层就会更加规范化。
当one-shot模型训练好之后,用一个固定的概率分布独立地采样结构,然后在验证集上评估。作者注意到,随机采样也可以用遗传算法或基于神经网络的强化学习代替。完成搜索之后,从头训练表现最好的结构,同时也可以扩展架构以增加其性能,也可以缩小架构以减少计算成本。作者在实验中,增加了过滤器的数量来扩展架构。
虽然one-shot采用权值共享加速了训练,每次子网络都继承上一次训练的权重,但超网络的排序能力是个问题,超网络只有能较准确地预测子网络的性能,one-shot方法才是有效的,而这也正是one-shot方法的核心与难点。
4、可微分NAS
次节介绍的论文是Liu, Hanxiao, et al. “DARTS: Differentiable Architecture Search.” International Conference on Learning Representations, 2018. 之前介绍的NAS方法搜索空间都是离散的,而可微分方法将搜索空间松弛化使其变成连续的,则可以使用梯度的方法来解决。
DARTS也是搜索卷积cell然后堆叠cell形成最终的网络。这里的cell是一个包含有向无环图,包含一个有N个节点的有序序列。每个节点

是一个隐含表示(比如特征图),每个有向的边(i,j)是变换

的操作

。作者假设cell有两个输入加点和一个输出节点,每个中间节点是它所有的前驱节点计算得到:
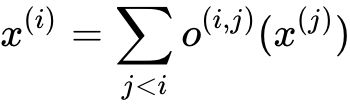
一个特殊的操作:
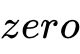
,包括在可能的操作集合里,表示两个节点之间没有连接。学习cell结构的任务就转换成了学习边上的操作。令
![]()
为可选操作的集合(比如卷积、最大池化、

),每个操作表示作用在
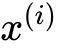
上的函数

。为了使搜索空间连续化,作者将特定操作的选择松弛化为在所有可能操作上的softmax:

一对节点(i,j)之间的操作被一个
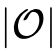
维向量

参数化。松弛化之后,搜索任务就变成了学习一组连续的变量

,如下图所示:
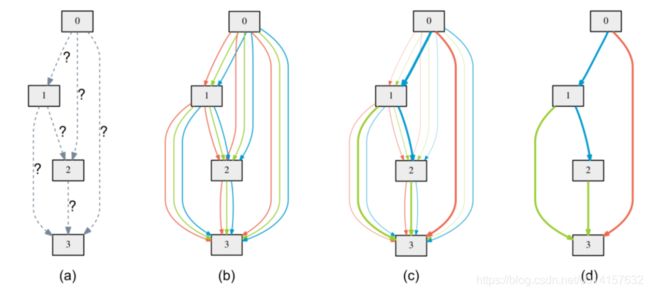
图(a)表示初始化的边,操作是未知的。图(b)通过在每条边放置混合的候选操作来松弛搜索空间,每个颜色的线表示不同的操作。图(c)是通过解决一个优化问题,联合训练候选操作的概率和网络的权重,不同的粗细表示了
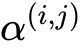
的大小。图(d)是最终学习到的结构。
学习到了所有操作的可能性

后,选择其中最优可能的操作,也就是

。接下来,我们都用
![]()
表示结构。松弛化之后,我们的目标就是共同学习结构
![]()
和权重w,DARTS的目标是用梯度下降优化验证集损失。令

和

分别表示训练和验证损失,我们就是要找到一个最优的
![]()
最小化验证集损失
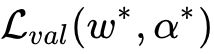
,其中
![]()
通过最小化训练集损失

。这是一个双层优化问题(bilevel opyimization problem),
![]()
是上层变量,w是下层变量:

解决上面的双层优化问题是困难的,因为任何$\alpha$的改变都会要求重新计算

。因此作者提出了一种近似的迭代解法,用梯度下降在权重空间和结构空间中轮流地优化w和
![]()
:

DARTS极大地加速了搜索速度,提供了可微分这样一个新颖的思路。但它的优化是个难点,搜索出来的模型可能包含大量的skip操作而导致模型性能崩塌。
最后还是要推荐下建的人工智能学习群:[966367816],如果你想学或者正在学习人工智能 ,欢迎你的加入
扫码加威更方便领取人工智能资料包呀
